Recognition: unknown
X-VC: Zero-shot Streaming Voice Conversion in Codec Space
Pith reviewed 2026-05-10 14:16 UTC · model grok-4.3
The pith
X-VC converts speech to unseen voices in one step inside a neural codec's latent space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
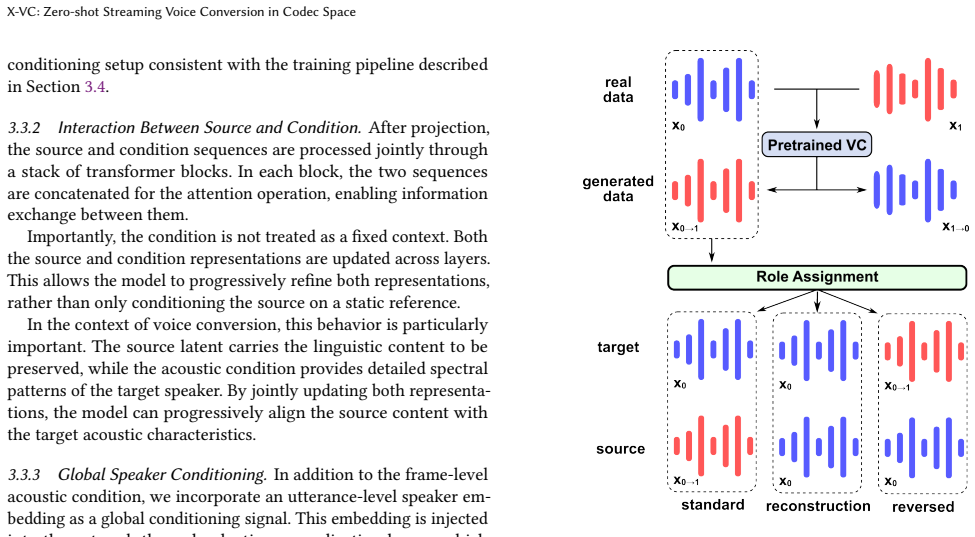
X-VC achieves one-step conversion by using a dual-conditioning acoustic converter that jointly models source codec latents and frame-level acoustic conditions derived from target reference speech, while injecting utterance-level target speaker information through adaptive normalization. Training employs generated paired data and a role-assignment strategy combining standard, reconstruction, and reversed modes to reduce the train-inference gap. Streaming inference uses a chunkwise scheme with overlap smoothing aligned to the codec's segment-based training paradigm. On Seed-TTS-Eval, this yields the best streaming word error rates in both English and Chinese, strong speaker similarity in same-
What carries the argument
dual-conditioning acoustic converter that jointly processes source codec latents with target acoustic conditions and adaptive normalization for speaker identity
If this is right
- One-step codec latent conversion becomes viable for interactive zero-shot VC without separate vocoder stages.
- The role-assignment training reduces mismatch for unseen targets in streaming setups.
- Chunkwise inference aligned with codec training delivers low real-time factor while preserving quality.
- Cross-lingual speaker similarity holds without language-specific retraining.
Where Pith is reading between the lines
- Advances in general neural codecs could directly lift VC performance across more audio domains.
- The method might extend to other low-latency generative tasks such as real-time speech enhancement.
- Integration into end-to-end pipelines could eliminate the need for separate acoustic feature extractors.
Load-bearing premise
Training on generated paired data with the role-assignment strategy sufficiently prepares the model for truly unseen target speakers under real streaming conditions.
What would settle it
Run the system in true streaming mode on live recordings from real unseen human target speakers providing short references and measure if streaming WER rises above the reported levels or speaker similarity falls sharply.
