HO-Flow: Generalizable Hand-Object Interaction Generation with Latent Flow Matching
Pith reviewed 2026-05-10 15:11 UTC · model grok-4.3
The pith
HO-Flow generates realistic hand-object interaction sequences from text and 3D objects by encoding motions into a unified latent manifold and applying masked flow matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HO-Flow encodes sequences of hand and object motions into a unified latent manifold via an interaction-aware variational autoencoder that incorporates hand and object kinematics. It then employs a masked flow matching model that combines auto-regressive temporal reasoning with continuous latent generation. Object motions are predicted relative to the initial frame to enable effective pre-training on large-scale synthetic data. On the GRAB, OakInk, and DexYCB benchmarks this produces state-of-the-art results in both physical plausibility and motion diversity for text-conditioned interaction synthesis.
What carries the argument
The interaction-aware VAE latent manifold that unifies hand and object kinematics, combined with masked flow matching for continuous latent generation and relative-frame object motion prediction.
If this is right
- Text and canonical object inputs can produce interaction sequences with improved temporal coherence and physical realism.
- Pre-training on large synthetic datasets becomes feasible through relative-frame object motion prediction.
- Motion diversity increases while maintaining interaction plausibility across multiple real-world benchmarks.
- Generation succeeds without requiring explicit physics simulation or post-processing steps.
Where Pith is reading between the lines
- The same latent flow matching pattern may transfer to full-body human-scene or multi-person motion synthesis tasks.
- Relative-frame prediction could increase robustness when objects appear at novel positions or scales.
- Combining the latent manifold with downstream physics-based refinement might further reduce rare implausible contacts.
Load-bearing premise
That the interaction-aware VAE latent manifold plus relative-frame object motion prediction will produce physically plausible outputs without explicit physics constraints or post-hoc correction.
What would settle it
Measuring whether generated motions on the DexYCB benchmark show higher rates of hand-object penetration or lower contact accuracy than baselines when evaluated with standard physical metrics.
Figures








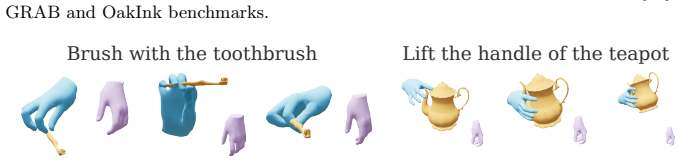
read the original abstract
Generating realistic 3D hand-object interactions (HOI) is a fundamental challenge in computer vision and robotics, requiring both temporal coherence and high-fidelity physical plausibility. Existing methods remain limited in their ability to learn expressive motion representations for generation and perform temporal reasoning. In this paper, we present HO-Flow, a framework for synthesizing realistic hand-object motion sequences from texts and canoncial 3D objects. HO-Flow first employs an interaction-aware variational autoencoder to encode sequences of hand and object motions into a unified latent manifold by incorporating hand and object kinematics, enabling the representation to capture rich interaction dynamics. It then leverages a masked flow matching model that combines auto-regressive temporal reasoning with continuous latent generation, improving temporal coherence. To further enhance generalization, HO-Flow predicts object motions relative to the initial frame, enabling effective pre-training on large-scale synthetic data. Experiments on the GRAB, OakInk, and DexYCB benchmarks demonstrate that HO-Flow achieves state-of-the-art performance in both physical plausibility and motion diversity for interaction motion synthesis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HO-Flow, a framework for synthesizing 3D hand-object interaction motion sequences from text and canonical 3D objects. It first trains an interaction-aware VAE to encode hand and object kinematics into a unified latent manifold, then applies a masked flow matching model that performs auto-regressive temporal reasoning in continuous latent space. Object motion is predicted relative to the initial frame to enable pre-training on large-scale synthetic data. The central claim is that this yields state-of-the-art physical plausibility and motion diversity on the GRAB, OakInk, and DexYCB benchmarks.
