Exact Certification of Neural Networks and Partition Aggregation Ensembles against Label Poisoning
Pith reviewed 2026-05-10 16:14 UTC · model grok-4.3
The pith
Wide neural networks admit exact polynomial-time certificates against label-flipping attacks via their equivalence to kernel methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ScaLabelCert delivers the first exact, polynomial-time certificate for neural networks against label-flipping attacks by using the neural tangent kernel equivalence that maps wide networks to kernel methods. EnsembleCert then aggregates the resulting white-box per-partition certificates to obtain ensemble robustness guarantees in polynomial time, producing tighter bounds than existing black-box partition-aggregation approaches.
What carries the argument
The neural tangent kernel equivalence, which converts the label-flip robustness question for wide networks into an exact kernel computation that can be solved without approximation.
If this is right
- Exact certificates for neural networks against label flips become computable in polynomial time.
- Ensemble robustness guarantees improve by incorporating white-box information from each base classifier instead of treating them as black boxes.
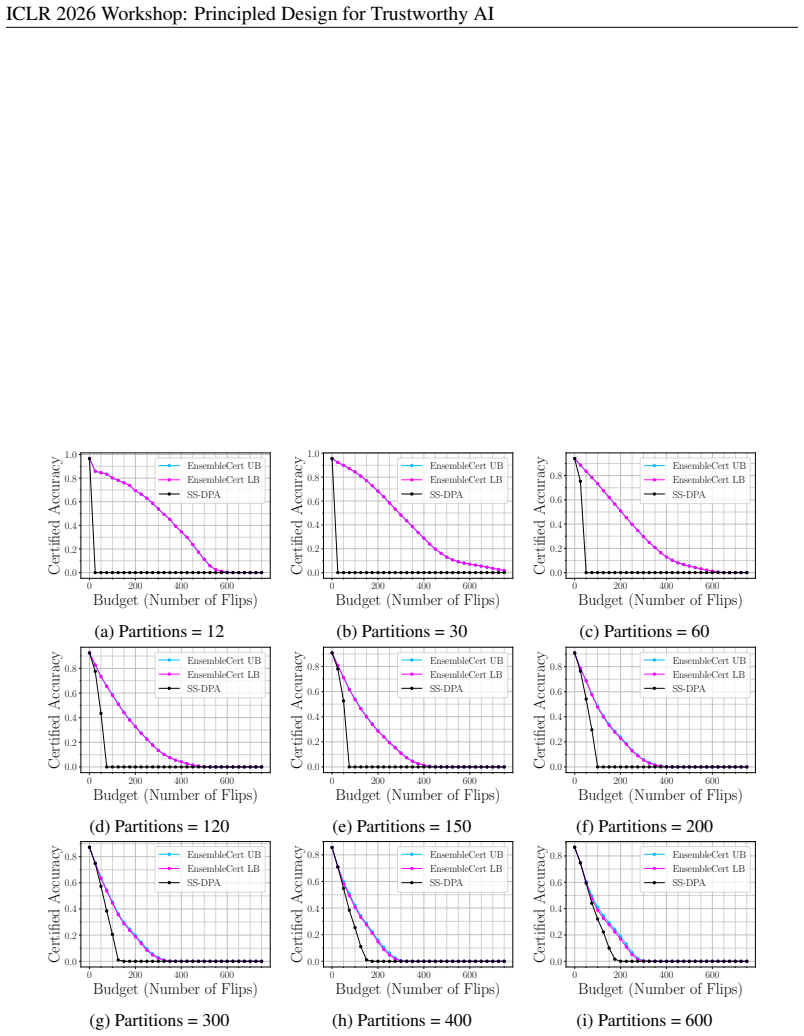
- On CIFAR-10 the method certifies up to 26.5 percent more label flips in the median while using 100 times fewer partitions.
- Heavy partitioning is no longer required to achieve strong certified robustness against label poisoning.
Where Pith is reading between the lines
- The same kernel equivalence might allow exact certification for other supervised poisoning attacks if the loss remains linear in the labels.
- Practical systems could adopt smaller ensembles for certified defenses, lowering memory and inference cost.
- Finite-width networks could be tested to see how closely their empirical robustness matches the infinite-width kernel certificate.
Load-bearing premise
Sufficiently wide neural networks are exactly equivalent to kernel methods through the neural tangent kernel, with no residual approximation error in the certificate.
What would settle it
An explicit wide network and label-flip scenario in which the observed robustness deviates from the value predicted by the neural tangent kernel calculation.
