Recognition: unknown
Empowering Video Translation using Multimodal Large Language Models
Pith reviewed 2026-05-10 16:31 UTC · model grok-4.3
The pith
Multimodal large language models unify video translation through semantic reasoning, expressive speech, and visual synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MLLMs empower video translation by overcoming the limits of cascaded pipelines through competitive or superior quality, stronger zero-shot and multi-speaker robustness, and joint modeling of semantic fidelity, timing, speaker identity, and emotional consistency; the paper establishes this via the first comprehensive overview organized around the three-role taxonomy of Semantic Reasoner for video understanding and multimodal fusion, Expressive Performer for controllable speech generation, and Visual Synthesizer for high-fidelity lip-sync video output.
What carries the argument
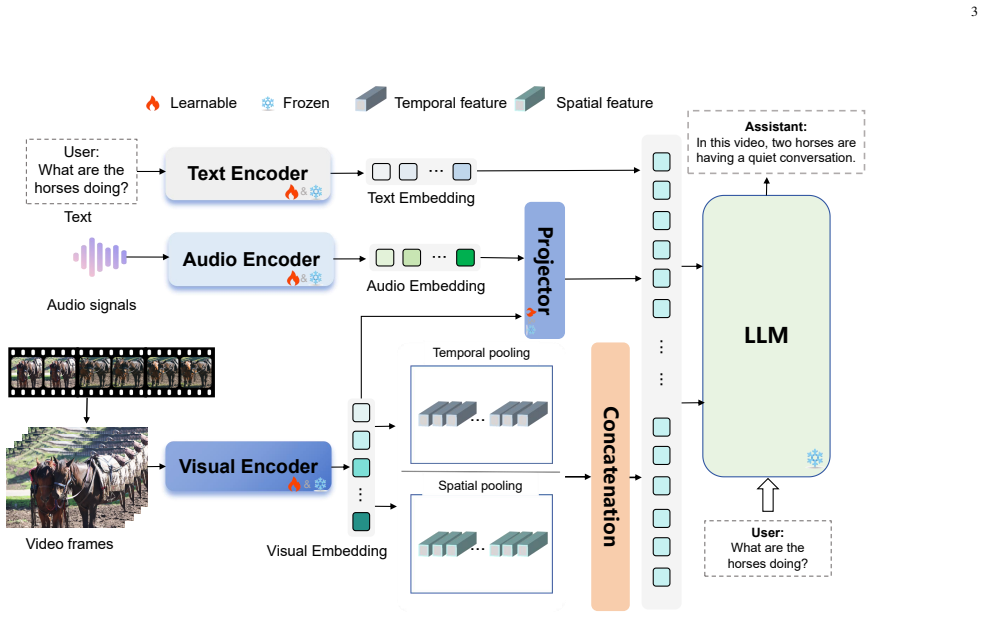
The three-role taxonomy that classifies MLLM contributions as Semantic Reasoner for understanding and temporal reasoning, Expressive Performer for speech generation, and Visual Synthesizer for visual alignment.
If this is right
- MLLMs handle video understanding, temporal reasoning, and multimodal fusion in the semantic reasoner role.
- LLM-driven methods produce expressive and controllable speech in the performer role.
- Video generators achieve high-fidelity lip-sync and visual alignment in the synthesizer role.
- Open challenges persist in video understanding, temporal modeling, and multimodal alignment.
- Future research directions focus on advancing MLLMs for video translation tasks.
Where Pith is reading between the lines
- The taxonomy could serve as an evaluation framework for new models on related multimodal tasks like live captioning.
- Strengthening temporal reasoning in one role would likely improve end-to-end consistency across the pipeline.
- Similar role-based breakdowns might help organize work on other generative video applications.
- Empirical tests of the taxonomy against the latest models would show whether it captures emerging techniques.
Load-bearing premise
That the reviewed MLLM methods truly surpass cascaded pipelines in zero-shot and multi-speaker cases without requiring new exhaustive comparisons in the paper itself.
What would settle it
A head-to-head experiment on multi-speaker videos showing cascaded ASR-MT-TTS-lip-sync systems maintain higher emotional consistency and speaker identity than current MLLM approaches would disprove the claimed superiority.
