Recognition: unknown
Seeing Through the Tool: A Controlled Benchmark for Occlusion Robustness in Foundation Segmentation Models
Pith reviewed 2026-05-10 16:20 UTC · model grok-4.3
The pith
SAM-family models exhibit distinct occlusion behaviors, with some focusing on visible tissue and others inferring occluded anatomy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
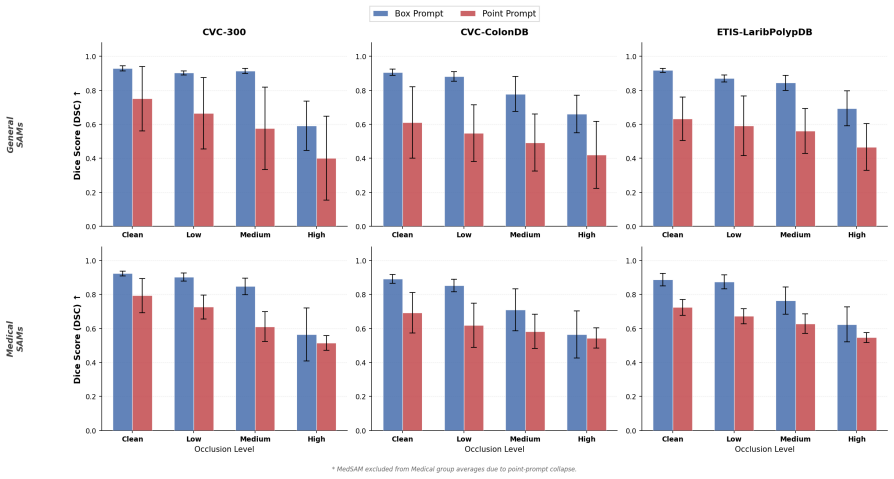
The central discovery is that occlusion robustness varies across SAM-family architectures. Occluder-Aware models such as SAM, SAM 2, SAM 3, and MedSAM3 prioritize delineating only the visible tissue and reject instruments, while Occluder-Agnostic models like MedSAM and MedSAM2 confidently segment into occluded regions. SAM-Med2D underperforms in all tested conditions. The three-region protocol exposes these differences that standard evaluation misses.
What carries the argument
A three-region evaluation protocol that breaks down segmentation performance into full target, visible-only, and invisible target regions to reveal model behaviors under occlusion.
Load-bearing premise
Synthesized occlusions from surgical tool overlays and cutouts on polyp datasets accurately reflect the conditions and effects of real-world occlusions in clinical endoscopy procedures.
What would settle it
If evaluation on actual endoscopic videos with natural occlusions fails to reproduce the same division into occluder-aware and occluder-agnostic model groups, the benchmark's conclusions about model archetypes would not hold.
Figures



read the original abstract
Occlusion, where target structures are partially hidden by surgical instruments or overlapping tissues, remains a critical yet underexplored challenge for foundation segmentation models in clinical endoscopy. We introduce OccSAM-Bench, a benchmark designed to systematically evaluate SAM-family models under controlled, synthesized surgical occlusion. Our framework simulates two occlusion types (i.e., surgical tool overlay and cutout) across three calibrated severity levels on three public polyp datasets. We propose a novel three-region evaluation protocol that decomposes segmentation performance into full, visible-only, and invisible targets. This metric exposes behaviors that standard amodal evaluation obscures, revealing two distinct model archetypes: Occluder-Aware models (SAM, SAM 2, SAM 3, MedSAM3), which prioritize visible tissue delineation and reject instruments, and Occluder-Agnostic models (MedSAM, MedSAM2), which confidently predict into occluded regions. SAM-Med2D aligns with neither and underperforms across all conditions. Ultimately, our results demonstrate that occlusion robustness is not uniform across architectures, and model selection must be driven by specific clinical intent-whether prioritizing conservative visible-tissue segmentation or the amodal inference of hidden anatomy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OccSAM-Bench, a controlled benchmark evaluating SAM-family models (including SAM, SAM 2, SAM 3, MedSAM variants, and SAM-Med2D) on polyp segmentation under synthesized surgical occlusions. It applies two occlusion types (tool overlay and cutout) at three calibrated severity levels to public polyp datasets and proposes a three-region protocol decomposing performance into full, visible-only, and invisible targets. This reveals two archetypes—Occluder-Aware models that prioritize visible tissue and reject instruments versus Occluder-Agnostic models that confidently inpaint occluded regions—with SAM-Med2D as an outlier; the work concludes that occlusion robustness is non-uniform and model choice should follow clinical intent for conservative visible versus amodal hidden anatomy segmentation.
