A Dataset and Evaluation for Complex 4D Markerless Human Motion Capture
Pith reviewed 2026-05-10 14:59 UTC · model grok-4.3
The pith
A new dataset with Vicon ground truth shows markerless 4D motion capture models degrade sharply on multi-person interactions with occlusions and similar appearances.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By supplying synchronized multi-view RGB and depth sequences, precise camera calibration, Vicon-derived 3D ground truth, and corresponding SMPL/SMPL-X parameters for single- and multi-person scenarios that feature intricate motions, frequent inter-person occlusions, rapid position exchanges between similarly dressed subjects, and varying distances, the dataset demonstrates substantial performance degradation in current state-of-the-art markerless MoCap models and shows that targeted fine-tuning improves generalization to these conditions.
What carries the argument
The proposed MoCap dataset, which supplies multi-view RGB, depth, Vicon 3D ground truth, and SMPL parameters for complex multi-person interactions with occlusions and similar subject appearances.
If this is right
- Markerless MoCap models must incorporate training or adaptation data that includes severe occlusions and rapid subject interactions to reach usable accuracy.
- Targeted fine-tuning on sequences with Vicon-aligned ground truth measurably reduces the generalization gap for these models.
- Precise multi-view RGB, depth, and SMPL parameter alignment enables quantitative diagnosis of where current methods fail.
- The dataset supplies a concrete testbed for measuring progress toward practical markerless 4D capture outside controlled labs.
Where Pith is reading between the lines
- Future work could test whether models trained or fine-tuned on this data transfer better to downstream tasks such as action recognition or virtual avatar animation.
- The emphasis on similarly dressed subjects suggests that appearance similarity is a key failure mode worth isolating in follow-up experiments.
- Combining this dataset with existing single-person or less occluded corpora could produce larger training mixtures that address multiple failure modes at once.
Load-bearing premise
The specific scenarios captured, including frequent inter-person occlusions, rapid position exchanges between similarly dressed subjects, and varying distances, sufficiently represent the domain gap present in real-world markerless 4D human motion capture.
What would settle it
If state-of-the-art markerless models show no substantial accuracy drop on the new sequences relative to existing benchmarks, or if fine-tuning on this dataset fails to improve performance on separate real-world multi-person test footage, the central claims would be undermined.
Figures









read the original abstract
Marker-based motion capture (MoCap) systems have long been the gold standard for accurate 4D human modeling, yet their reliance on specialized hardware and markers limits scalability and real-world deployment. Advancing reliable markerless 4D human motion capture requires datasets that reflect the complexity of real-world human interactions. Yet, existing benchmarks often lack realistic multi-person dynamics, severe occlusions, and challenging interaction patterns, leading to a persistent domain gap. In this work, we present a new dataset and evaluation for complex 4D markerless human motion capture. Our proposed MoCap dataset captures both single and multi-person scenarios with intricate motions, frequent inter-person occlusions, rapid position exchanges between similarly dressed subjects, and varying subject distances. It includes synchronized multi-view RGB and depth sequences, accurate camera calibration, ground-truth 3D motion capture from a Vicon system, and corresponding SMPL/SMPL-X parameters. This setup ensures precise alignment between visual observations and motion ground truth. Benchmarking state-of-the-art markerless MoCap models reveals substantial performance degradation under these realistic conditions, highlighting limitations of current approaches. We further demonstrate that targeted fine-tuning improves generalization, validating the dataset's realism and value for model development. Our evaluation exposes critical gaps in existing models and provides a rigorous foundation for advancing robust markerless 4D human motion capture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a new multi-view dataset for complex 4D markerless human motion capture, featuring single- and multi-person scenarios with intricate motions, frequent inter-person occlusions, rapid position exchanges between similarly dressed subjects, and varying distances. It supplies synchronized multi-view RGB and depth sequences, camera calibration, Vicon ground-truth 3D motion capture, and corresponding SMPL/SMPL-X parameters. Benchmarking of state-of-the-art markerless MoCap models on this data shows substantial performance degradation relative to prior benchmarks, and targeted fine-tuning on the new dataset is shown to improve generalization.
Significance. If the quantitative benchmarking and fine-tuning results hold, the dataset supplies a valuable, realistic testbed that exposes domain gaps in current markerless approaches and supports further model development. The provision of precise Vicon ground truth aligned with visual observations and SMPL parameters is a clear strength for reproducibility and downstream research.
minor comments (3)
- Abstract and §1: The phrase 'substantial performance degradation' is used without a forward reference to the specific metrics or tables that quantify it; adding such a pointer would improve readability.
- Dataset description section: A compact table summarizing sequence counts, subject numbers, total frames, and occlusion statistics would make the scale and complexity of the captured scenarios easier to assess at a glance.