Figures



read the original abstract
Zero-shot voice conversion (VC) aims to convert a source utterance into the voice of an unseen target speaker while preserving its linguistic content. Although recent systems have improved conversion quality, building zero-shot VC systems for interactive scenarios remains challenging because high-fidelity speaker transfer and low-latency streaming inference are difficult to achieve simultaneously. In this work, we present X-VC, a zero-shot streaming VC system that performs one-step conversion in the latent space of a pretrained neural codec. X-VC uses a dual-conditioning acoustic converter that jointly models source codec latents and frame-level acoustic conditions derived from target reference speech, while injecting utterance-level target speaker information through adaptive normalization. To reduce the mismatch between training and inference, we train the model with generated paired data and a role-assignment strategy that combines standard, reconstruction, and reversed modes. For streaming inference, we further adopt a chunkwise inference scheme with overlap smoothing that is aligned with the segment-based training paradigm of the codec. Experiments on Seed-TTS-Eval show that X-VC achieves the best streaming WER in both English and Chinese, strong speaker similarity in same-language and cross-lingual settings, and substantially lower offline real-time factor than the compared baselines. These results suggest that codec-space one-step conversion is a practical approach for building high-quality low-latency zero-shot VC systems. Our audio samples, code and checkpoints are released at https://github.com/Jerrister/X-VC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces X-VC, a zero-shot streaming voice conversion system performing one-step conversion in the latent space of a pretrained neural codec. It employs a dual-conditioning acoustic converter jointly modeling source codec latents and frame-level acoustic conditions from target reference speech, with utterance-level speaker information injected via adaptive normalization. Training uses generated paired data and a role-assignment strategy (standard, reconstruction, and reversed modes) to reduce train-inference mismatch, combined with chunkwise inference and overlap smoothing for streaming. On Seed-TTS-Eval, it claims the best streaming WER in English and Chinese, strong speaker similarity (including cross-lingual), and substantially lower offline RTF than baselines.
Significance. If the results hold under rigorous validation, this would be a notable contribution to practical zero-shot VC by showing that codec-space one-step conversion with targeted training can simultaneously deliver high fidelity, cross-lingual transfer, and low-latency streaming suitable for interactive use. The open release of code, checkpoints, and audio samples is a clear strength supporting reproducibility.
major comments (2)
- [Abstract and §4] Abstract and §4: The claim of achieving the 'best streaming WER in both English and Chinese' and 'strong speaker similarity' is load-bearing for the central experimental result, yet the manuscript provides no details on the exact baselines, data splits, number of evaluation samples, error bars, or statistical significance tests, preventing verification of the comparative superiority.
- [§3] §3 (Method, role-assignment and training): The dual-conditioning converter plus chunkwise inference is presented as enabling true zero-shot streaming on unseen targets, but the generated paired data with role-assignment (standard/reconstruction/reversed) is not validated against real acoustic distributions or ablated for its effect on closing the train-inference gap, especially in cross-lingual settings and low-latency chunked conditions; this assumption is central to the generalization claims.
minor comments (2)
- A dedicated table or figure summarizing exact WER, similarity scores, and RTF values with all baselines would improve clarity of the comparative results.
- The description of overlap smoothing in chunkwise inference could benefit from a short equation or pseudocode to make the alignment with codec segment training explicit.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and detailed comments. We address each major point below and will revise the manuscript accordingly to improve transparency and validation of our claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4: The claim of achieving the 'best streaming WER in both English and Chinese' and 'strong speaker similarity' is load-bearing for the central experimental result, yet the manuscript provides no details on the exact baselines, data splits, number of evaluation samples, error bars, or statistical significance tests, preventing verification of the comparative superiority.
Authors: We agree that the experimental section requires more precise documentation to support the reported superiority. In the revised manuscript, we will expand §4 with: the full list of baselines and their configurations; the exact data splits and number of evaluation samples from Seed-TTS-Eval (specifying counts for English and Chinese); standard deviations across multiple runs presented as error bars; and results of statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests) on WER and speaker similarity metrics. These additions will enable direct verification of the claims. revision: yes
-
Referee: [§3] §3 (Method, role-assignment and training): The dual-conditioning converter plus chunkwise inference is presented as enabling true zero-shot streaming on unseen targets, but the generated paired data with role-assignment (standard/reconstruction/reversed) is not validated against real acoustic distributions or ablated for its effect on closing the train-inference gap, especially in cross-lingual settings and low-latency chunked conditions; this assumption is central to the generalization claims.
Authors: We acknowledge the value of explicit validation for the role-assignment strategy. While zero-shot settings inherently lack real paired data for unseen speakers, making direct distributional comparisons difficult, the strategy is intended to mitigate train-inference mismatch through mode switching. In the revision, we will add an ablation study (in §4 or an appendix) quantifying the impact of each training mode on WER, speaker similarity, and cross-lingual performance, including results under different chunk sizes to address low-latency conditions. We will also include a brief analysis of how the generated pairs approximate real acoustic properties based on reconstruction fidelity. revision: yes
Circularity Check
No circularity detected; claims rest on empirical validation
full rationale
The paper presents X-VC as an architectural system (dual-conditioning converter in pretrained codec space, role-assignment training on generated pairs, chunkwise streaming inference) whose performance claims are supported by direct comparisons on Seed-TTS-Eval rather than any derivation that reduces to its own inputs. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the described chain; the role-assignment strategy is a training heuristic whose effectiveness is measured externally, not assumed by construction. The work is self-contained against external benchmarks and pretrained components.
