Recognition: unknown
Monte Carlo Stochastic Depth for Uncertainty Estimation in Deep Learning
Pith reviewed 2026-05-10 14:50 UTC · model grok-4.3
The pith
Monte Carlo Stochastic Depth offers a computationally efficient approximation to Bayesian inference for uncertainty estimation in deep residual networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
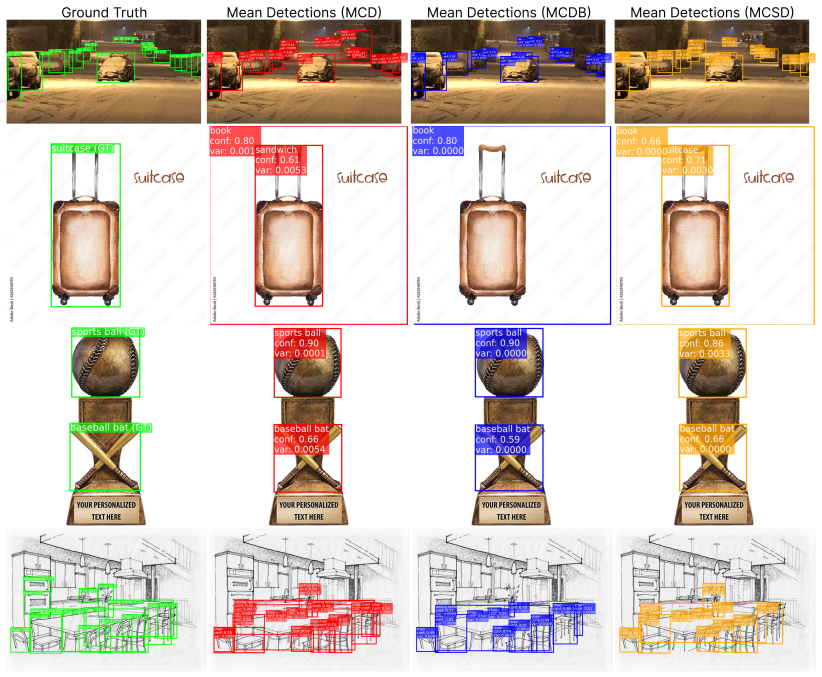
The authors show that Monte Carlo Stochastic Depth (MCSD) provides a principled approximate variational inference method by repurposing the stochastic depth regularizer. In benchmarks on state-of-the-art object detectors including YOLO and RT-DETR evaluated on COCO and COCO-O, MCSD yields competitive mean average precision while offering marginal gains in expected calibration error and area under the accuracy-rejection curve over Monte Carlo Dropout.
What carries the argument
Monte Carlo Stochastic Depth (MCSD), the application of stochastic depth during multiple forward passes at inference time to approximate posterior predictive distributions, serving as an efficient Bayesian approximation analogous to Monte Carlo Dropout.
If this is right
- MCSD can be used in residual-based backbones common in modern architectures for UQ.
- It achieves highly competitive mAP on detection tasks.
- It yields slight improvements in calibration (ECE) and uncertainty ranking (AUARC) compared to MCD.
- MCSD is computationally efficient for large-scale deep learning applications.
Where Pith is reading between the lines
- The method might extend to other computer vision tasks where stochastic depth is already employed, such as image segmentation.
- Combining MCSD with other stochastic regularizers could further enhance uncertainty estimates.
- The theoretical connection suggests potential for deriving similar approximations for other regularizers in deep networks.
- Validation on additional datasets beyond COCO would strengthen the generalization claims.
Load-bearing premise
The assumption that stochastic depth admits a direct interpretation as approximate variational inference analogous to dropout, allowing the Monte Carlo sampling to yield meaningful uncertainty estimates.
What would settle it
If repeated experiments on the same YOLO and RT-DETR models with COCO show no improvement or worse ECE for MCSD compared to MCD, the claim of slight improvements would be falsified.