Figures

read the original abstract
Recent developments in video translation have further enhanced cross-lingual access to video content, with multimodal large language models (MLLMs) playing an increasingly important supporting role. With strong multimodal understanding, reasoning, and generation capabilities, MLLMs-based video translation systems are overcoming the limitations of traditional cascaded pipelines that separately handle automatic speech recognition, machine translation, text-to-speech and lip synchronization. These MLLM-powered approaches not only achieve competitive or superior translation quality, but also demonstrate stronger robustness in zero-shot settings and multi-speaker scenarios, while jointly modeling semantic fidelity, timing, speaker identity, and emotional consistency. However, despite the rapid progress of MLLMs and extensive surveys on general video-language understanding, a focused and systematic review of how MLLMs empower video translation tasks is still lacking. To fill this gap, we provide the first comprehensive overview of MLLMs-based video translation, organized around a three-role taxonomy: 1) Semantic Reasoner, which characterizes how MLLMs perform video understanding, temporal reasoning, and multimodal fusion; 2) Expressive Performer, which analyzes LLM-driven and LLM-augmented techniques for expressive, controllable speech generation; and 3) Visual Synthesizer, which examines different types of video generators for high-fidelity lip-sync and visual alignment. Finally, we discuss open challenges in video understanding, temporal modeling, and multimodal alignment, and outline promising future research directions for MLLMs-powered video translation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a survey on MLLM-based video translation. It claims to provide the first comprehensive overview organized around a three-role taxonomy: Semantic Reasoner (video understanding, temporal reasoning, multimodal fusion), Expressive Performer (LLM-driven expressive speech generation), and Visual Synthesizer (video generators for lip-sync and alignment). The paper asserts that these approaches overcome limitations of cascaded pipelines (ASR+MT+TTS+lip sync) by delivering competitive/superior quality, stronger zero-shot and multi-speaker robustness, and joint modeling of semantic fidelity, timing, speaker identity, and emotion, while also discussing open challenges and future directions.
Significance. As the first focused survey on this topic, the work could help organize a rapidly growing literature at the intersection of MLLMs and video translation. The proposed taxonomy offers a structured lens for understanding MLLM roles, and the synthesis of robustness claims from cited works plus the outlined challenges in video understanding, temporal modeling, and multimodal alignment may guide future research. Its value hinges on the depth of coverage and the taxonomy's utility in practice.
major comments (2)
- [Abstract / §1] Abstract and introduction: The central claim that MLLM-based systems 'demonstrate stronger robustness in zero-shot settings and multi-speaker scenarios' while 'jointly modeling semantic fidelity, timing, speaker identity, and emotional consistency' is load-bearing for the survey's motivation. This should be tied to specific cited results or tables in the main body (e.g., under each role) rather than asserted at a high level, to allow readers to assess the strength of the supporting evidence from prior work.
- [Taxonomy introduction] Taxonomy definition section: The three-role taxonomy is the paper's primary organizing contribution. It is unclear how boundaries are drawn without overlap—for instance, whether 'multimodal fusion' (Semantic Reasoner) is distinct from alignment tasks assigned to Visual Synthesizer, or how Expressive Performer interfaces with temporal reasoning. A explicit justification or decision tree for role assignment, perhaps with a summary table of representative papers, is needed to make the taxonomy falsifiable and useful.
minor comments (2)
- [Abstract] The abstract lists open challenges (video understanding, temporal modeling, multimodal alignment) but does not preview which sections or cited works illustrate each; adding forward references would improve flow.
- [Throughout / related work sections] Consider adding a table that maps key papers to the three roles, including metrics or settings (zero-shot, multi-speaker) where available, to enhance readability and allow quick comparison.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our survey as the first focused review on MLLM-based video translation and for the recommendation of minor revision. We address the two major comments point by point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / §1] Abstract and introduction: The central claim that MLLM-based systems 'demonstrate stronger robustness in zero-shot settings and multi-speaker scenarios' while 'jointly modeling semantic fidelity, timing, speaker identity, and emotional consistency' is load-bearing for the survey's motivation. This should be tied to specific cited results or tables in the main body (e.g., under each role) rather than asserted at a high level, to allow readers to assess the strength of the supporting evidence from prior work.
Authors: We agree that the high-level claims in the abstract and introduction should be explicitly grounded in cited results from the surveyed literature. In the revised manuscript we will add targeted citations and brief result summaries (e.g., zero-shot robustness metrics from representative Semantic Reasoner and Expressive Performer papers, and joint modeling outcomes from Visual Synthesizer works) directly in the abstract/introduction and cross-reference the corresponding role sections. This will allow readers to evaluate the evidence strength without altering the survey's overall narrative. revision: yes
-
Referee: [Taxonomy introduction] Taxonomy definition section: The three-role taxonomy is the paper's primary organizing contribution. It is unclear how boundaries are drawn without overlap—for instance, whether 'multimodal fusion' (Semantic Reasoner) is distinct from alignment tasks assigned to Visual Synthesizer, or how Expressive Performer interfaces with temporal reasoning. A explicit justification or decision tree for role assignment, perhaps with a summary table of representative papers, is needed to make the taxonomy falsifiable and useful.
