RADA: Region-Aware Dual-encoder Auxiliary learning for Barely-supervised Medical Image Segmentation
Pith reviewed 2026-05-10 16:30 UTC · model grok-4.3
The pith
A dual-encoder setup extracts fine-grained visual features from sparse medical annotations and merges them with text semantics to guide pixel-level segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that their region-aware dual-encoder auxiliary learning pipeline extracts fine-grained, region-specific visual features from the original images and the limited annotations, combines these image-level features with text-level semantic guidance, and thereby supplies region-aware supervision that bridges image-level semantics and pixel-level segmentation, resulting in improved performance when integrated into a triple-view training framework under extremely sparse annotation conditions.
What carries the argument
The dual-encoder framework that supplies fine-grained region-specific visual features and combines them with text-level semantic guidance to produce region-aware supervision for segmentation.
If this is right
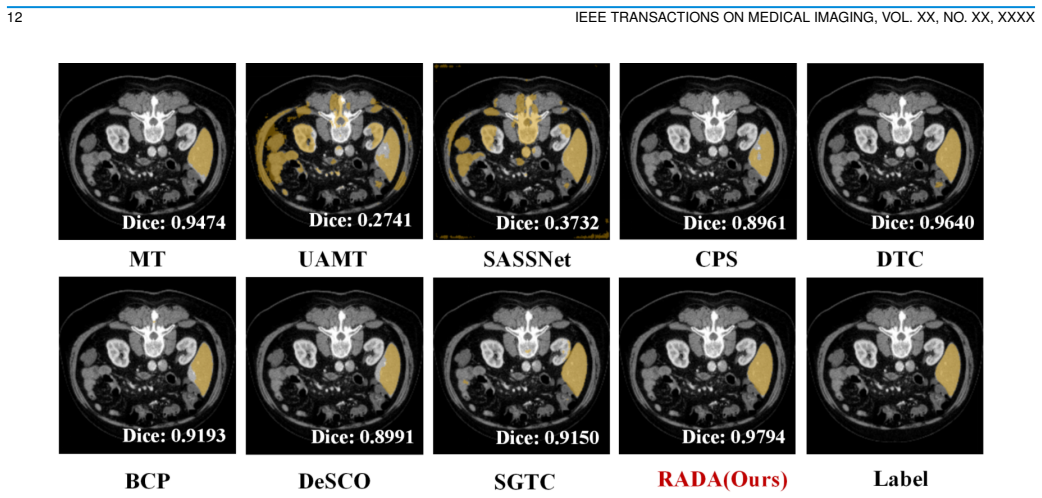
- Achieves state-of-the-art performance on LA2018, KiTS19, and LiTS under extremely sparse annotation settings.
- Demonstrates robust generalization across diverse medical imaging datasets.
- Improves pseudo-label quality by adding semantic understanding beyond geometric continuity alone.
- Bridges image-level semantics and pixel-level segmentation through combined visual and text guidance.
Where Pith is reading between the lines
- The same feature-plus-text combination might reduce annotation effort in other pixel-wise medical tasks such as detection or registration.
- If the extracted features generalize, similar dual setups could help adapt natural-image models to other specialized imaging domains with limited labels.
- The triple-view training structure could be tested on 2D slices or non-volumetric modalities to check whether the gains persist outside 3D CT and MRI.
- Success here points toward broader use of multimodal guidance to stabilize pseudo-labeling in any low-supervision visual segmentation setting.
Load-bearing premise
That fine-grained visual features extracted by the dual-encoder transfer effectively to medical images and can be combined with text-level semantic guidance to deliver reliable region-aware supervision for pixel-level segmentation.
What would settle it
If removing the dual-encoder component or the text-semantic guidance produces no measurable gain in segmentation accuracy or boundary precision on the LA2018, KiTS19, or LiTS datasets, the central mechanism would be falsified.
