At FullTilt: Real-Time Open-Set 3D Macromolecule Detection Directly from Tilted 2D Projections
Pith reviewed 2026-05-10 15:17 UTC · model grok-4.3
The pith
FullTilt detects 3D macromolecules in real time by processing 2D tilt-series projections directly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
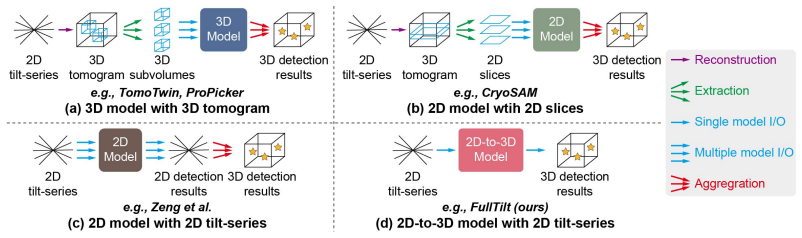
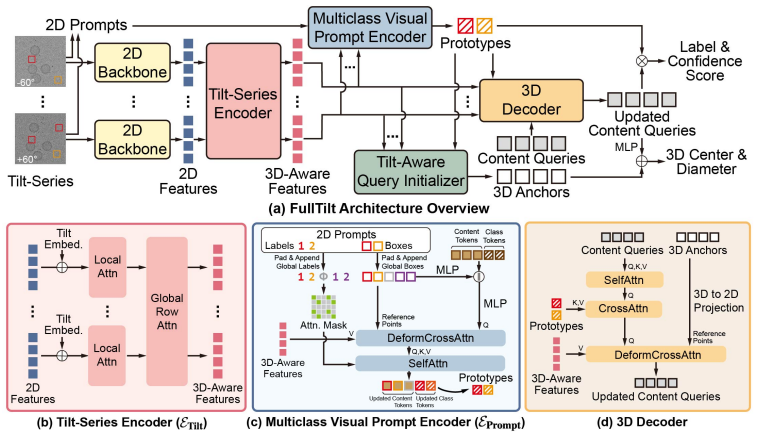
FullTilt redefines 3D detection by operating directly on aligned 2D tilt-series. Because a tilt-series contains significantly fewer images than slices in a reconstructed tomogram, FullTilt eliminates redundant volumetric computation and accelerates inference by orders of magnitude. To process the entire tilt-series simultaneously, a tilt-series encoder fuses cross-view information. A multiclass visual prompt encoder supports flexible prompting, a tilt-aware query initializer anchors 3D queries, and an auxiliary geometric primitives module improves the model's grasp of multi-view geometry while adding robustness to imaging artifacts. On three real-world datasets, FullTilt reaches state-of-the
What carries the argument
The tilt-series encoder that processes the full set of tilted 2D projections at once to fuse cross-view information, replacing the need for 3D tomogram reconstruction and sliding-window subvolume scans.
If this is right
- Inference speeds up by orders of magnitude because the method handles far fewer images than the slices inside a tomogram.
- VRAM use drops enough that the entire tilt-series can be processed at once without extracting and scanning subvolumes.
- Zero-shot detection reaches state-of-the-art levels on real datasets without any target-specific retraining.
- Large-scale visual proteomics studies become feasible on standard hardware rather than high-memory systems.
Where Pith is reading between the lines
- The same direct-projection strategy could shorten processing times for other tomography tasks that currently reconstruct full 3D volumes first.
- Lower memory demands might let the approach run on smaller computers or in settings where only modest GPUs are available.
- Further tests on tilt-series with heavier noise or missing wedges could clarify how much the geometry module contributes to robustness.
Load-bearing premise
The tilt-series encoder, prompt encoder, query initializer, and geometry module can combine information across views and cope with artifacts well enough to replace full 3D volumetric processing.
What would settle it
A head-to-head test on one of the three real-world datasets where FullTilt's zero-shot detection accuracy falls below that of prior sliding-window methods on the same data.