- Evaluation section: Standard error metrics (e.g., MPJPE, PVE) and per-scenario breakdowns should be presented with direct comparisons to the same models' published numbers on existing datasets to strengthen the domain-gap claim.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our work, accurate summary of the dataset contributions, and recommendation for minor revision. The referee correctly highlights the value of the Vicon-aligned ground truth and the observed performance degradation in existing models under realistic multi-person conditions.
Circularity Check
No significant circularity
full rationale
The paper is a dataset contribution with standard benchmarking and fine-tuning experiments on independent Vicon ground truth. No derivations, fitted parameters renamed as predictions, self-citation chains, or uniqueness theorems appear in the argument structure. All claims follow directly from empirical evaluation without reducing to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Vicon optical motion capture system supplies accurate 3D ground-truth poses for alignment with visual data
- domain assumption Multi-view camera calibration is sufficiently accurate for 4D reconstruction
Reference graph
Works this paper leans on
-
[1]
2d human pose estimation: New benchmark and state of the art analysis
Mykhaylo Andriluka, Leonid Pishchulin, Peter Gehler, and Bernt Schiele. 2d human pose estimation: New benchmark and state of the art analysis. InProceedings of the IEEE Con- ference on computer Vision and Pattern Recognition, pages 3686–3693, 2014
work page 2014
-
[2]
3D multibod- ies: Fitting sets of plausible 3D models to ambiguous image data
Benjamin Biggs, S ´ebastien Ehrhart, Hanbyul Joo, Benjamin Graham, Andrea Vedaldi, and David Novotny. 3D multibod- ies: Fitting sets of plausible 3D models to ambiguous image data. InNeurIPS, 2020
work page 2020
-
[3]
Federica Bogo, Javier Romero, Matthew Loper, and Michael J. Black. FAUST: Dataset and evaluation for 3D mesh registration. InProceedings IEEE Conf. on Com- puter Vision and Pattern Recognition (CVPR), Piscataway, NJ, USA, 2014. IEEE
work page 2014
-
[4]
Humman: Multi-modal 4d human dataset for ver- satile sensing and modeling
Zhongang Cai, Daxuan Ren, Ailing Zeng, Zhengyu Lin, Tao Yu, Wenjia Wang, Xiangyu Fan, Yang Gao, Yifan Yu, Liang Pan, et al. Humman: Multi-modal 4d human dataset for ver- satile sensing and modeling. InEuropean Conference on Computer Vision, pages 557–577. Springer, 2022
work page 2022
-
[5]
Anargyros Chatzitofis, Leonidas Saroglou, Prodromos Boutis, Petros Drakoulis, Nikolaos Zioulis, Shishir Subra- manyam, Bart Kevelham, Caecilia Charbonnier, Pablo Ce- sar, Dimitrios Zarpalas, et al. Human4d: A human-centric multimodal dataset for motions and immersive media.IEEE Access, 8:176241–176262, 2020
work page 2020
-
[6]
Guide to the carnegie mellon university multimodal activity (cmu-mmac) database
Fernando De la Torre, Jessica Hodgins, Adam Bargteil, Xavier Martin, Justin Macey, Alex Collado, and Pep Beltran. Guide to the carnegie mellon university multimodal activity (cmu-mmac) database. 2009
work page 2009
-
[7]
Humans in 4d: Re- constructing and tracking humans with transformers
Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, and Jitendra Malik. Humans in 4d: Re- constructing and tracking humans with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14783–14794, 2023
work page 2023
-
[8]
John C Gower and Garmt B Dijksterhuis.Procrustes prob- lems. Oxford university press, 2004
work page 2004
-
[9]
Perspose: 3d human pose estima- tion with perspective encoding and perspective rotation
Xiaoyang Hao and Han Li. Perspose: 3d human pose estima- tion with perspective encoding and perspective rotation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 8110–8119, 2025
work page 2025
-
[10]
Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. Human3.6m: Large scale datasets and predic- tive methods for 3d human sensing in natural environments. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 36(7):1325–1339, 2014
work page 2014
-
[11]
Panoptic studio: A massively multiview system for social motion capture
Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh. Panoptic studio: A massively multiview system for social motion capture. InThe IEEE International Conference on Computer Vision (ICCV), 2015