Figures







read the original abstract
Deep learning has greatly advanced medical image segmentation, but its success relies heavily on fully supervised learning, which requires dense annotations that are costly and time-consuming for 3D volumetric scans. Barely-supervised learning reduces annotation burden by using only a few labeled slices per volume. Existing methods typically propagate sparse annotations to unlabeled slices through geometric continuity to generate pseudo-labels, but this strategy lacks semantic understanding, often resulting in low-quality pseudo-labels. Furthermore, medical image segmentation is inherently a pixel-level visual understanding task, where accuracy fundamentally depends on the quality of local, fine-grained visual features. Inspired by this, we propose RADA, a novel Region-Aware Dual-encoder Auxiliary learning pipeline which introduces a dual-encoder framework pre-trained on Alpha-CLIP to extract fine-grained, region-specific visual features from the original images and limited annotations. The framework combines image-level fine-grained visual features with text-level semantic guidance, providing region-aware semantic supervision that bridges image-level semantics and pixel-level segmentation. Integrated into a triple-view training framework, RADA achieves SOTA performance under extremely sparse annotation settings on LA2018, KiTS19 and LiTS, demonstrating robust generalization across diverse datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RADA, a Region-Aware Dual-encoder Auxiliary learning pipeline for barely-supervised 3D medical image segmentation. It employs a dual-encoder pre-trained on Alpha-CLIP to extract fine-grained, region-specific visual features from images and sparse annotations, fuses these with text-level semantic guidance to generate region-aware semantic supervision, and integrates the result into a triple-view training framework, claiming state-of-the-art performance on the LA2018, KiTS19, and LiTS datasets under extremely sparse annotation regimes.
Significance. If the empirical claims hold after proper validation, the work would be significant for the field by replacing purely geometric pseudo-label propagation with semantically informed, region-aware supervision derived from a pre-trained dual-encoder. This could reduce annotation burden while improving generalization across heterogeneous medical volumes, provided the Alpha-CLIP feature transfer demonstrably supplies medically meaningful local semantics.
major comments (2)
- [Abstract] Abstract: The central claim of achieving SOTA performance on LA2018, KiTS19 and LiTS is stated without any quantitative metrics, baseline comparisons, statistical significance tests, or experimental protocol details, rendering the data support for the claim unevaluable.
- [Method] Method (dual-encoder component): The region-aware semantic supervision rests on the untested assumption that fine-grained visual features extracted by an Alpha-CLIP-pretrained dual-encoder transfer effectively to 3D medical volumes and, when fused with text guidance, yield reliable pixel-level pseudo-supervision. No domain-adaptation step, medical pre-training, or ablation isolating the contribution of these transferred features versus standard consistency regularization is described; if the transfer fails to carry medically meaningful local semantics, the advertised benefit collapses.
minor comments (1)
- [Abstract] The term 'barely-supervised' and the precise sparsity level (number of labeled slices per volume) should be defined explicitly with reference to the experimental protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to improve the evaluability of our claims and to provide additional validation for the dual-encoder component.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of achieving SOTA performance on LA2018, KiTS19 and LiTS is stated without any quantitative metrics, baseline comparisons, statistical significance tests, or experimental protocol details, rendering the data support for the claim unevaluable.
Authors: We agree that the abstract would benefit from quantitative support. In the revised manuscript, we have updated the abstract to include key performance metrics (Dice scores on LA2018, KiTS19, and LiTS under the sparse annotation settings), direct comparisons to recent baselines, and a concise description of the evaluation protocol, including the use of multiple runs for statistical reliability. This makes the SOTA claim directly evaluable while preserving the abstract's brevity. revision: yes
-
Referee: [Method] Method (dual-encoder component): The region-aware semantic supervision rests on the untested assumption that fine-grained visual features extracted by an Alpha-CLIP-pretrained dual-encoder transfer effectively to 3D medical volumes and, when fused with text guidance, yield reliable pixel-level pseudo-supervision. No domain-adaptation step, medical pre-training, or ablation isolating the contribution of these transferred features versus standard consistency regularization is described; if the transfer fails to carry medically meaningful local semantics, the advertised benefit collapses.