Axiom & Free-Parameter Ledger
free parameters (1)
- chunk size and overlap for streaming inference
axioms (1)
- domain assumption Pretrained neural codec latents preserve sufficient linguistic content for one-step conversion without explicit content modeling.
Reference graph
Works this paper leans on
-
[1]
Philip Anastassiou, Jiawei Chen, Jitong Chen, Yuanzhe Chen, Zhuo Chen, Ziyi Chen, Jian Cong, Lelai Deng, Chuang Ding, Lu Gao, Mingqing Gong, Peisong Huang, Qingqing Huang, Zhiying Huang, Yuanyuan Huo, Dongya Jia, Chumin Li, Feiya Li, Hui Li, Jiaxin Li, Xiaoyang Li, Xingxing Li, Lin Liu, Shouda Liu, Sichao Liu, Xudong Liu, Yuchen Liu, Zhengxi Liu, Lu Lu, J...
work page internal anchor Pith review arXiv 2024
- [2]
-
[3]
Edresson Casanova, Julian Weber, Christopher D Shulby, Arnaldo Candido Junior, Eren Gölge, and Moacir A Ponti. 2022. YourTTS: Towards Zero-Shot Multi- Speaker TTS and Zero-Shot Voice Conversion for Everyone. InProceedings of the 39th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 162), Kamalika Chaudhuri, Stef...
2022
-
[4]
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Xiangzhan Yu, and Furu Wei. 2022. WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing.IEEE Journal of Selected Topics in Sig...
-
[5]
Wenxi Chen, Xinsheng Wang, Ruiqi Yan, Yushen Chen, Zhikang Niu, Ziyang Ma, Xiquan Li, Yuzhe Liang, Hanlin Wen, Shunshun Yin, Ming Tao, and Xie Chen. 2025. SAC: Neural Speech Codec with Semantic-Acoustic Dual-Stream Quantization. arXiv:2510.16841 [eess.AS] https://arxiv.org/abs/2510.16841
-
[6]
Yushen Chen, Zhikang Niu, Ziyang Ma, Keqi Deng, Chunhui Wang, Jian Zhao, Kai Yu, and Xie Chen. 2025. F5-TTS: A Fairytaler that Fakes Fluent and Faithful Speech with Flow Matching. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad T...
2025
-
[7]
Yafeng Chen, Siqi Zheng, Hui Wang, Luyao Cheng, Qian Chen, and Jiajun Qi
-
[8]
An Enhanced Res2Net with Local and Global Feature Fusion for Speaker Verification. InInterspeech 2023. 2228–2232. doi:10.21437/Interspeech.2023-1294
-
[9]
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. 2023. High Fidelity Neural Audio Compression.Transactions on Machine Learning Research (2023). https://openreview.net/forum?id=ivCd8z8zR2 Featured Certification, Reproducibility Certification
2023
-
[10]
Sefik Emre Eskimez, Xiaofei Wang, Manthan Thakker, Canrun Li, Chung-Hsien Tsai, Zhen Xiao, Hemin Yang, Zirun Zhu, Min Tang, Xu Tan, Yanqing Liu, Sheng Zhao, and Naoyuki Kanda. 2024. E2 TTS: Embarrassingly Easy Fully Non-Autoregressive Zero-Shot TTS. In2024 IEEE Spoken Language Technology Workshop (SLT). 682–689. doi:10.1109/SLT61566.2024.10832320
-
[11]
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. 2024. Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. InProceedings of the 41st International Conference on Machine Learning...
2024
-
[12]
Zhifu Gao, ShiLiang Zhang, Ian McLoughlin, and Zhijie Yan. 2022. Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition. InInterspeech 2022. 2063–2067. doi:10.21437/Interspeech. 2022-9996
- [13]
-
[14]
Haorui He, Zengqiang Shang, Chaoren Wang, Xuyuan Li, Yicheng Gu, Hua Hua, Liwei Liu, Chen Yang, Jiaqi Li, Peiyang Shi, Yuancheng Wang, Kai Chen, Pengyuan Zhang, and Zhizheng Wu. 2024. Emilia: An Extensive, Multilingual, and Diverse Speech Dataset For Large-Scale Speech Generation. In2024 IEEE Spoken Language Technology Workshop (SLT). 885–890. doi:10.1109...
