Recognition: unknown
Combating Pattern and Content Bias: Adversarial Feature Learning for Generalized AI-Generated Image Detection
Pith reviewed 2026-05-10 14:56 UTC · model grok-4.3
The pith
Adversarial feature learning suppresses pattern and content biases for improved generalization in detecting AI-generated images
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
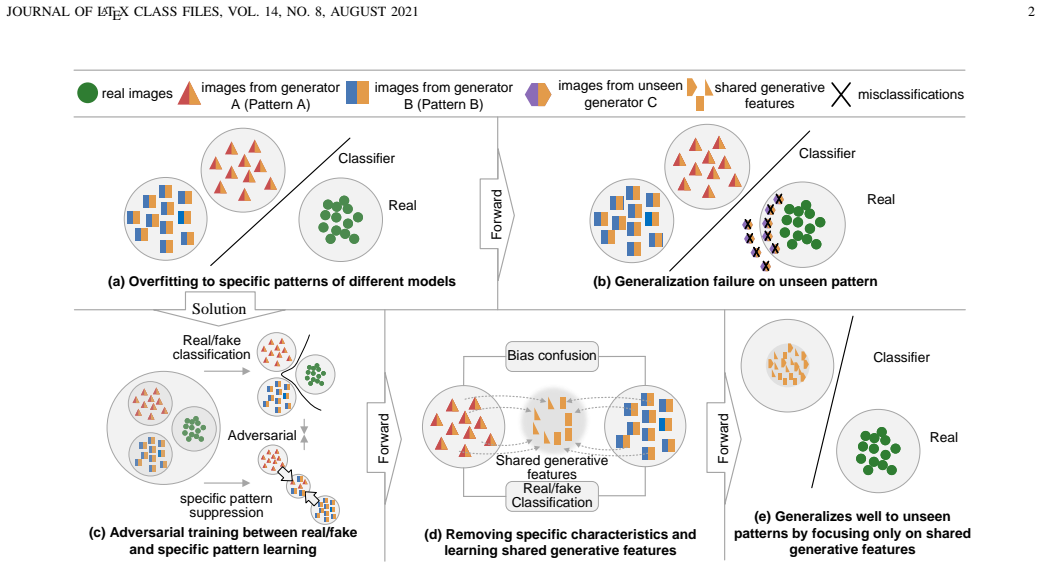
The MAFL framework adopts a pretrained multimodal image encoder as the feature extraction backbone, constructs a real-fake feature learning network, and designs an adversarial bias-learning branch equipped with a multi-dimensional adversarial loss, forming an adversarial training mechanism between authenticity-discriminative feature learning and bias feature learning. By suppressing generation-pattern and content biases, MAFL guides the model to focus on the generative features shared across different generative models, thereby effectively capturing the fundamental differences between real and generated images, enhancing cross-model generalization, and substantially reducing the reliance on
What carries the argument
Multi-dimensional Adversarial Feature Learning (MAFL) framework with an adversarial bias-learning branch and multi-dimensional adversarial loss that creates opposing objectives between bias identification and authenticity feature extraction
If this is right
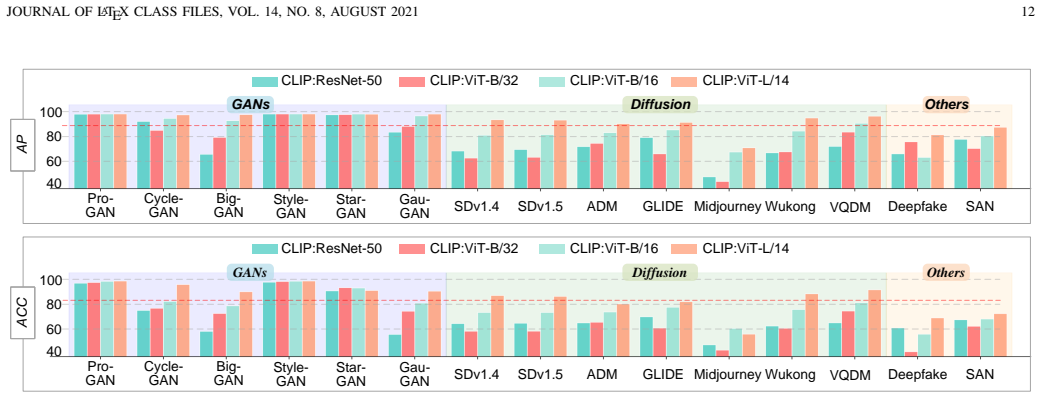
- The model outperforms existing state-of-the-art approaches by 10.89% in accuracy and 8.57% in Average Precision.