Figures

read the original abstract
Open-set 3D macromolecule detection in cryogenic electron tomography eliminates the need for target-specific model retraining. However, strict VRAM constraints prohibit processing an entire 3D tomogram, forcing current methods to rely on slow sliding-window inference over extracted subvolumes. To overcome this, we propose FullTilt, an end-to-end framework that redefines 3D detection by operating directly on aligned 2D tilt-series. Because a tilt-series contains significantly fewer images than slices in a reconstructed tomogram, FullTilt eliminates redundant volumetric computation, accelerating inference by orders of magnitude. To process the entire tilt-series simultaneously, we introduce a tilt-series encoder to efficiently fuse cross-view information. We further propose a multiclass visual prompt encoder for flexible prompting, a tilt-aware query initializer to effectively anchor 3D queries, and an auxiliary geometric primitives module to enhance the model's understanding of multi-view geometry while improving robustness to adverse imaging artifacts. Extensive evaluations on three real-world datasets demonstrate that FullTilt achieves state-of-the-art zero-shot performance while drastically reducing runtime and VRAM requirements, paving the way for rapid, large-scale visual proteomics analysis. All code and data will be publicly available upon publication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents FullTilt, an end-to-end framework for open-set 3D macromolecule detection in cryogenic electron tomography that operates directly on aligned 2D tilt-series projections rather than reconstructed 3D tomograms. It introduces a tilt-series encoder to fuse cross-view information, a multiclass visual prompt encoder for flexible prompting, a tilt-aware query initializer to anchor 3D queries, and an auxiliary geometric primitives module to enhance multi-view geometry understanding and artifact robustness. The central claim is that this yields state-of-the-art zero-shot performance on three real-world datasets while achieving orders-of-magnitude reductions in runtime and VRAM usage compared to sliding-window volumetric methods, with all code and data to be released publicly.
Significance. If the results hold, the work has substantial significance for visual proteomics and cryo-ET analysis. Eliminating the need for full 3D tomogram reconstruction and subvolume sliding windows directly addresses VRAM and speed bottlenecks, potentially enabling real-time, large-scale detection on resource-limited hardware. The zero-shot open-set formulation without target-specific retraining is a notable strength, and the explicit commitment to public code and data supports reproducibility and follow-on work.
major comments (3)
- [§3.3] §3.3 (tilt-aware query initializer): The description states that this module anchors 3D queries from 2D projections, but provides no equations, pseudocode, or explicit mechanism for depth disambiguation; without this, it is unclear whether the initializer can reliably solve the inverse problem of 3D localization from a small number of tilted views, which is load-bearing for the claim of replacing volumetric processing.
- [§4] §4 (Experiments): The assertion of SOTA zero-shot performance on three datasets lacks reported quantitative metrics (e.g., precision-recall at specific IoU thresholds), ablation studies isolating the geometric primitives module, or error analysis on low-SNR/high-tilt regimes; if these are absent or insufficient, the evidence does not yet confirm that the 2D-only pipeline matches or exceeds volumetric baselines on ground-truth tomogram-derived detections.
- [§3.4] §3.4 (auxiliary geometric primitives module): This component is positioned as key for robustness to adverse imaging artifacts and multi-view geometry, yet the manuscript supplies no ablation removing it or testing its contribution to 3D query accuracy; this omission directly affects the central claim that the architecture can handle depth and artifact issues without explicit 3D features.
minor comments (2)
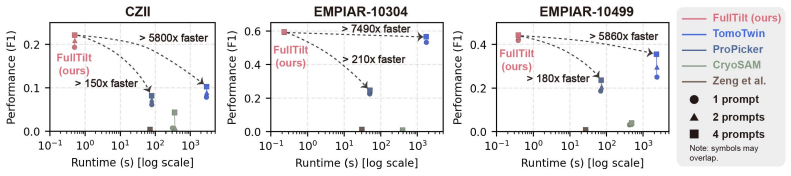
- [Abstract] Abstract: The phrase 'orders of magnitude' speedup is used without a specific factor or reference to a table/figure; adding a concrete comparison (e.g., '10-100x faster than X') would improve clarity.