Figures





read the original abstract
The deployment of deep neural networks in safety-critical systems necessitates reliable and efficient uncertainty quantification (UQ). A practical and widespread strategy for UQ is repurposing stochastic regularizers as scalable approximate Bayesian inference methods, such as Monte Carlo Dropout (MCD) and MC-DropBlock (MCDB). However, this paradigm remains under-explored for Stochastic Depth (SD), a regularizer integral to the residual-based backbones of most modern architectures. While prior work demonstrated its empirical promise for segmentation, a formal theoretical connection to Bayesian variational inference and a benchmark on complex, multi-task problems like object detection are missing. In this paper, we first provide theoretical insights connecting Monte Carlo Stochastic Depth (MCSD) to principled approximate variational inference. We then present the first comprehensive empirical benchmark of MCSD against MCD and MCDB on state-of-the-art detectors (YOLO, RT-DETR) using the COCO and COCO-O datasets. Our results position MCSD as a robust and computationally efficient method that achieves highly competitive predictive accuracy (mAP), notably yielding slight improvements in calibration (ECE) and uncertainty ranking (AUARC) compared to MCD. We thus establish MCSD as a theoretically-grounded and empirically-validated tool for efficient Bayesian approximation in modern deep learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Monte Carlo Stochastic Depth (MCSD) as an extension of Stochastic Depth for uncertainty quantification in deep networks. It claims to provide theoretical insights linking MCSD to approximate variational inference (analogous to Monte Carlo Dropout), followed by the first comprehensive benchmark of MCSD versus MCD and MC-DropBlock on modern object detectors (YOLO, RT-DETR) using COCO and COCO-O, reporting competitive mAP with slight gains in ECE and AUARC.
Significance. If the variational-inference link is made rigorous and the empirical gains prove robust across architectures and tasks, MCSD would supply a lightweight, architecture-native Bayesian approximation for residual networks that dominate current vision backbones, offering a practical alternative to dropout-based methods in safety-critical settings.
major comments (2)
- [§3] §3 (Theoretical Insights): The abstract asserts a 'theoretical connection' to principled approximate variational inference, yet the provided text supplies no explicit ELBO derivation, no definition of the variational family q(·) induced by the per-block inclusion indicators, and no demonstration that the training objective matches the VI objective (including the KL term). Without these steps the grounding remains an analogy to Dropout rather than a derivation; this directly supports the central claim that MCSD is 'theoretically-grounded'.
- [§4.2] §4.2 and Table 2: The reported ECE and AUARC improvements are described as 'slight' and 'highly competitive', but the text gives neither numeric deltas, standard errors, nor the number of Monte Carlo samples used at test time. These quantities are load-bearing for the empirical-validation half of the strongest claim; their absence prevents assessment of whether the gains exceed run-to-run variability.
minor comments (2)
- [Abstract] The abstract and introduction repeatedly use 'MCSD' before it is defined; add an explicit definition on first use.
- [§4] Figure captions and axis labels in the experimental section should state the exact number of MC samples and the random seed protocol used for the reported metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and will incorporate the suggested clarifications and details into the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Theoretical Insights): The abstract asserts a 'theoretical connection' to principled approximate variational inference, yet the provided text supplies no explicit ELBO derivation, no definition of the variational family q(·) induced by the per-block inclusion indicators, and no demonstration that the training objective matches the VI objective (including the KL term). Without these steps the grounding remains an analogy to Dropout rather than a derivation; this directly supports the central claim that MCSD is 'theoretically-grounded'.
Authors: We thank the referee for this observation. Section 3 draws a parallel between MCSD and Monte Carlo Dropout by interpreting the per-block stochastic depth masks as samples from an implicit variational distribution over sub-networks. We acknowledge, however, that the manuscript does not contain an explicit ELBO derivation, a formal definition of the variational family q(·), or an explicit accounting of the KL term. In the revision we will expand §3 to supply these elements: we will define the variational family induced by the independent Bernoulli inclusion probabilities for each residual block, derive the corresponding evidence lower bound, and show how the standard Stochastic Depth training objective approximates the VI objective. revision: yes
-
Referee: [§4.2] §4.2 and Table 2: The reported ECE and AUARC improvements are described as 'slight' and 'highly competitive', but the text gives neither numeric deltas, standard errors, nor the number of Monte Carlo samples used at test time. These quantities are load-bearing for the empirical-validation half of the strongest claim; their absence prevents assessment of whether the gains exceed run-to-run variability.
