Tamper-Proofing with Self-Modifying Code
Pith reviewed 2026-05-10 16:20 UTC · model grok-4.3
The pith
Treating timing and self-introspection as observables makes non-self-modifying simulation of timed self-modifying code detectably expensive on commodity hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Once timing, ordering, and self-introspective effects are treated as observables, a practically faithful non-SMC reproduction of timed SMC becomes detectably expensive on commodity systems. The proposed model combines introspective and polymorphic SMC, reliable clocks, and runtime timing predicates to bind integrity checks to execution behavior, with x86-64 primitives for checksum-driven self-patching that preserve tamper-detection value.
What carries the argument
checksum-driven self-patching primitives using introspective and polymorphic self-modifying code together with timing predicates and reliable clocks to enforce integrity checks during execution.
Load-bearing premise
External timing inputs, concurrency, and microarchitectural state on modern processors make non-SMC simulation of timed SMC detectably expensive while the checksum-driven self-patching primitives preserve tamper-detection value without catastrophic pipeline clears.
What would settle it
Empirical evidence that a non-SMC implementation can replicate the exact timing behavior, ordering, and self-introspective effects of the SMC version at similar or lower computational cost on the same hardware, or performance-monitoring counters showing indistinguishable microarchitectural activity.
Figures
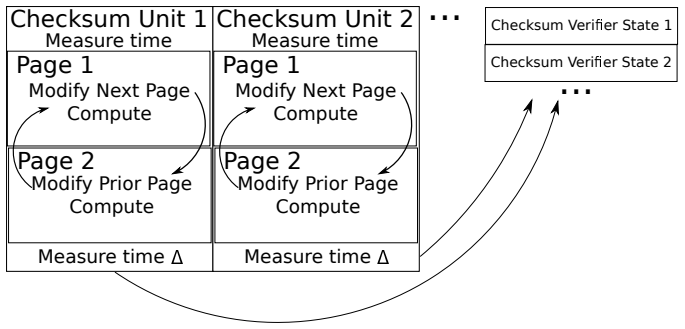


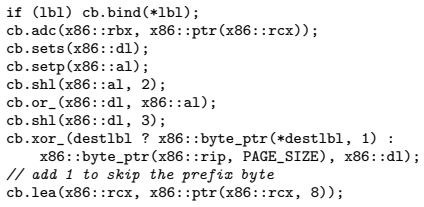
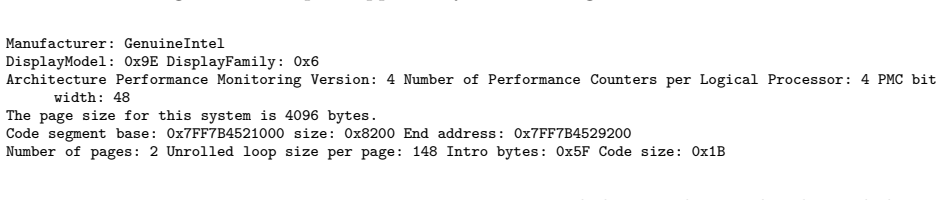
read the original abstract
Classical computability theory tells us that self-modifying code (SMC) on a deterministic universal Turing machine can be simulated by non-SMC code on the same model. That abstraction, however, omits the external timing inputs, concurrency, and microarchitectural state that dominate practical execution on modern processors. We argue that once timing, ordering, and self-introspective effects are treated as observables, a practically faithful non-SMC reproduction of timed SMC becomes detectably expensive on commodity systems. We present a tamper-proofing model that combines introspective and polymorphic SMC, reliable clocks, and runtime timing predicates to bind integrity checks to execution behavior. We distinguish static and dynamic SMC generation, characterize the timing semantics needed to avoid catastrophic pipeline clears, and give x86-64 design primitives for checksum-driven self-patching. We also report timer measurements, performance comparisons, and performance-monitoring counter evidence showing that careful engineering -- especially loop unrolling and cross-page modification -- substantially reduces the overhead of SMC while preserving its tamper-detection value. The paper concludes with an efficiency analysis, a threat model, and deployment guidance for trusted code executing in untrusted environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that while classical computability theory permits simulation of self-modifying code (SMC) by non-SMC code on a deterministic Turing machine, treating external timing inputs, concurrency, and microarchitectural state as observables renders a practically faithful non-SMC reproduction of timed SMC detectably expensive on commodity x86-64 systems. It proposes a tamper-proofing model combining introspective and polymorphic SMC with reliable clocks and runtime timing predicates, distinguishes static/dynamic SMC generation, characterizes timing semantics to avoid pipeline clears, supplies checksum-driven self-patching primitives, and reports timer measurements, performance comparisons, and PMC evidence indicating that optimizations such as loop unrolling and cross-page modification substantially reduce SMC overhead while preserving tamper-detection value.
