Recognition: unknown
LARY: A Latent Action Representation Yielding Benchmark for Generalizable Vision-to-Action Alignment
Pith reviewed 2026-05-10 16:32 UTC · model grok-4.3
The pith
General visual foundation models without action supervision outperform specialized latent action models at turning vision into physical actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
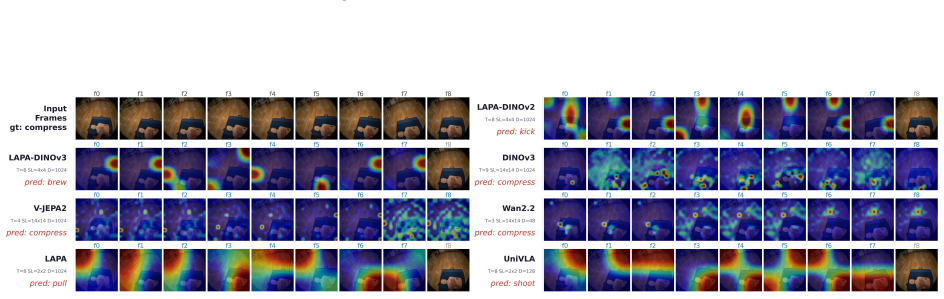
Experiments on the introduced benchmark reveal that general visual foundation models, trained without any action supervision, consistently outperform specialized embodied latent action models. Latent-based visual space is fundamentally better aligned to physical action space than pixel-based space. These results indicate that general visual representations inherently encode action-relevant knowledge for physical control and that semantic-level abstraction serves as a more effective pathway from vision to action than pixel-level reconstruction.
What carries the argument
The LARY benchmark, a unified evaluation framework that measures latent action representations on high-level semantic action categories and low-level robotic control using a dataset of over one million videos plus hundreds of thousands of image pairs and motion trajectories.
If this is right
- General visual representations can support robust control from visual observations without dedicated action training.
- Semantic abstraction in latent spaces forms a better route to physical actions than direct pixel reconstruction.
- Unlabeled human action videos at scale are sufficient to extract features useful for physical control.
- Specialized training on embodied data is not required to achieve strong vision-to-action performance.
Where Pith is reading between the lines
- This finding suggests that scaling general visual pretraining alone could improve robotic systems without the need for new action-labeled datasets.
- The advantage of latent over pixel spaces may apply to control tasks in environments or robots not covered by the current data.
- Developers could try applying these general models to real robots with little or no extra action-specific adjustment to check for immediate gains.
- Further tests could measure whether even larger general visual models continue to improve results on the same semantic and control metrics.
Load-bearing premise
The curated dataset and its two evaluation metrics for semantic actions and robotic control measure generalizable vision-to-action alignment without biases from how the data was chosen or how success is scored.
What would settle it
Running the same benchmark and finding that a specialized embodied latent action model scores higher than general visual foundation models on the robotic control tasks would show the central claim is not correct.
Figures
















read the original abstract
While the shortage of explicit action data limits Vision-Language-Action (VLA) models, human action videos offer a scalable yet unlabeled data source. A critical challenge in utilizing large-scale human video datasets lies in transforming visual signals into ontology-independent representations, known as latent actions. However, the capacity of latent action representation to derive robust control from visual observations has yet to be rigorously evaluated. We introduce the Latent Action Representation Yielding (LARY) Benchmark, a unified framework for evaluating latent action representations on both high-level semantic actions (what to do) and low-level robotic control (how to do). The comprehensively curated dataset encompasses over one million videos (1,000 hours) spanning 151 action categories, alongside 620K image pairs and 595K motion trajectories across diverse embodiments and environments. Our experiments reveal two crucial insights: (i) General visual foundation models, trained without any action supervision, consistently outperform specialized embodied latent action models. (ii) Latent-based visual space is fundamentally better aligned to physical action space than pixel-based space. These results suggest that general visual representations inherently encode action-relevant knowledge for physical control, and that semantic-level abstraction serves as a fundamentally more effective pathway from vision to action than pixel-level reconstruction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the LARY benchmark, a large-scale dataset of over 1M human action videos (1,000 hours, 151 categories), 620K image pairs, and 595K motion trajectories across embodiments, to evaluate latent action representations on both high-level semantic action classification and low-level robotic control tasks. Experiments compare general visual foundation models (no action supervision) against specialized embodied latent action models, concluding that the former consistently outperform the latter and that latent visual spaces are fundamentally better aligned to physical action than pixel-based spaces.
Significance. If the benchmark controls for curation artifacts, the results would indicate that general visual representations already encode substantial action-relevant structure, supporting a shift away from action-specific pretraining in VLA models. The dual-metric design (semantic + control) is a positive step toward more comprehensive evaluation.
major comments (2)
- [§3] §3 (LARY Dataset Curation): The description of category selection, embodiment sampling, and trajectory collection does not report ablations on pixel-level visual variation or balanced controls across environments; without these, the observed superiority of latent spaces over pixel-based ones could arise from curation choices that prioritize semantic abstraction rather than intrinsic alignment properties.
- [§5] §5 (Experiments and Metrics): The dual evaluation (semantic action classification and robotic control success) lacks reported controls for metric weighting or embodiment-specific artifacts; the claim that latent visual space is 'fundamentally better aligned' (abstract and §5) therefore rests on untested assumptions about how the 595K trajectories and 620K pairs were constructed.
minor comments (2)
- [Table 1] Table 1 and Figure 3: axis labels and legend entries use inconsistent abbreviations for model names; standardize to full names or a clear key for readability.
