Recognition: unknown
The Effect of Document Selection on Query-focused Text Analysis
Pith reviewed 2026-05-10 14:52 UTC · model grok-4.3
The pith
Semantic or hybrid retrieval provides strong default strategies for selecting documents in query-focused text analyses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through systematic evaluation of seven selection methods from random selection to hybrid retrieval on four text analyses methods (LDA, BERTopic, TopicGPT, HiCode) over two datasets with 26 open-ended queries, semantic or hybrid retrieval emerge as strong go-to approaches. These avoid the pitfalls of weaker selection strategies and the unnecessary compute overhead of more complicated ones. This positions data selection as a methodological decision rather than a practical necessity.
What carries the argument
Comparative evaluation framework of document selection methods applied to downstream text analysis outputs; it quantifies how selection strategy impacts analysis quality across multiple queries and datasets.
If this is right
- Semantic and hybrid retrieval should be preferred as default document selection methods for query-focused analyses.
- Random or weak selection methods risk producing less relevant or lower quality analysis results.
- Complex selection methods beyond hybrid retrieval add computational cost without clear benefits in this context.
- The choice of document selection is a key factor that researchers must consider deliberately when designing analyses.
Where Pith is reading between the lines
- Integrating retrieval directly into analysis pipelines could further improve efficiency and relevance.
- The evaluation approach could be extended to other text processing tasks such as summarization or entity extraction.
- Future work might explore adaptive selection methods that adjust based on the specific analysis technique used.
Load-bearing premise
The chosen evaluation metrics accurately measure the relevance and quality of the analysis outputs for the given open-ended queries.
What would settle it
A follow-up study using human evaluators to rate the analysis outputs for relevance to the queries, finding that differences between selection methods disappear or reverse.
Figures









read the original abstract
Analyses of document collections often require selecting what data to analyze, as not all documents are relevant to a particular research question and computational constraints preclude analyzing all documents, yet little work has examined effects of selection strategy choices. We systematically evaluate seven selection methods (from random selection to hybrid retrieval) on outputs from four text analyses methods (LDA, BERTopic, TopicGPT, HiCode) over two datasets with 26 open-ended queries. Our evaluation reveals practice guidance: semantic or hybrid retrieval offer strong go-to approaches that avoid the pitfalls of weaker selection strategies and the unnecessary compute overhead of more complicated ones. Overall, our evaluation framework establishes data selection as a methodological decision, rather than a practical necessity, inviting the development of new strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a systematic empirical evaluation of seven document selection methods (from random to hybrid retrieval) applied to outputs from four text analysis techniques (LDA, BERTopic, TopicGPT, HiCode) across two datasets and 26 open-ended queries. It concludes that semantic or hybrid retrieval strategies serve as strong, efficient go-to approaches that mitigate weaknesses of simpler methods while avoiding the overhead of more complex alternatives, framing document selection as a methodological choice rather than mere practicality.
Significance. If the chosen metrics for analysis quality prove reliable, the work supplies actionable guidance for query-focused text analysis in information retrieval and related fields, demonstrating that selection strategy meaningfully affects downstream outputs and encouraging more deliberate methodological decisions. The multi-method, multi-dataset design adds breadth to the comparative findings.
major comments (2)
- [Evaluation section] Evaluation section: the central claim that semantic/hybrid retrieval yield superior analysis outputs rests on automated proxies (coherence, embedding similarity, etc.) for the 26 open-ended queries, yet these lack any reported validation against human judgments or task-specific relevance assessments; without such grounding, observed differences may not reflect actual utility or query relevance.
- [Results section] Results section: comparative tables and figures report differences across selection methods but omit statistical significance tests, confidence intervals, or controls for query variability, weakening the robustness of the practice guidance that semantic/hybrid methods are reliably preferable.
minor comments (2)
- [Abstract] Abstract: the summary of findings could briefly name the primary evaluation metrics to allow readers to assess the strength of the reported practice guidance.
- [Introduction] Introduction: provide explicit definitions or pseudocode for the seven selection methods at the outset to improve traceability through the experimental comparisons.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important aspects for improving the robustness and validity of our empirical evaluation. We address each major comment below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: the central claim that semantic/hybrid retrieval yield superior analysis outputs rests on automated proxies (coherence, embedding similarity, etc.) for the 26 open-ended queries, yet these lack any reported validation against human judgments or task-specific relevance assessments; without such grounding, observed differences may not reflect actual utility or query relevance.
