Recognition: unknown
Do Thought Streams Matter? Evaluating Reasoning in Gemini Vision-Language Models for Video Scene Understanding
Pith reviewed 2026-05-10 16:00 UTC · model grok-4.3
The pith
Internal reasoning traces improve video scene understanding in vision-language models but deliver most benefits within the first few hundred tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that thought streams do affect the quality of video scene understanding outputs, yet the relationship follows a pattern of quick saturation where the majority of gains happen early, and that insufficient reasoning allocation results in the final output containing elements not present in the reasoning trace, representing a form of hallucination induced by the compression to the answer.
What carries the argument
Thought streams as sequences of model-generated reasoning prior to the final answer, assessed through metrics for content usefulness, fidelity to the final output, and focus on key entities in the scene.
If this is right
- Shorter reasoning traces can suffice for high-quality video scene understanding, reducing token usage.
- Constrained reasoning budgets lead to hallucinated content in final outputs that was not reasoned about.
- One model configuration achieves an optimal trade-off between performance and resource consumption.
- Thought streams maintain similar focus on dominant scene elements across different model variants despite variations in expression style.
Where Pith is reading between the lines
- The rapid plateau in benefits could extend to other video-related tasks like temporal event detection or multi-shot analysis.
- Adaptive systems might monitor early reasoning content to decide when to stop generating further thoughts.
- Stylistic differences in reasoning expression between model types may influence how easily humans can interpret the model's process.
- Independent validation using human judges on the coverage and contentfulness metrics would test the reliability of the automated evaluation approach.
Load-bearing premise
An external language model can serve as a reliable and unbiased evaluator of the content value in reasoning traces, the extent to which that content appears in the final answer, and the main entities the model attends to.
What would settle it
If the quality scores assigned by the judge to model outputs continue to rise substantially when reasoning token limits are increased well beyond a few hundred, that would contradict the plateau claim; alternatively, if low-budget final answers frequently include scene details absent from their thought streams, it would support the hallucination observation.
Figures


read the original abstract
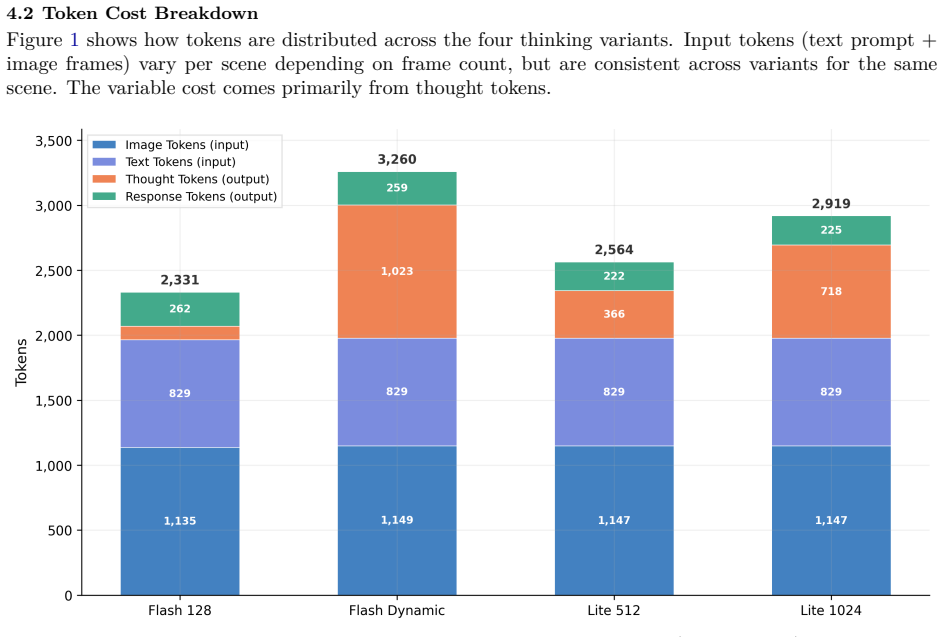
We benchmark how internal reasoning traces, which we call thought streams, affect video scene understanding in vision-language models. Using four configurations of Google's Gemini 2.5 Flash and Flash Lite across scenes extracted from 100 hours of video, we ask three questions: does more thinking lead to better outputs, where do the gains stop, and what do these models actually think about? We introduce three evaluation metrics. Contentfulness measures how much of the thought stream is useful scene content versus meta-commentary. Thought-Final Coverage measures how faithfully the thought stream translates into the final output. Dominant Entity Analysis identifies which subjects, actions, and settings the model focuses on. GPT-5 serves as an independent judge. We find that quality gains from additional thinking plateau quickly, with most improvement occurring in the first few hundred tokens. Flash Lite offers the best balance between quality and token usage. Tight reasoning budgets cause the model to add content in the final output that it never reasoned about, a form of compression-step hallucination. Despite being different model tiers, Flash and Flash Lite produce similar thought streams, though they differ in style: Flash discusses its reasoning process, while Lite focuses on describing the scene.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks the impact of internal reasoning traces ('thought streams') on video scene understanding in Gemini 2.5 Flash and Flash Lite. Using scenes from 100 hours of video and four model configurations, it introduces three GPT-5-scored metrics—contentfulness (useful scene content vs. meta-commentary), thought-final coverage, and dominant entity analysis—to address whether more thinking improves outputs, where gains plateau, and what the models focus on. Main findings: quality gains plateau after the first few hundred tokens, Flash Lite offers the best quality-token trade-off, tight budgets induce 'compression-step hallucination' (final outputs containing un-reasoned content), and the two models generate similar thought streams but differ stylistically (Flash discusses reasoning; Lite describes scenes).