Significance. The three-region protocol is a clear strength, as it systematically exposes model behaviors that standard amodal metrics would obscure, providing a reproducible way to characterize foundation model responses to occlusion in medical imaging. If the synthetic conditions prove representative, the archetype distinction offers practical guidance for selecting models in endoscopy. However, the clinical implications are only partially grounded without evidence that the controlled synthesis captures real occlusion physics.
major comments (1)
- [Abstract] Abstract: the claim that 'model selection must be driven by specific clinical intent—whether prioritizing conservative visible-tissue segmentation or the amodal inference of hidden anatomy' is load-bearing for the paper's contribution but depends on the synthesized occlusions (tool overlay and cutout at three severity levels) accurately representing real surgical conditions; the evaluation protocol does not include validation against actual endoscopic frames with shadows, specular reflections, tissue deformation, or dynamic motion, leaving open the possibility that the observed archetype split is an artifact of the synthesis method rather than a transferable architectural property.
minor comments (2)
- The abstract and methods should explicitly list all model variants with precise version citations (e.g., SAM 2 vs. SAM 3) and dataset splits to improve reproducibility.
- Figure captions for the three-region protocol would benefit from an explicit diagram showing how visible-only and invisible targets are defined on the same frame.
Simulated Author's Rebuttal
We thank the referee for recognizing the value of the three-region protocol and for the constructive critique. We respond to the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'model selection must be driven by specific clinical intent—whether prioritizing conservative visible-tissue segmentation or the amodal inference of hidden anatomy' is load-bearing for the paper's contribution but depends on the synthesized occlusions (tool overlay and cutout at three severity levels) accurately representing real surgical conditions; the evaluation protocol does not include validation against actual endoscopic frames with shadows, specular reflections, tissue deformation, or dynamic motion, leaving open the possibility that the observed archetype split is an artifact of the synthesis method rather than a transferable architectural property.
Authors: We appreciate the referee highlighting the dependence of our clinical recommendation on the fidelity of the synthetic occlusions. The controlled synthesis (calibrated tool overlays and cutouts at three severity levels) was intentionally chosen to isolate occlusion effects and enable reproducible severity scaling, which is difficult to achieve with the high variability of real endoscopic videos. The consistent emergence of the occluder-aware versus occluder-agnostic archetypes across SAM-family variants and multiple polyp datasets supports our view that these behaviors reflect architectural differences rather than synthesis artifacts. That said, we agree that the lack of direct validation against real frames containing shadows, specularities, deformation, and motion means the transferability of the archetype distinction to clinical practice is not yet fully demonstrated. In the revised manuscript we will (i) qualify the abstract claim to state that the guidance applies under controlled synthetic conditions and (ii) add an explicit limitations paragraph in the Discussion that acknowledges this gap and outlines future validation on real surgical videos. These changes constitute a partial revision that preserves the benchmark contribution while addressing the grounding concern. revision: partial
Circularity Check
No circularity: purely empirical benchmark with direct observations
full rationale
The paper introduces OccSAM-Bench as a controlled evaluation framework on public datasets, applies synthesized occlusions at fixed severity levels, and reports performance via a three-region protocol. No equations, fitted parameters, predictions, or derivations are present; the central distinction between Occluder-Aware and Occluder-Agnostic archetypes emerges directly from tabulated results on the chosen models and metrics. The evaluation protocol and occlusion synthesis are defined independently of the final claims, with no self-citation load-bearing the conclusions or renaming of prior results. This is a standard empirical benchmark study whose findings are falsifiable against the released benchmark data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthesized tool overlay and cutout occlusions at calibrated severity levels accurately simulate real surgical occlusion in endoscopy
Reference graph
Works this paper leans on
-
[1]
SAM 3: Segment any- thing with concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoub- hik Debnath, Ronghang Hu, Didac Suris Coll-Vinent, Chai- tanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, An- drew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman R ¨adle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han W...