Authors: We appreciate the suggestion to make the taxonomy more precise and falsifiable. We will expand the taxonomy introduction with an explicit justification of role boundaries, clarifying that Semantic Reasoner covers understanding/reasoning/fusion while Visual Synthesizer addresses generative alignment and lip-sync; Expressive Performer focuses on speech generation with temporal interfaces handled via cross-role coordination. We will add a short decision tree or assignment criteria and a summary table of representative papers per role to illustrate categorization and minimize perceived overlap. revision: yes
Circularity Check
No significant circularity: literature review with external citations only
full rationale
This is a survey paper whose core contribution is a three-role taxonomy for organizing prior MLLM-based video translation literature. No equations, fitted parameters, predictions, or derivations appear in the manuscript. All assertions about overcoming cascaded-pipeline limitations are presented as summaries of externally cited results rather than new claims derived from the paper's own definitions or self-citations. The taxonomy functions as an organizational lens, not a self-referential model that reduces to its inputs by construction. Self-citations, if present, serve only to reference independent prior work and do not bear the load of any internal proof. The paper is therefore self-contained against external benchmarks with no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MLLMs possess strong multimodal understanding, reasoning, and generation capabilities
Reference graph
Works this paper leans on
-
[1]
K. Ataallah, X. Shen, E. Abdelrahman, E. Sleiman, D. Zhu, J. Ding, and M. Elhoseiny, “Minigpt4-video: Advancing multimodal llms for video understanding with interleaved visual-textual tokens,” arXiv:2404.03413, 2024
-
[2]
Zero-shot video question answering via frozen bidirectional language models,
A. Yang, A. Miech, J. Sivic, I. Laptev, and C. Schmid, “Zero-shot video question answering via frozen bidirectional language models,” inNeurIPS, vol. 35, 2022, pp. 124–141
2022
-
[3]
Video-chatgpt: Towards detailed video understanding via large vision and language models,
M. Maaz, H. Rasheed, S. Khan, and F. Khan, “Video-chatgpt: Towards detailed video understanding via large vision and language models,” in ACL, 2024, pp. 12585–12602
2024
-
[4]
Video-llama: An instruction-tuned audio-visual language model for video understanding,
H. Zhang, X. Li, and L. Bing, “Video-llama: An instruction-tuned audio-visual language model for video understanding,” inEMNLP, 2023, pp. 543–553
2023
-
[5]
VideoChat: Chat-Centric Video Understanding
K. Li, Y. He, Y. Wang, Y. Li, W. Wang, P. Luo, Y. Wang, L. Wang, and Y. Qiao, “Videochat: Chat-centric video understanding,” arXiv:2305.06355, 2023
work page internal anchor Pith review arXiv 2023
-
[6]
Llama-vid: An image is worth 2 tokens in large language models,
Y. Li, C. Wang, and J. Jia, “Llama-vid: An image is worth 2 tokens in large language models,” inECCV, 2024, pp. 323–340
2024
-
[7]
arXiv preprint arXiv:2306.07207 , year=
R. Luo, Z. Zhao, M. Yang, J. Dong, D. Li, P. Lu, T. Wang, L. Hu, M. Qiu, and Z. Wei, “Valley: Video assistant with large language model enhanced ability,”arXiv:2306.07207, 2023
-
[8]
Vista- llama: Reliable video narrator via equal distance to visual tokens,
F. Ma, X. Jin, H. Wang, Y. Xian, J. Feng, and Y. Yang, “Vista- llama: Reliable video narrator via equal distance to visual tokens,” arXiv:2312.08870, 2023
-
[9]
An image grid can be worth a video: Zero-shot video question answering using a vlm,
W. Kim, C. Choi, W. Lee, and W. Rhee, “An image grid can be worth a video: Zero-shot video question answering using a vlm,”IEEE Access, 2024
2024
-
[10]
Mvbench: A comprehensive multi- modal video understanding benchmark,
K. Li, Y. Wang, Y. He, Y. Li, Y. Wang, Y. Liu, Z. Wang, J. Xu, G. Chen, P. Luo, L. Wang, and Y. Qiao, “Mvbench: A comprehensive multi- modal video understanding benchmark,” inCVPR, 2024, pp. 22195– 22206