Significance. If the empirical results hold after proper validation, the work would provide actionable insights into reasoning efficiency for vision-language models on video tasks. The rapid plateau and compression hallucination observations could guide budget allocation and architecture choices for multimodal reasoning; the model-tier comparison and new metrics would offer a reusable framework for analyzing thought processes in VLMs. These contributions would be relevant to efficient inference and interpretability in computer vision and multimodal AI.
major comments (2)
- [Abstract and Evaluation Metrics section] Abstract and Evaluation Metrics section: The three headline results (plateau after a few hundred tokens, compression-step hallucination under tight budgets, and stylistic differences) rest entirely on GPT-5 judgments of contentfulness, thought-final coverage, and dominant entity analysis. No human correlation, prompt-consistency checks, inter-annotator agreement, or bias audit is reported for this judge. Because the metrics are inherently subjective, any systematic preference in GPT-5 (e.g., favoring scene descriptions over meta-reasoning) would render the plateau and hallucination claims artifacts of the evaluator rather than properties of Gemini's thought streams.
- [Experimental Setup section] Experimental Setup section: The manuscript reports results across 100 hours of video but supplies no baselines (e.g., non-reasoning or standard CoT modes), statistical significance tests, error bars, or details on scene sampling and diversity. These omissions make it impossible to determine whether the observed plateau and model differences are robust or sensitive to the particular video corpus and prompting choices.
minor comments (1)
- The term 'compression-step hallucination' is introduced without a formal definition or illustrative example drawn from the model outputs; adding one would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of validation and experimental design. We will revise the manuscript accordingly to enhance the reliability of our findings on thought streams in Gemini models for video understanding.
read point-by-point responses
-
Referee: [Abstract and Evaluation Metrics section] The three headline results (plateau after a few hundred tokens, compression-step hallucination under tight budgets, and stylistic differences) rest entirely on GPT-5 judgments of contentfulness, thought-final coverage, and dominant entity analysis. No human correlation, prompt-consistency checks, inter-annotator agreement, or bias audit is reported for this judge. Because the metrics are inherently subjective, any systematic preference in GPT-5 (e.g., favoring scene descriptions over meta-reasoning) would render the plateau and hallucination claims artifacts of the evaluator rather than properties of Gemini's thought streams.
Authors: We agree that the reliance on GPT-5 as the sole judge without additional validation is a limitation that could affect the interpretation of our results. To address this, we will perform a human correlation study on a random subset of 100 thought streams, where human annotators score the same metrics, and report Pearson or Spearman correlations with GPT-5 scores. We will also include prompt-consistency checks by testing multiple judge prompts and reporting variance in scores. These additions will be incorporated into the Evaluation Metrics section to substantiate the claims. revision: yes
-
Referee: [Experimental Setup section] The manuscript reports results across 100 hours of video but supplies no baselines (e.g., non-reasoning or standard CoT modes), statistical significance tests, error bars, or details on scene sampling and diversity. These omissions make it impossible to determine whether the observed plateau and model differences are robust or sensitive to the particular video corpus and prompting choices.
Authors: We acknowledge the need for baselines and statistical rigor to demonstrate robustness. In the revised Experimental Setup, we will add a non-reasoning baseline where the model directly outputs the scene description without generating a thought stream, allowing direct comparison of quality gains. We will also report error bars using standard deviation across video scenes and conduct statistical significance tests (e.g., Wilcoxon signed-rank tests) for key comparisons like plateau points and model differences. Additionally, we will provide more details on scene sampling, including the source videos' diversity (e.g., genres, lengths) and how scenes were extracted to ensure representativeness. revision: yes
Circularity Check
No circularity: purely empirical evaluation with independent metrics and external judge
full rationale
The paper performs direct empirical benchmarking of Gemini model outputs across video scenes using three explicitly defined metrics (Contentfulness, Thought-Final Coverage, Dominant Entity Analysis) scored by GPT-5 as an external judge. No equations, parameter fitting, predictions derived from fitted inputs, or self-citations are present in the reported chain. The central observations (plateau after a few hundred tokens, compression-step hallucination under tight budgets) are stated as direct results from applying the metrics to generated thought streams and final outputs. This structure is self-contained against external benchmarks and contains no reduction of results to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GPT-5 serves as a reliable and unbiased evaluator for the quality of thought streams and final outputs in the defined metrics
Reference graph
Works this paper leans on
-
[1]
ActivityNet: A large-scale video benchmark for human activity understanding
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. ActivityNet: A large-scale video benchmark for human activity understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 961–970, 2015
2015
-
[2]
Evaluating Large Language Models Trained on Code
MarkChen, JerryTworek, HeewooJun, QimingYuan, HenriquePondedeOliveiraPinto, JaredKaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, and Mengdan Zhang. Video-MME: The first-ever comprehensive evaluation benchmark of multi-modal LLMs in video analysis.arXiv preprint arXiv:2405.21075, 2024
work page internal anchor Pith review arXiv 2024
-
[4]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Google. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Ego4D: Around the world in 3,000 hours of egocentric video
KristenGrauman, AndrewWestbury, EugeneByrne, ZacharyChavis, AntoninoFurnari, RohitGirdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4D: Around the world in 3,000 hours of egocentric video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18995–19012, 2022
2022
-
[6]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InProceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[7]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, pages 24824–24837, 2022
2022
-
[10]
HellaSwag: Can a ma- chine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), pages 4791–4800, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a ma- chine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), pages 4791–4800, 2019
2019
-
[11]
Xing, et al
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, et al. Judging LLM-as-a-judge with MT-Bench and chatbot arena. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, 2023. 7
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.