Development, Evaluation, and Deployment of a Multi-Agent System for Thoracic Tumor Board
Pith reviewed 2026-05-10 16:31 UTC · model grok-4.3
The pith
A multi-agent AI system generates accurate patient summaries for thoracic tumor boards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A multi-agent AI system for automated chart summarization can be built, evaluated against human-created gold standards via fact-based rubrics, deployed for live use in thoracic tumor boards, and monitored in production, while also confirming that an LLM can serve as an effective judge for the same scoring task.
What carries the argument
The multi-agent AI system that extracts and synthesizes data from patient electronic health records to produce concise case summaries for tumor board display.
If this is right
- Physician time preparing for tumor boards decreases as summarization becomes automated.
- Summary quality becomes more consistent across different cases and preparers.
- LLM-based judging scales evaluation without requiring constant physician review.
- Post-deployment monitoring supports ongoing refinement of the system in live use.
Where Pith is reading between the lines
- The same multi-agent structure could be adapted for tumor boards in other oncology or medical specialties.
- Tighter integration with hospital record systems might remove the remaining manual chart access steps.
- Continued monitoring is needed to catch rare but high-impact errors in summary content.
Load-bearing premise
The AI-generated summaries contain no critical omissions or inaccuracies that would alter the patient care recommendations made during the tumor board.
What would settle it
A real tumor board case in which the final recommendation differs when the full radiology and pathology data are reviewed manually versus when only the AI summary is used.
Figures
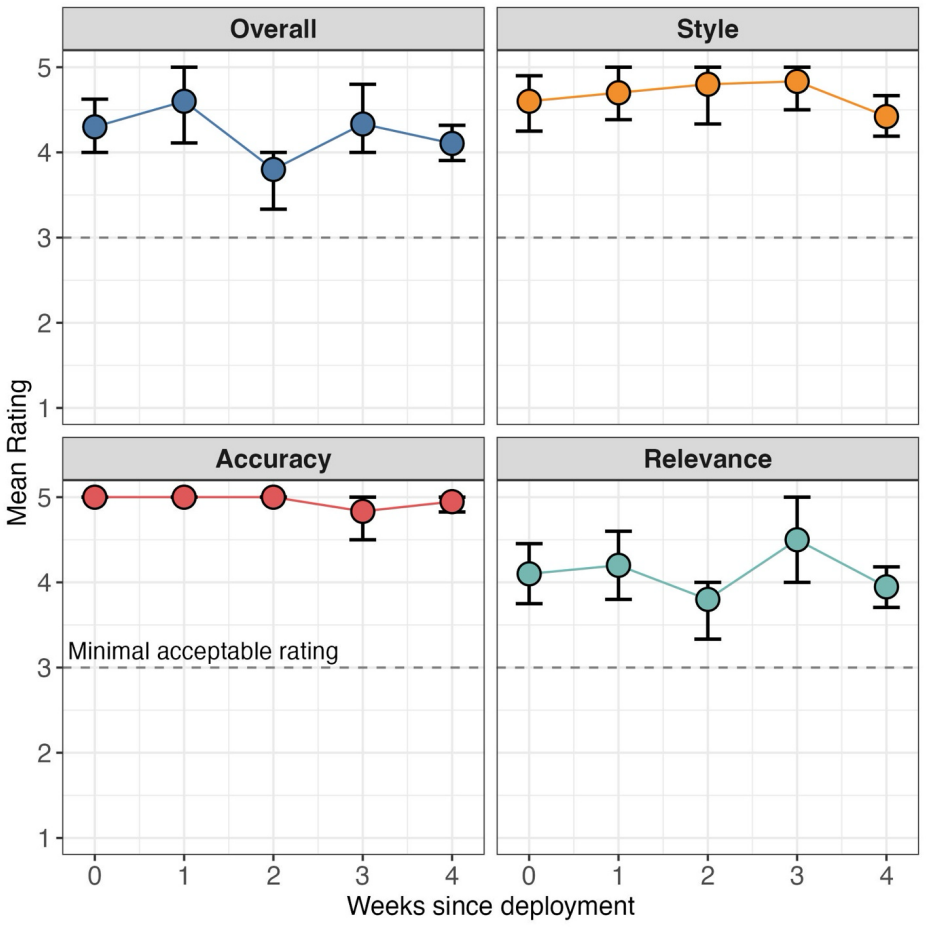
read the original abstract
Tumor boards are multidisciplinary conferences dedicated to producing actionable patient care recommendations with live review of primary radiology and pathology data. Succinct patient case summaries are needed to drive efficient and accurate case discussions. We developed a manual AI-based workflow to generate patient summaries to display live at the Stanford Thoracic Tumor board. To improve on this manually intensive process, we developed several automated AI chart summarization methods and evaluated them against physician gold standard summaries and fact-based scoring rubrics. We report these comparative evaluations as well as our deployment of the final state automated AI chart summarization tool along with post-deployment monitoring. We also validate the use of an LLM as a judge evaluation strategy for fact-based scoring. This work is an example of integrating AI-based workflows into routine clinical practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes the development of a multi-agent AI system for generating succinct patient case summaries to support live thoracic tumor board discussions at Stanford. It progresses from a manual AI-assisted workflow to several automated chart summarization approaches, evaluates these against physician gold-standard summaries using fact-based scoring rubrics, validates an LLM-as-judge strategy for the same rubrics, and reports deployment of the final automated tool together with post-deployment monitoring. The work is framed as a practical example of integrating AI workflows into routine clinical oncology practice.