2024
-
[11]
Vaquita: Enhancing alignment in llm-assisted video understanding,
Y. Wang, R. Zhang, H. Wang, U. Bhattacharya, Y. Fu, and G. Wu, “Vaquita: Enhancing alignment in llm-assisted video understanding,” arXiv:2312.02310, 2023
-
[12]
Vamos: Versatile action models for video understanding,
S. Wang, Q. Zhao, M. Q. Do, N. Agarwal, K. Lee, and C. Sun, “Vamos: Versatile action models for video understanding,” inECCV. Springer, 2024, pp. 142–160
2024
-
[13]
Cosmo: Contrastive streamlined multimodal model with interleaved pre-training,
A. J. Wang, L. Li, K. Q. Lin, J. Wang, K. Lin, Z. Yang, L. Wang, and M. Z. Shou, “Cosmo: Contrastive streamlined multimodal model with interleaved pre-training,”arXiv:2401.00849, 2024
-
[14]
Llms meet long video: Advancing long video comprehension with an interactive visual adapter in llms,
Y. Li, X. Chen, B. Hu, and M. Zhang, “Llms meet long video: Advancing long video comprehension with an interactive visual adapter in llms,”arXiv:2402.13546, 2024
-
[15]
Mmict: Boosting multi-modal fine-tuning with in-context examples,
T. Chen, E. Zhang, Y. Gao, K. Li, X. Sun, Y. Zhang, H. Li, and R. Ji, “Mmict: Boosting multi-modal fine-tuning with in-context examples,” TOMM, 2024
2024
-
[16]
Lxmert: Learning cross-modality encoder representations from transformers,
H. Tan and M. Bansal, “Lxmert: Learning cross-modality encoder representations from transformers,” inEMNLP-IJCNLP, 2019, pp. 5100–5111
2019
-
[17]
Eve: Efficient multimodal vision language models with elastic visual experts,
M. Rang, Z. Bi, C. Liu, Y. Tang, K. Han, and Y. Wang, “Eve: Efficient multimodal vision language models with elastic visual experts,” arXiv:2501.04322, 2025
-
[18]
Chatbridge: Bridging modalities with large language model as a language catalyst,
Z. Zhao, L. Guo, T. Yue, S. Chen, S. Shao, X. Zhu, Z. Yuan, and J. Liu, “Chatbridge: Bridging modalities with large language model as a language catalyst,” inCVPR, 2024, pp. 12953–12963
2024
-
[19]
LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model
P. Gao, J. Han, R. Zhang, Z. Lin, S. Geng, A. Zhou, W. Zhang, P. Lu et al., “Llama-adapter v2: Parameter-efficient visual instruction model,” arXiv:2304.15010, 2023
work page internal anchor Pith review arXiv 2023
-
[20]
Bt-adapter: Video conversation is feasible without video instruction tuning,
R. Liu, C. Li, Y. Ge, T. H. Li, Y. Shan, and G. Li, “Bt-adapter: Video conversation is feasible without video instruction tuning,” inCVPR, 2024, pp. 13658–13667
2024
-
[21]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
B. Zhang, K. Li, Z. Cheng, Z. Hu, Y. Yuan, G. Chen, S. Leng, Y. Jiang, H. Zhang, X. Li, P. Jin, W. Zhang, F. Wang, L. Bing, and D. Zhao, “Videollama 3: Frontier multimodal foundation models for image and video understanding,”arXiv:2501.13106, 2025
work page internal anchor Pith review arXiv 2025
-
[22]
From image to video, what do we need in multimodal llms?
S. Huang, H. Zhang, L. Zhong, H. Chen, Y. Gao, Y. Hu, and Z. Qin, “From image to video, what do we need in multimodal llms?” arXiv:2404.11865, 2024
-
[23]
Internvideo2: Scaling foundation models for multimodal video understanding,
Y. Wang, K. Li, X. Li, J. Yu, Y. He, G. Chen, B. Pei, R. Zheng, Z. Wang, Y. Shi, T. Jiang, S. Li, J. Xu, H. Zhang, Y. Huang, Y. Qiao, Y. Wang, and L. Wang, “Internvideo2: Scaling foundation models for multimodal video understanding,” inECCV, 2024, pp. 396–416
2024
-
[24]
Otter: A multi-modal model with in-context instruction tuning,
B. Li, Y. Zhang, L. Chen, J. Wang, F. Pu, J. A. Cahyono, J. Yang, C. Li, and Z. Liu, “Otter: A multi-modal model with in-context instruction tuning,”IEEE Trans. Pattern Anal. Mach. Intell., 2025
2025
-
[25]
Vlog:Video-languagemodelsbygenerative retrieval of narration vocabulary,
K.Q.LinandM.Z.Shou,“Vlog:Video-languagemodelsbygenerative retrieval of narration vocabulary,” inCVPR, 2025, pp. 3218–3228
2025
-
[26]
Time Blindness: Why Video-Language Models Can't See What Humans Can?
