Recognition: no theorem link
Parcae: Scaling Laws For Stable Looped Language Models
Pith reviewed 2026-05-10 15:29 UTC · model grok-4.3
The pith
Parcae stabilizes looped language models by constraining spectral norms of injection parameters, enabling predictable scaling laws that improve quality with fixed parameters by increasing FLOPs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By recasting looping as a dynamical system and using a linear approximation to locate instability in large spectral norms, Parcae discretizes a negative diagonal parameterization to constrain those norms, producing stable training and explicit power-law scaling for increasing FLOPs via loops at fixed parameter count.
What carries the argument
Negative diagonal parameterization of injection parameters, discretized to enforce spectral norm bounds within the looped residual-stream dynamics.
If this is right
- For a fixed FLOP budget, training quality improves when loops and data are scaled together rather than one alone.
- Test-time looping produces quality gains that follow a predictable saturating exponential decay.
- Parcae yields up to 6.3 percent lower validation perplexity than earlier large-scale looped models.
- At 1.3B parameters Parcae raises CORE and Core-Extended scores by 2.99 and 1.18 points over strong transformer baselines under identical parameter and data limits.
Where Pith is reading between the lines
- If the derived power laws continue to larger scales, looped models could reduce peak memory during training by trading repeated passes for wider layers.
- The spectral-norm control may apply directly to other iterative or recurrent blocks in sequence models.
- Combining Parcae loops with mixture-of-experts routing could multiply the effective FLOP scaling without proportional parameter growth.
Load-bearing premise
The linear approximation to the nonlinear time-variant dynamical system accurately identifies instability sources, and discretizing the negative diagonal parameterization constrains norms without loss of capacity.
What would settle it
Train a 1.3B Parcae model and check whether residual explosion or loss spikes appear, or whether quality fails to rise as predicted when the number of loops is increased.
Figures


























read the original abstract
Traditional fixed-depth architectures scale quality by increasing training FLOPs, typically through increased parameterization, at the expense of a higher memory footprint, or data. A potential alternative is looped architectures, which instead increase FLOPs by sending activations through a block of layers in a loop. While promising, existing recipes for training looped architectures can be unstable, suffering from residual explosion and loss spikes. We address these challenges by recasting looping as a nonlinear time-variant dynamical system over the residual stream. Via a linear approximation to this system, we find that instability occurs in existing looped architectures as a result of large spectral norms in their injection parameters. To address these instability issues, we propose Parcae, a novel stable, looped architecture that constrains the spectral norm of the injection parameters via discretization of a negative diagonal parameterization. As a result, Parcae achieves up to 6.3% lower validation perplexity over prior large-scale looped models. Using our stable looped architecture, we investigate the scaling properties of looping as a medium to improve quality by increasing FLOPs in training and test-time. For training, we derive predictable power laws to scale FLOPs while keeping parameter count fixed. Our initial scaling laws suggest that looping and data should be increased in tandem, given a fixed FLOP budget. At test-time, we find that Parcae can use looping to scale compute, following a predictable, saturating exponential decay. When scaled up to 1.3B parameters, we find that Parcae improves CORE and Core-Extended quality by 2.99 and 1.18 points when compared to strong Transformer baselines under a fixed parameter and data budget, achieving a relative quality of up to 87.5% a Transformer twice the size.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Parcae, a looped language model that stabilizes training by modeling the loop as a nonlinear time-variant dynamical system over the residual stream. A linear approximation identifies large spectral norms in injection parameters as the instability source, addressed via discretization of a negative diagonal parameterization. The work derives training scaling laws (power laws suggesting tandem increases in looping and data at fixed FLOP budget) and test-time scaling (saturating exponential decay), and reports that at 1.3B parameters Parcae improves CORE and Core-Extended scores by 2.99 and 1.18 points over strong Transformer baselines under fixed parameter/data budgets, reaching up to 87.5% relative quality of a twice-larger Transformer.