2026
-
[2]
Christian Chang, Hudson Law, Connor Poon, Sydney Yen, Kaustubh Lall, Armin Jamshidi, Vadim Malis, Dosik Hwang, and Won C. Bae. Segment anything model (SAM) and medical SAM (MedSAM) for lumbar spine MRI.Sen- sors, 25(12):3596, 2025. 7
2025
-
[3]
Junlong Cheng, Jin Ye, Zhongying Deng, Jianpin Chen, Tianbin Li, Haoyu Wang, Yanzhou Su, Ziyan Huang, Ji- long Chen, Lei Jiang, et al. Sam-med2d.arXiv preprint arXiv:2308.16184, 2023. 1, 2, 4, 5
-
[4]
Improved Regularization of Convolutional Neural Networks with Cutout
Terrance DeVries and Graham W Taylor. Improved regular- ization of convolutional neural networks with cutout.arXiv preprint arXiv:1708.04552, 2017. 3
work page internal anchor Pith review arXiv 2017
-
[5]
Stable segment anything model
Qi Fan, Xin Tao, Lei Ke, Mingqiao Ye, Di Zhang, Pengfei Wan, Yu-Wing Tai, and Chi-Keung Tang. Stable segment anything model. InInternational Conference on Learning Representations (ICLR), 2025. 1
2025
-
[6]
Learning to see the invisible: End-to-end trainable amodal instance segmen- tation
Patrick Follmann, Rebecca K ¨onig, Philipp H ¨artinger, Michael Klostermann, and Tobias B ¨ottger. Learning to see the invisible: End-to-end trainable amodal instance segmen- tation. In2019 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1328–1336. IEEE, 2019. 2
2019
-
[7]
Medsam: Segment anything in medical images,
Sheng He, Rina Bao, Jingpeng Li, Jeffrey Stout, Atle Bjornerud, P. Ellen Grant, and Yangming Ou. Computer- vision benchmark segment-anything model (SAM) in med- ical images: Accuracy in 12 datasets.arXiv preprint arXiv:2304.09324, 2023. 2
-
[8]
Segment anything model for medical images?Medical Image Analysis, 92:103061, 2024
Yuhao Huang, Xin Yang, Lian Liu, Han Zhou, Ao Chang, Xinrui Zhou, Rusi Chen, Junxuan Yu, Jiongquan Chen, Chaoyu Chen, et al. Segment anything model for medical images?Medical Image Analysis, 92:103061, 2024. 1, 2
2024
-
[9]
Kvasir-instrument: Diagnostic and therapeu- tic tool segmentation dataset in gastrointestinal endoscopy
Debesh Jha, Sharib Ali, Krister Emanuelsen, Steven A Hicks, Vajira Thambawita, Enrique Garcia-Ceja, Michael A Riegler, Thomas De Lange, Peter T Schmidt, H ˚avard D Jo- hansen, et al. Kvasir-instrument: Diagnostic and therapeu- tic tool segmentation dataset in gastrointestinal endoscopy. InInternational Conference on Multimedia Modeling, pages 218–229. Spr...