Authors: We thank the referee for this important observation. The original manuscript validates the approach through consistent SOTA results across three heterogeneous datasets, but we acknowledge the value of more direct isolation of the dual-encoder's contribution. In the revised version, we have added a dedicated ablation study comparing the full RADA pipeline against a variant using only standard consistency regularization (without the Alpha-CLIP dual-encoder and region-aware fusion). We have also expanded the method discussion to explain that no explicit domain-adaptation module was introduced because the auxiliary learning and triple-view framework enable effective transfer of the region-specific features; the ablation results confirm that these features supply medically meaningful local semantics beyond geometric propagation alone. revision: yes
Circularity Check
No circularity; method uses external pre-training and reports empirical SOTA results
full rationale
The paper proposes RADA as a dual-encoder auxiliary pipeline pre-trained on Alpha-CLIP to supply region-aware visual features fused with text guidance inside a triple-view consistency framework. It evaluates this empirically on public benchmarks (LA2018, KiTS19, LiTS) under sparse annotation protocols and claims SOTA performance. No equations, fitted parameters, or self-citations are shown that reduce the claimed supervision quality or performance gains to quantities defined or fitted from the target data by construction. The central pipeline depends on an external pre-trained model and geometric/textual consistency losses whose validity is tested externally rather than assumed tautologically.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Alpha-CLIP pre-training yields transferable fine-grained region-specific features for medical images
invented entities (1)
-
Region-aware semantic supervision
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Improve retinal artery/vein classification via channel couplin,
S. Zeng, C. H. Lee, K. Li, B. Xie, O. Fu, H. He, L. Zhu, Y . Lu, and F. Cheng, “Improve retinal artery/vein classification via channel couplin,” 2025. [Online]. Available: https://arxiv.org/abs/2508.03738
-
[2]
Novel extraction of discriminative fine-grained feature to improve retinal vessel segmentation,
S. Zeng, C. H. Lee, M. C. Nnamdi, W. Shi, J. B. Tamo, L. Zhu, H. He, X. Zhang, Q. Chen, M. D. Wang, Y . Lu, and Q. Ren, “Novel extraction of discriminative fine-grained feature to improve retinal vessel segmentation,” 2025. [Online]. Available: https://arxiv.org/abs/2505.03896
-
[3]
A. Tarvainen and H. Valpola, “Mean teachers are better role mod- els: Weight-averaged consistency targets improve semi-supervised deep learning results,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[4]
Uncertainty-aware self-ensembling model for semi-supervised 3d left atrium segmentation,
L. Yu, S. Wang, X. Li, C.-W. Fu, and P.-A. Heng, “Uncertainty-aware self-ensembling model for semi-supervised 3d left atrium segmentation,” inInternational conference on medical image computing and computer- assisted intervention. Springer, 2019, pp. 605–613
work page 2019
-
[5]
Semi-supervised semantic segmentation with cross pseudo supervision,
X. Chen, Y . Yuan, G. Zeng, and J. Wang, “Semi-supervised semantic segmentation with cross pseudo supervision,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 2613–2622
work page 2021
-
[6]
Supercl: Superpixel guided contrastive learning for medical image segmentation pre- training,
S. Zeng, L. Zhu, X. Zhang, H. He, and Y . Lu, “Supercl: Superpixel guided contrastive learning for medical image segmentation pre- training,” 2025. [Online]. Available: https://arxiv.org/abs/2504.14737
-
[7]
Multi-level asymmetric contrastive learning for volumetric medical image segmentation pre-training,
S. Zeng, L. Zhu, X. Zhang, M. C. Nnamdi, W. Shi, J. B. Tamo, Q. Chen, H. He, L. Jin, Z. Tian, Q. Ren, Z. Xie, and Y . Lu, “Multi-level asymmetric contrastive learning for volumetric medical image segmentation pre-training,” 2025. [Online]. Available: https://arxiv.org/abs/2309.11876
-
[8]
Pln: Parasitic- like network for barely supervised medical image segmentation,
