Recognition: unknown
Please Make it Sound like Human: Encoder-Decoder vs. Decoder-Only Transformers for AI-to-Human Text Style Transfer
Pith reviewed 2026-05-10 14:55 UTC · model grok-4.3
The pith
BART-large outperforms the much larger Mistral-7B when rewriting AI-generated text to sound human.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When fine-tuned on a parallel corpus of 25,140 AI-to-human text pairs, BART-large reaches BERTScore F1 of 0.924, ROUGE-L of 0.566, and chrF++ of 55.92, outperforming Mistral-7B in reference similarity while using far fewer parameters. The analysis shows Mistral-7B's stronger shift in the 11 stylistic markers is an overshoot, not superior performance, exposing a blind spot in style transfer metrics that focus only on the amount of change rather than its accuracy.
What carries the argument
The parallel corpus of AI-generated and human text pairs together with the eleven stylistic markers used both for training targets and evaluation.
If this is right
- Encoder-decoder models offer a more efficient solution for this style transfer task than scaling up decoder-only models.
- Marker shift scores can misleadingly favor models that overshoot the desired human style instead of matching it precisely.
- Reference-based automatic metrics like BERTScore better capture the success of making AI text sound human than marker shift alone.
- The fine-tuned BART-large can be deployed in tools to humanize AI writing in academic and professional contexts with lower computational cost.
Where Pith is reading between the lines
- For style transfer tasks requiring fine control, model architecture may matter more than raw size, suggesting experiments with other encoder-decoder variants.
- Evaluation protocols for AI-to-human rewriting should include tests for whether changes hit the human style or go beyond it.
- This approach could be extended to other domains like creative writing or code comments where subtle stylistic adjustments are needed.
Load-bearing premise
The eleven stylistic markers comprehensively capture the essence of what makes text sound human-written rather than AI-generated, and the parallel corpus of 25,140 pairs is free of biases that would skew the training or evaluation.
What would settle it
A blind test in which human raters consistently judge the fine-tuned Mistral-7B outputs as more convincingly human-like than the BART-large outputs would falsify the claim that reference similarity scores indicate better style transfer.
Figures


read the original abstract
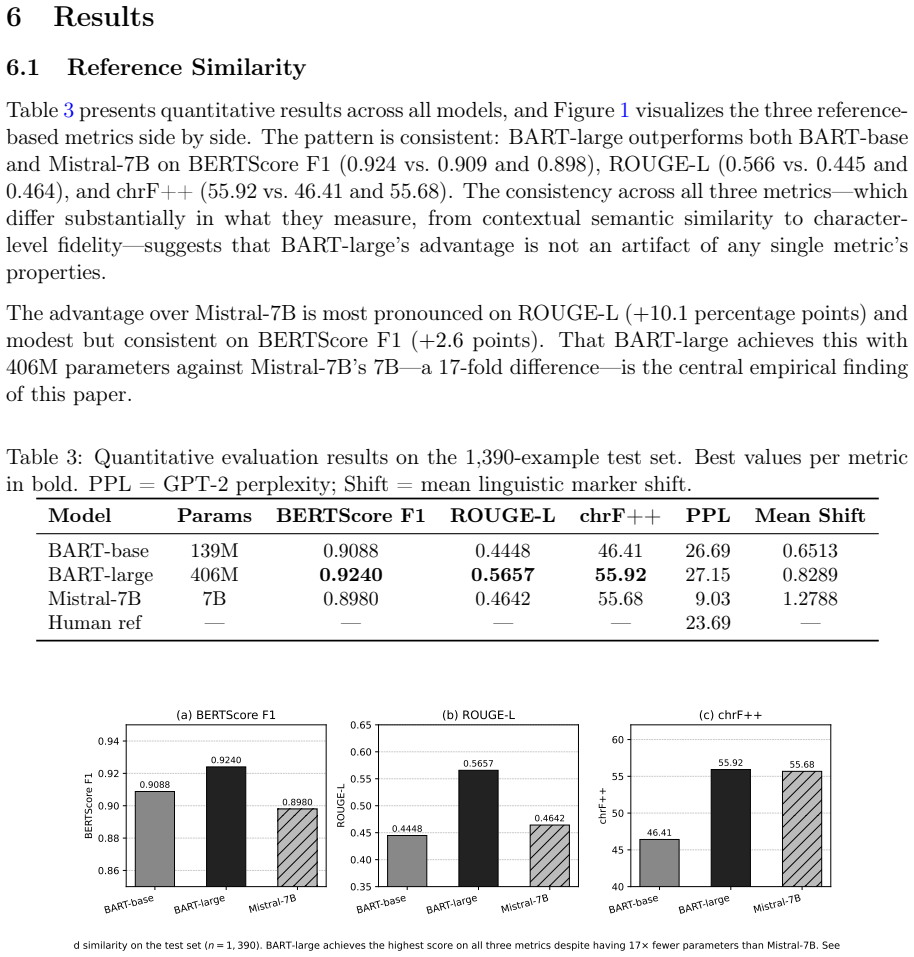
AI-generated text has become common in academic and professional writing, prompting research into detection methods. Less studied is the reverse: systematically rewriting AI-generated prose to read as genuinely human-authored. We build a parallel corpus of 25,140 paired AI-input and human-reference text chunks, identify 11 measurable stylistic markers separating the two registers, and fine-tune three models: BART-base, BART-large, and Mistral-7B-Instruct with QLoRA. BART-large achieves the highest reference similarity -- BERTScore F1 of 0.924, ROUGE-L of 0.566, and chrF++ of 55.92 -- with 17x fewer parameters than Mistral-7B. We show that Mistral-7B's higher marker shift score reflects overshoot rather than accuracy, and argue that shift accuracy is a meaningful blind spot in current style transfer evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript constructs a parallel corpus of 25,140 AI-generated and human-reference text pairs, identifies 11 stylistic markers distinguishing the registers, and fine-tunes BART-base, BART-large, and Mistral-7B-Instruct (QLoRA) for AI-to-human style transfer. It reports BART-large achieving the highest reference similarity (BERTScore F1 0.924, ROUGE-L 0.566, chrF++ 55.92) with 17x fewer parameters than Mistral-7B, interprets Mistral's higher marker shift score as overshoot rather than accuracy, and argues that shift accuracy is an overlooked aspect of style transfer evaluation.