- Detection accuracy exceeds 80% on public datasets even when trained with only 320 images.
- The approach enhances cross-model generalization by directing attention to features shared across different generative models.
- Reliance on large-scale training data is substantially reduced while maintaining effective real-versus-fake discrimination.
Where Pith is reading between the lines
- If the bias separation proves stable, the same adversarial branch design could transfer to detection of other synthetic media such as video or audio.
- Pretrained multimodal encoders may serve as effective starting points for additional forensic tasks that suffer from domain-specific spurious cues.
- The framework suggests a path toward detectors that require infrequent retraining when new generators appear.
Load-bearing premise
The adversarial bias-learning branch successfully separates and suppresses generation-pattern and content biases while preserving authenticity-discriminative features without introducing new instabilities or trade-offs.
What would settle it
Train the model exclusively on images from a limited set of generators, then evaluate accuracy on images from a new generative model never encountered during training or validation to check if the reported gains over baselines hold.
Figures






read the original abstract
In recent years, the rapid development of generative artificial intelligence technology has significantly lowered the barrier to creating high-quality fake images, posing a serious challenge to information authenticity and credibility. Existing generated image detection methods typically enhance generalization through model architecture or network design. However, their generalization performance remains susceptible to data bias, as the training data may drive models to fit specific generative patterns and content rather than the common features shared by images from different generative models (asymmetric bias learning). To address this issue, we propose a Multi-dimensional Adversarial Feature Learning (MAFL) framework. The framework adopts a pretrained multimodal image encoder as the feature extraction backbone, constructs a real-fake feature learning network, and designs an adversarial bias-learning branch equipped with a multi-dimensional adversarial loss, forming an adversarial training mechanism between authenticity-discriminative feature learning and bias feature learning. By suppressing generation-pattern and content biases, MAFL guides the model to focus on the generative features shared across different generative models, thereby effectively capturing the fundamental differences between real and generated images, enhancing cross-model generalization, and substantially reducing the reliance on large-scale training data. Through extensive experimental validation, our method outperforms existing state-of-the-art approaches by 10.89% in accuracy and 8.57% in Average Precision (AP). Notably, even when trained with only 320 images, it can still achieve over 80% detection accuracy on public datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Multi-dimensional Adversarial Feature Learning (MAFL) framework for generalized AI-generated image detection. It uses a pretrained multimodal image encoder as backbone, a real-fake feature learning network, and an adversarial bias-learning branch with multi-dimensional adversarial loss to suppress generation-pattern and content biases (termed asymmetric bias learning), guiding the model toward shared generative features. Experiments report outperforming SOTA by 10.89% accuracy and 8.57% AP, with >80% accuracy even when trained on only 320 images.
Significance. If the adversarial mechanism reliably suppresses biases while preserving discriminative power, the result would be significant for developing data-efficient, cross-model robust detectors that address a core limitation of current methods fitting to specific patterns rather than fundamental real/fake differences.
major comments (2)
- [Method (adversarial training mechanism and multi-dimensional adversarial loss)] The central claim depends on the adversarial bias-learning branch suppressing generation-pattern and content biases without degrading authenticity-discriminative features or introducing instabilities. No theoretical bounds, ablation on loss weighting, gradient reversal strength, or stability analysis is provided, especially critical for the 320-image low-data regime where adversarial dynamics are prone to failure (either over-suppression or insufficient bias removal).