- [§3.1] Notation: The distinction between 'tilt-series encoder' and 'multiclass visual prompt encoder' inputs could be clarified with a diagram or explicit tensor shapes in §3.1-3.2 to aid readers unfamiliar with the prompting setup.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each of the major comments point-by-point below and have incorporated revisions to improve clarity and completeness of the presentation.
read point-by-point responses
-
Referee: [§3.3] §3.3 (tilt-aware query initializer): The description states that this module anchors 3D queries from 2D projections, but provides no equations, pseudocode, or explicit mechanism for depth disambiguation; without this, it is unclear whether the initializer can reliably solve the inverse problem of 3D localization from a small number of tilted views, which is load-bearing for the claim of replacing volumetric processing.
Authors: We appreciate the referee pointing out the need for greater technical detail in Section 3.3. While the original manuscript describes the tilt-aware query initializer in prose, including its use of tilt angles to project 2D features into 3D space, we acknowledge that explicit equations would enhance reproducibility. In the revised manuscript, we have added the mathematical formulation for the initializer, which computes initial 3D query positions as the weighted average of back-projected rays from multiple views, with weights based on detection confidence and geometric consistency. Pseudocode has also been included in the supplementary material. This explicitly addresses depth disambiguation by leveraging the known geometry of the tilt-series. revision: yes
-
Referee: [§4] §4 (Experiments): The assertion of SOTA zero-shot performance on three datasets lacks reported quantitative metrics (e.g., precision-recall at specific IoU thresholds), ablation studies isolating the geometric primitives module, or error analysis on low-SNR/high-tilt regimes; if these are absent or insufficient, the evidence does not yet confirm that the 2D-only pipeline matches or exceeds volumetric baselines on ground-truth tomogram-derived detections.
Authors: We thank the referee for this observation. The original manuscript includes quantitative results in Section 4, with comparisons of precision, recall, and F1 scores at IoU=0.5 for FullTilt versus baselines on the three datasets. To further address the concern, we have expanded the experiments in the revision to include full precision-recall curves at multiple IoU thresholds, dedicated ablation studies for the geometric primitives module demonstrating its contribution to performance, and error analysis on low-SNR and high-tilt regimes. These additions provide stronger evidence that the 2D-only pipeline achieves state-of-the-art zero-shot performance comparable to or exceeding volumetric baselines. revision: yes
-
Referee: [§3.4] §3.4 (auxiliary geometric primitives module): This component is positioned as key for robustness to adverse imaging artifacts and multi-view geometry, yet the manuscript supplies no ablation removing it or testing its contribution to 3D query accuracy; this omission directly affects the central claim that the architecture can handle depth and artifact issues without explicit 3D features.
Authors: We agree that an ablation study is important to substantiate the role of the auxiliary geometric primitives module. In the revised manuscript, we have added an ablation study in Section 4 comparing the full model to a variant without this module. The results indicate improved robustness to imaging artifacts and better accuracy in 3D query initialization, supporting the central claim that the architecture can effectively handle depth and artifact issues through multi-view geometric understanding without explicit 3D features. revision: yes
Circularity Check
No circularity: architecture claims rest on empirical evaluation, not self-referential reductions