U. Upadhyay, M. Ranjan, Z. Shen, and M. Elhoseiny, “Time blindness: Why video-language models can’t see what humans can?” arXiv:2505.24867, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Time-r1: Post-training large vision language model for temporal video grounding,
Y. Wang, Z. Wang, B. Xu, Y. Du, K. Lin, Z. Xiao, Z. Yue, J. Ju, L. Zhang, D. Yang, X. Fang, Z. He, Z. Luo, W. Wang, J. Lin, J. Luan, and Q. Jin, “Time-r1: Post-training large vision language model for temporal video grounding,”arXiv:2503.13377, 2025
-
[28]
Ma-lmm: Memory-augmented large multimodal model for long-term video understanding,
B. He, H. Li, Y. K. Jang, M. Jia, X. Cao, A. Shah, A. Shrivastava, and S.-N. Lim, “Ma-lmm: Memory-augmented large multimodal model for long-term video understanding,” inCVPR, 2024, pp. 13504–13514
2024
-
[29]
Moviellm: Enhancing long video understanding with ai-generated movies
Z. Song, C. Wang, J. Sheng, C. Zhang, G. Yu, J. Fan, and T. Chen, “Moviellm: Enhancing long video understanding with ai-generated movies,”arXiv:2403.01422, 2024
-
[30]
Moviechat:Fromdensetoken to sparse memory for long video understanding,
E. Song, W. Chai, G. Wang, Y. Zhang, H. Zhou, F. Wu, H. Chi, X. Guo, T.Ye,Y.Lu,J.-N.Hwang,andG.Wang,“Moviechat:Fromdensetoken to sparse memory for long video understanding,” inCVPR, 2024, pp. 18221–18232
2024
-
[31]
Longvlm: Efficient long video understanding via large language models,
Y. Weng, M. Han, H. He, X. Chang, and B. Zhuang, “Longvlm: Efficient long video understanding via large language models,” in ECCV, 2024, pp. 453–470
2024
-
[32]
Streaming long video understanding with large language models,
R. Qian, X. Dong, P. Zhang, Y. Zang, S. Ding, D. Lin, and J. Wang, “Streaming long video understanding with large language models,” Advances in Neural Information Processing Systems, vol. 37, pp. 119336–119360, 2024
2024
-
[33]
Videollm: Modeling video sequence with large language models
G. Chen, Y.-D. Zheng, J. Wang, J. Xu, Y. Huang, J. Pan, Y. Wang, Y. Wang, Y. Qiao, T. Luet al., “Videollm: Modeling video sequence with large language models,”arXiv:2305.13292, 2023
-
[34]
Videollm-online: Online video large language model for streaming video,
J. Chen, Z. Lv, S. Wu, K. Q. Lin, C. Song, D. Gao, J.-W. Liu, Z. Gao, D. Mao, and M. Z. Shou, “Videollm-online: Online video large language model for streaming video,” inCVPR, 2024, pp. 18407– 18418
2024
-
[35]
Vript: A video is worth thousands of words,
D. Yang, S. Huang, C. Lu, X. Han, H. Zhang, Y. Gao, Y. Hu, and H. Zhao, “Vript: A video is worth thousands of words,”NeurIPS, vol. 37, pp. 57240–57261, 2024
2024
-
[36]
A simple llm framework for long-range video question- answering,
C. Zhang, T. Lu, M. M. Islam, Z. Wang, S. Yu, M. Bansal, and G. Bertasius, “A simple llm framework for long-range video question- answering,” inEMNLP, 2024, pp. 21715–21737
2024
-
[37]
Timechat: A time-sensitive multimodal large language model for long video understanding,
S. Ren, L. Yao, S. Li, X. Sun, and L. Hou, “Timechat: A time-sensitive multimodal large language model for long video understanding,” in CVPR, 2024, pp. 14313–14323
2024
-
[38]
Momentor: Ad- vancing video large language model with fine-grained temporal reasoning,
L.Qian,J.Li,Y.Wu,Y.Ye,H.Fei,T.-S.Chua,Y.Zhuang,andS.Tang, “Momentor: Advancing video large language model with fine-grained temporal reasoning,”arXiv:2402.11435, 2024
-
[39]
Lita: Language instructed temporal-localization assistant,
D.-A. Huang, S. Liao, S. Radhakrishnan, H. Yin, P. Molchanov, Z. Yu, and J. Kautz, “Lita: Language instructed temporal-localization assistant,” inECCV, 2024, pp. 202–218
2024
-
[40]
Self-chained image-language model for video localization and question answering,
S. Yu, J. Cho, P. Yadav, and M. Bansal, “Self-chained image-language model for video localization and question answering,” inNeurIPS, vol. 36, 2023, pp. 76749–76771
2023
-
[41]
Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding,
Y. Guo, J. Liu, M. Li, D. Cheng, X. Tang, D. Sui, Q. Liu, X. Chen, and K. Zhao, “Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding,” inAAAI, vol. 39, no. 3, 2025, pp. 3302–3310