- [Experiments and results] Reported gains of 10.89% accuracy and 8.57% AP, plus the low-data result, lack details on baseline re-implementations, statistical tests, exact dataset splits, and controls for evaluation bias, undermining verification that improvements are robust rather than due to unstated factors.
minor comments (1)
- [Abstract] The term 'asymmetric bias learning' is introduced in the abstract but not formally defined or contrasted with symmetric alternatives in the provided description.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of our work on the MAFL framework. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Method (adversarial training mechanism and multi-dimensional adversarial loss)] The central claim depends on the adversarial bias-learning branch suppressing generation-pattern and content biases without degrading authenticity-discriminative features or introducing instabilities. No theoretical bounds, ablation on loss weighting, gradient reversal strength, or stability analysis is provided, especially critical for the 320-image low-data regime where adversarial dynamics are prone to failure (either over-suppression or insufficient bias removal).
Authors: We appreciate the referee highlighting the need for deeper validation of the adversarial mechanism. Our empirical results, including consistent performance exceeding 80% accuracy in the 320-image regime across multiple datasets, demonstrate that the multi-dimensional adversarial loss effectively suppresses biases while retaining discriminative power without evident instabilities. That said, we agree additional analysis would enhance the manuscript. In the revision, we will add ablations varying loss weighting and gradient reversal strength, along with stability metrics (e.g., variance across random seeds) specifically for the low-data setting. As the work is primarily empirical rather than theoretical, we do not provide formal bounds but will include a brief discussion of potential future theoretical directions. revision: partial
-
Referee: [Experiments and results] Reported gains of 10.89% accuracy and 8.57% AP, plus the low-data result, lack details on baseline re-implementations, statistical tests, exact dataset splits, and controls for evaluation bias, undermining verification that improvements are robust rather than due to unstated factors.
Authors: We agree that greater experimental transparency is necessary to allow full verification of the reported gains. The revised manuscript will expand the experimental section with: detailed re-implementation protocols for all baselines (including hyperparameters and training settings); statistical significance tests (e.g., paired t-tests over five independent runs); precise descriptions of dataset splits, preprocessing, and evaluation protocols; and additional controls such as cross-dataset validation to address potential evaluation bias. These changes will substantiate that the improvements stem from the proposed MAFL framework. revision: yes
Circularity Check
No circularity: empirical adversarial training procedure with experimental validation
full rationale
The paper proposes an empirical MAFL framework consisting of a pretrained multimodal encoder backbone, a real-fake feature learning network, and an adversarial bias-learning branch with multi-dimensional adversarial loss. All central claims (outperformance by 10.89% accuracy / 8.57% AP, >80% accuracy with 320 training images) are supported by reported experimental results on public datasets rather than any closed-form derivation. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the derivation chain; the method is a standard adversarial training recipe evaluated through benchmarks and is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A pretrained multimodal image encoder provides features that can be separated into authenticity-discriminative and bias components
Reference graph
Works this paper leans on
-
[1]
Fidavl: Fake image detection and attribution using vision- language model,