Significance. If the central claim holds, the work supplies a concrete, hardware-grounded defense primitive for code integrity in untrusted environments that exploits observables difficult to replicate without actual self-modification. The reported empirical reductions in SMC overhead via targeted engineering constitute a useful practical contribution, provided the non-SMC baselines are shown to be representative.
major comments (2)
- [Performance comparisons and PMC evidence] Performance comparisons and PMC evidence sections: the non-SMC baselines used for contrast are unspecified. This is load-bearing for the claim that non-SMC reproduction is detectably expensive, because an adversary maintaining equivalent shadow timing state and ordering via rdtsc + PMC sampling (without self-modification) might incur lower cost than asserted.
- [Abstract and timing-semantics characterization] Abstract and timing-semantics characterization: the paper states that timing predicates and checksum-driven self-patching avoid catastrophic pipeline clears on the SMC side, yet provides no corresponding argument or experiment demonstrating why an equivalent non-SMC construction cannot achieve comparable avoidance while preserving the claimed observables.
minor comments (1)
- [Abstract] The abstract references 'timer measurements, performance comparisons, and performance-monitoring counter evidence' but does not indicate the corresponding tables or figures; explicit cross-references would improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments point by point below, clarifying the non-SMC baselines and strengthening the timing-semantics discussion while preserving the manuscript's core claims.
read point-by-point responses
-
Referee: Performance comparisons and PMC evidence sections: the non-SMC baselines used for contrast are unspecified. This is load-bearing for the claim that non-SMC reproduction is detectably expensive, because an adversary maintaining equivalent shadow timing state and ordering via rdtsc + PMC sampling (without self-modification) might incur lower cost than asserted.
Authors: We agree that explicit specification of the non-SMC baselines is necessary to support the central claim. In the revised manuscript we will add a dedicated subsection detailing the baseline constructions: equivalent tamper-detection logic implemented as static code that uses rdtsc for timing, explicit PMC reads to track microarchitectural state, and shadow data structures to emulate the ordering and introspection effects that SMC achieves through direct modification. Our existing PMC data already show that these non-SMC versions incur additional instruction overhead and higher pipeline-stall rates precisely because they must maintain and consult the shadow state at every predicate evaluation. We will also discuss why an adversary limited to rdtsc + PMC sampling cannot replicate the full set of observables without either (a) introducing detectable timing skew or (b) effectively performing runtime code generation, which collapses back to SMC. Revision will include these clarifications and any additional comparative measurements required for completeness. revision: yes
-
Referee: Abstract and timing-semantics characterization: the paper states that timing predicates and checksum-driven self-patching avoid catastrophic pipeline clears on the SMC side, yet provides no corresponding argument or experiment demonstrating why an equivalent non-SMC construction cannot achieve comparable avoidance while preserving the claimed observables.