Significance. If the linear approximation accurately diagnoses instability and the scaling laws prove robust, Parcae offers a memory-efficient alternative to parameter scaling for quality gains via increased FLOPs. The empirical results at 1.3B scale and the derivation of predictable laws (rather than purely empirical fits) are notable strengths that could influence efficient architecture design.
major comments (3)
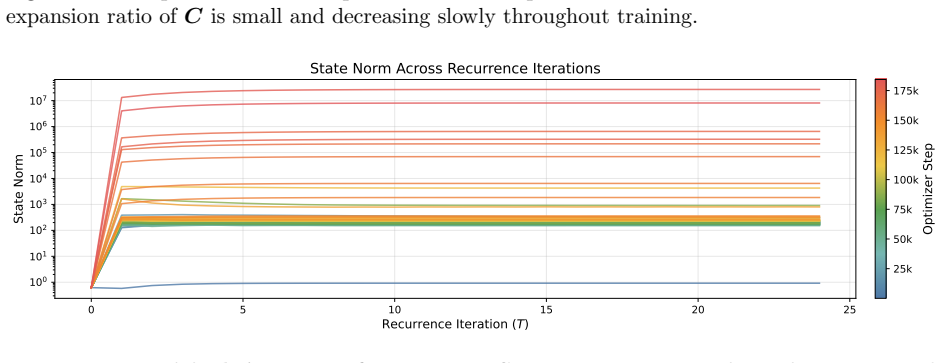
- [§3] §3 (Stability via Dynamical System): The central stability claim rests on the linear approximation to the nonlinear time-variant residual dynamics correctly identifying large spectral norms of injection parameters as the root cause, motivating the negative-diagonal discretization. No experiments or analysis verify that nonlinear interactions do not dominate, so the parameterization may constrain norms without addressing the actual failure mode; this is load-bearing for both stability and downstream scaling claims.
- [§4.1] §4.1 (Training Scaling Laws): The manuscript states that 'predictable power laws' govern scaling FLOPs at fixed parameter count and recommends increasing looping and data in tandem. However, no goodness-of-fit statistics (R², residual norms, or cross-validation details) or explicit functional forms are provided for the fitted laws, weakening the 'predictable' assertion and the recommendation for joint scaling.
- [§5.3] §5.3 (Test-time Scaling and 1.3B Evaluation): The saturating exponential decay for test-time looping is presented as predictable, and the 1.3B results claim 2.99/1.18 point gains plus 87.5% relative quality. The baseline comparisons lack explicit confirmation that Transformer controls received matched hyperparameter search or optimization budgets, risking attribution of gains to the Parcae parameterization rather than other factors.
minor comments (2)
- [Abstract] Abstract: The reported 'up to 6.3% lower validation perplexity over prior large-scale looped models' does not name the specific prior models or the scale at which the comparison holds.
- [§3] Notation and §3: The discretization step mapping the continuous negative diagonal parameterization to a discrete spectral-norm constraint would benefit from an explicit equation or pseudocode to clarify capacity preservation.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment point-by-point below, providing clarifications and committing to revisions where they strengthen the work without misrepresenting our contributions.
read point-by-point responses
-
Referee: [§3] §3 (Stability via Dynamical System): The central stability claim rests on the linear approximation to the nonlinear time-variant residual dynamics correctly identifying large spectral norms of injection parameters as the root cause, motivating the negative-diagonal discretization. No experiments or analysis verify that nonlinear interactions do not dominate, so the parameterization may constrain norms without addressing the actual failure mode; this is load-bearing for both stability and downstream scaling claims.
Authors: The linear approximation follows standard practice in dynamical systems analysis to identify dominant instability modes, as nonlinear systems are often diagnosed via their linearized behavior near equilibria. While nonlinear interactions are present, the parameterization's empirical success in stabilizing training (where prior looped models exhibit explosion and spikes) validates its practical utility. We will revise §3 to explicitly discuss the approximation's limitations as a diagnostic tool and note that full nonlinear verification remains an open direction. revision: partial
-
Referee: [§4.1] §4.1 (Training Scaling Laws): The manuscript states that 'predictable power laws' govern scaling FLOPs at fixed parameter count and recommends increasing looping and data in tandem. However, no goodness-of-fit statistics (R², residual norms, or cross-validation details) or explicit functional forms are provided for the fitted laws, weakening the 'predictable' assertion and the recommendation for joint scaling.