Significance. If the evaluations and safety assumptions hold, the paper provides a concrete demonstration of AI deployment in a high-stakes multidisciplinary clinical setting, including post-deployment monitoring and an empirical check on LLM-as-judge reliability. These elements offer a useful template for other groups seeking to move AI summarization tools from research to live use, with explicit attention to human gold standards rather than purely automated metrics.
major comments (1)
- [Evaluation and LLM-as-judge validation sections] The central deployment claim—that the automated summaries contain no critical omissions or inaccuracies that would affect patient care decisions—rests on the fact-based rubrics and LLM-as-judge validation. However, the rubrics are defined a priori and the LLM judge is validated only against the same rubrics rather than against downstream clinical impact or multi-physician detection of subtle contraindications and staging implications. This assumption is load-bearing for asserting safe live use and requires either explicit limitation discussion or additional validation (e.g., error analysis on missed clinical nuances).
minor comments (2)
- [Abstract] The abstract states that comparative evaluations and deployment are reported but supplies no sample sizes, specific metrics (e.g., precision/recall on rubric items), or error analysis; a brief quantitative summary would strengthen the abstract.
- [Abstract and title] The title emphasizes a 'Multi-Agent System' while the abstract refers only to 'AI chart summarization methods'; the abstract should explicitly note the multi-agent architecture and how agents interact.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript on the multi-agent system for thoracic tumor board summarization. We have carefully considered the major comment on evaluation and LLM-as-judge validation. Our response addresses the concern directly, and we have revised the manuscript to incorporate an expanded limitations discussion as suggested.
read point-by-point responses
-
Referee: [Evaluation and LLM-as-judge validation sections] The central deployment claim—that the automated summaries contain no critical omissions or inaccuracies that would affect patient care decisions—rests on the fact-based rubrics and LLM-as-judge validation. However, the rubrics are defined a priori and the LLM judge is validated only against the same rubrics rather than against downstream clinical impact or multi-physician detection of subtle contraindications and staging implications. This assumption is load-bearing for asserting safe live use and requires either explicit limitation discussion or additional validation (e.g., error analysis on missed clinical nuances).
Authors: We appreciate the referee highlighting this important consideration for the strength of our deployment claims. The fact-based rubrics were developed in close collaboration with thoracic oncology physicians to focus on clinically critical elements, including staging details, contraindications, and other factors that influence care decisions, rather than being defined without clinical grounding. The primary evaluation benchmark consists of physician-authored gold-standard summaries, with the LLM-as-judge approach validated through direct comparison to human scoring on the identical rubrics, demonstrating high agreement. Our post-deployment monitoring in the live Stanford Thoracic Tumor Board further provides real-world performance data in the target clinical setting. We acknowledge that direct assessment of downstream clinical impact, such as effects on multidisciplinary decisions or patient outcomes, represents an ideal but separate endpoint that is difficult to isolate and was beyond the scope of this work. To address the referee's point, we will revise the manuscript to include an explicit limitations section that discusses the proxy nature of our metrics, the a priori development of the rubrics, and the value of future studies involving multi-physician review of subtle nuances. This provides a balanced framing of the evidence supporting safe use. revision: yes
Circularity Check
No circularity; empirical evaluation against external gold standards
full rationale
The paper develops AI chart summarization methods for thoracic tumor boards, evaluates them directly against physician-generated gold standard summaries and predefined fact-based scoring rubrics, reports deployment with post-deployment monitoring, and validates an LLM-as-judge approach by correlation with the same external rubrics. No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps exist; all results are grounded in independent human-created references and real-world deployment data rather than reducing to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multi-step summarization. The system first generated constrained per-note extracts (≤5 lines) capturing note date and key tumor board fields and then performed a final synthesis step to produce the final tumor board summary. 4. Low-autonomy multi-agent system. A multi-agent system retrieved notes once from the fixed 180-day window and followed detailed, cancer...
-
[2]
Educational Strategies to Promote Clinical Diagnostic Reasoning
Bowen JL. Educational Strategies to Promote Clinical Diagnostic Reasoning. New England Journal of Medicine 2006;355(21):2217–25. 10.1056/NEJMra054782 13. CHANG RW, BORDAGE G, CONNELL KJ. The importance of early problem representation during case presentations. Academic Medicine 1998;73(10):S109-111. 10.1097/00001888-199810000-00062 14. Merker L, Conroy S,...
-
[3]
McKinney Wes. Python for data analysis : data wrangling with pandas, NumPy, and IPython. O’Reilly Media, Inc.; 2018. 25. Wickham H, Averick M, Bryan J, et al. Welcome to the Tidyverse. J Open Source Softw 2019;4(43):1686. 10.21105/joss.01686 26. Hollander M, Wolfe D. Nonparametric Statistical Methods. 2nd ed. New York: John Wiley & Sons; 1999. 27. Benjami...
-
[4]
Note Date: - Date on which the note was written (if documented) - YYYY-MM-DD Format - If no explicit date is present, write Unknown (do NOT guess) 1) ID (if present): - Name (if present), age, sex in format 65M / 80F - Primary cancer diagnosis + site + histology/subtype - Stage (and staging system if stated) and year of diagnosis (if stated) - Key patholo...
work page 2021
-
[5]
Overall (Would you trust and use this summary for tumor board?) Give your holistic judgment of whether the summary is suitable for real-world tumor board use, considering relevance, style, and accuracy together. • 5 (Excellent): You would use it as-is; trustworthy, eWicient, and clinically useful with no needed edits. • 4 (Good): You would use it with min...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.