Recognition: no theorem link
Can Large Language Models Reliably Extract Physiology Index Values from Coronary Angiography Reports?
Pith reviewed 2026-05-15 07:44 UTC · model grok-4.3
The pith
Large language models can extract physiological index values from Portuguese coronary angiography reports using zero-shot prompting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
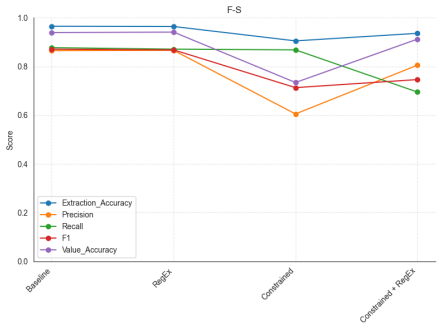
Large language models successfully extract physiological index values and locations from Portuguese CAG reports. On a corpus of 1342 reports, Llama with zero-shot prompting produced the highest accuracy, GPT-OSS showed the greatest stability across prompt variations, and general-purpose models matched the performance of medical-domain models. The multi-stage evaluation framework separated format compliance, value detection, and correctness while weighting errors according to their clinical consequences, and constrained generation plus regex post-processing produced no consistent gains.
What carries the argument
The multi-stage evaluation framework that checks format validity, detects values, and verifies correctness while accounting for asymmetric clinical error costs.
If this is right
- Physiological measurements buried in CAG text become usable for large-scale clinical research without manual review.
- General-purpose LLMs can perform medical information extraction tasks at the same level as specialized medical models.
- Zero-shot prompting suffices for this task, removing the need to curate example sets for each deployment.
- Constrained generation enables certain open models but lowers overall extraction accuracy compared with unconstrained prompting.
Where Pith is reading between the lines
- The same prompting and evaluation pattern could be tested on angiography reports written in other languages.
- Hospital record systems could run these models routinely to turn free-text notes into structured physiology fields.
- Robustness to prompt wording suggests the method could transfer across different hospital documentation styles with little retuning.
Load-bearing premise
The 1342 reports carry accurate ground-truth annotations and represent the variety of typical coronary angiography reports.
What would settle it
A fresh collection of 200 CAG reports with independently double-checked annotations on which the models achieve the same rates of value-correct extraction reported in the study.
Figures










read the original abstract
Coronary angiography (CAG) reports contain clinically relevant physiological measurements, yet this information is typically in the form of unstructured natural language, limiting its use in research. We investigate the use of Large Language Models (LLMs) to automatically extract these values, along with their anatomical locations, from Portuguese CAG reports. To our knowledge, this study is the first addressing physiology indexes extraction from a large (1342 reports) corpus of CAG reports, and one of the few focusing on CAG or Portuguese clinical text. We explore local privacy-preserving general-purpose and medical LLMs under different settings. Prompting strategies included zero-shot, few-shot, and few-shot prompting with implausible examples. In addition, we apply constrained generation and introduce a post-processing step based on RegEx. Given the sparsity of measurements, we propose a multi-stage evaluation framework separating format validity, value detection, and value correctness, while accounting for asymmetric clinical error costs. This study demonstrates the potential of LLMs in for extracting physiological indices from Portuguese CAG reports. Non-medical models performed similarly, the best results were obtained with Llama with a zero-shot prompting, while GPT-OSS demonstrated the highest robustness to changes in the prompts. While MedGemma demonstrated similar results to non-medical models, MedLlama's results were out-of-format in the unconstrained setting, and had a significant lower performance in the constrained one. Changes in the prompt techinique and adding a RegEx layer showed no significant improvement across models, while using constrained generation decreased performance, although having the benefit of allowing the usage of specific models that are not able to conform with the templates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study on using large language models (LLMs) to extract physiological index values and their anatomical locations from 1342 Portuguese coronary angiography (CAG) reports. It evaluates general-purpose and medical LLMs with various prompting strategies (zero-shot, few-shot, few-shot with implausible examples), constrained generation, and RegEx post-processing. A multi-stage evaluation framework is introduced to assess format validity, value detection, and correctness while considering asymmetric clinical error costs. The authors conclude that non-medical models perform similarly to medical ones, with Llama in zero-shot prompting yielding the best results and GPT-OSS showing highest robustness to prompt changes.