Significance. If the performance claims are substantiated, the combination of an interaction-aware latent manifold with relative-frame flow matching offers a scalable route to generalizable HOI generation that avoids explicit physics engines or post-processing. The explicit use of synthetic pre-training via relative motion prediction is a concrete strength that could transfer to other motion synthesis tasks.
major comments (3)
- [Abstract] Abstract: The claim of state-of-the-art results on GRAB, OakInk, and DexYCB for both physical plausibility and motion diversity is stated without any quantitative metrics, tables, ablation studies, or error analysis, leaving the central empirical claim unsupported by evidence.
- [Method] Method description (interaction-aware VAE and masked flow matching): The physical-plausibility claim rests on the assumption that the learned latent manifold plus relative-frame prediction will implicitly enforce non-penetration and stable contact; no explicit physics losses, contact terms, or post-inference correction are described, and no analysis of interpenetration or floating-contact failure modes on held-out sequences is provided.
- [Experiments] Experiments section: No definition or reporting of the concrete metrics used to quantify physical plausibility (e.g., penetration volume, contact stability) or motion diversity (e.g., diversity score, FID) appears, preventing assessment of whether the reported SOTA improvements are meaningful.
minor comments (1)
- [Abstract] The abstract contains the typo 'canoncial' (should be 'canonical').
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the potential of combining an interaction-aware latent manifold with relative-frame flow matching. We address each major comment below and will make targeted revisions to improve clarity and substantiation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of state-of-the-art results on GRAB, OakInk, and DexYCB for both physical plausibility and motion diversity is stated without any quantitative metrics, tables, ablation studies, or error analysis, leaving the central empirical claim unsupported by evidence.
Authors: We agree that the abstract would benefit from explicit quantitative support. The full manuscript reports specific SOTA improvements via tables and ablations in the experiments section, but these are not summarized numerically in the abstract. We will revise the abstract to include key metrics (e.g., reductions in penetration volume and gains in diversity scores) while remaining within length limits. revision: yes
-
Referee: [Method] Method description (interaction-aware VAE and masked flow matching): The physical-plausibility claim rests on the assumption that the learned latent manifold plus relative-frame prediction will implicitly enforce non-penetration and stable contact; no explicit physics losses, contact terms, or post-inference correction are described, and no analysis of interpenetration or floating-contact failure modes on held-out sequences is provided.
Authors: Physical plausibility arises from data-driven implicit modeling: the interaction-aware VAE encodes hand-object kinematics (including contact patterns) into a unified manifold, while masked flow matching and relative-frame object prediction enable learning of stable dynamics from both real and large-scale synthetic data. No explicit physics losses are used, as this preserves generality and avoids reliance on simulators. We will add an analysis of failure modes, including quantitative interpenetration statistics and contact stability on held-out sequences, plus qualitative examples. revision: partial
-
Referee: [Experiments] Experiments section: No definition or reporting of the concrete metrics used to quantify physical plausibility (e.g., penetration volume, contact stability) or motion diversity (e.g., diversity score, FID) appears, preventing assessment of whether the reported SOTA improvements are meaningful.