full rationale
The manuscript introduces an end-to-end neural architecture (tilt-series encoder, multiclass visual prompt encoder, tilt-aware query initializer, auxiliary geometric primitives module) for open-set 3D detection directly from 2D tilt-series. No equations, derivations, or parameter-fitting steps are presented that would allow a claimed prediction or uniqueness result to reduce by construction to its own inputs. Performance assertions are supported by evaluations on three real-world cryo-ET datasets rather than by internal redefinitions or self-citation chains. Any self-citations that may exist in the full text are not load-bearing for the central claims, which remain falsifiable against external volumetric baselines. This is the expected outcome for a methods paper whose contributions are architectural and empirical.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
T. L. Blundell, “Structure-based drug design,”Nature, vol. 384, no. 6604, p. 23, 1996. 1
work page 1996
-
[2]
Structural systems pharmacology: the role of 3d structures in next-generation drug development,
M. Duran-Frigola, R. Mosca, and P. Aloy, “Structural systems pharmacology: the role of 3d structures in next-generation drug development,”Chemistry & biology, vol. 20, no. 5, pp. 674–684, 2013. 1
work page 2013
-
[3]
The promise and the challenges of cryo-electron tomography,
M. Turk and W. Baumeister, “The promise and the challenges of cryo-electron tomography,”FEBS letters, vol. 594, no. 20, pp. 3243–3261, 2020. 1
work page 2020
-
[4]
Advances in cryo-et data processing: meeting the demands of visual proteomics,
A. J. Watson and A. Bartesaghi, “Advances in cryo-et data processing: meeting the demands of visual proteomics,”Current Opinion in Structural Biology, vol. 87, p. 102861, 2024. 1, 9
work page 2024
-
[5]
Cryo-electron tomography: Challenges and computational strategies for particle picking,
T. Wagner and S. Raunser, “Cryo-electron tomography: Challenges and computational strategies for particle picking,”Current Opinion in Structural Biology, vol. 93, p. 103113, 2025. 1
work page 2025
-
[6]
Sphire-cryolo is a fast and accurate fully automated particle picker for cryo-em,
T. Wagner, F. Merino, M. Stabrin, T. Moriya, C. Antoni, A. Apelbaum, P. Hagel, O. Sitsel, T. Raisch, D. Prumbaum,et al., “Sphire-cryolo is a fast and accurate fully automated particle picker for cryo-em,” Communications biology, vol. 2, no. 1, p. 218, 2019. 1, 3
work page 2019
-
[7]
Deep learning improves macromolecule identification in 3d cellular cryo-electron tomograms,
E. Moebel, A. Martinez-Sanchez, L. Lamm, R. D. Righetto, W. Wietrzynski, S. Albert, D. Larivière, E. Fourmentin, S. Pfeffer, J. Ortiz,et al., “Deep learning improves macromolecule identification in 3d cellular cryo-electron tomograms,”Nature methods, vol. 18, no. 11, pp. 1386–1394, 2021. 3
work page 2021
-
[8]
G. Liu, T. Niu, M. Qiu, Y . Zhu, F. Sun, and G. Yang, “Deepetpicker: Fast and accurate 3d particle picking for cryo-electron tomography using weakly supervised deep learning,”Nature Communications, vol. 15, no. 1, p. 2090, 2024. 1
work page 2090
-
[9]
G. Rice, T. Wagner, M. Stabrin, O. Sitsel, D. Prumbaum, and S. Raunser, “Tomotwin: generalized 3d localization of macromolecules in cryo-electron tomograms with structural data mining,”Nature methods, vol. 20, no. 6, pp. 871–880, 2023. 1, 3, 6, 7, 8
work page 2023
-
[10]
Cryosam: Training-free cryoet tomogram segmentation with foundation models,
Y . Zhao, H. Bian, M. Mu, M. R. Uddin, Z. Li, X. Li, T. Wang, and M. Xu, “Cryosam: Training-free cryoet tomogram segmentation with foundation models,” inInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 124–134, Springer, 2024. 1, 3, 6, 7, 8
work page 2024
-
[11]
Propicker: promptable segmentation for particle picking in cryogenic electron tomography,