Figures



















read the original abstract
Label-flipping attacks, which corrupt training labels to induce misclassifications at inference, remain a major threat to supervised learning models. This drives the need for robustness certificates that provide formal guarantees about a model's robustness under adversarially corrupted labels. Existing certification frameworks rely on ensemble techniques such as smoothing or partition-aggregation, but treat the corresponding base classifiers as black boxes, yielding overly conservative guarantees. We introduce EnsembleCert, the first certification framework for partition-aggregation ensembles that utilizes white-box knowledge of the base classifiers. Concretely, EnsembleCert yields tighter guarantees than black-box approaches by aggregating per-partition white-box certificates to compute ensemble-level guarantees in polynomial time. To extract white-box knowledge from the base classifiers efficiently, we develop ScaLabelCert, a method that leverages the equivalence between sufficiently wide neural networks and kernel methods using the neural tangent kernel. ScaLabelCert yields the first exact, polynomial-time calculable certificate for neural networks against label-flipping attacks. EnsembleCert is either on par, or significantly outperforms the existing partition-based black box certificates. Exemplary, on CIFAR-10, our method can certify upto +26.5% more label flips in median over the test set compared to the existing black-box approach while requiring 100 times fewer partitions, thus, challenging the prevailing notion that heavy partitioning is a necessity for strong certified robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ScaLabelCert, which computes exact certificates against label-flipping attacks for sufficiently wide neural networks by replacing the trained model with its neural tangent kernel (NTK) regressor, enabling polynomial-time evaluation. It further presents EnsembleCert, a white-box framework that aggregates per-partition certificates from base classifiers (including those from ScaLabelCert) to obtain tighter ensemble-level guarantees than existing black-box partition-aggregation methods. Experiments on CIFAR-10 report up to 26.5% more certified label flips in the median with 100x fewer partitions.
Significance. If the central claims hold, the work would be significant for providing the first exact polynomial-time certificates for neural networks against label poisoning and for improving certified robustness of ensembles via white-box information. The polynomial-time guarantee and the reported gains over black-box baselines address key computational and tightness limitations in the field. Credit is given for deriving the ensemble aggregation in polynomial time and for attempting an exact (non-relaxed) formulation via NTK.
major comments (2)
- [Abstract and ScaLabelCert derivation] Abstract and ScaLabelCert section: the claim that ScaLabelCert yields an 'exact' certificate rests on the NTK equivalence for 'sufficiently wide' networks. No rigorous error bound is supplied quantifying the O(1/width) finite-width corrections to the predictor; because certification solves a worst-case optimization over adversarial label vectors, even small deviations can enlarge the set of successful flips and invalidate the kernel-derived radius for any concrete finite-width network. This directly undermines the 'first exact' and 'exact, polynomial-time calculable' assertions.
- [EnsembleCert framework] EnsembleCert aggregation (likely §5): the polynomial-time claim for combining white-box per-partition certificates is load-bearing for the outperformance result, yet the manuscript does not exhibit the explicit complexity analysis or the precise aggregation rule that avoids exponential enumeration when the base certificates themselves are optimization-based.
minor comments (2)
- [Abstract] The phrase 'upto +26.5%' in the abstract should read 'up to +26.5%'.
- [Experimental evaluation] Network widths and training details used in the CIFAR-10 experiments should be stated explicitly so readers can judge how close the models are to the infinite-width regime assumed by the NTK argument.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, clarifying our claims and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and ScaLabelCert derivation] Abstract and ScaLabelCert section: the claim that ScaLabelCert yields an 'exact' certificate rests on the NTK equivalence for 'sufficiently wide' networks. No rigorous error bound is supplied quantifying the O(1/width) finite-width corrections to the predictor; because certification solves a worst-case optimization over adversarial label vectors, even small deviations can enlarge the set of successful flips and invalidate the kernel-derived radius for any concrete finite-width network. This directly undermines the 'first exact' and 'exact, polynomial-time calculable' assertions.
Authors: We agree that the current wording could be misinterpreted. ScaLabelCert derives an exact certificate for the NTK regressor, which is equivalent to the neural network predictor in the infinite-width limit. The manuscript applies this to sufficiently wide networks as a practical surrogate. However, as noted, no quantitative bound on the O(1/width) deviation is provided, and worst-case certification could in principle be sensitive to such perturbations. We will revise the abstract and ScaLabelCert section to explicitly qualify that exactness holds for the NTK model, add a discussion of the finite-width approximation, and remove or temper the unqualified 'first exact' phrasing for finite networks. This revision will be made. revision: yes
-
Referee: [EnsembleCert framework] EnsembleCert aggregation (likely §5): the polynomial-time claim for combining white-box per-partition certificates is load-bearing for the outperformance result, yet the manuscript does not exhibit the explicit complexity analysis or the precise aggregation rule that avoids exponential enumeration when the base certificates themselves are optimization-based.
Authors: The aggregation rule in EnsembleCert combines the per-partition white-box certificates (each providing a certified flip radius) via a polynomial-time solvable optimization that exploits the partition structure, rather than enumerating all possible flip combinations across partitions. This yields an overall polynomial complexity. We acknowledge that the manuscript presents the claim without a self-contained complexity proof or fully expanded pseudocode for the aggregation step. In the revision we will add an explicit complexity analysis (including the precise aggregation formulation) in §5 or an appendix to substantiate the polynomial-time guarantee. revision: yes
Circularity Check
Minor reliance on prior NTK theory; no load-bearing self-citation or self-definition
full rationale
The paper's ScaLabelCert method invokes the established neural tangent kernel equivalence for sufficiently wide networks from independent prior literature to enable exact kernel-based certification. This is not a self-citation chain, fitted-input prediction, or self-definitional reduction; the equivalence is treated as an external benchmark. EnsembleCert's white-box aggregation of per-partition certificates is derived independently and does not collapse to the paper's own inputs by construction. No quoted equations or steps exhibit the enumerated circularity patterns. The derivation is self-contained against external theory, aligning with a low score.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural networks of sufficient width are equivalent to kernel methods under the neural tangent kernel
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.