Authors: We agree that explicit functional forms and quantitative fit metrics are needed to support the predictability claim. In the revision, we will report the exact power-law equations (e.g., loss as function of FLOPs, loops, and data), R² values, residual diagnostics, and fitting methodology to substantiate the recommendation for tandem scaling of loops and data. revision: yes
-
Referee: [§5.3] §5.3 (Test-time Scaling and 1.3B Evaluation): The saturating exponential decay for test-time looping is presented as predictable, and the 1.3B results claim 2.99/1.18 point gains plus 87.5% relative quality. The baseline comparisons lack explicit confirmation that Transformer controls received matched hyperparameter search or optimization budgets, risking attribution of gains to the Parcae parameterization rather than other factors.
Authors: The Transformer baselines followed standard hyperparameter configurations from the literature, with additional tuning to match the fixed parameter and data budgets. We will revise §5.3 to detail the hyperparameter ranges explored, optimization procedures, and final settings for the baselines, clarifying that gains are attributable to the Parcae architecture under comparable training conditions. revision: partial
Circularity Check
No significant circularity; derivation relies on external empirical validation rather than self-reduction
full rationale
The abstract describes recasting looped models as a nonlinear dynamical system, applying a linear approximation to diagnose instability from spectral norms, and introducing a negative-diagonal discretization for stability. Scaling laws are stated as 'predictable power laws' and 'saturating exponential decay' derived for fixed-parameter FLOP scaling, with quality gains validated at 1.3B parameters against baselines. No equations or self-citations are provided that reduce any claimed prediction or uniqueness result to a fitted input or prior author work by construction; the central claims rest on observed stability and quality metrics rather than tautological reparameterization.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 5 Pith papers
-
SMolLM: Small Language Models Learn Small Molecular Grammar
A 53K-parameter model generates 95% valid SMILES on ZINC-250K, outperforming larger models, by resolving chemical constraints in fixed order: brackets first, rings second, valence last.
-
How Much Is One Recurrence Worth? Iso-Depth Scaling Laws for Looped Language Models
A fitted iso-depth scaling law measures that one recurrence in looped transformers is worth r^0.46 unique blocks in validation loss.
-
Dynamics of the Transformer Residual Stream: Coupling Spectral Geometry to Network Topology
Training installs a depth-dependent spectral gradient and low-rank bottleneck in LLM residual streams whose amplification or suppression of graph communities is predicted by local operator type.
-
Memory-Efficient Looped Transformer: Decoupling Compute from Memory in Looped Language Models
MELT decouples reasoning depth from memory in looped LLMs by sharing a single gated KV cache per layer and using two-phase chunk-wise distillation from Ouro, delivering constant memory use while matching or beating st...
-
Hyperloop Transformers
Hyperloop Transformers outperform standard and mHC Transformers with roughly 50% fewer parameters by looping a middle block of layers and applying hyper-connections only after each loop.