Authors: We agree that these quantitative details are necessary for readers to judge the practical significance of the reported improvements. The current version describes the ECE and AUARC results only qualitatively. In the revision we will update §4.2 and Table 2 to report the exact numeric deltas, include standard errors computed across repeated training runs, and explicitly state the number of Monte Carlo samples used at inference time for all compared methods. revision: yes
Circularity Check
Minor self-citation in literature positioning; central theoretical insights and benchmarks remain independent.
full rationale
The abstract and provided context position MCSD as an extension of MCD/MCDB with new theoretical insights and a fresh benchmark on COCO/YOLO/RT-DETR. No equations, fitted parameters, or self-citation chains are exhibited that reduce the claimed variational connection or empirical results to tautologies or prior inputs by construction. The derivation is presented as additive content rather than a renaming or self-referential fit, consistent with a non-circular extension of existing MC methods.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stochastic Depth can be repurposed as a scalable approximate Bayesian inference method analogous to Monte Carlo Dropout
Reference graph
Works this paper leans on
-
[1]
Variational bayesian monte carlo
Luigi Acerbi. Variational bayesian monte carlo. InAd- vances in Neural Information Processing Systems. Curran Associates, Inc., 2018. 3
2018
-
[2]
Depth Uncertainty in Neural Networks
Javier Antoran, James Allingham, and Jos ´e Miguel Hern´andez-Lobato. Depth Uncertainty in Neural Networks. InAdvances in Neural Information Processing Systems, pages 10620–10634. Curran Associates, Inc., 2020. 2
2020
-
[3]
Uncertainty Estimation via Stochastic Batch Normalization
Andrei Atanov, Arsenii Ashukha, Dmitry Molchanov, Kirill Neklyudov, and Dmitry Vetrov. Uncertainty Estimation via Stochastic Batch Normalization. InAdvances in Neural Net- works – ISNN 2019, pages 261–269, Cham, 2019. Springer International Publishing. 2
2019
-
[4]
The need for uncertainty quantification in machine- assisted medical decision making.Nature Machine Intelli- gence, 1(1):20–23, 2019-01
Edmon Begoli, Tanmoy Bhattacharya, and Dimitri Kusne- zov. The need for uncertainty quantification in machine- assisted medical decision making.Nature Machine Intelli- gence, 1(1):20–23, 2019-01. Publisher: Nature Publishing Group. 2
2019
-
[5]
Riemannian laplace approxima- tions for bayesian neural networks.Advances in Neural In- formation Processing Systems, 36:31066–31095, 2023-12-
Federico Bergamin, Pablo Moreno-Mu ˜noz, Søren Hauberg, and Georgios Arvanitidis. Riemannian laplace approxima- tions for bayesian neural networks.Advances in Neural In- formation Processing Systems, 36:31066–31095, 2023-12-
2023
-
[6]
Blei, Alp Kucukelbir, and Jon D
David M. Blei, Alp Kucukelbir, and Jon D. McAuliffe. Vari- ational inference: A review for statisticians.Journal of the American Statistical Association, 112(518):859–877, 2017- 04-03. 2
2017
-
[7]
Weight uncertainty in neural network
Charles Blundell, Julien Cornebise, Koray Kavukcuoglu, and Daan Wierstra. Weight uncertainty in neural network. InInternational Conference on Machine Learning, pages 1613–1622. PMLR, 2015-06-01. ISSN: 1938-7228. 2
2015
-
[8]
Verification of forecasts expressed in terms of probability.Monthly Weather Review, 78(1):1–3, 1950
Glenn W Brier. Verification of forecasts expressed in terms of probability.Monthly Weather Review, 78(1):1–3, 1950. 6
1950
-
[9]
Jeffrey De Fauw, Joseph R. Ledsam, Bernardino Romera- Paredes, Stanislav Nikolov, Nenad Tomasev, Sam Black- well, Harry Askham, Xavier Glorot, Brendan O’Donoghue, Daniel Visentin, George van den Driessche, Balaji Lakshmi- narayanan, Clemens Meyer, Faith Mackinder, Simon Bou- ton, Kareem Ayoub, Reena Chopra, Dominic King, Alan Karthikesalingam, C ´ıan O. H...