Authors: We acknowledge that our evaluation relies primarily on automated metrics without direct human validation for the specific queries. These metrics are standard in the literature for assessing topic quality and semantic similarity. To address this, we will revise the manuscript to include a more explicit discussion of the metrics' limitations and their established correlations with human judgments from prior studies in topic modeling. We will also add this as a noted limitation. revision: partial
-
Referee: [Results section] Results section: comparative tables and figures report differences across selection methods but omit statistical significance tests, confidence intervals, or controls for query variability, weakening the robustness of the practice guidance that semantic/hybrid methods are reliably preferable.
Authors: We agree that the inclusion of statistical tests would strengthen the findings. In the revised manuscript, we will incorporate appropriate statistical significance tests (such as paired t-tests or non-parametric equivalents across the 26 queries), report confidence intervals, and include analyses that account for query variability, such as per-query breakdowns or variance measures. revision: yes
Circularity Check
No circularity: purely empirical comparative evaluation
full rationale
The paper performs a systematic experimental comparison of seven document selection strategies (random to hybrid retrieval) against four analysis methods (LDA, BERTopic, TopicGPT, HiCode) on two datasets using 26 open-ended queries. No derivations, equations, fitted parameters, or predictions are claimed; results are obtained directly from running the analyses and applying evaluation metrics to the outputs. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The central practice guidance follows from the observed empirical patterns rather than any reduction to inputs by construction. Evaluation-metric validity is a separate methodological concern and does not constitute circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The two datasets and 26 queries are representative of typical query-focused text analysis scenarios.
Reference graph
Works this paper leans on
-
[1]
opera- tion change agent
Latent dirichlet allocation.J. Mach. Learn. Res., 3(null):993–1022. G. Caleb Alexander, Lisa A. Mix, Sayeed Choudhury, Rachel Taketa, Cecília Tomori, Maryam Mooghali, Anni Fan, Sarah Mars, Dan Ciccarone, Mark Patton, Dorie E. Apollonio, Laura Schmidt, Michael A. Stein- man, Jeremy Greene, Kelly R. Knight, Pamela M. Ling, Anne K. Seymour, Stanton Glantz, a...
2022
-
[2]
BERTopic: Neural topic modeling with a class-based TF-IDF procedure
Identifying misleading corporate narratives: The application of linguistic and qualitative meth- ods to commercial determinants of health research. PLOS Global Public Health, 2(11):1–13. Edward A Fox and Joseph A Shaw. 1994. Combination of multiple searches.NIST special publication SP, 243. Maarten Grootendorst. 2020. KeyBERT: Minimal key- word extraction...
work page internal anchor Pith review arXiv 1994
-
[3]
Coresets for data-efficient training of machine learning models. InProceedings of the 37th Inter- national Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 6950–6960. PMLR. Rodrigo Nogueira and Kyunghyun Cho. 2020. Passage re-ranking with BERT.Preprint, arXiv:1901.04085. Chau Minh Pham, Alexander Hoyle, Simeng S...
work page internal anchor Pith review arXiv 2020
-
[4]
InProceedings of The Third Text REtrieval Conference, TREC 1994, Gaithers- burg, Maryland, USA, November 2-4, 1994, volume 500-225 ofNIST Special Publication, pages 109–
Okapi at TREC-3. InProceedings of The Third Text REtrieval Conference, TREC 1994, Gaithers- burg, Maryland, USA, November 2-4, 1994, volume 500-225 ofNIST Special Publication, pages 109–
1994
-
[5]
National Institute of Standards and Technology (NIST). Rodrygo L. T. Santos, Jie Peng, Craig Macdonald, and Iadh Ounis. 2010. Explicit search result diversifica- tion through sub-queries. ECIR’2010, page 87–99, Berlin, Heidelberg. Springer-Verlag. Ozan Sener and Silvio Savarese. 2018. Active learn- ing for convolutional neural networks: A core-set approac...
-
[6]
How does the coronavirus respond to changes in the weather?
-
[7]
How has COVID-19 affected Canada?
-
[8]
Has social distancing had an impact on slow- ing the spread of COVID-19?
-
[9]
What are the transmission routes of coron- avirus?
-
[10]
What are the best masks for preventing infec- tion by Covid-19?
-
[11]
What are the mortality rates overall and in specific populations?
-
[12]
What kinds of complications related to COVID-19 are associated with hypertension?
-
[13]
What kinds of complications related to COVID-19 are associated with diabetes?
-
[14]
What are the initial symptoms of Covid-19?
-
[15]
What is known about those infected with Covid-19 but are asymptomatic?
-
[16]
What are the longer-term complications of those who recover from COVID-19?
-
[17]
How has the COVID-19 pandemic impacted violence in society, including violent crimes?