Reference graph
Works this paper leans on
-
[1]
Ibrahim Alabdulmohsin and Xiaohua Zhai. Recursive inference scaling: A winning path to scalable inference in language and multimodal systems, 2025. URL https://arxiv.org/abs/ 2502.07503
-
[2]
Mathqa: Towards interpretable math word problem solving with operation-based formalisms, 2019
Aida Amini, Saadia Gabriel, Peter Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. Mathqa: Towards interpretable math word problem solving with operation-based formalisms, 2019
2019
-
[3]
Noah Amsel, David Persson, Christopher Musco, and Robert M. Gower. The polar express: Optimal matrix sign methods and their application to the muon algorithm, 2025. URL https://arxiv.org/abs/2505.16932
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Path independent equilibrium models can better exploit test-time computation, 2022
Cem Anil, Ashwini Pokle, Kaiqu Liang, Johannes Treutlein, Yuhuai Wu, Shaojie Bai, Zico Kolter, and Roger Grosse. Path independent equilibrium models can better exploit test-time computation, 2022. URLhttps://arxiv.org/abs/2211.09961
-
[5]
Sangmin Bae, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Seungyeon Kim, and Tal Schuster. Relaxed recursive transformers: Effective parameter sharing with layer-wise lora.ArXiv, abs/2410.20672, 2024. URLhttps://api.semanticscholar.org/CorpusID:273654907
-
[6]
Mixture-of-recursions: Learning dynamic recursive depths for adaptive token-level computation
Sangmin Bae, Yujin Kim, Reza Bayat, Sungnyun Kim, Jiyoun Ha, Tal Schuster, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Aaron Courville, and Se-Young Yun. Mixture-of-recursions: Learning dynamic recursive depths for adaptive token-level computation, 2025. URL https: //arxiv.org/abs/2507.10524
-
[7]
Zico Kolter, and Vladlen Koltun
Shaojie Bai, J. Zico Kolter, and Vladlen Koltun. Deep equilibrium models, 2019. URL https://arxiv.org/abs/1909.01377
-
[8]
Neural deep equilibrium solvers
Shaojie Bai, Vladlen Koltun, and J Zico Kolter. Neural deep equilibrium solvers. InInternational Conference on Learning Representations, 2022. URL https://openreview.net/forum?id= B0oHOwT5ENL
2022
-
[9]
The winograd schema challenge and reasoning about correlation
Daniel Bailey, Amelia Harrison, Yuliya Lierler, Vladimir Lifschitz, and Julian Michael. The winograd schema challenge and reasoning about correlation. InWorking Notes of the Symposium on Logical Formalizations of Commonsense Reasoning. AAAI Press, 2015. URL http://www. cs.utexas.edu/users/ai-lab?wsc15
2015
-
[10]
End-to-end algorithm synthesis with recurrent networks: Extrapolation without overthinking
Arpit Bansal, Avi Schwarzschild, Eitan Borgnia, Zeyad Emam, Furong Huang, Micah Goldblum, and Tom Goldstein. End-to-end algorithm synthesis with recurrent networks: Extrapolation without overthinking. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022. URL https://openreview...
2022
-
[11]
PIQA: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. PIQA: Reasoning about physical commonsense in natural language. InProceedings of the AAAI conference on Artificial Intelligence, volume 34, 2020
2020
-
[12]
Cautious weight decay.arXiv preprint arXiv:2510.12402, 2025
Lizhang Chen, Jonathan Li, Kaizhao Liang, Baiyu Su, Cong Xie, Nuo Wang Pierse, Chen Liang, Ni Lao, and Qiang Liu. Cautious weight decay, 2026. URL https://arxiv.org/abs/ 2510.12402. 12
-
[13]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradb...
work page internal anchor Pith review arXiv 2022
-
[14]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. In NAACL, 2019
2019
-
[15]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [16]
-
[17]
Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality, 2024. URLhttps://arxiv.org/abs/2405.21060
work page internal anchor Pith review arXiv 2024
-
[18]
Uni- versal transformers
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Lukasz Kaiser. Uni- versal transformers. InInternational Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=HyzdRiR9Y7
2019
-
[19]
C. Desoer and Min-Yen Wu. Stability of linear time-invariant systems.IEEE Transactions on Circuit Theory, 15(3):245–250, 1968. doi: 10.1109/TCT.1968.1082819
-
[20]
The case for 4-bit precision: k-bit inference scaling laws,
Tim Dettmers and Luke Zettlemoyer. The case for 4-bit precision: k-bit inference scaling laws,
- [21]
-
[22]
arXiv preprint arXiv:2404.10830 , year=
Hantian Ding, Zijian Wang, Giovanni Paolini, Varun Kumar, Anoop Deoras, Dan Roth, and Stefano Soatto. Fewer truncations improve language modeling, 2024. URL https: //arxiv.org/abs/2404.10830
-
[23]
Depth-adaptive transformer
Maha Elbayad, Jiatao Gu, Edouard Grave, and Michael Auli. Depth-adaptive transformer. In International Conference on Learning Representations, 2020. URL https://openreview.net/ forum?id=SJg7KhVKPH
2020
-
[24]
Sigmoid-weighted linear units for neural network function approximation in reinforcement learning, 2017
Stefan Elfwing, Eiji Uchibe, and Kenji Doya. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning, 2017. URL https://arxiv.org/abs/1702. 03118. 13
2017
-
[25]
LayerSkip: enabling early exit inference and self- speculative decoding
Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer, Bram Wasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, Ahmed Aly, Beidi Chen, and Carole-Jean Wu. Layerskip: Enabling early exit inference and self-speculative decoding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics ...