Authors: We apologize for the lack of explicit definitions. Physical plausibility is quantified via penetration volume (average interpenetrating mesh volume) and contact stability (fraction of frames with persistent non-floating contacts). Diversity uses a variance-based score on motion features and FID on latent embeddings. These appear in our result tables but without prior formal definition. We will insert a dedicated metrics subsection in Experiments with formulas, implementation details, and references to prior usage before the quantitative results. revision: yes
Circularity Check
No circularity: standard VAE + flow-matching pipeline with external benchmarks
full rationale
The paper presents HO-Flow as an interaction-aware VAE encoding hand/object kinematics into a latent manifold followed by masked flow matching with relative-frame object motion prediction. No equations, derivations, or self-citations are shown that reduce any claimed prediction or uniqueness result to a fitted quantity defined by the same inputs. The method description relies on established VAE and flow-matching building blocks without self-definitional loops, fitted-input renamings, or load-bearing self-citations for core premises. Performance claims rest on GRAB/OakInk/DexYCB benchmarks rather than tautological reductions, rendering the derivation chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Athanasiou, N., Petrovich, M., Black, M.J., Varol, G.: SINC: Spatial composition of 3D human motions for simultaneous action generation. In: ICCV (2023)
work page 2023
-
[2]
Blattmann, A., Rombach, R., Oktay, D., Ommer, B.: Align your latents: High- resolution video synthesis with latent diffusion models. In: CVPR (2023)
work page 2023
-
[3]
Bohg, J., Morales, A., Asfour, T., Kragic, D.: Data-driven grasp synthesis—a sur- vey. IEEE TRO (2013)
work page 2013
-
[4]
Cha, J., Kim, J., Yoon, J.S., Baek, S.: Text2HOI: Text-guided 3D motion genera- tion for hand-object interaction. In: CVPR (2024)
work page 2024
-
[5]
Chao,Y.W.,Yang,W.,Xiang, Y.,Molchanov,P.,Handa,A., Tremblay, J.,Narang, Y.S., Van Wyk, K., Iqbal, U., Birchfield, S., et al.: DexYCB: A benchmark for capturing hand grasping of objects. In: CVPR (2021)
work page 2021
-
[6]
Chen, X., Jiang, B., Liu, W., Huang, Z., Fu, B., Chen, T., Yu, G.: Executing your commands via motion diffusion in latent space. In: CVPR (2023)
work page 2023
-
[7]
Chen, Z., Hasson, Y., Schmid, C., Laptev, I.: AlignSDF: Pose-aligned signed dis- tance fields for hand-object reconstruction. In: ECCV (2022)
work page 2022
-
[8]
Christen, S., Hampali, S., Sener, F., Remelli, E., Hodan, T., Sauser, E., Ma, S., Tekin, B.: DiffH2O: Diffusion-based synthesis of hand-object interactions from tex- tual descriptions. In: SIGGRAPH Asia (2024)
work page 2024
-
[9]
Dasari, S., Gupta, A., Kumar, V.: Learning dexterous manipulation from exemplar object trajectories and pre-grasps. In: ICRA (2023)
work page 2023
-
[10]
Du, Y., Weinzaepfel, P., Lepetit, V., Brégier, R.: Multi-finger grasping like humans. In: IROS (2022)
work page 2022
-
[11]
In: Computer Graphics Forum (2023)
Ghosh, A., Dabral, R., Golyanik, V., Theobalt, C., Slusallek, P.: IMoS: intent- driven full-body motion synthesis for human-object interactions. In: Computer Graphics Forum (2023)
work page 2023
-
[12]
Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Poole, B., Norouzi, M., Fleet, D.J., Salimans, T.: Video diffusion models. In: NeurIPS (2022)
work page 2022
-
[13]
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: NeurIPS (2020)
work page 2020
-
[14]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv:2207.12598 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Huang, M., Chu, F.J., Tekin, B., Liang, K.J., Ma, H., Wang, W., Chen, X., Gleize, P., Xue, H., Lyu, S., et al.: HOIGPT: Learning long-sequence hand-object interac- tion with language models. In: CVPR (2025)