2025
-
[42]
Vtimellm: Empower llm to grasp video moments,
B. Huang, X. Wang, H. Chen, Z. Song, and W. Zhu, “Vtimellm: Empower llm to grasp video moments,” inCVPR, 2024, pp. 14271– 14280
2024
-
[43]
Hawkeye: Training video-text llms for grounding text in videos,
Y. Wang, X. Meng, J. Liang, Y. Wang, Q. Liu, and D. Zhao, “Hawkeye: Training video-text llms for grounding text in videos,” arXiv:2403.10228, 2024
-
[44]
Chat-univi: Unified visual representation empowers large language models with image and video understanding,
P. Jin, R. Takanobu, W. Zhang, X. Cao, and L. Yuan, “Chat-univi: Unified visual representation empowers large language models with image and video understanding,” inCVPR, 2024, pp. 13700–13710
2024
-
[45]
M. Maaz, H. Rasheed, S. Khan, and F. Khan, “Videogpt+: Integrating image and video encoders for enhanced video understanding,” arXiv:2406.09418, 2024
-
[46]
St-llm: Large language models are effective temporal learners,
R. Liu, C. Li, H. Tang, Y. Ge, Y. Shan, and G. Li, “St-llm: Large language models are effective temporal learners,” inECCV, 2024, pp. 1–18
2024
-
[47]
Slot-vlm: Slowfast slots for video-language modeling,
J. Xu, C. Lan, W. Xie, X. Chen, and Y. Lu, “Slot-vlm: Slowfast slots for video-language modeling,”arXiv:2402.13088, 2024
-
[48]
Lstp:Language-guidedspatial-temporalpromptlearningforlong-form video-text understanding,
Y. Wang, Y. Wang, P. Wu, J. Liang, D. Zhao, and Z. Zheng, “Lstp:Language-guidedspatial-temporalpromptlearningforlong-form video-text understanding,”arXiv:2402.16050, 2024. 8
-
[49]
Omnivid: A generative framework for universal video understanding,
J. Wang, D. Chen, C. Luo, B. He, L. Yuan, Z. Wu, and Y.-G. Jiang, “Omnivid: A generative framework for universal video understanding,” inCVPR, 2024, pp. 18209–18220
2024
-
[50]
Vid2seq: Large-scale pretraining of a visual language model for dense video captioning,
A. Yang, A. Nagrani, P. H. Seo, A. Miech, J. Pont-Tuset, I. Laptev, J. Sivic, and C. Schmid, “Vid2seq: Large-scale pretraining of a visual language model for dense video captioning,” inCVPR, 2023, pp. 10714–10726
2023
-
[51]
Drvideo: Document retrieval based long video understanding,
Z. Ma, C. Gou, H. Shi, B. Sun, S. Li, H. Rezatofighi, and J. Cai, “Drvideo: Document retrieval based long video understanding,” in CVPR, 2025, pp. 18936–18946
2025
-
[52]
arXiv preprint arXiv:2504.02438 , year=
C. Cheng, J. Guan, W. Wu, and R. Yan, “Scaling video-language models to 10k frames via hierarchical differential distillation,” arXiv:2504.02438, 2025
-
[53]
Adaptive keyframe sampling for long video understanding,
X. Tang, J. Qiu, L. Xie, Y. Tian, J. Jiao, and Q. Ye, “Adaptive keyframe sampling for long video understanding,” inCVPR, 2025, pp. 29118– 29128
2025
-
[54]
Inimagetrans: Multimodal llm-based text image machine translation,
F. Zuo, K. Chen, Y. Zhang, Z. Xue, and M. Zhang, “Inimagetrans: Multimodal llm-based text image machine translation,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025
2025
-
[55]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Z. Cheng, S. Leng, H. Zhang, Y. Xin, X. Li, G. Chen, Y. Zhu et al., “Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms,”arXiv:2406.07476, 2024
work page internal anchor Pith review arXiv 2024
-
[56]
Audio-visual llm for video understanding,
F. Shu, L. Zhang, H. Jiang, and C. Xie, “Audio-visual llm for video understanding,” inICCV, 2025, pp. 4246–4255
2025
-
[57]
Empowering llms with pseudo-untrimmed videos for audio-visual temporal understanding,
Y. Tang, D. Shimada, J. Bi, M. Feng, H. Hua, and C. Xu, “Empowering llms with pseudo-untrimmed videos for audio-visual temporal understanding,” inAAAI, 2025, pp. 7293–7301
2025
-
[58]
Seamlessm4t: Massively multilingual & multimodal ma- chine translation,
Seamless Communication, L. Barrault, Y.-A. Chung, M. C. Meglioli, D. Dale, N. Dong, P.-A. Duquenne, H. Elsahar, H. Gong, K. Heffernan, J. Hoffman, C. Klaiber, P. Li, D. Licht, J. Maillard, A. Rakotoarison, K. R. Sadagopan, G. Wenzek, E. Ye, B. Akula, P.-J. Chen, N. E. Hachem, B. Ellis, G. M. Gonzalez, J. Haaheim, P. Hansanti, R. Howes, B. Huang, M.-J. Hwa...