-
[15]
Xun Huang and Serge Belongie. 2017. Arbitrary Style Transfer in Real-Time With Adaptive Instance Normalization. InProceedings of the IEEE International Conference on Computer Vision (ICCV)
2017
-
[16]
Zeqian Ju, Yuancheng Wang, Kai Shen, Xu Tan, Detai Xin, Dongchao Yang, Eric Liu, Yichong Leng, Kaitao Song, Siliang Tang, Zhizheng Wu, Tao Qin, Xi- angyang Li, Wei Ye, Shikun Zhang, Jiang Bian, Lei He, Jinyu Li, and Sheng Zhao. 2024. NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models. InProceedings of the 41st Internati...
2024
-
[17]
Eugene Kharitonov, Damien Vincent, Zalán Borsos, Raphaël Marinier, Sertan Girgin, Olivier Pietquin, Matt Sharifi, Marco Tagliasacchi, and Neil Zeghidour
-
[18]
Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision.Transactions of the Association for Computational Linguistics11 (12 2023), 1703–1718. doi:10.1162/tacl_a_00618
-
[19]
Junjie Li, Yiwei Guo, Xie Chen, and Kai Yu. 2024. SEF-VC: Speaker Embedding Free Zero-Shot Voice Conversion with Cross Attention. InICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 12296–12300. doi:10.1109/ICASSP48485.2024.10446160
-
[20]
Jingyi Li, Weiping Tu, and Li Xiao. 2023. Freevc: Towards High-Quality Text-Free One-Shot Voice Conversion. InICASSP 2023 - 2023 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP). 1–5. doi:10.1109/ICASSP49357.2023.10095191
-
[21]
Yinghao Aaron Li, Ali Zare, and Nima Mesgarani. 2021. StarGANv2-VC: A Diverse, Unsupervised, Non-Parallel Framework for Natural-Sounding Voice Conversion. InInterspeech 2021. 1349–1353. doi:10.21437/Interspeech.2021-319
-
[22]
Lin, Chung-Ming Chien, Jheng-Hao Lin, Hung-yi Lee, and Lin-shan Lee
Yist Y. Lin, Chung-Ming Chien, Jheng-Hao Lin, Hung-yi Lee, and Lin-shan Lee
-
[23]
Developing real-time streaming transformer transducer for speech recognition on large-scale dataset
Fragmentvc: Any-To-Any Voice Conversion by End-To-End Extracting and Fusing Fine-Grained Voice Fragments with Attention. InICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 5939–5943. doi:10.1109/ICASSP39728.2021.9413699
- [24]
- [25]
-
[26]
Seyed Hamidreza Mohammadi and Alexander Kain. 2017. An overview of voice conversion systems.Speech Communication88 (2017), 65–82. doi:10.1016/j. specom.2017.01.008
work page doi:10.1016/j 2017
-
[27]
Ziqian Ning, Yuepeng Jiang, Pengcheng Zhu, Shuai Wang, Jixun Yao, Lei Xie, and Mengxiao Bi. 2024. Dualvc 2: Dynamic Masked Convolution for Unified Streaming and Non-Streaming Voice Conversion. InICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 11106–11110. doi:10.1109/ICASSP48485.2024.10446229
-
[28]
Ziqian Ning, Yuepeng Jiang, Pengcheng Zhu, Jixun Yao, Shuai Wang, Lei Xie, and Mengxiao Bi. 2023. DualVC: Dual-mode Voice Conversion using Intra- model Knowledge Distillation and Hybrid Predictive Coding. InInterspeech 2023. 2063–2067. doi:10.21437/Interspeech.2023-1157
-
[29]
William Peebles and Saining Xie. 2023. Scalable Diffusion Models with Trans- formers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 4195–4205
2023
-
[30]
Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. 2018. FiLM: Visual Reasoning with a General Conditioning Layer. Proceedings of the AAAI Conference on Artificial Intelligence32, 1 (Apr. 2018). doi:10.1609/aaai.v32i1.11671
-
[31]
Kaizhi Qian, Yang Zhang, Shiyu Chang, Xuesong Yang, and Mark Hasegawa- Johnson. 2019. AutoVC: Zero-Shot Voice Style Transfer with Only Autoencoder Loss. InProceedings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 97), Kamalika Chaudhuri and Ruslan Salakhutdinov (Eds.). PMLR, 5210–5219. https://pro...