2018
-
[10]
Make me a BNN: A simple strategy for estimating bayesian uncer- tainty from pre-trained models
Gianni Franchi, Olivier Laurent, Maxence Legu ´ery, An- drei Bursuc, Andrea Pilzer, and Angela Yao. Make me a BNN: A simple strategy for estimating bayesian uncer- tainty from pre-trained models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), number arXiv:2312.15297, 2024. 2, 3
-
[11]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. InInternational Conference on Machine Learning, pages 1050–1059. PMLR, 2016-06-11. ISSN: 1938-7228. 1, 2, 3, 4, 5
2016
-
[12]
Concrete dropout
Yarin Gal, Jiri Hron, and Alex Kendall. Concrete dropout. In Advances in Neural Information Processing Systems. Curran Associates, Inc., 2017. 1
2017
- [13]
-
[14]
Bias- reduced uncertainty estimation for deep neural classifiers.In- ternational Conference on Learning Representations (ICLR), 2019-04-25
Yonatan Geifman, Guy Uziel, and Ran El-Yaniv. Bias- reduced uncertainty estimation for deep neural classifiers.In- ternational Conference on Learning Representations (ICLR), 2019-04-25. 6
2019
-
[15]
DropBlock: A regularization method for convolutional networks
Golnaz Ghiasi, Tsung-Yi Lin, and Quoc V Le. DropBlock: A regularization method for convolutional networks. InAd- vances in Neural Information Processing Systems. Curran Associates, Inc., 2018. 4
2018
-
[16]
Bayesian neural networks: An introduction and survey
Ethan Goan and Clinton Fookes. Bayesian neural networks: An introduction and survey. pages 45–87. 2020. 2
2020
-
[17]
FipTR: A simple yet effective transformer framework for future instance prediction in autonomous driving
Xingtai Gui, Tengteng Huang, Haonan Shao, Haotian Yao, and Chi Zhang. FipTR: A simple yet effective transformer framework for future instance prediction in autonomous driving. InComputer Vision – ECCV 2024, pages 19–35. Springer Nature Switzerland, 2025. 1
2024
-
[18]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. InInternational Conference on Machine Learning, pages 1321–1330. PMLR, 2017-07-17. ISSN: 2640-3498. 1, 6
2017
-
[19]
A survey on vision transformer.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1):87–110, 2023-01
Kai Han, Yunhe Wang, Hanting Chen, Xinghao Chen, Jianyuan Guo, Zhenhua Liu, Yehui Tang, An Xiao, Chunjing Xu, Yixing Xu, Zhaohui Yang, Yiman Zhang, and Dacheng Tao. A survey on vision transformer.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1):87–110, 2023-01. 1
2023
-
[20]
Towards Corner Case Detection by Modeling the Uncertainty of Instance Segmentation Networks
Florian Heidecker, Abdul Hannan, Maarten Bieshaar, and Bernhard Sick. Towards Corner Case Detection by Modeling the Uncertainty of Instance Segmentation Networks. InPat- tern Recognition. ICPR International Workshops and Chal- lenges, pages 361–374, Cham, 2021. Springer International Publishing. 3
2021
-
[21]
Stephen C. Hora. Aleatory and epistemic uncertainty in probability elicitation with an example from hazardous waste management.Reliability Engineering & System Safety, 54 (2):217–223, 1996-11-01. 2
1996
-
[22]
Weinberger
Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kil- ian Q. Weinberger. Deep networks with stochastic depth. InComputer Vision – ECCV 2016, pages 646–661. Springer International Publishing, 2016. 1, 4
2016
-
[23]
Aleatoric and epistemic uncertainty in machine learning: an introduction to concepts and methods.Machine Learning, 110(3):457– 506, 2021-03-01