Significance. If the corpus and markers prove robust, the work would be significant for NLP style transfer research by providing a direct architecture comparison showing smaller encoder-decoder models outperforming larger decoder-only ones on reference metrics, while highlighting a blind spot in marker-shift evaluation. The concrete automatic metrics and cross-model analysis supply useful empirical baselines, and the overshoot interpretation could prompt more nuanced evaluation protocols.
major comments (3)
- [Abstract and §3 (Corpus Construction)] Abstract and corpus construction: The 25,140-pair parallel corpus is introduced only at high level ('we build a parallel corpus of 25,140 paired AI-input and human-reference text chunks') with no description of source texts, generation prompts, content/length matching between AI and human sides, or bias checks. This is load-bearing for the central claim, as selection biases could systematically favor BART's reported similarity scores and the marker-shift interpretation.
- [Abstract and §4 (Marker Identification)] Marker identification and shift score: The 11 stylistic markers are stated to have been 'identified' but no statistical criterion, feature selection method, or held-out validation is provided. Because the marker shift score is computed directly from these same markers and used to argue that Mistral's higher score reflects 'overshoot rather than accuracy,' the interpretation risks circularity and lacks external grounding.
- [§5 (Experiments and Results)] Evaluation protocol: Results give point estimates for BERTScore, ROUGE-L, and chrF++ with no error bars, multiple seeds, or statistical tests. No human evaluation of transferred text is reported, which is required to substantiate claims about sounding 'like human' and to distinguish overshoot from genuine accuracy.
minor comments (2)
- [§4] Define the marker shift score formula explicitly on first use and clarify whether it is normalized or absolute.
- [References] Add citations for the automatic metrics (BERTScore, ROUGE-L, chrF++) and for prior style-transfer corpora if not already present.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for improving the clarity, rigor, and evaluation of our work on AI-to-human style transfer. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and §3 (Corpus Construction)] The 25,140-pair parallel corpus is introduced only at high level ('we build a parallel corpus of 25,140 paired AI-input and human-reference text chunks') with no description of source texts, generation prompts, content/length matching between AI and human sides, or bias checks. This is load-bearing for the central claim, as selection biases could systematically favor BART's reported similarity scores and the marker-shift interpretation.
Authors: We agree that additional details on corpus construction are necessary to ensure reproducibility and to rule out potential biases. In the revised manuscript, we will expand Section 3 with a detailed description of the source texts used, the specific generation prompts employed for creating the AI-generated texts, the methods for matching content and length between AI and human pairs, and any bias checks or analyses performed. This will directly address concerns about selection biases affecting the similarity scores and marker interpretations. revision: yes
-
Referee: [Abstract and §4 (Marker Identification)] Marker identification and shift score: The 11 stylistic markers are stated to have been 'identified' but no statistical criterion, feature selection method, or held-out validation is provided. Because the marker shift score is computed directly from these same markers and used to argue that Mistral's higher score reflects 'overshoot rather than accuracy,' the interpretation risks circularity and lacks external grounding.