S. Wiedemann, Z. Fabian, M. Soltanolkotabi, and R. Heckel, “Propicker: promptable segmentation for particle picking in cryogenic electron tomography,”Journal of Structural Biology, p. 108298, 2026. 1, 3, 6, 7, 8
work page 2026
-
[12]
Tomopicker: annotation-efficient particle picking in cryo-electron tomograms,
M. R. Uddin, A. Y . Ahmed, M. T. Tahmid, M. Z. U. Alam, Z. Freyberg, and M. Xu, “Tomopicker: annotation-efficient particle picking in cryo-electron tomograms,”bioRxiv, 2024. 1, 3, 8
work page 2024
-
[13]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo,et al., “Segment anything,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 4015–4026, 2023. 1, 3
work page 2023
-
[14]
Levoy,Volume rendering using the Fourier projection-slice theorem
M. Levoy,Volume rendering using the Fourier projection-slice theorem. Computer Systems Laboratory, Stanford University, 1992. 1
work page 1992
-
[15]
H. Winkler and K. A. Taylor, “Accurate marker-free alignment with simultaneous geometry determination and reconstruction of tilt series in electron tomography,”Ultramicroscopy, vol. 106, no. 3, pp. 240–254,
-
[16]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” inEuropean conference on computer vision, pp. 213–229, Springer, 2020. 2, 4, 9
work page 2020
-
[17]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 10012–10022, 2021. 2, 7
work page 2021
-
[18]
Surround-view vision-based 3d detection for autonomous driving: A survey,
A. Singh, “Surround-view vision-based 3d detection for autonomous driving: A survey,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3243–3252, 2023. 2
work page 2023
-
[19]
Detr3d: 3d object detection from multi-view images via 3d-to-2d queries,
Y . Wang, V . C. Guizilini, T. Zhang, Y . Wang, H. Zhao, and J. Solomon, “Detr3d: 3d object detection from multi-view images via 3d-to-2d queries,” inConference on robot learning, pp. 180–191, PMLR, 2022. 2, 4, 6, 7, 8
work page 2022
-
[20]
Petr: Position embedding transformation for multi-view 3d object detection,
Y . Liu, T. Wang, X. Zhang, and J. Sun, “Petr: Position embedding transformation for multi-view 3d object detection,” inEuropean conference on computer vision, pp. 531–548, Springer, 2022. 2, 4, 6, 7, 8 10
work page 2022
-
[21]
Self-supervised noise modeling and sparsity guided electron tomography volumetric image denoising,
Z. Yang, D. Zang, H. Li, Z. Zhang, F. Zhang, and R. Han, “Self-supervised noise modeling and sparsity guided electron tomography volumetric image denoising,”Ultramicroscopy, vol. 255, p. 113860, 2024. 2
work page 2024
-
[22]
X. Zeng, Z. Lin, M. R. Uddin, B. Zhou, C. Cheng, J. Zhang, Z. Freyberg, and M. Xu, “Structure detection in three-dimensional cellular cryoelectron tomograms by reconstructing two-dimensional annotated tilt series,”Journal of Computational Biology, vol. 29, no. 8, pp. 932–941, 2022. 2, 3, 6, 7, 8
work page 2022
-
[23]
Pickyolo: Fast deep learning particle detector for annotation of cryo electron tomograms,
E. Genthe, S. Miletic, I. Tekkali, R. H. James, T. C. Marlovits, and P. Heuser, “Pickyolo: Fast deep learning particle detector for annotation of cryo electron tomograms,”Journal of structural biology, vol. 215, no. 3, p. 107990, 2023. 3
work page 2023
-
[24]
Convolutional networks for supervised mining of molecular patterns within cellular context,
I. de Teresa-Trueba, S. K. Goetz, A. Mattausch, F. Stojanovska, C. E. Zimmerli, M. Toro-Nahuelpan, D. W. Cheng, F. Tollervey, C. Pape, M. Beck,et al., “Convolutional networks for supervised mining of molecular patterns within cellular context,”Nature Methods, vol. 20, no. 2, pp. 284–294, 2023. 3
work page 2023
-
[25]
Y . Hao, B. Zhang, X. Wan, R. Yan, Z. Liu, J. Li, S. Zhang, X. Cui, and F. Zhang, “Vp-detector: A 3d convolutional neural network for automated macromolecule localization and classification in cryo-electron tomograms,”bioRxiv, pp. 2021–05, 2021. 3
work page 2021
-
[26]
Accurate detection of proteins in cryo-electron tomograms from sparse labels,