work page 2015
-
[12]
Hanbyul Joo, Tomas Simon, Xulong Li, Hao Liu, Lei Tan, Lin Gui, Sean Banerjee, Timothy Scott Godisart, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh. Panoptic studio: A massively multiview sys- tem for social interaction capture.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 2017
work page 2017
-
[13]
Total cap- ture: A 3d deformation model for tracking faces, hands, and bodies
Hanbyul Joo, Tomas Simon, and Yaser Sheikh. Total cap- ture: A 3d deformation model for tracking faces, hands, and bodies. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8320–8329, 2018
work page 2018
-
[14]
Huang, Otmar Hilliges, and Michael J
Muhammed Kocabas, Chun-Hao P. Huang, Otmar Hilliges, and Michael J. Black. PARE: Part attention regressor for 3D human body estimation. InProc. International Conference on Computer Vision (ICCV), pages 11127–11137, 2021
work page 2021
-
[15]
Nikos Kolotouros, Georgios Pavlakos, Michael J Black, and Kostas Daniilidis. Learning to reconstruct 3d human pose and shape via model-fitting in the loop** supplementary ma- terial
-
[16]
Learning to reconstruct 3d human pose and shape via model-fitting in the loop
Nikos Kolotouros, Georgios Pavlakos, Michael J Black, and Kostas Daniilidis. Learning to reconstruct 3d human pose and shape via model-fitting in the loop. InICCV, 2019
work page 2019
-
[17]
Non-rigid structure from motion: Prior- free factorization method revisited
Suryansh Kumar. Non-rigid structure from motion: Prior- free factorization method revisited. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 51–60, 2020
work page 2020
-
[18]
Organic priors in non- rigid structure from motion
Suryansh Kumar and Luc Van Gool. Organic priors in non- rigid structure from motion. InEuropean Conference on Computer Vision, pages 71–88. Springer, 2022
work page 2022
-
[19]
Multi- body non-rigid structure-from-motion
Suryansh Kumar, Yuchao Dai, and Hongdong Li. Multi- body non-rigid structure-from-motion. In2016 Fourth In- ternational Conference on 3D Vision (3DV), pages 148–156. IEEE, 2016
work page 2016
-
[20]
Suryansh Kumar, Yuchao Dai, and Hongdong Li. Spatio- temporal union of subspaces for multi-body non-rigid structure-from-motion.Pattern Recognition, 71:428–443, 2017
work page 2017
-
[21]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer vision–ECCV 2014: 13th European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part v 13, pages 740–755. Springer, 2014
work page 2014
-
[22]
Mosh: motion and shape capture from sparse markers.ACM Trans
Matthew Loper, Naureen Mahmood, and Michael J Black. Mosh: motion and shape capture from sparse markers.ACM Trans. Graph., 33(6):220–1, 2014
work page 2014
-
[23]
Smpl: a skinned multi- person linear model.ACM Transactions on Graphics (TOG), 34(6):1–16, 2015
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: a skinned multi- person linear model.ACM Transactions on Graphics (TOG), 34(6):1–16, 2015
work page 2015
-
[24]
Smpl: A skinned multi- person linear model
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi- person linear model. InSeminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 851–866. 2023
work page 2023
-
[25]
Troje, Ger- ard Pons-Moll, and Michael J
Naureen Mahmood, Nima Ghorbani, Nikolaus F. Troje, Ger- ard Pons-Moll, and Michael J. Black. AMASS: Archive of motion capture as surface shapes. InIEEE/CVF Interna- tional Conference on Computer Vision (ICCV), pages 5442– 5451, 2019
work page 2019
-
[26]
Troje, Ger- ard Pons-Moll, and Michael J
Naureen Mahmood, Nima Ghorbani, Nikolaus F. Troje, Ger- ard Pons-Moll, and Michael J. Black. Amass: Archive of motion capture as surface shapes.arXiv, 2019
work page 2019
-
[27]
Meshcapade GmbH, T ¨ubingen, Germany, 2024
Meshcapade GmbH.Meshcapade: The Digital Human Plat- form. Meshcapade GmbH, T ¨ubingen, Germany, 2024
work page 2024
-
[28]
Dynamicfusion: Reconstruction and tracking of non-rigid scenes in real-time
Richard A Newcombe, Dieter Fox, and Steven M Seitz. Dynamicfusion: Reconstruction and tracking of non-rigid scenes in real-time. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 343–352, 2015
work page 2015
-
[29]
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. Expressive body capture: 3D hands, face, and body from a single image. InProceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 10975–10985, 2019