-
[18]
How has the COVID-19 pandemic impacted mental health?
-
[19]
What are the health outcomes for children who contract COVID-19?
-
[20]
A.2 Doctor-Reviews Queries We designed 11 queries with domain experts for the physician review dataset:
What are the benefits and risks of re-opening schools in the midst of the COVID-19 pan- demic? Notice that the index of the queries match to the original query indices. A.2 Doctor-Reviews Queries We designed 11 queries with domain experts for the physician review dataset:
-
[21]
How do patients find and choose their doc- tors?
-
[22]
What are patients’ experiences with specialist referrals?
-
[23]
What breathing problems do patients report and how are they treated?
-
[24]
How do doctors manage patients with asthma?
-
[25]
What do patients like about their doctors?
-
[26]
What do patients dislike about their doctors?
-
[27]
What follow-up care or testing do doctors rec- ommend for people with asthma?
-
[28]
What do patients like about treatment or man- agement recommendations?
-
[29]
What do patients dislike about treatment or management recommendations?
-
[30]
What lifestyle challenges do patients with asthma report?
-
[31]
The coding for experiments was assisted by AI tools
What symptoms do patients with asthma re- port? B Implementation Details: Data Selection Strategies All methods retrieve from the full corpus and select 1,000 documents per query using fixed random seed (= 42 ) for reproducibility. The coding for experiments was assisted by AI tools. B.1 Keyword Search We use BM25 as our Keyword Search strategy, a lexical...
1994
-
[32]
symmetric
embeddings on queries and documents which retrieves top documents by cosine similarity. B.3 Hybrid approaches For the following approaches, we retrieve the union of top documents from BM25 and SBERT, re-rank these documents on the hybrid score and select the finally set of documents (e.g. 1000 documents for our experiments). Direct RetrievalDirect Retriev...
2009
-
[33]
How has the COVID- 19 pandemic impacted violence in society, includ- ing violent crimes?
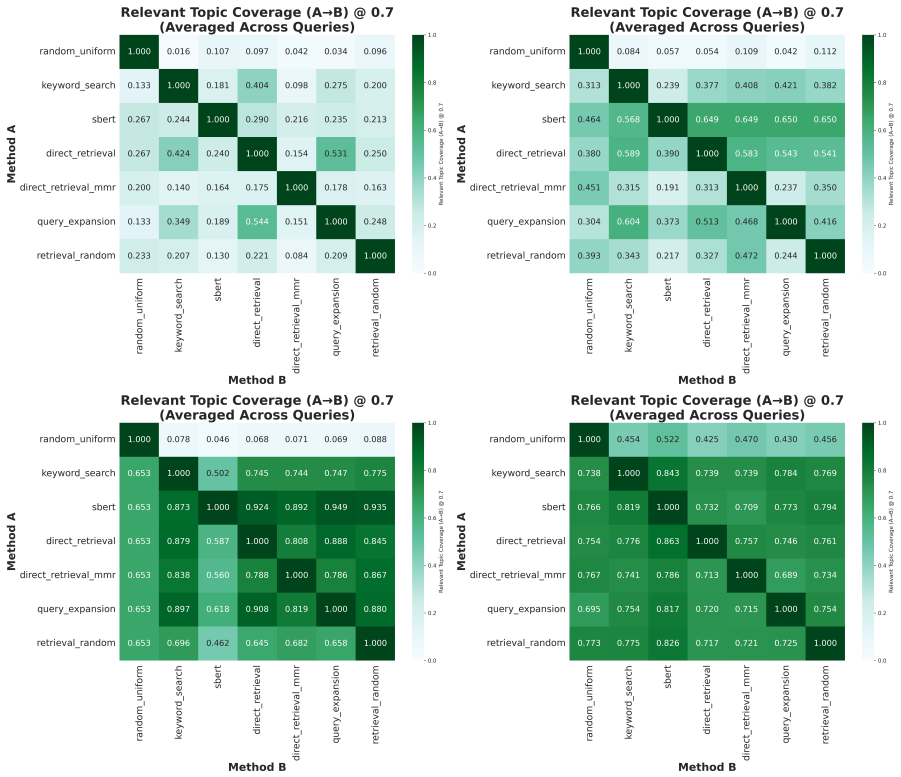
show TREC-COVID-like differentiation, while weak queries (3, 10, 11) approach random perfor- mance. D.2 Relevant Topic Diversity TREC-COVIDWhen diversity is computed only among query-relevant topics (similarity≥0.5 ), dif- ferentiation between selection methods disappears across all models (Fig. 7). TopicGPT shows over- lapping ranges of 0.416–0.476, BERT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.