2021
-
[10]
Deep occlusion- aware instance segmentation with overlapping BiLayers
Lei Ke, Yu-Wing Tai, and Chi-Keung Tang. Deep occlusion- aware instance segmentation with overlapping BiLayers. In Proc. IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 4184–4193, 2021. 2
2021
-
[11]
Segment any- thing
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 4015–4026, 2023. 1, 2, 4, 5
2023
-
[12]
Ultra- ecp: Ellipse-constrained and point-robust foundation model adaptation for fetal cardiac ultrasound segmentation
Minh HN Le, Khanh TQ Le, Tuan Vinh, Thanh-Huy Nguyen, Han H Huynh, Khoa D Pham, Anh Mai Vu, Hien Quang Kha, Phat Ky Nguyen, Ulas Bagci, et al. Ultra- ecp: Ellipse-constrained and point-robust foundation model adaptation for fetal cardiac ultrasound segmentation. InMed- ical Imaging with Deep Learning, 2026. 2
2026
-
[13]
Cao, Yifan Shen, Yi Lu, Xiang Li, Qianqian Chen, and Jintai Chen
Anglin Liu, Rundong Xue, Xu R. Cao, Yifan Shen, Yi Lu, Xiang Li, Qianqian Chen, and Jintai Chen. Medsam3: Delv- ing into segment anything with medical concepts, 2025. 1, 4, 5
2025
-
[14]
Segment anything in medical images.Nature communications, 15(1):654, 2024
Jun Ma, Yuting He, Feifei Li, Lin Han, Chenyu You, and Bo Wang. Segment anything in medical images.Nature communications, 15(1):654, 2024. 1, 2, 4, 5, 7
2024
-
[15]
Segment anything model for medical image analysis: an experimental study
Maciej A Mazurowski, Haoyu Dong, Hanxue Gu, Jichen Yang, Nicholas Konz, and Yixin Zhang. Segment anything model for medical image analysis: an experimental study. Medical Image Analysis, 89:102918, 2023. 1, 2, 4
2023
-
[16]
Up2d: Uncertainty-aware progres- sive pseudo-label denoising for source-free domain adap- tive medical image segmentation.Neurocomputing, page 132659, 2026
Thanh-Huy Nguyen, Quang-Khai Bui-Tran, Manh D Ho, Thinh B Lam, Vi Vu, Hoang-Thien Nguyen, Phat Huynh, and Ulas Bagci. Up2d: Uncertainty-aware progres- sive pseudo-label denoising for source-free domain adap- tive medical image segmentation.Neurocomputing, page 132659, 2026. 2
2026
-
[17]
Adaptive knowledge transferring with switching dual-student framework for semi-supervised medical image segmentation.Pattern Recognition, page 113115, 2026
Thanh-Huy Nguyen, Hoang-Thien Nguyen, Ba-Thinh Lam, Vi Vu, Bach X Nguyen, Jianhua Xing, Tianyang Wang, Xingjian Li, and Min Xu. Adaptive knowledge transferring with switching dual-student framework for semi-supervised medical image segmentation.Pattern Recognition, page 113115, 2026. 2
2026
-
[18]
Amodal instance segmentation with KINS dataset
Lu Qi, Li Jiang, Shu Liu, Xiaoyong Shen, and Jiaya Jia. Amodal instance segmentation with KINS dataset. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3014–3023, 2019. 2
2019
-
[19]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. SAM 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 1, 2, 4, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Comparative validation of multi-instance instrument segmentation in endoscopy: Results of the ROBUST-MIS 2019 challenge.Medical image analysis, 70:101920, 2021
Tobias Roß, Annika Reinke, Peter M Full, Martin Wag- ner, Hannes Kenngott, Martin Apitz, Hellena Hempe, Di- ana Mindroc-Filimon, Patrick Scholz, Thuy Nuong Tran, et al. Comparative validation of multi-instance instrument segmentation in endoscopy: Results of the ROBUST-MIS 2019 challenge.Medical image analysis, 70:101920, 2021. 2