Eyke H ¨ullermeier and Willem Waegeman. Aleatoric and epistemic uncertainty in machine learning: an introduction to concepts and methods.Machine Learning, 110(3):457– 506, 2021-03-01. 2
2021
-
[24]
Ultralytics YOLO, 2023
Glenn Jocher, Jing Qiu, and Ayush Chaurasia. Ultralytics YOLO, 2023. 5, 6
2023
-
[25]
What uncertainties do we need in bayesian deep learning for computer vision? InAd- vances in Neural Information Processing Systems
Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision? InAd- vances in Neural Information Processing Systems. Curran Associates, Inc., 2017. 2
2017
-
[26]
Aleatory or epis- temic? does it matter?Structural Safety, 31(2):105–112, 2009-03-01
Armen Der Kiureghian and Ove Ditlevsen. Aleatory or epis- temic? does it matter?Structural Safety, 31(2):105–112, 2009-03-01. 2
2009
-
[27]
Simple and scalable predictive uncertainty esti- mation using deep ensembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty esti- mation using deep ensembles. InAdvances in Neural Infor- mation Processing Systems. Curran Associates, Inc., 2017. 2
2017
-
[28]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C. Lawrence Zitnick. Microsoft COCO: Common objects in context. In Computer Vision – ECCV 2014, pages 740–755. Springer In- ternational Publishing, 2014. 5
2014
-
[29]
A complete recipe for stochastic gradient MCMC
Yi-An Ma, Tianqi Chen, and Emily Fox. A complete recipe for stochastic gradient MCMC. InAdvances in Neural Infor- mation Processing Systems. Curran Associates, Inc., 2015. 2
2015
-
[30]
COCO-o: A benchmark for ob- ject detectors under natural distribution shifts
Xiaofeng Mao, Yuefeng Chen, Yao Zhu, Da Chen, Hang Su, Rong Zhang, and Hui Xue. COCO-o: A benchmark for ob- ject detectors under natural distribution shifts. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 6339–6350, 2023. 5
2023
-
[31]
Dropout Sampling for Robust Object Detection in Open-Set Conditions
Dimity Miller, Lachlan Nicholson, Feras Dayoub, and Niko S¨underhauf. Dropout Sampling for Robust Object Detection in Open-Set Conditions. In2018 IEEE International Confer- ence on Robotics and Automation (ICRA), pages 3243–3249,
-
[32]
Evaluating Merging Strategies for Sampling- based Uncertainty Techniques in Object Detection
Dimity Miller, Feras Dayoub, Michael Milford, and Niko S¨underhauf. Evaluating Merging Strategies for Sampling- based Uncertainty Techniques in Object Detection. In 2019 International Conference on Robotics and Automation (ICRA), pages 2348–2354, 2019. ISSN: 2577-087X. 6
2019
-
[33]
Evaluating bayesian deep learning methods for semantic segmentation
Jishnu Mukhoti and Yarin Gal. Evaluating bayesian deep learning methods for semantic segmentation. arXiv:1811.12709, 2019-03-23. 1
-
[34]
Radford M. Neal. MCMC using hamiltonian dynamics. In Handbook of Markov Chain Monte Carlo. Chapman and Hall/CRC, 2011. Num Pages: 50. 2
2011
-
[35]
Epistemic Neural Networks.Advances in Neural Information Processing Systems, 36:2795–2823,
Ian Osband, Zheng Wen, Seyed Mohammad Asghari, Vikranth Dwaracherla, Morteza Ibrahimi, Xiuyuan Lu, and Benjamin Van Roy. Epistemic Neural Networks.Advances in Neural Information Processing Systems, 36:2795–2823,
-
[36]
Theodore Papamarkou, Maria Skoularidou, Konstantina Palla, Laurence Aitchison, Julyan Arbel, David Dun- son, Maurizio Filippone, Vincent Fortuin, Philipp Hennig, Jos´e Miguel Hern´andez-Lobato, Aliaksandr Hubin, Alexan- der Immer, Theofanis Karaletsos, Mohammad Emtiyaz Khan, Agustinus Kristiadi, Yingzhen Li, Stephan Mandt, Christopher Nemeth, Michael A. O...