Q. Huang, Y . Zhou, H.-F. Liu, and A. Bartesaghi, “Accurate detection of proteins in cryo-electron tomograms from sparse labels,” inEuropean Conference on Computer Vision, pp. 644–660, Springer, 2022. 3, 7, 8
work page 2022
-
[27]
Positive-unlabeled learning with non-negative risk estimator,
R. Kiryo, G. Niu, M. C. Du Plessis, and M. Sugiyama, “Positive-unlabeled learning with non-negative risk estimator,”Advances in neural information processing systems, vol. 30, 2017. 3
work page 2017
-
[28]
Deep models for multi-view 3d object recognition: a review,
M. Alzahrani, M. Usman, S. K. Jarraya, S. Anwar, and T. Helmy, “Deep models for multi-view 3d object recognition: a review,”Artificial Intelligence Review, vol. 57, no. 12, p. 323, 2024. 4
work page 2024
-
[29]
Petrv2: A unified framework for 3d perception from multi-camera images,
Y . Liu, J. Yan, F. Jia, S. Li, A. Gao, T. Wang, and X. Zhang, “Petrv2: A unified framework for 3d perception from multi-camera images,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 3262–3272, 2023. 4
work page 2023
-
[30]
Deformable DETR: deformable transformers for end-to-end object detection,
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable DETR: deformable transformers for end-to-end object detection,” in9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021, OpenReview.net, 2021. 5
work page 2021
-
[31]
Vggt: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “Vggt: Visual geometry grounded transformer,” inProceedings of the Computer Vision and Pattern Recognition Conference, pp. 5294–5306,
-
[32]
T-rex2: Towards generic object detection via text-visual prompt synergy,
Q. Jiang, F. Li, Z. Zeng, T. Ren, S. Liu, and L. Zhang, “T-rex2: Towards generic object detection via text-visual prompt synergy,” inEuropean Conference on Computer Vision, pp. 38–57, Springer, 2024. 5, 6, 7
work page 2024
-
[33]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection,
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Su,et al., “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” inEuropean conference on computer vision, pp. 38–55, Springer, 2024. 5, 6, 7
work page 2024
-
[34]
Dino: Detr with improved denoising anchor boxes for end-to-end object detection,
H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. M. Ni, and H.-Y . Shum, “Dino: Detr with improved denoising anchor boxes for end-to-end object detection,” 2022. 5, 6, 7
work page 2022
-
[35]
Simulation of transmission electron microscope images of biological specimens,
H. Rullgård, L.-G. Öfverstedt, S. Masich, B. Daneholt, and O. Öktem, “Simulation of transmission electron microscope images of biological specimens,”Journal of microscopy, vol. 243, no. 3, pp. 234–256, 2011. 6
work page 2011
-
[36]
A realistic phantom dataset for benchmarking cryo-et data annotation,
A. Peck, Y . Yu, J. Schwartz, A. Cheng, U. H. Ermel, J. Hutchings, S. Kandel, D. Kimanius, E. A. Montabana, D. Serwas,et al., “A realistic phantom dataset for benchmarking cryo-et data annotation,” Nature Methods, vol. 22, no. 9, pp. 1819–1823, 2025. 7
work page 2025
-
[37]
Improved applicability and robustness of fast cryo-electron tomography data acquisition,
F. Eisenstein, R. Danev, and M. Pilhofer, “Improved applicability and robustness of fast cryo-electron tomography data acquisition,”Journal of structural biology, vol. 208, no. 2, pp. 107–114, 2019. 7
work page 2019
-
[38]
Multi-particle cryo-em refinement with m visualizes ribosome-antibiotic complex at 3.5 å in cells,
D. Tegunov, L. Xue, C. Dienemann, P. Cramer, and J. Mahamid, “Multi-particle cryo-em refinement with m visualizes ribosome-antibiotic complex at 3.5 å in cells,”Nature methods, vol. 18, no. 2, pp. 186–193,
-
[39]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inInternational Conference on Learning Representations, 2019. 7 11
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.