2019
-
[21]
Tobias Rueckert, Maximilian Rieder, David Rauber, Michel Xiao, Eg Humolli, Hubertus Feussner, Dirk Wilhelm, and Christoph Palm. Augmenting instrument segmentation in video sequences of minimally invasive surgery by synthetic smoky frames.International Journal of Computer Assisted Radiology and Surgery, pages S54–S56, 2023. 2
2023
-
[22]
Toward embedded detection of polyps in WCE images for early diagnosis of colorectal can- cer.International journal of computer assisted radiology and surgery, 9(2):283–293, 2014
Juan Silva, Aymeric Histace, Olivier Romain, Xavier Dray, and Bertrand Granado. Toward embedded detection of polyps in WCE images for early diagnosis of colorectal can- cer.International journal of computer assisted radiology and surgery, 9(2):283–293, 2014. 4
2014
-
[23]
Segment anything, even oc- cluded
Wei-En Tai, Yu-Lin Shih, Cheng Sun, Yu-Chiang Frank Wang, and Hwann-Tzong Chen. Segment anything, even oc- cluded. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29385–29394, 2025. 1, 2
2025
-
[24]
Gurudu, and Jianming Liang
Nima Tajbakhsh, Suryakanth R. Gurudu, and Jianming Liang. Automated polyp detection in colonoscopy videos using shape and context information.IEEE Transactions on Medical Imaging, 35(2):630–644, 2016. 4
2016
-
[25]
Unsupervised multi- scale segmentation of cellular cryo-electron tomograms with stable diffusion foundation model.bioRxiv, pages 2025–06,
Mostofa Rafid Uddin, Thanh-Huy Nguyen, HM Shadman Tabib, Kashish Gandhi, and Min Xu. Unsupervised multi- scale segmentation of cellular cryo-electron tomograms with stable diffusion foundation model.bioRxiv, pages 2025–06,
2025
-
[26]
A benchmark for en- doluminal scene segmentation of colonoscopy images.Jour- nal of healthcare engineering, 2017(1):4037190, 2017
David V ´azquez, Jorge Bernal, F Javier S ´anchez, Gloria Fern´andez-Esparrach, Antonio M L ´opez, Adriana Rsomero, Michal Drozdzal, and Aaron Courville. A benchmark for en- doluminal scene segmentation of colonoscopy images.Jour- nal of healthcare engineering, 2017(1):4037190, 2017. 4
2017
-
[27]
Vi Vu, Thanh-Huy Nguyen, Tien-Thinh Nguyen, Ba-Thinh Lam, Hoang-Thien Nguyen, Tianyang Wang, Xingjian Li, and Min Xu. From specialist to generalist: Unlocking sam’s learning potential on unlabeled medical images.arXiv preprint arXiv:2601.17934, 2026. 2
-
[28]
Describe anything in medical images.arXiv preprint arXiv:2505.05804, 2025
Xi Xiao, Yunbei Zhang, Thanh-Huy Nguyen, Ba-Thinh Lam, Janet Wang, Lin Zhao, Jihun Hamm, Tianyang Wang, Xingjian Li, Xiao Wang, et al. Describe anything in medical images.arXiv preprint arXiv:2505.05804, 2025. 2
-
[29]
Medical sam 2: Segment medical images as video via segment anything model 2,
Jiayuan Zhu, Abdullah Hamdi, Yunli Qi, Yueming Jin, and Junde Wu. MedSAM2: Segment medical images as video via segment anything model 2.arXiv preprint arXiv:2408.00874, 2024. 1, 2, 4, 5, 7
-
[30]
Semantic amodal segmentation
Yan Zhu, Yuandong Tian, Dimitris Metaxas, and Piotr Doll´ar. Semantic amodal segmentation. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 1464–1472, 2017. 2 Supplementary Material We report additional quantitative results across three datasets under different occlusion generation strategies and prompt set- tings. ...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.