-
[37]
PyTorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Rai- son, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An imperative style, high-per...
2019
-
[38]
Probabilistic consis- tency in machine learning and its connection to uncertainty quantification
Paul Patrone and Anthony Kearsley. Probabilistic consis- tency in machine learning and its connection to uncertainty quantification. (arXiv:2507.21670), 2025-09-26. 1
-
[39]
Uncertainty quantifi- cation and deep ensembles
Rahul Rahaman and alexandre thiery. Uncertainty quantifi- cation and deep ensembles. InAdvances in Neural Informa- tion Processing Systems, pages 20063–20075. Curran Asso- ciates, Inc., 2021. 2
2021
-
[40]
You only look once: Unified, real-time object de- tection
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object de- tection. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 779–788, 2016. 2
2016
-
[41]
Faster r-CNN: Towards real-time object detection with re- gion proposal networks
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-CNN: Towards real-time object detection with re- gion proposal networks. InAdvances in Neural Information Processing Systems. Curran Associates, Inc., 2015. 2, 5
2015
-
[42]
A scal- able laplace approximation for neural networks
Hippolyt Ritter, Aleksandar Botev, and David Barber. A scal- able laplace approximation for neural networks. 2018. 2
2018
-
[43]
Eviden- tial Deep Learning to Quantify Classification Uncertainty
Murat Sensoy, Lance Kaplan, and Melih Kandemir. Eviden- tial Deep Learning to Quantify Classification Uncertainty. In Advances in Neural Information Processing Systems. Curran Associates, Inc., 2018. 2
2018
-
[44]
Ronald Seoh. Qualitative analysis of monte carlo dropout. arXiv:2007.01720, 2020-07-06. 3
-
[45]
C. E. Shannon. A mathematical theory of communication. The Bell System Technical Journal, 27(3):379–423, 1948-07. 6
1948
-
[46]
Reliable post hoc explanations: Modeling uncer- tainty in explainability
Dylan Slack, Anna Hilgard, Sameer Singh, and Himabindu Lakkaraju. Reliable post hoc explanations: Modeling uncer- tainty in explainability. InAdvances in Neural Information Processing Systems, pages 9391–9404. Curran Associates, Inc., 2021. 2
2021
-
[47]
Dropout: a simple way to prevent neural networks from overfitting.J
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting.J. Mach. Learn. Res., 15(1):1929–1958, 2014-01-01. 3
1929
-
[48]
A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas.Machine Learning and Knowledge Ex- traction, 5(4):1680–1716, 2023
Juan Terven, Diana-Margarita C ´ordova-Esparza, and Julio- Alejandro Romero-Gonz ´alez. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas.Machine Learning and Knowledge Ex- traction, 5(4):1680–1716, 2023. 1
2023
-
[49]
Regularization of Neural Networks using DropCon- nect
Li Wan, Matthew Zeiler, Sixin Zhang, Yann Le Cun, and Rob Fergus. Regularization of Neural Networks using DropCon- nect. InProceedings of the 30th International Conference on Machine Learning, pages 1058–1066. PMLR, 2013. 2
2013
-
[50]
A survey on bayesian deep learning.ACM Comput
Hao Wang and Dit-Yan Yeung. A survey on bayesian deep learning.ACM Comput. Surv., 53(5):108:1–108:37, 2020- 09-28. 1
2020
-
[51]
Bayesian learning via stochastic gradient langevin dynamics
Max Welling and Yee Whye Teh. Bayesian learning via stochastic gradient langevin dynamics. InProceedings of the 28th International Conference on International Conference on Machine Learning, pages 681–688. Omnipress, 2011-06-