- [§2] §2 (Related Work): several recent VLA papers on general visual pretraining are cited only by arXiv number; add full bibliographic details.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the LARY benchmark. We address the concerns about potential curation artifacts and untested assumptions in the evaluation design below. We will revise the manuscript to incorporate additional controls, statistics, and moderated language where appropriate to strengthen the presentation of results.
read point-by-point responses
-
Referee: §3 (LARY Dataset Curation): The description of category selection, embodiment sampling, and trajectory collection does not report ablations on pixel-level visual variation or balanced controls across environments; without these, the observed superiority of latent spaces over pixel-based ones could arise from curation choices that prioritize semantic abstraction rather than intrinsic alignment properties.
Authors: We agree that explicit ablations on pixel-level visual variation and balanced environmental controls would help isolate intrinsic alignment from curation effects. The original curation prioritized diversity across 151 categories, embodiments, and environments using standard sampling from public sources, but dedicated ablations were not included. In the revised version, we will expand §3 with quantitative statistics on visual diversity (e.g., scene complexity metrics) and report performance on a controlled data subset minimizing pixel-level variations. This will clarify that latent-space advantages persist under tighter controls. revision: yes
-
Referee: §5 (Experiments and Metrics): The dual evaluation (semantic action classification and robotic control success) lacks reported controls for metric weighting or embodiment-specific artifacts; the claim that latent visual space is 'fundamentally better aligned' (abstract and §5) therefore rests on untested assumptions about how the 595K trajectories and 620K pairs were constructed.
Authors: The dual metrics are evaluated independently without explicit weighting, as described in §5, using the same 595K trajectories and 620K pairs for all models to ensure fair comparison. These were constructed via consistent pipelines from standard datasets. We acknowledge the value of embodiment-specific controls. In revision, we will add per-embodiment performance breakdowns and sensitivity analysis on metric combinations. We will also revise the phrasing in the abstract and §5 from 'fundamentally better aligned' to 'empirically better aligned within the evaluated settings' to better reflect the benchmark's scope. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or self-referential predictions
full rationale
The paper introduces the LARY benchmark and reports experimental comparisons showing general visual foundation models outperforming specialized latent action models, plus latent space alignment advantages. No equations, fitted parameters, or derivation chains exist that reduce by construction to inputs (e.g., no self-definitional quantities, no predictions that are statistically forced from fits, no uniqueness theorems imported via self-citation). The central claims rest on dataset curation and dual metrics, which are externally falsifiable via replication on held-out data and do not rely on self-citation chains for their validity. This is a standard empirical benchmark paper whose results are independent of any internal redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human action videos provide a scalable source of unlabeled data that can be transformed into ontology-independent latent actions useful for robotic control.
Forward citations
Cited by 1 Pith paper
-
RotVLA: Rotational Latent Action for Vision-Language-Action Model
RotVLA models latent actions as continuous SO(n) rotations with triplet-frame supervision and flow-matching to reach 98.2% success on LIBERO and 89.6%/88.5% on RoboTwin2.0 using a 1.7B-parameter model.
Reference graph
Works this paper leans on
-
[1]
doi:10.1109/LRA.2022.3180108. Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, et al. Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 111...
-
[2]
This process yields a massive corpus of short video clips, each paired with a brief, sentence-level action annotation describing the ongoing interaction
Action Segmentation:Initially, we perform temporal action segmentation on the raw video sequences using the API. This process yields a massive corpus of short video clips, each paired with a brief, sentence-level action annotation describing the ongoing interaction
-
[3]
Clips are retained strictly based on three criteria: (i)Temporal validity:Clip durations must fall within the [0.5s, 20s] interval
Video-Description Matching:Given the inevitable noise from automated cropping and preliminary captioning, we implement a rigorous API-driven filtering protocol to sift the initial clips. Clips are retained strictly based on three criteria: (i)Temporal validity:Clip durations must fall within the [0.5s, 20s] interval. This discards clips that are too short...
2025
-
[4]
Video-Verb Consistency Check:To eliminate semantic ambiguity and ensure that the isolated verb accurately encapsulates the visual content, we conduct a secondary API-based verification. This step explicitly evaluates whether the single verb token alone maintains strict visual-semantic alignment with the corresponding video clip, discarding any poorly corr...
-
[5]
Manual Sampling Inspection:Finally, we perform a manual quality assurance review to exclude verbs that lack explicit or well-defined kinematic meanings. Action categories representing overly abstract or kinematically ambiguous operations (e.g.,apply,arrange,clean) are systematically purged from the taxonomy to maintain the physical and dynamic rigor of th...
-
[6]
- Mismatch if: The video is missing parts of the action, OR contains any additional, unrelated actions before, during, or after
Strict Verification: Does the video content EXCLUSIVELY represent the description {old_desc}? - Match if: The video contains the described action and NOTHING else. - Mismatch if: The video is missing parts of the action, OR contains any additional, unrelated actions before, during, or after
-
[7]
Identify perspective: ’1st’ (ego) or ’3rd’ (non-ego)
-
[8]
perspective
Final Action: If and only if it’s a STRICT match, provide ONE most precise English verb defining the movement, not limited to the exact word in the description (e.g., ’take’); Otherwise, return ’None’. Return ONLY JSON: {{"perspective": "1st/3rd", "action": "verb/None"}} [Video-Verb Consistency Check Prompt] <video_1>Please watch this video and determine ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.