-
[26]
Katie Everett, Lechao Xiao, Mitchell Wortsman, Alexander A. Alemi, Roman Novak, Peter J. Liu, Izzeddin Gur, Jascha Sohl-Dickstein, Leslie Pack Kaelbling, Jaehoon Lee, and Jeffrey Pennington. Scaling exponents across parameterizations and optimizers, 2024. URL https: //arxiv.org/abs/2407.05872
-
[27]
Cramming: Training a language model on a single GPU in one day
Jonas Geiping and Tom Goldstein. Cramming: Training a language model on a single GPU in one day. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Proceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 11117–11143. P...
2023
-
[28]
Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein
Jonas Geiping, Sean Michael McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R. Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/ forum...
2025
-
[29]
SemEval-2012 task 7: Choice of plausible alternatives: An evaluation of commonsense causal reasoning
Andrew Gordon, Zornitsa Kozareva, and Melissa Roemmele. SemEval-2012 task 7: Choice of plausible alternatives: An evaluation of commonsense causal reasoning. In Eneko Agirre, Johan Bos, Mona Diab, Suresh Manandhar, Yuval Marton, and Deniz Yuret, editors,*SEM 2012: The First Joint Conference on Lexical and Computational Semantics – Volume 1: Proceedings of...
2012
-
[30]
Mamba: Linear-time sequence modeling with selective state spaces,
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces,
-
[31]
URLhttps://arxiv.org/abs/2312.00752
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding, 2021. URL https: //arxiv.org/abs/2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
Alex Henry, Prudhvi Raj Dachapally, Shubham Pawar, and Yuxuan Chen. Query-key normal- ization for transformers, 2020. URLhttps://arxiv.org/abs/2010.04245
-
[34]
Hinton and Ilya Sutskever
Geoffrey E. Hinton and Ilya Sutskever. Training recurrent neural networks, 2013. URL https://api.semanticscholar.org/CorpusID:61713861
2013
-
[35]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent 14 Si...
work page internal anchor Pith review arXiv 2022
-
[36]
Peter J. Huber. Robust Estimation of a Location Parameter.The Annals of Mathematical Statistics, 35(1):73 – 101, 1964. doi: 10.1214/aoms/1177703732. URL https://doi.org/10. 1214/aoms/1177703732
-
[37]
Block-recurrent dynamics in vision transformers.arXiv preprint arXiv:2512.19941, 2025
Mozes Jacobs, Thomas Fel, Richard Hakim, Alessandra Brondetta, Demba Ba, and T. Andy Keller. Block-recurrent dynamics in vision transformers, 2026. URL https://arxiv.org/abs/ 2512.19941
-
[38]
Loopformer: Elastic-depth looped transformers for latent reasoning via shortcut modulation
Ahmadreza Jeddi, Marco Ciccone, and Babak Taati. Loopformer: Elastic-depth looped transformers for latent reasoning via shortcut modulation. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id= RzYXb5YWBs
2026
-
[39]
Pubmedqa: A dataset for biomedical research question answering
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2567–2577, 2019
2019
-
[40]
Less is More: Recursive Reasoning with Tiny Networks
Alexia Jolicoeur-Martineau. Less is more: Recursive reasoning with tiny networks, 2025. URL https://arxiv.org/abs/2510.04871
work page internal anchor Pith review arXiv 2025
-
[41]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan, Yuchen Jin, Vlado Boza, You Jiacheng, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks, 2024. URL https://kellerjordan.github.io/posts/muon/
2024
-
[42]
200,000+ Jeopardy! Questions, 2019
kaggle200000Jeopardy. 200,000+ Jeopardy! Questions, 2019. URL https://www.kaggle.com/ datasets/tunguz/200000-jeopardy-questions