M. Keita, W. Hamidouche, H. B. Eutamene, A. Taleb-Ahmed, and A. Hadid, “Fidavl: Fake image detection and attribution using vision- language model,” inInternational Conference on Pattern Recognition. Springer, 2025, pp. 160–176
2025
-
[2]
Faces blind your eyes: Unveiling the content-irrelevant synthetic arti- facts for deepfake detection,
X. Fu, B. Fu, S. Chen, T. Yao, Y . Wang, S. Ding, X. Liang, and X. Li, “Faces blind your eyes: Unveiling the content-irrelevant synthetic arti- facts for deepfake detection,”IEEE Transactions on Image Processing, 2025
2025
-
[3]
Z. Yan, J. Wang, Z. Wang, P. Jin, K.-Y . Zhang, S. Chen, T. Yao, S. Ding, B. Wu, and L. Yuan, “Effort: Efficient orthogonal modeling for general- izable ai-generated image detection,”arXiv preprint arXiv:2411.15633, 2024
-
[4]
Breaking semantic artifacts for generalized ai-generated image detec- tion,
C. Zheng, C. Lin, Z. Zhao, H. Wang, X. Guo, S. Liu, and C. Shen, “Breaking semantic artifacts for generalized ai-generated image detec- tion,”Advances in Neural Information Processing Systems, vol. 37, pp. 59 570–59 596, 2024
2024
-
[5]
Online detection of ai-generated images,
D. C. Epstein, I. Jain, O. Wang, and R. Zhang, “Online detection of ai-generated images,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 382–392
2023
-
[6]
Generalizable deepfake detection with phase-based motion analysis,
E. Prashnani, M. Goebel, and B. Manjunath, “Generalizable deepfake detection with phase-based motion analysis,”IEEE Transactions on Image Processing, 2024
2024
-
[7]
What makes fake images de- tectable? understanding properties that generalize,
L. Chai, D. Bau, S.-N. Lim, and P. Isola, “What makes fake images de- tectable? understanding properties that generalize,” inComputer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXVI 16. Springer, 2020, pp. 103–120. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13
2020
-
[8]
Cnn- generated images are surprisingly easy to spot... for now,
S.-Y . Wang, O. Wang, R. Zhang, A. Owens, and A. A. Efros, “Cnn- generated images are surprisingly easy to spot... for now,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 8695–8704
2020
-
[9]
Do gans leave artificial fingerprints?
F. Marra, D. Gragnaniello, L. Verdoliva, and G. Poggi, “Do gans leave artificial fingerprints?” in2019 IEEE conference on multimedia information processing and retrieval (MIPR). IEEE, 2019, pp. 506– 511
2019
-
[10]
Attributing fake images to gans: Learn- ing and analyzing gan fingerprints,
N. Yu, L. S. Davis, and M. Fritz, “Attributing fake images to gans: Learn- ing and analyzing gan fingerprints,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 7556–7566
2019
-
[11]
Dire for diffusion-generated image detection,
Z. Wang, J. Bao, W. Zhou, W. Wang, H. Hu, H. Chen, and H. Li, “Dire for diffusion-generated image detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 445–22 455
2023
-
[13]
Ucf: Uncovering common features for generalizable deepfake detection,
Z. Yan, Y . Zhang, Y . Fan, and B. Wu, “Ucf: Uncovering common features for generalizable deepfake detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 412–22 423
2023
-
[15]
Towards universal fake image detec- tors that generalize across generative models,
U. Ojha, Y . Li, and Y . J. Lee, “Towards universal fake image detec- tors that generalize across generative models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 24 480–24 489
2023
-
[16]
Clipping the deception: Adapting vision-language models for universal deepfake detection,
S. A. Khan and D.-T. Dang-Nguyen, “Clipping the deception: Adapting vision-language models for universal deepfake detection,” inProceed- ings of the 2024 International Conference on Multimedia Retrieval, 2024, pp. 1006–1015
2024
-
[17]
Face forgery detection with clip-enhanced multi-encoder distillation
C. Peng, T. Yan, D. Liu, N. Wang, R. Hu, and X. Gao, “Face forgery detection with clip-enhanced multi-encoder distillation.”IEEE Transactions on Image Processing: a Publication of the IEEE Signal Processing Society, 2025
2025
-
[18]
Leveraging frequency analysis for deep fake image recogni- tion,
