BEM: Training-Free Background Embedding Memory for False-Positive Suppression in Real-Time Fixed-Background Camera
Pith reviewed 2026-05-10 16:15 UTC · model grok-4.3
The pith
Background Embedding Memory reduces false positives in pretrained object detectors for fixed-background cameras without training or speed loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BEM estimates clean background embeddings, maintains a prototype memory of them, and re-scores detection logits with an inverse-similarity rank-weighted penalty, reducing false positives in quasi-static fixed-camera environments while preserving recall and real-time performance on YOLO and RT-DETR models.
What carries the argument
Background Embedding Memory (BEM), a training-free module that stores prototype background embeddings and applies an inverse-similarity penalty to detection scores based on frame similarity.
If this is right
- False positives decrease across YOLO and RT-DETR families on LLVIP and simulated surveillance data.
- Real-time speed is preserved because BEM adds only negligible computation at inference.
- Precision rises in high-density few-class scenes without any retraining of the base detector.
- Background-frame cosine similarity can serve as a direct control signal for detection confidence.
Where Pith is reading between the lines
- BEM could be combined with existing post-processing filters to handle gradual background drift.
- The same memory idea might apply to other fixed-sensor tasks such as traffic monitoring or industrial inspection.
- Longer-term memory adaptation could extend the method to scenes with slow environmental changes.
Load-bearing premise
The background remains sufficiently static across frames to provide a reliable reference for identifying and suppressing detections that resemble it.
What would settle it
Running BEM on footage where the background slowly changes due to lighting shifts or permanent scene alterations, then checking whether false-positive reduction disappears or reverses.
Figures





read the original abstract
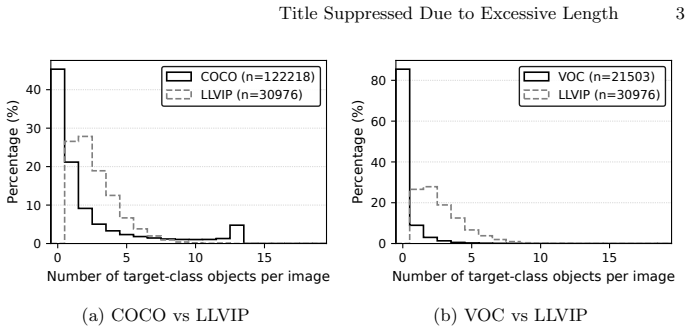
Pretrained detectors perform well on benchmarks but often suffer performance degradation in real-world deployments due to distribution gaps between training data and target environments. COCO-like benchmarks emphasize category diversity rather than instance density, causing detectors trained under per-class sparsity to struggle in dense, single- or few-class scenes such as surveillance and traffic monitoring. In fixed-camera environments, the quasi-static background provides a stable, label-free prior that can be exploited at inference to suppress spurious detections. To address the issue, we propose Background Embedding Memory (BEM), a lightweight, training-free, weight-frozen module that can be attached to pretrained detectors during inference. BEM estimates clean background embeddings, maintains a prototype memory, and re-scores detection logits with an inverse-similarity, rank-weighted penalty, effectively reducing false positives while maintaining recall. Empirically, background-frame cosine similarity correlates negatively with object count and positively with Precision-Confidence AUC (P-AUC), motivating its use as a training-free control signal. Across YOLO and RT-DETR families on LLVIP and simulated surveillance streams, BEM consistently reduces false positives while preserving real-time performance. Our code is available at https://github.com/Leo-Park1214/Background-Embedding-Memory.git
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Background Embedding Memory (BEM), a lightweight training-free module attachable to pretrained detectors (YOLO and RT-DETR families) for fixed-background cameras. BEM estimates clean background embeddings from incoming frames, maintains a prototype memory, and applies an inverse-similarity rank-weighted penalty to detection logits to suppress false positives while preserving recall. It reports a negative correlation between background-frame cosine similarity and object count, plus a positive correlation with Precision-Confidence AUC (P-AUC), and claims consistent FP reduction on LLVIP and simulated surveillance streams without compromising real-time performance. Code is released at the provided GitHub link.
Significance. If the central empirical claims hold, BEM offers a practical inference-only technique for improving detector robustness in dense, quasi-static surveillance and traffic scenes by exploiting label-free background priors, avoiding the need for domain-specific retraining. The training-free design and public code release are strengths that could facilitate adoption and further testing in real-time CV applications.
major comments (2)
- [§3] §3: The prototype memory is updated directly from incoming frames without an explicit mechanism (temporal filtering, statistical outlier rejection, or foreground masking) for separating background from foreground. In the high object-density surveillance scenarios highlighted in the introduction, persistent or slow-moving objects risk contaminating the background embeddings; this could either suppress true static detections or fail to penalize spurious ones, directly threatening the reported P-AUC gains.
- [Experiments] Experiments section: The abstract states consistent FP reduction and a background-similarity correlation with object count/P-AUC across YOLO/RT-DETR on LLVIP and simulated streams, yet no quantitative tables, per-scenario ablations on object density, or error bars are referenced; without these, it is impossible to verify whether the gains are robust or load-bearing for the central claim.
minor comments (2)
- [Abstract] Abstract: The term 'simulated surveillance streams' is used without describing the simulation procedure, camera parameters, or how it matches real fixed-background conditions.