2019
-
[43]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020. URLhttps://arxiv.org/abs/2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[44]
nanochat: The best chatgpt that$100 can buy, 2025
Andrej Karpathy. nanochat: The best chatgpt that$100 can buy, 2025. URL https://github. com/karpathy/nanochat
2025
-
[45]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017. URL https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Encode, think, decode: Scaling test-time reasoning with recursive latent thoughts, 2025
Yeskendir Koishekenov, Aldo Lipani, and Nicola Cancedda. Encode, think, decode: Scaling test-time reasoning with recursive latent thoughts, 2025. URL https://arxiv.org/abs/2510. 07358
2025
-
[47]
Datacomp- LM : In search of the next generation of training sets for language models
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, Saurabh Garg, Rui Xin, Niklas Muennighoff, Reinhard Heckel, Jean Mercat, Mayee Chen, Suchin Gururangan, Mitchell Wortsman, Alon Albalak, Yonatan Bitton, Marianna Nezhurina, Amro Abbas, Cheng-Yu Hsieh, Dhruba Ghosh, Josh Gardn...
-
[48]
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for llm compression and acceleration, 2024. URLhttps://arxiv.org/abs/2306.00978
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Logiqa: A challenge dataset for machine reading comprehension with logical reasoning, 2020
Jian Liu, Leyang Cui, Hanmeng Liu, Dandan Huang, Yile Wang, and Yue Zhang. Logiqa: A challenge dataset for machine reading comprehension with logical reasoning, 2020
2020
-
[50]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. URLhttps: //arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[51]
Bartoldson, Bhavya Kailkhura, Avi Schwarzschild, Jonas Geiping, Tom Goldstein, and Micah Goldblum
Sean McLeish, Ang Li, John Kirchenbauer, Dayal Singh Kalra, Brian R. Bartoldson, Bhavya Kailkhura, Avi Schwarzschild, Jonas Geiping, Tom Goldstein, and Micah Goldblum. Teach- ing pretrained language models to think deeper with retrofitted recurrence.arXiv preprint arXiv:2511.07384, 2025
-
[52]
Pointer sentinel mixture models, 2016
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models, 2016
2016
-
[53]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering, 2018. URL https: //arxiv.org/abs/1809.02789
work page internal anchor Pith review arXiv 2018
-
[54]
Lpu: A latency-optimized and highly scalable processor for large language model inference, 2024
Seungjae Moon, Jung-Hoon Kim, Junsoo Kim, Seongmin Hong, Junseo Cha, Minsu Kim, Sukbin Lim, Gyubin Choi, Dongjin Seo, Jongho Kim, Hunjong Lee, Hyunjun Park, Ryeowook Ko, Soongyu Choi, Jongse Park, Jinwon Lee, and Joo-Young Kim. Lpu: A latency-optimized and highly scalable processor for large language model inference, 2024. URL https://arxiv. org/abs/2408.07326
-
[55]
llm-foundry: Llm training and evaluation framework, 2023
MosaicML. llm-foundry: Llm training and evaluation framework, 2023. URL https://github. com
2023
-
[56]
Minions: Cost-efficient collaboration between on-device and cloud language models, 2025
Avanika Narayan, Dan Biderman, Sabri Eyuboglu, Avner May, Scott Linderman, James Zou, and Christopher Re. Minions: Cost-efficient collaboration between on-device and cloud language models, 2025. URLhttps://arxiv.org/abs/2502.15964
-
[57]
Jorge Nocedal. Updating quasi-newton matrices with limited storage.Mathematics of Com- putation, 35(151):773–782, 1980. ISSN 00255718, 10886842. URL http://www.jstor.org/ stable/2006193
-
[58]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, a...