Authors: We acknowledge the risk of circularity in our marker-based evaluation. The markers were derived from a combination of prior literature on linguistic differences between AI and human text and empirical analysis. To strengthen this, in the revision we will provide the statistical criteria used for identification (such as significance tests on frequency differences), the feature selection approach, and results from validation on a held-out set of data. This will provide external grounding for the marker shift score and support our interpretation that higher shift in Mistral reflects overshoot. revision: yes
-
Referee: [§5 (Experiments and Results)] Evaluation protocol: Results give point estimates for BERTScore, ROUGE-L, and chrF++ with no error bars, multiple seeds, or statistical tests. No human evaluation of transferred text is reported, which is required to substantiate claims about sounding 'like human' and to distinguish overshoot from genuine accuracy.
Authors: We agree that reporting variability and conducting statistical tests would enhance the reliability of our results. We will update the experiments section to include multiple random seeds, report means with standard deviations or error bars, and perform appropriate statistical tests (e.g., paired t-tests) to compare model performances. For human evaluation, we recognize its value in validating human-likeness and distinguishing overshoot. Although not included originally due to time and resource limitations, we will conduct and report a human evaluation study in the revised version to provide qualitative support for our claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core claims rest on empirical evaluation of fine-tuned models against held-out human references using independent metrics (BERTScore, ROUGE-L, chrF++). The 11 stylistic markers are used to construct the parallel corpus and to compute an auxiliary marker-shift analysis, but this does not reduce the reference-similarity rankings or the overshoot interpretation to the markers by construction; the primary evidence remains external to the marker definitions. No self-citations, uniqueness theorems, or fitted parameters renamed as predictions appear in the load-bearing steps. The derivation chain is therefore self-contained against standard external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Number of stylistic markers
- QLoRA configuration
axioms (2)
- domain assumption The 11 stylistic markers reliably separate AI-generated from human text across domains.
- domain assumption Automatic reference-based metrics (BERTScore, ROUGE-L, chrF++) correlate with human judgments of style transfer success.
Reference graph
Works this paper leans on
-
[1]
Eric Mitchell et al. DetectGPT: Zero-shot machine-generated text detection using proba- bility curvature.arXiv:2301.11305, 2023. 11
-
[2]
Shangqing Tu, Yuliang Sun, Yushi Bai, Jifan Yu, Lei Hou, and Juanzi Li
Ruixiang Tang, Yusen Chuang, and Xia Hu. The science of detecting LLM-generated text. arXiv:2303.07205, 2023
-
[3]
How close is ChatGPT to human experts? Comparison corpus, evaluation, and detection
Biyang Guo et al. How close is ChatGPT to human experts?arXiv:2301.07597, 2023
-
[4]
Deep learning for text style transfer: A survey.Computational Linguistics, 48(1):155–205, 2022
Di Jin et al. Deep learning for text style transfer: A survey.Computational Linguistics, 48(1):155–205, 2022
2022
-
[5]
Dear sir or madam, may i introduce the GYAFC dataset
Sudha Rao and Joel Tetreault. Dear sir or madam, may i introduce the GYAFC dataset. InProceedings of NAACL, 2018
2018
-
[6]
Style transfer from non-parallel text by cross-alignment
Tianxiao Shen et al. Style transfer from non-parallel text by cross-alignment. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[7]
Author obfuscation using generalizable writing style
Anna Wegmann and Dong Nguyen. Author obfuscation using generalizable writing style. arXiv:2210.07743, 2022
-
[8]
BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension
Mike Lewis et al. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. InProceedings of ACL, 2020
2020
-
[9]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020
Colin Raffel et al. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020
2020
-
[10]
Language models are unsupervised multitask learners.OpenAI Blog, 2019
Alec Radford et al. Language models are unsupervised multitask learners.OpenAI Blog, 2019
2019
-
[11]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron et al. LLaMA: Open and efficient foundation language models. arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Albert Q. Jiang et al. Mistral 7b.arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
QLoRA: Efficient Finetuning of Quantized LLMs
Tim Dettmers et al. QLoRA: Efficient finetuning of quantized LLMs.arXiv:2305.14314, 2023
work page internal anchor Pith review arXiv 2023
-
[14]
BERTScore: Evaluating Text Generation with BERT
Tianyi Zhang et al. BERTScore: Evaluating text generation with BERT.arXiv:1904.09675, 2019. 12
work page internal anchor Pith review arXiv 1904
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.