- Notation: The embedding memory update rule and the exact form of the rank-weighted inverse-similarity penalty would benefit from an explicit equation or pseudocode block in the method section to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline revisions that will strengthen the empirical support and methodological clarity of the manuscript.
read point-by-point responses
-
Referee: §3: The prototype memory is updated directly from incoming frames without an explicit mechanism (temporal filtering, statistical outlier rejection, or foreground masking) for separating background from foreground. In the high object-density surveillance scenarios highlighted in the introduction, persistent or slow-moving objects risk contaminating the background embeddings; this could either suppress true static detections or fail to penalize spurious ones, directly threatening the reported P-AUC gains.
Authors: We agree that the absence of an explicit separation mechanism in the prototype update is a valid concern for high-density scenes. The current design relies on the background similarity metric to modulate penalty strength but performs direct averaging for memory maintenance. To address this, we will revise Section 3 to incorporate a lightweight temporal filtering step (exponential moving average with similarity-gated updates) and add a short ablation on embedding contamination under persistent objects. These changes will be accompanied by new results confirming that P-AUC gains hold under moderate density increases. revision: yes
-
Referee: Experiments section: The abstract states consistent FP reduction and a background-similarity correlation with object count/P-AUC across YOLO/RT-DETR on LLVIP and simulated streams, yet no quantitative tables, per-scenario ablations on object density, or error bars are referenced; without these, it is impossible to verify whether the gains are robust or load-bearing for the central claim.
Authors: We acknowledge that the experimental reporting requires greater quantitative detail to allow verification of robustness. While correlations and FP reductions are described, dedicated tables, density-specific breakdowns, and statistical variability measures are indeed missing. In the revised manuscript we will add comprehensive tables reporting FP reduction, correlation coefficients, and P-AUC for each detector-dataset pair, plus new per-scenario ablations across low/medium/high object density regimes and error bars from repeated runs on the simulated streams. revision: yes
Circularity Check
No circularity: BEM is an external training-free attachment using independent background prior
full rationale
The paper introduces BEM as a lightweight inference-only module attached to frozen pretrained detectors. It estimates background embeddings from quasi-static frames, maintains a prototype memory updated from incoming frames, and applies an inverse-similarity penalty to detection logits. This construction relies on external frame data as a label-free prior rather than any fitted parameters or outputs from the detector itself. No equations or claims reduce by construction to the detector's predictions, no self-citations are load-bearing for the core mechanism, and the reported negative correlation between background similarity and object count is presented as empirical motivation, not a derived result. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Quasi-static background provides a stable, label-free prior exploitable at inference
Reference graph
Works this paper leans on
-
[1]
Aljundi, R., et al.: Gradient based sample selection for online continual learning. NeurIPS32(2019)
work page 2019
- [2]
- [3]
-
[4]
Class imbalance in object detection: An experimental diagnosis and study of mitigation strategies,
Crasto, N.: Class imbalance in object detection: an experimental diagnosis and study of mitigation strategies. arXiv preprint arXiv:2403.07113 (2024) Title Suppressed Due to Excessive Length 15
-
[5]
International journal of computer vision88(2), 303–338 (2010)
Everingham, M., et al.: The pascal visual object classes (voc) challenge. International journal of computer vision88(2), 303–338 (2010)
work page 2010
-
[6]
arXiv preprint arXiv:2508.01382 (2025)
Guo, Q., et al.: A full-stage refined proposal algorithm for suppressing false positives in two-stage cnn-based detection methods. arXiv preprint arXiv:2508.01382 (2025)
- [7]
- [8]
-
[9]
https://github.com/ultralytics/ ultralytics(2023), accessed: 2025-12-07
Jocher, G., Ultralytics: Ultralytics yolov8. https://github.com/ultralytics/ ultralytics(2023), accessed: 2025-12-07
work page 2023
-
[10]
https: //github.com/ultralytics/ultralytics(2024), accessed: 2025-12-07
Jocher, G., Ultralytics: Ultralytics yolov11: Real-time object detection. https: //github.com/ultralytics/ultralytics(2024), accessed: 2025-12-07
work page 2024
-
[11]
Proceedings of the national academy of sciences114(13), 3521–3526 (2017)
Kirkpatrick, J., et al.: Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences114(13), 3521–3526 (2017)
work page 2017
- [12]
-
[13]
K¨ uppers, F., et al.: Confidence calibration for object detection and segmentation. In: Deep neural networks and data for automated driving: Robustness, uncertainty quantification, and insights towards safety, pp. 225–250. Springer International Publishing Cham (2022)
work page 2022
- [14]
- [15]
- [16]
- [17]
-
[18]
IEEE transac- tions on pattern analysis and machine intelligence43(10), 3388–3415 (2020)
Oksuz, K., et al.: Imbalance problems in object detection: A review. IEEE transac- tions on pattern analysis and machine intelligence43(10), 3388–3415 (2020)
work page 2020
- [19]
- [20]
- [21]
-
[22]
arXiv preprint arXiv:2508.14660 (2025)
Siddiqui, M.I., et al.: Towards persense++: Advancing training-free personalized instance segmentation in dense images. arXiv preprint arXiv:2508.14660 (2025)
- [23]
- [24]
- [25]
-
[26]
In: International Conference on Neural Information Processing
Zeng, R., et al.: Boosting open-vocabulary object detection by handling background samples. In: International Conference on Neural Information Processing. pp. 274–
- [27]
- [28]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.