-
[59]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y.-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,”TASLP, vol. 29, pp. 3451–3460, 2021
2021
-
[60]
Artemis: Towards referential understanding in complex videos,
J. Qiu, Y. Zhang, X. Tang, L. Xie, T. Ma, P. Yan, D. Doermann, Q. Ye, and Y. Tian, “Artemis: Towards referential understanding in complex videos,” inNeurIPS, vol. 37, 2024, pp. 114321–114347
2024
-
[61]
arXiv preprint arXiv:2404.16994 , year=
L. Xu, Y. Zhao, D. Zhou, Z. Lin, S. K. Ng, and J. Feng, “Pllava: Parameter-free llava extension from images to videos for video dense captioning,”arXiv:2404.16994, 2024
-
[62]
PG-Video-LLaV A: Pixel Grounding Large Video-Language Models.ArXiv 2311.13435, 2023
S. Munasinghe, R. Thushara, M. Maaz, H. A. Rasheed, S. Khan, M. Shah, and F. Khan, “Pg-video-llava: Pixel grounding large video- language models,”arXiv:2311.13435, 2023
-
[63]
Groundinggpt: Language enhanced multi-modal grounding model,
Z. Li, Q. Xu, D. Zhang, H. Song, Y. Cai, Q. Qi, R. Zhou, J. Pan, Z. Li, V. T. Vu, Z. Huang, and T. Wang, “Groundinggpt: Language enhanced multi-modal grounding model,” inACL, 2024, pp. 6657–6678
2024
-
[64]
Vidi: Large multimodal models for video understanding and editing,
V. Team, C. Liu, C.-W. Kuo, D. Du, F. Chen, G. Chen, J. Yuan, L. Zhang, L. Guo, L. Li, L. Wen, Q. Chen, R. Deng, S. Zhu, S. Siew, T. Jin, W. Lu, W. Zhong, X. Shen, X. Gu, X. Mei, X. Qu, and Z. Chen, “Vidi: Large multimodal models for video understanding and editing,” arXiv:2504.15681, 2025
-
[65]
Reef: Relevance-aware and efficient llm adapter for video understanding,
S.Reza,X.Song,H.Yu,Z.Lin,M.Moghaddam,andO.Camps,“Reef: Relevance-aware and efficient llm adapter for video understanding,” in CVPR, 2025, pp. 2592–2603
2025
-
[66]
Video-xl: Extra-long vision language model for hour-scale video understanding,
Y. Shu, Z. Liu, P. Zhang, M. Qin, J. Zhou, Z. Liang, T. Huang, and B. Zhao, “Video-xl: Extra-long vision language model for hour-scale video understanding,” inCVPR, 2025, pp. 26160–26169
2025
-
[67]
Mega-tts 2: Boosting prompting mechanisms for zero-shot speech synthesis,
Z. Jiang, J. Liu, Y. Ren, J. He, Z. Ye, S. Ji, Q. Yang, C. Zhang, P. Wei, C. Wang, X. Yin, Z. Ma, and Z. Zhao, “Mega-tts 2: Boosting prompting mechanisms for zero-shot speech synthesis,” inAAAI, 2024
2024
-
[68]
Z. Du, Q. Chen, S. Zhang, K. Hu, H. Lu, Y. Yang, H. Hu, S. Zheng, Y. Gu, Z. Ma, Z. Gao, and Z. Yan, “Cosyvoice: A scalable multilingual voice generation model,”arXiv:2407.05407, 2024
-
[69]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Z. Du, Y. Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y. Yang, C. Gao, H. Wang, F. Yu, H. Liu, Z. Sheng, Y. Gu, C. Deng, W. Wang, S.Zhang,Z.Yan,andJ.Zhou,“Cosyvoice2:Scalablestreamingspeech synthesis with large language models,”arXiv:2412.10117, 2024
work page internal anchor Pith review arXiv 2024
-
[71]
Prompttts 2: Describing and generating voices with text prompt,