J. Frank, T. Eisenhofer, L. Sch ¨onherr, A. Fischer, D. Kolossa, and T. Holz, “Leveraging frequency analysis for deep fake image recogni- tion,” inInternational conference on machine learning. PMLR, 2020, pp. 3247–3258
2020
-
[19]
Detecting generated images by real images,
B. Liu, F. Yang, X. Bi, B. Xiao, W. Li, and X. Gao, “Detecting generated images by real images,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 95–110
2022
-
[20]
Detecting generated images by real images only,
X. Bi, B. Liu, F. Yang, B. Xiao, W. Li, G. Huang, and P. C. Cosman, “Detecting generated images by real images only,”arXiv preprint arXiv:2311.00962, 2023
-
[21]
Learning on gradients: Generalized artifacts representation for gan-generated images detection,
C. Tan, Y . Zhao, S. Wei, G. Gu, and Y . Wei, “Learning on gradients: Generalized artifacts representation for gan-generated images detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 12 105–12 114
2023
-
[22]
Rethinking the up- sampling operations in cnn-based generative network for generalizable deepfake detection,
C. Tan, Y . Zhao, S. Wei, G. Gu, P. Liu, and Y . Wei, “Rethinking the up- sampling operations in cnn-based generative network for generalizable deepfake detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 28 130–28 139
2024
-
[23]
Multi- attentional deepfake detection,
H. Zhao, W. Zhou, D. Chen, T. Wei, W. Zhang, and N. Yu, “Multi- attentional deepfake detection,” inProceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, 2021, pp. 2185–2194
2021
-
[24]
Fusing global and local features for generalized ai-synthesized image detection,
Y . Ju, S. Jia, L. Ke, H. Xue, K. Nagano, and S. Lyu, “Fusing global and local features for generalized ai-synthesized image detection,” in2022 IEEE International Conference on Image Processing (ICIP). IEEE, 2022, pp. 3465–3469
2022
-
[25]
Scaling laws of synthetic images for model training... for now,
L. Fan, K. Chen, D. Krishnan, D. Katabi, P. Isola, and Y . Tian, “Scaling laws of synthetic images for model training... for now,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 7382–7392
2024
-
[26]
Zero-shot detection of ai-generated images,
D. Cozzolino, G. Poggi, M. Nießner, and L. Verdoliva, “Zero-shot detection of ai-generated images,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 54–72
2024
-
[27]
Exploring the adversarial robustness of clip for ai-generated image de- tection,
V . De Rosa, F. Guillaro, G. Poggi, D. Cozzolino, and L. Verdoliva, “Exploring the adversarial robustness of clip for ai-generated image de- tection,” in2024 IEEE International Workshop on Information Forensics and Security (WIFS). IEEE, 2024, pp. 1–6
2024
-
[28]
Rais- ing the bar of ai-generated image detection with clip,
D. Cozzolino, G. Poggi, R. Corvi, M. Nießner, and L. Verdoliva, “Rais- ing the bar of ai-generated image detection with clip,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4356–4366
2024
-
[29]
A bias-free training paradigm for more general ai-generated image detection,
F. Guillaro, G. Zingarini, B. Usman, A. Sud, D. Cozzolino, and L. Ver- doliva, “A bias-free training paradigm for more general ai-generated image detection,”arXiv preprint arXiv:2412.17671, 2024
-
[30]
On information and sufficiency,
S. Kullback and R. A. Leibler, “On information and sufficiency,”The annals of mathematical statistics, vol. 22, no. 1, pp. 79–86, 1951
1951
-
[31]
Z. Zhou, Y . Luo, Y . Wu, K. Sun, J. Ji, K. Yan, S. Ding, X. Sun, Y . Wu, and R. Ji, “Aigi-holmes: Towards explainable and generalizable ai-generated image detection via multimodal large language models,” arXiv preprint arXiv:2507.02664, 2025
-
[32]
Genimage: A million-scale benchmark for detecting ai- generated image,
M. Zhu, H. Chen, Q. Yan, X. Huang, G. Lin, W. Li, Z. Tu, H. Hu, J. Hu, and Y . Wang, “Genimage: A million-scale benchmark for detecting ai- generated image,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[33]
B. F. Labs, “Flux,” https://github.com/black-forest-labs/flux, 2024
2024
-
[34]
Pixart-σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation,
J. Chen, C. Ge, E. Xie, Y . Wu, L. Yao, X. Ren, Z. Wang, P. Luo, H. Lu, and Z. Li, “Pixart-σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 74–91