S. Li, H. Cai, L. Qi, Q. Yu, Y . Shi, and Y . Gao, “Pln: Parasitic- like network for barely supervised medical image segmentation,”IEEE Transactions on Medical Imaging, vol. 42, no. 3, pp. 582–593, 2022
work page 2022
-
[10]
K. Yan, Q. Cai, F. Zhang, Z. Cao, and Z. Liu, “Sgtc: Semantic-guided triplet co-training for sparsely annotated semi- supervised medical image segmentation,” 2024. [Online]. Available: https://arxiv.org/abs/2412.15526
-
[11]
Bidirectional copy- paste for semi-supervised medical image segmentation,
Y . Bai, D. Chen, Q. Li, W. Shen, and Y . Wang, “Bidirectional copy- paste for semi-supervised medical image segmentation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 11 514–11 524
work page 2023
-
[12]
Shape-aware semi-supervised 3d semantic segmentation for medical images,
S. Li, C. Zhang, and X. He, “Shape-aware semi-supervised 3d semantic segmentation for medical images,” inInternational Conference on Med- ical Image Computing and Computer-Assisted Intervention. Springer, 2020, pp. 552–561
work page 2020
-
[13]
Semi-supervised medical image segmentation through dual-task consistency,
X. Luo, J. Chen, T. Song, and G. Wang, “Semi-supervised medical image segmentation through dual-task consistency,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, no. 10, 2021, pp. 8801– 8809
work page 2021
-
[14]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
work page 2021
-
[15]
Maskclip: Masked self-distillation advances contrastive language-image pretraining,
X. Dong, J. Bao, Y . Zheng, T. Zhang, D. Chen, H. Yang, M. Zeng, W. Zhang, L. Yuan, D. Chenet al., “Maskclip: Masked self-distillation advances contrastive language-image pretraining,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 10 995–11 005
work page 2023
-
[16]
Alpha-clip: A clip model focusing on wherever you want,
Z. Sun, Y . Fang, T. Wu, P. Zhang, Y . Zang, S. Kong, Y . Xiong, D. Lin, and J. Wang, “Alpha-clip: A clip model focusing on wherever you want,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 13 019–13 029
work page 2024
-
[17]
Y . Xiao, Y . Chen, H. Ma, J. Hong, C. Li, L. Wu, H. Guo, and J. Wang, “Pixclip: Achieving fine-grained visual language understand- ing via any-granularity pixel-text alignment learning,”arXiv preprint arXiv:2511.04601, 2025
-
[18]
Z. Xiong, Q. Xia, Z. Hu, N. Huang, C. Bian, Y . Zheng, S. Vesal, N. Ravikumar, A. Maier, X. Yanget al., “A global benchmark of algorithms for segmenting the left atrium from late gadolinium-enhanced cardiac magnetic resonance imaging,”Medical image analysis, vol. 67, p. 101832, 2021
work page 2021
-
[19]
N. Heller, N. Sathianathen, A. Kalapara, E. Walczak, K. Moore, H. Kaluzniak, J. Rosenberg, P. Blake, Z. Rengel, M. Oestreichet al., “The kits19 challenge data: 300 kidney tumor cases with clinical context, ct semantic segmentations, and surgical outcomes,”arXiv preprint arXiv:1904.00445, 2019
-
[20]
The liver tumor segmentation benchmark (lits),
P. Bilic, P. Christ, H. B. Li, E. V orontsov, A. Ben-Cohen, G. Kaissis, A. Szeskin, C. Jacobs, G. E. H. Mamani, G. Chartrandet al., “The liver tumor segmentation benchmark (lits),”Medical image analysis, vol. 84, p. 102680, 2023
work page 2023
-
[21]
Orthogonal annotation benefits barely-supervised medical image segmentation,
H. Cai, S. Li, L. Qi, Q. Yu, Y . Shi, and Y . Gao, “Orthogonal annotation benefits barely-supervised medical image segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2023, pp. 3302–3311
work page 2023
-
[22]
V-net: Fully convolutional neural networks for volumetric medical image segmentation,
F. Milletari, N. Navab, and S.-A. Ahmadi, “V-net: Fully convolutional neural networks for volumetric medical image segmentation,” in2016 fourth international conference on 3D vision (3DV). Ieee, 2016, pp. 565–571
work page 2016
-
[23]
A reproducible evaluation of ants similarity metric performance in brain image registration,
B. B. Avants, N. J. Tustison, G. Song, P. A. Cook, A. Klein, and J. C. Gee, “A reproducible evaluation of ants similarity metric performance in brain image registration,”Neuroimage, vol. 54, no. 3, pp. 2033–2044, 2011. AUTHORet al.: PREPARATION OF PAPERS FOR IEEE TRANSACTIONS ON MEDICAL IMAGING 9 VI. APPENDIX A. Network Architecture The backbone network e...
work page 2033
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.