Y. Leng, Z. Guo, K. Shen, X. Tan, Z. Ju, Y. Liu, Y. Liu, D. Yang, L. Zhang, K. Song, S. Zhao, and T. Qin, “Prompttts 2: Describing and generating voices with text prompt,”arXiv:2309.02285, 2023
-
[72]
S. Liao, Y. Wang, T. Li, Y. Cheng, R. Zhang, R. Zhou, and Y. Xing, “Fish-speech: Leveraging large language models for advanced multilingual text-to-speech synthesis,”arXiv:2411.01156, 2024
-
[73]
Hall-e: Hierarchical neural codec language model for minute-long zero-shot text-to-speech synthesis,
K. Nishimura, Y. Inoue, K. Kondo, Y. Shibata, K. Abe, T. Kashiwagi, M. Nagira, and R. Tanaka, “Hall-e: Hierarchical neural codec language model for minute-long zero-shot text-to-speech synthesis,” arXiv:2410.04380, 2024
-
[74]
Voxinstruct: Expressive human instruction-to-speech generation with unified multilingual codec language modelling,
Y. Zhou, X. Qin, Z. Jin, S. Zhou, S. Lei, S. Zhou, Z. Wu, and J. Jia, “Voxinstruct: Expressive human instruction-to-speech generation with unified multilingual codec language modelling,” inACM MM, 2024, pp. 554–563
2024
-
[75]
Y. Wang, K. Zhang, Q. Chen, Z. Du, H. Liu, F. Yu, H. Wang, and J. Zhou, “Spark-tts: An efficient llm-based text-to-speech model with single-stream decoupled speech tokens,”arXiv:2503.01710, 2025
-
[76]
Instructtts: Modelling expressive tts in discrete latent space with natural language style prompt,
D. Yang, S. Liu, R. Huang, C. Weng, and H. Meng, “Instructtts: Modelling expressive tts in discrete latent space with natural language style prompt,”arXiv:2301.13662, 2023
-
[77]
Emo- dpo: Controllable emotional speech synthesis through direct preference optimization,
X. Gao, C. Zhang, Y. Chen, H. Zhang, and N. F. Chen, “Emo- dpo: Controllable emotional speech synthesis through direct preference optimization,”arXiv:2409.10157, 2024
-
[78]
P. Anastassiou, J. Chen, J. Chen, Y. Chen, Z. Chen, Z. Chen, J. Cong, L. Deng, C. Ding, L. Gao, M. Gong, P. Huang, Q. Huang, Z. Huang, Y. Huo, D. Jia, C. Li, F. Li, H. Li, J. Li, X. Li, X. Li, L. Liu, S. Liu, S. Liu, X. Liu, Y. Liu, Z. Liu, L. Lu, J. Pan, X. Wang, Y. Wang, Y. Wang, Z. Wei, J. Wu, C. Yao, Y. Yang, Y. Yi, J. Zhang, Q. Zhang, S. Zhang, W. Zh...
-
[79]
Z. Jiang, Y. Ren, R. Li, S. Ji, B. Zhang, Z. Ye, C. Zhang, J. Bai, X. Yang, and Z. Zhao, “Megatts 3: Sparse alignment enhanced latent diffusion transformer for zero-shot speech synthesis,” arXiv:2502.18924, 2025
-
[80]
F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching,
Y. Chen, Z. Niu, Z. Ma, K. Deng, C. Wang, J. Zhao, K. Yu, and X. Chen, “F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching,” inACL, 2025, pp. 6255–6271
2025
-
[81]
E2 TTS: embarrassingly easy fully non-autoregressive zero-shot TTS
S. E. Eskimez, X. Wang, M. Thakker, C. Li, C.-H. Tsai, Z. Xiao, H. Yang, Z. Zhu, M. Tang, X. Tan, Y. Liu, H. Wang, and S. Zhao, “E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts,” arXiv:2406.18009, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.