Authors: The timing-semantics section already characterizes the safe modification points that SMC exploits via runtime checksums and timing predicates. We will expand this section with an explicit argument showing why a faithful non-SMC equivalent cannot match the same avoidance cost: any static or precomputed non-SMC implementation must either (i) duplicate code paths for every possible timing outcome (inducing branch mispredictions and pipeline flushes) or (ii) perform equivalent dynamic patching at runtime, which reintroduces self-modification and its associated observables. The existing PMC evidence already indicates lower stall rates for the SMC variants precisely because the self-patching occurs at architecturally safe points determined by the predicates. We will add this comparative reasoning to the manuscript; no new experiments are required, as the distinction follows directly from the timing model and the reported counter data. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's argument begins from classical computability (SMC simulable by non-SMC on a deterministic UTM) and contrasts it with practical observables (timing inputs, concurrency, microarchitectural state) on commodity hardware. It then supplies design primitives (checksum-driven self-patching, timing predicates, static vs. dynamic SMC generation) and reports empirical measurements (timer data, performance comparisons, PMC evidence). No equations, fitted parameters, or self-referential definitions appear; no prediction is constructed by renaming or fitting an input; no load-bearing self-citation or uniqueness theorem is invoked. The central claim—that faithful non-SMC reproduction is detectably expensive—rests on hardware observables and reported benchmarks rather than reducing to definitional equivalence or prior author results. This is a standard non-circular contrast between theory and practice.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Classical computability theory: self-modifying code on a deterministic universal Turing machine can be simulated by non-SMC code
- domain assumption Modern processors are dominated by external timing inputs, concurrency, and microarchitectural state that affect observable execution behavior
Reference graph
Works this paper leans on
-
[1]
Marvin L. Minsky. Computation: Finite and Infinite Machines . Prentice-Hall, Englewood Cliffs, NJ, 1967
work page 1967
-
[2]
John E. Hopcroft and Jeffrey D. Ullman. Introduction to Automata Theory, Languages, and Computation. Addison-Wesley, Reading, MA, 1979
work page 1979
-
[3]
Computational Complexity: A Modern Approach
Sanjeev Arora and Boaz Barak. Computational Complexity: A Modern Approach . Cambridge University Press, Cambridge, 2009
work page 2009
-
[4]
A software protection method b ased on computer fingerprint and asymmetric encryption
Hua Shan Tan and Yang Yang. A software protection method b ased on computer fingerprint and asymmetric encryption. In Information Technology Applications in Industry, Compute r Engineering and Materials Science , volume 756 of Advanced Materials Research, pages 1215–
-
[5]
Trans Tech Publications Ltd, 10 2013
work page 2013
-
[6]
A true r andom number generator based on mouse movement and chaotic cryptography
Yue Hu, Xiaofeng Liao, Kwok wo Wong, and Qing Zhou. A true r andom number generator based on mouse movement and chaotic cryptography. Chaos, Solitons & Fractals , 40(5):2286– 2293, 2009
work page 2009
-
[7]
C.S. Collberg and C. Thomborson. Watermarking, tamper- proofing, and obfuscation - tools for software protection. IEEE Transactions on Software Engineering , 28(8):735–746, 2002
work page 2002
-
[8]
J.T. Giffin, M. Christodorescu, and L. Kruger. Strengthen ing software self-checksumming via self-modifying code. In 21st Annual Computer Security Applications Conference (AC SAC’05), pages 10 pp.–32, 2005
work page 2005
-
[9]
Scanclave: Verifying application r untime integrity in untrusted environ- ments
Mathias Morbitzer. Scanclave: Verifying application r untime integrity in untrusted environ- ments. In 2019 IEEE 28th International Conference on Enabling Techno logies: Infrastructure for Collaborative Enterprises (WETICE) , pages 198–203, 2019
work page 2019
-
[10]
Weaver, Dan Terpstra, and Shirley Moore
Vincent M. Weaver, Dan Terpstra, and Shirley Moore. Non- determinism and overcount on modern hardware performance counter implementations. In 2013 IEEE International Sympo- sium on Performance Analysis of Systems and Software (ISPAS S), pages 215–224, 2013
work page 2013
-
[11]
AsmJit project: Low-latency machine c ode generation — asmjit.com
AsmJit Project. AsmJit project: Low-latency machine c ode generation — asmjit.com. https://asmjit.com/, 2023. [Accessed 19-Jun-2023]
work page 2023
-
[12]
Intel 64 and IA-32 Architectures Software Developer’s Manu al - Volume 3B
Intel Corporation. Intel 64 and IA-32 Architectures Software Developer’s Manu al - Volume 3B. Intel Corporation, September 2016
work page 2016
-
[13]
Inc. Advanced Micro Devices. AMD64 Architecture Programmer’s Manual Volume 2: System Programming. Advanced Micro Devices, Inc., January 2023
work page 2023
-
[14]
What’s WinRing0 — openlibsys.org
OpenLibSys.org. What’s WinRing0 — openlibsys.org. https://openlibsys.org/manual/WhatIsWinRing0.html, 2023. [Accessed 20-Jun-2023]
work page 2023
-
[15]
AsmJit Project. AsmGrid — asmjit.com. https://asmjit.com/asmgrid/, 2023. [Accessed 19-Jun-2023]
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.