work page 2025
-
[16]
Jiang, H., Liu, S., Wang, J., Wang, X.: Hand-object contact consistency reasoning for human grasps generation. In: ICCV (2021)
work page 2021
-
[17]
Karras,T.,Aittala,M.,Aila,T.,Laine,S.:Elucidatingthedesignspaceofdiffusion- based generative models. In: NeurIPS (2022)
work page 2022
-
[18]
Karunratanakul, K., Yang, J., Zhang, Y., Black, M.J., Muandet, K., Tang, S.: Grasping field: Learning implicit representations for human grasps. In: 3DV (2020)
work page 2020
-
[19]
Auto-Encoding Variational Bayes
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[20]
Li, K., Wang, J., Yang, L., Lu, C., Dai, B.: SemGrasp: Semantic grasp generation via language aligned discretization. In: ECCV (2024)
work page 2024
-
[21]
Li, M., Christen, S., Wan, C., Cai, Y., Liao, R., Sigal, L., Ma, S.: LatentHOI: On the generalizable hand object motion generation with latent hand diffusion. In: CVPR (2025)
work page 2025
-
[22]
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: ICLR (2023) 16 Chen et al
work page 2023
-
[23]
Liu, T., Liu, Z., Jiao, Z., Zhu, Y., Zhu, S.C.: Synthesizing diverse and physically stable grasps with arbitrary hand structures using differentiable force closure esti- mator. IEEE RA-L (2021)
work page 2021
-
[24]
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. In: ICLR (2023)
work page 2023
-
[25]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Lu, J., Kang, H., Li, H., Liu, B., Yang, Y., Huang, Q., Hua, G.: UGG: Unified generative grasping. In: ECCV (2024)
work page 2024
-
[27]
Luo, Z., Cao, J., Christen, S., Winkler, A., Kitani, K.M., Xu, W.: OmniGrasp: Grasping diverse objects with simulated humanoids. In: NeurIPS (2024)
work page 2024
-
[28]
Ma, N., Goldstein, M., Albergo, M.S., Boffi, N.M., Vanden-Eijnden, E., Xie, S.: SiT: Exploring flow and diffusion-based generative models withscalable interpolant transformers. In: ECCV (2024)
work page 2024
-
[29]
IEEE Robotics & Automation Magazine (2004)
Miller, A.T., Allen, P.K.: Graspit! a versatile simulator for robotic grasping. IEEE Robotics & Automation Magazine (2004)
work page 2004
-
[30]
Nichol, A., Dhariwal, P.: Improved denoising diffusion probabilistic models. In: ICML (2021)
work page 2021
-
[31]
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: ICCV (2023)
work page 2023
-
[32]
Petrovich, M., Black, M.J., Varol, G.: TEMOS: Generating diverse human motions from textual descriptions. In: ECCV (2022)
work page 2022
-
[33]
Prokudin, S., Lassner, C., Romero, J.: Efficient learning on point clouds with basis point sets. In: ICCV (2019)
work page 2019
-
[34]
Qi, C.R., Yi, L., Su, H., Guibas, L.J.: PointNet++: Deep hierarchical feature learn- ing on point sets in a metric space. In: NeurIPS (2017)
work page 2017
-
[35]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: ICML (2021)
work page 2021
-
[36]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022)
work page 2022
-
[37]
Romero, J., Tzionas, D., Black, M.J.: Embodied Hands: Modeling and capturing hands and bodies together. TOG (2017)
work page 2017
-
[38]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., Ganguli, S.: Deep unsuper- vised learning using nonequilibrium thermodynamics. In: ICML (2015)
work page 2015
-
[40]
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. In: ICLR (2021)
work page 2021
-
[41]
Sutton, R.S.: Reinforcement learning: An introduction. A Bradford Book (2018)
work page 2018
-
[42]
Taheri, O., Ghorbani, N., Black, M.J., Tzionas, D.: GRAB: A dataset of whole- body human grasping of objects. In: ECCV (2020)
work page 2020
-
[43]
Tevet, G., Raab, S., Gordon, B., Shafir, Y., Cohen-Or, D., Bermano, A.H.: Human motion diffusion model. In: ICLR (2023)
work page 2023
-
[44]