2011
-
[52]
Ross Wightman. PyTorch Image Models.https : //github.com/huggingface/pytorch- image- models. Version 1.0.11. DOI: 10.5281/zenodo.4414861. License: Apache 2.0. 7, 1
-
[53]
Balancing calibration and performance: Stochas- tic depth in segmentation BNNs, 2024
Linghong Yao, Denis Hadjivelichkov, Andromachi Maria Delfaki, Yuanchang Liu, Brooks Paige, and Dimitrios Kanoulas. Balancing calibration and performance: Stochas- tic depth in segmentation BNNs, 2024. 1, 2, 7
2024
-
[54]
Monte carlo DropBlock for modeling uncer- tainty in object detection.Pattern Recognition, 146:110003, 2024-02-01
Sai Harsha Yelleni, Deepshikha Kumari, Srijith P.k., and Kr- ishna Mohan C. Monte carlo DropBlock for modeling uncer- tainty in object detection.Pattern Recognition, 146:110003, 2024-02-01. 1, 2, 4, 5, 7
2024
-
[55]
Laplace approximation based epis- temic uncertainty estimation in 3d object detection
Peng Yun and Ming Liu. Laplace approximation based epis- temic uncertainty estimation in 3d object detection. InCon- ference on Robot Learning, pages 1125–1135. PMLR, 2023- 03-06. ISSN: 2640-3498. 2
2023
-
[56]
Tal Zeevi, Ravid Shwartz-Ziv, Yann LeCun, Lawrence H. Staib, and John A. Onofrey. Rate-in: Information-driven adaptive dropout rates for improved inference-time uncer- tainty estimation. InIEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), number arXiv:2412.07169, 2025-06-04. 1, 2
-
[57]
DETRs beat YOLOs on real-time object detection
Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, and Jie Chen. DETRs beat YOLOs on real-time object detection. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16965–16974, 2024. 2, 5
2024
-
[58]
Identity curvature laplace approximation for improved out- of-distribution detection
Maksim Zhdanov, Stanislav Dereka, and Sergey Kolesnikov. Identity curvature laplace approximation for improved out- of-distribution detection. In2025 IEEE/CVF Winter Con- ference on Applications of Computer Vision (WACV), pages 7019–7028, 2025-02. ISSN: 2642-9381. 2 Monte Carlo Stochastic Depth for Uncertainty Estimation in Deep Learning Supplementary Material
2025
-
[59]
Hardware and Software.Experiments were conducted us- ing Python 3.10.12, PyTorch 2.6.0, and Ultralytics 8.3.171
Appendix A: Reproducibility Complete source code reproducing all methods (MCD, MCDB, MCSD) and models (Faster R-CNN, YOLOv8x, RT-DETRx) is provided in the GitHub1 repository. Hardware and Software.Experiments were conducted us- ing Python 3.10.12, PyTorch 2.6.0, and Ultralytics 8.3.171. The codebase is hardware-agnostic; however, all reported results were...
2026
-
[60]
Appendix B: Theoretical Derivations In this section, we provide the formal derivation connecting the Stochastic Depth (SD) training objective to the Varia- tional Inference (VI) framework utilized in the main paper. 9.1. Derivation of the ELBO Objective for MCSD As defined in the main paper, our objective is to maximize the Evidence Lower Bound (ELBO): LV...
-
[61]
Extended Pareto Analysis Complementing Fig
Appendix C: Additional Results 10.1. Extended Pareto Analysis Complementing Fig. 2 in the main text, we provide the com- plete Pareto trade-off plots for the Faster R-CNN (Fig. 4) and YOLOv8x (Fig. 5) architectures. Consistent with the RT-DETR results discussed in the main paper, we observe that theconfidence threshold acts as the dominant variable govern...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.