2019
- [32]
-
[33]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine Mcleavey, and Ilya Sutskever. 2023. Robust Speech Recognition via Large-Scale Weak Super- vision. InProceedings of the 40th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 202), Andreas Krause, Emma Brun- skill, Kyunghyun Cho, Barbara Engelhardt, Siv...
2023
-
[34]
Chandan K A Reddy, Vishak Gopal, and Ross Cutler. 2021. Dnsmos: A Non- Intrusive Perceptual Objective Speech Quality Metric to Evaluate Noise Suppres- sors. InICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 6493–6497. doi:10.1109/ICASSP39728.2021.9414878
-
[35]
Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamichi, and Hiroshi Saruwatari. 2022. UTMOS: UTokyo-SaruLab System for VoiceMOS Challenge 2022. InInterspeech 2022. 4521–4525. doi:10.21437/ Interspeech.2022-439
2022
-
[36]
Berrak Sisman, Junichi Yamagishi, Simon King, and Haizhou Li. 2021. An Overview of Voice Conversion and Its Challenges: From Statistical Modeling to Deep Learning.IEEE/ACM Transactions on Audio, Speech, and Language Processing 29 (2021), 132–157. doi:10.1109/TASLP.2020.3038524 X-VC: Zero-shot Streaming Voice Conversion in Codec Space
-
[37]
Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, Lei He, Sheng Zhao, and Furu Wei. 2023. Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers. arXiv:2301.02111 [cs.CL] https://arxiv.org/abs/2301.02111
work page internal anchor Pith review arXiv 2023
-
[38]
Disong Wang, Liqun Deng, Yu Ting Yeung, Xiao Chen, Xunying Liu, and He- len Meng. 2021. VQMIVC: Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-Shot Voice Con- version. InInterspeech 2021. 1344–1348. doi:10.21437/Interspeech.2021-283
-
[39]
Tianrui Wang, Meng Ge, Zhikang Niu, Cheng Gong, Chunyu Qiang, Haoyu Wang, Zikang Huang, Ziyang Ma, Xiaobao Wang, Xie Chen, Longbiao Wang, and Jianwu Dang. 2025. A Progressive Generation Framework with Speech Pre-trained Model for Expressive Voice Conversion. In2025 IEEE International Conference on Multimedia and Expo (ICME). 1–6. doi:10.1109/ICME59968.202...
-
[40]
Zhichao Wang, Yuanzhe Chen, Xinsheng Wang, Lei Xie, and Yuping Wang
-
[41]
StreamVoice: Streamable Context-Aware Language Modeling for Real- time Zero-Shot Voice Conversion. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 7328–7338. doi:10.18653/v1/...
-
[42]
Yang Yang, Yury Kartynnik, Yunpeng Li, Jiuqiang Tang, Xing Li, George Sung, and Matthias Grundmann. 2024. STREAMVC: Real-Time Low-Latency Voice Conversion. InICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 11016–11020. doi:10.1109/ICASSP48485. 2024.10446863
- [43]
-
[44]
Weiss, Ye Jia, Zhifeng Chen, and Yonghui Wu
Heiga Zen, Viet Dang, Rob Clark, Yu Zhang, Ron J. Weiss, Ye Jia, Zhifeng Chen, and Yonghui Wu. 2019. LibriTTS: A Corpus Derived from LibriSpeech for Text- to-Speech. InInterspeech 2019. 1526–1530. doi:10.21437/Interspeech.2019-2441
-
[45]
Hanlin Zhang, Daxin Tan, Dehua Tao, Xiao Chen, Haochen Tan, Yunhe Li, Yuchen Cao, Jianping Wang, and Linqi Song. 2026. DSA-Tokenizer: Disentangled Semantic-Acoustic Tokenization via Flow Matching-based Hierarchical Fusion. arXiv:2601.09239 [cs.SD] https://arxiv.org/abs/2601.09239
-
[46]
Xueyao Zhang, Xiaohui Zhang, Kainan Peng, Zhenyu Tang, Vimal Manohar, Yin- gru Liu, Jeff Hwang, Dangna Li, Yuhao Wang, Julian Chan, Yuan Huang, Zhizheng Wu, and Mingbo Ma. 2025. Vevo: Controllable Zero-Shot Voice Imitation with Self-Supervised Disentanglement. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/fo...
2025
- [47]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.