Van Den Oord, A., Vinyals, O., et al.: Neural discrete representation learning. In: NeurIPS (2017)
work page 2017
-
[45]
Wan,W.,Geng,H.,Liu,Y.,Shan,Z.,Yang,Y.,Yi,L.,Wang,H.:UniDexGrasp++: Improving dexterous grasping policy learning via geometry-aware curriculum and iterative generalist-specialist learning. In: ICCV (2023) HO-Flow 17
work page 2023
-
[46]
Wei, Y.L., Jiang, J.J., Xing, C., Tan, X.T., Wu, X.M., Li, H., Cutkosky, M., Zheng, W.S.: Grasp as you say: Language-guided dexterous grasp generation. In: NeurIPS (2024)
work page 2024
-
[47]
Wei, Y.L., Lin, M., Lin, Y., Jiang, J.J., Wu, X.M., Zeng, L.A., Zheng, W.S.: AffordDexGrasp: Open-set language-guided dexterous grasp with generalizable- instructive affordance. In: ICCV (2025)
work page 2025
-
[48]
Wu, Z., Potamias, R.A., Zhang, X., Zhang, Z., Deng, J., Luo, S.: CEDex: Cross- embodiment dexterous grasp generation at scale from human-like contact repre- sentations. In: ICRA (2026)
work page 2026
-
[49]
Xu, G.H., Wei, Y.L., Zheng, D., Wu, X.M., Zheng, W.S.: Dexterous grasp trans- former. In: CVPR (2024)
work page 2024
-
[50]
Xu, Y., Wan, W., Zhang, J., Liu, H., Shan, Z., Shen, H., Wang, R., Geng, H., Weng, Y., Chen, J., et al.: UniDexGrasp: Universal robotic dexterous grasping via learning diverse proposal generation and goal-conditioned policy. In: CVPR (2023)
work page 2023
-
[51]
Yang, L., Li, K., Zhan, X., Wu, F., Xu, A., Liu, L., Lu, C.: OakInk: A large-scale knowledge repository for understanding hand-object interaction. In: CVPR (2022)
work page 2022
-
[52]
Yang,L.,Zhan,X.,Li,K.,Xu,W.,Li,J.,Lu,C.:CPF:Learningacontactpotential field to model the hand-object interaction. In: ICCV (2021)
work page 2021
-
[53]
Ye, Q., Li, H., Liu, Q., Jiang, S., Zhou, T., Huo, Y., Chen, J.: Contact2motion: Contact guided dexterous grasp motion generation with synergy embedded opti- mization. IJRR (2025)
work page 2025
-
[54]
Ye, Y., Li, X., Gupta, A., De Mello, S., Birchfield, S., Song, J., Tulsiani, S., Liu, S.: Affordance diffusion: Synthesizing hand-object interactions. In: CVPR (2023)
work page 2023
-
[55]
Zhang, H., Christen, S., Fan, Z., Hilliges, O., Song, J.: GraspXL: Generating grasp- ing motions for diverse objects at scale. In: ECCV (2024)
work page 2024
-
[56]
Zhang, J., Zhang, Y., Cun, X., Huang, S., Zhang, Y., Zhao, H., Lu, H., Shen, X.: T2M-GPT: Generating human motion from textual descriptions with discrete representations. In: CVPR (2023)
work page 2023
-
[57]
Zhang, M., Li, Z., Wang, Q., Shi, J., Li, Y., Tan, P.: MotionDiffuse: Text-driven human motion generation with diffusion model. arXiv:2208.15001 (2022)
-
[58]
Zhang, W., Dabral, R., Golyanik, V., Choutas, V., Alvarado, E., Beeler, T., Haber- mann, M., Theobalt, C.: BimArt: A unified approach for the synthesis of 3D bi- manual interaction with articulated objects. In: CVPR (2025)
work page 2025
-
[59]
Zhang,Z.,Wang,H.,Yu,Z.,Cheng,Y.,Yao,A.,Chang,H.J.:NL2Contact:Natural language guided 3D hand-object contact modeling with diffusion model. In: ECCV (2024)
work page 2024
-
[60]
Zhong, Y., Jiang, Q., Yu, J., Ma, Y.: DexGrasp Anything: Towards universal robotic dexterous grasping with physics awareness. In: CVPR (2025)
work page 2025
-
[61]
Zhou, Y., Barnes, C., Lu, J., Yang, J., Li, H.: On the continuity of rotation repre- sentations in neural networks. In: CVPR (2019)
work page 2019
-
[62]
Appendix In appendix, we provide implementation details about our network architecture in Section A
Zhu, H., Zhao, T., Ni, X., Wang, J., Fang, K., Righetti, L., Pang, T.: Should we learn contact-rich manipulation policies from sampling-based planners? IEEE RA-L (2025) 18 Chen et al. Appendix In appendix, we provide implementation details about our network architecture in Section A. Section B further describes the training and testing procedures of our m...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.