work page 2019
-
[30]
3d human pose estimation in video with tem- poral convolutions and semi-supervised training
Dario Pavllo, Christoph Feichtenhofer, David Grangier, and Michael Auli. 3d human pose estimation in video with tem- poral convolutions and semi-supervised training. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7753–7762, 2019
work page 2019
-
[31]
Yu Rong, Takaaki Shiratori, and Hanbyul Joo. Frankmo- cap: Fast monocular 3d hand and body motion capture by regression and integration.arXiv preprint arXiv:2008.08324, 2020
-
[32]
Wham: Reconstructing world-grounded humans with accu- rate 3d motion
Soyong Shin, Juyong Kim, Eni Halilaj, and Michael J Black. Wham: Reconstructing world-grounded humans with accu- rate 3d motion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2070– 2080, 2024
work page 2070
-
[33]
Leonid Sigal, Alexandru O Balan, and Michael J Black. Hu- maneva: Synchronized video and motion capture dataset and baseline algorithm for evaluation of articulated human mo- tion.International journal of computer vision, 87(1):4–27, 2010
work page 2010
-
[34]
Hand key- point detection in single images using multiview bootstrap- ping.CVPR, 2017
Tomas Simon, Hanbyul Joo, and Yaser Sheikh. Hand key- point detection in single images using multiview bootstrap- ping.CVPR, 2017
work page 2017
-
[35]
3d hu- man pose estimation via intuitive physics
Shashank Tripathi, Lea M ¨uller, Chun-Hao P Huang, Omid Taheri, Michael J Black, and Dimitrios Tzionas. 3d hu- man pose estimation via intuitive physics. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4713–4725, 2023
work page 2023
-
[36]
NP Van der Aa, Xinghan Luo, Geert-Jan Giezeman, Robby T Tan, and Remco C Veltkamp. Umpm benchmark: A multi- person dataset with synchronized video and motion capture data for evaluation of articulated human motion and interac- tion. In2011 IEEE international conference on computer vi- sion workshops (ICCV Workshops), pages 1264–1269. IEEE, 2011
work page 2011
-
[37]
Recovering accurate 3d human pose in the wild using imus and a moving camera
Timo von Marcard, Roberto Henschel, Michael Black, Bodo Rosenhahn, and Gerard Pons-Moll. Recovering accurate 3d human pose in the wild using imus and a moving camera. In European Conference on Computer Vision (ECCV), 2018
work page 2018
-
[38]
Prompthmr: Promptable human mesh recovery
Yufu Wang, Yu Sun, Priyanka Patel, Kostas Daniilidis, Michael J Black, and Muhammed Kocabas. Prompthmr: Promptable human mesh recovery. InProceedings of the computer vision and pattern recognition conference, pages 1148–1159, 2025
work page 2025
-
[39]
Decoupling human and camera motion from videos in the wild
Vickie Ye, Georgios Pavlakos, Jitendra Malik, and Angjoo Kanazawa. Decoupling human and camera motion from videos in the wild. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023. A Dataset and Evaluation for Complex 4D Markerless Human Motion Capture Supplementary Material Abstract Continuing with our main paper, this supplementary ...
work page 2023
-
[40]
Motion and Activity Type In this supplementary, we provide a more detailed descrip- tion of the motion categories in HUM4D and explain how the dataset is organized. HUM4D is designed to capture challenging motion patterns that are not sufficiently repre- sented in existing markerless motion-capture benchmarks, including rapid local motion, heavy interacti...
-
[41]
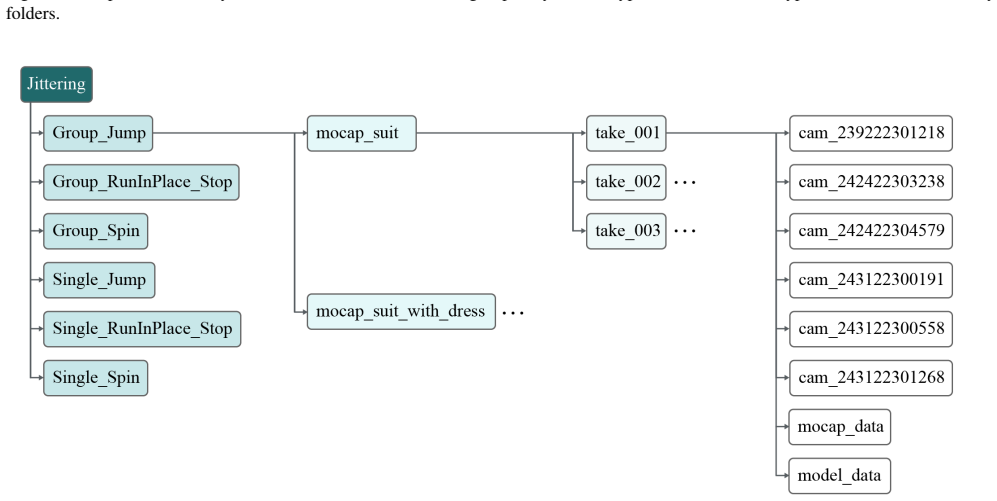
Dataset Arrangement In this section, we describe how HUM4D is organized for convenient access. As illustrated in Fig. 10 and Fig. 11, the dataset follows a hierarchical structure from motion type to action category, recording setting, take index, and camera streams and annotation files. At the top level, the dataset is divided into four mo- tion type grou...
-
[42]
Motion Type Analysis To further analyze method behavior on HUM4D, we report a breakdown of reconstruction performance by motion type. Since HUM4D is organized around four challenging motion categories, namelyOcclusion,ID Swap,Near-Far Cam- era, andJittering, this evaluation offers a more specific view of model behavior. As shown in Table 4,ID Swap Motion ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.