work page internal anchor Pith review arXiv 2022
-
[59]
OpenAI. Gpt-4 technical report, 2024. URLhttps://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[60]
The LAMBADA dataset: Word prediction requiring a broad discourse context
Denis Paperno, Germ´ an Kruszewski, Angeliki Lazaridou, Ngoc-Quan Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fern´ andez. The LAMBADA dataset: Word prediction requiring a broad discourse context. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics, pages 1525–1534, 2016
2016
- [61]
-
[62]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Guilherme Penedo, Hynek Kydl´ ıˇ cek, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale, 2024. URLhttps://arxiv.org/abs/2406.17557
work page internal anchor Pith review arXiv 2024
-
[63]
Language models are unsupervised multitask learners
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019
2019
-
[64]
Squad: 100,000+ questions for machine comprehension of text, 2016
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text, 2016. URL https://arxiv.org/abs/1606. 05250
2016
- [65]
-
[66]
Siva Reddy, Danqi Chen, and Christopher D. Manning. Coqa: A conversational question answering challenge, 2019. URLhttps://arxiv.org/abs/1808.07042
work page Pith review arXiv 2019
-
[67]
Rachel Rudinger, Jason Naradowsky, Brian Leonard, and Benjamin Van Durme. Gender bias in coreference resolution, 2018. URLhttps://arxiv.org/abs/1804.09301
-
[68]
Winogrande: An adversarial Winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial Winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
2021
-
[69]
Socialiqa: Commonsense reasoning about social interactions, 2019
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. Socialiqa: Commonsense reasoning about social interactions, 2019. URL https://arxiv.org/abs/1904. 09728
2019
- [70]
-
[71]
Can you learn an algorithm? generalizing from easy to hard problems with recurrent networks
Avi Schwarzschild, Eitan Borgnia, Arjun Gupta, Furong Huang, Uzi Vishkin, Micah Goldblum, and Tom Goldstein. Can you learn an algorithm? generalizing from easy to hard problems with recurrent networks. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, 2021. URL https://openreview. n...
2021
-
[72]
Glu variants improve transformer, 2020
Noam Shazeer. Glu variants improve transformer, 2020. URL https://arxiv.org/abs/2002. 05202. 17
2020
-
[73]
AdaMuon: Adaptive Muon optimizer.arXiv preprint arXiv:2507.11005, 2025
Chongjie Si, Debing Zhang, and Wei Shen. Adamuon: Adaptive muon optimizer, 2025. URL https://arxiv.org/abs/2507.11005
-
[74]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, Adam Santoro, Aditya Gupta, Adri` a Garriga-Alonso, Agnieszka Kluska, Aitor Lewkowycz, Akshat Agarwal, Alethea Power, Alex Ray, Alex Warstadt, Alexander W. Kocurek, Ali Safaya, Ali Tazarv, Alice Xiang, Alicia Parrish, Allen Nie, Aman Hussain, Ama...
work page internal anchor Pith review arXiv 2023
-
[75]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding, 2023. URL https://arxiv.org/abs/ 2104.09864
work page internal anchor Pith review arXiv 2023
-
[76]
Spike no more: Stabilizing the pre-training of large language models, 2025
Sho Takase, Shun Kiyono, Sosuke Kobayashi, and Jun Suzuki. Spike no more: Stabilizing the pre-training of large language models, 2025. URLhttps://arxiv.org/abs/2312.16903
-
[77]
CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge, 2019. URL https://arxiv. org/abs/1811.00937
work page Pith review arXiv 2019
-
[78]
Resformer: Scaling vits with multi-resolution training, 2023
Rui Tian, Zuxuan Wu, Qi Dai, Han Hu, Yu Qiao, and Yu-Gang Jiang. Resformer: Scaling vits with multi-resolution training, 2023. URLhttps://arxiv.org/abs/2212.00776
-
[79]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ ee Lacroix, Baptiste Rozi` ere, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models, 2023. URLhttps://arxiv.org/abs/2302.13971
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[80]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023. URL https://arxiv. org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.