2024
-
[35]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boeselet al., “Scaling rectified flow transformers for high-resolution image synthesis,” inForty-first international conference on machine learning, 2024
2024
-
[36]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
P. Sun, Y . Jiang, S. Chen, S. Zhang, B. Peng, P. Luo, and Z. Yuan, “Autoregressive model beats diffusion: Llama for scalable image gener- ation,”arXiv preprint arXiv:2406.06525, 2024
work page internal anchor Pith review arXiv 2024
-
[37]
Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis,
J. Han, J. Liu, Y . Jiang, B. Yan, Y . Zhang, Z. Yuan, B. Peng, and X. Liu, “Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 15 733–15 744
2025
-
[38]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
X. Chen, Z. Wu, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, and C. Ruan, “Janus-pro: Unified multimodal understanding and generation with data and model scaling,”arXiv preprint arXiv:2501.17811, 2025
work page internal anchor Pith review arXiv 2025
-
[39]
Visual autore- gressive modeling: Scalable image generation via next-scale prediction,
K. Tian, Y . Jiang, Z. Yuan, B. Peng, and L. Wang, “Visual autore- gressive modeling: Scalable image generation via next-scale prediction,” Advances in neural information processing systems, vol. 37, pp. 84 839– 84 865, 2024
2024
-
[40]
Janus: Decoupling visual encoding for unified multi- modal understanding and generation,
C. Wu, X. Chen, Z. Wu, Y . Ma, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, C. Ruanet al., “Janus: Decoupling visual encoding for unified multi- modal understanding and generation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12 966–12 977
2025
-
[41]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
J. Xie, W. Mao, Z. Bai, D. J. Zhang, W. Wang, K. Q. Lin, Y . Gu, Z. Chen, Z. Yang, and M. Z. Shou, “Show-o: One single transformer to unify multimodal understanding and generation,”arXiv preprint arXiv:2408.12528, 2024
work page internal anchor Pith review arXiv 2024
-
[42]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. Springer, 2014, pp. 740–755
2014
-
[43]
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
F. Yu, A. Seff, Y . Zhang, S. Song, T. Funkhouser, and J. Xiao, “Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop,”arXiv preprint arXiv:1506.03365, 2015
work page internal anchor Pith review arXiv 2015
-
[44]
Imagenet large scale visual recognition challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernsteinet al., “Imagenet large scale visual recognition challenge,”International journal of computer vision, vol. 115, pp. 211–252, 2015
2015
-
[45]
Deep learning face attributes in the wild,
Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” inProceedings of the IEEE international conference on computer vision, 2015, pp. 3730–3738
2015
-
[46]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
T. Karras, “Progressive growing of gans for improved quality, stability, and variation,”arXiv preprint arXiv:1710.10196, 2017
work page internal anchor Pith review arXiv 2017
-
[47]
Faceforensics++: Learning to detect manipulated facial images,
A. Rossler, D. Cozzolino, L. Verdoliva, C. Riess, J. Thies, and M. Nießner, “Faceforensics++: Learning to detect manipulated facial images,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 1–11
2019
-
[48]
Lareˆ 2: Latent reconstruction error based method for diffusion-generated image detection,
Y . Luo, J. Du, K. Yan, and S. Ding, “Lareˆ 2: Latent reconstruction error based method for diffusion-generated image detection,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 17 006–17 015
2024
-
[49]
Towards universal ai-generated image detection by variational information bottleneck net- work,
H. Zhang, Q. He, X. Bi, W. Li, B. Liu, and B. Xiao, “Towards universal ai-generated image detection by variational information bottleneck net- work,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 23 828–23 837
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.