Significance. If substantiated with proper validation, this work could advance clinical NLP by showing that LLMs enable automated extraction of structured physiological data from unstructured CAG reports in Portuguese, supporting privacy-preserving local model use and large-scale research. The multi-stage evaluation framework sensibly handles sparse measurements and asymmetric error costs. The study is among the first on physiology index extraction from CAG reports and Portuguese clinical text, with credit due for exploring both medical and non-medical models plus constrained generation.
major comments (2)
- [Methods (Corpus and ground-truth annotation)] The ground-truth annotation process for the 1342-report corpus is not described (no protocol, number of annotators, expertise level such as cardiologist involvement, or inter-annotator agreement metric). This is load-bearing for the central claim of reliable extraction, as the multi-stage correctness evaluation (format validity → detection → correctness) cannot distinguish model errors from label noise without these details.
- [Results and Evaluation] No non-LLM baselines (e.g., rule-based extraction or traditional NLP methods) or statistical tests are reported to contextualize the LLM performance claims, including the assertion that Llama zero-shot is best and GPT-OSS most robust. This weakens support for the comparative conclusions in the multi-stage framework.
minor comments (2)
- [Abstract] Abstract contains typos: 'techinique' should be 'technique' and 'in for extracting' should be 'in extracting'.
- [Abstract] The abstract provides no quantitative results, performance metrics, or statistical details, which is atypical for an empirical evaluation paper and reduces immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to strengthen the description of our methods and evaluation.
read point-by-point responses
-
Referee: [Methods (Corpus and ground-truth annotation)] The ground-truth annotation process for the 1342-report corpus is not described (no protocol, number of annotators, expertise level such as cardiologist involvement, or inter-annotator agreement metric). This is load-bearing for the central claim of reliable extraction, as the multi-stage correctness evaluation (format validity → detection → correctness) cannot distinguish model errors from label noise without these details.
Authors: We agree that a detailed description of the ground-truth annotation process is necessary to support the reliability of our evaluation. In the revised manuscript, we will add a dedicated subsection in Methods describing the annotation protocol, the number of annotators, their expertise (including cardiologist involvement), and the inter-annotator agreement metric. This addition will allow readers to evaluate potential label noise separately from model errors in the multi-stage framework. revision: yes
-
Referee: [Results and Evaluation] No non-LLM baselines (e.g., rule-based extraction or traditional NLP methods) or statistical tests are reported to contextualize the LLM performance claims, including the assertion that Llama zero-shot is best and GPT-OSS most robust. This weakens support for the comparative conclusions in the multi-stage framework.
Authors: We acknowledge that non-LLM baselines and statistical tests would better contextualize our performance claims. In the revision, we will add a rule-based baseline (extending the RegEx post-processing already described in the study) and include statistical significance tests (e.g., McNemar's test) on key metrics to support the comparative conclusions regarding Llama zero-shot performance and GPT-OSS robustness. These will be presented in the Results section. revision: yes
Circularity Check
No significant circularity: purely empirical evaluation against external annotations
full rationale
The paper performs a direct empirical comparison of LLM outputs against a fixed corpus of 1342 annotated Portuguese CAG reports using a multi-stage evaluation framework (format validity, detection, correctness with asymmetric costs). No mathematical derivations, equations, fitted parameters, or predictions are claimed. The central results (Llama zero-shot best, GPT-OSS most robust) are obtained by measuring model performance on held-out annotations rather than by any self-referential definition or reduction to inputs. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked; the study is self-contained against external ground truth.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Ground-truth annotations for the 1342 reports are accurate and the corpus is representative
- domain assumption Asymmetric clinical error costs are appropriately modeled in the multi-stage framework
Reference graph
Works this paper leans on
-
[1]
World Health Organization. The top 10 causes of death. Last accessed January 2026
work page 2026
-
[2]
N. H. Pijls, B. Van Gelder, P. Van der Voort, K. Peels, F. A. Bracke, H. J. Bonnier, and M. I. el Gamal. Fractional flow reserve. a useful index to evaluate the influence of an epicardial coronary stenosis on myocardial blood flow.Circulation, 92(11):3183–3193, December 1995
work page 1995
-
[3]
Christiaan Vrints, Felicita Andreotti, Konstanti- nos C Koskinas, Xavier Rossello, Marianna Adamo, James Ainslie, Adrian Paul Banning, Andrzej Bu- daj, Ronny R Buechel, Giovanni Alfonso Chiariello, Alaide Chieffo, Ruxandra Maria Christodorescu, Christi Deaton, Torsten Doenst, Hywel W Jones, Vijay Kunadian, Julinda Mehilli, Milan Milojevic, Jan J Piek, Fra...
work page 2024
-
[4]
Miguel Nobre Menezes, Jo˜ ao Louren¸ co Silva, Beat- riz Silva, Tiago Rodrigues, Cl´ audio Guerreiro, Jo˜ ao Pedro Guedes, Manuel Oliveira Santos, Ar- lindo L. Oliveira, and Fausto J. Pinto. Coronary x-ray angiography segmentation using artificial in- telligence: a multicentric validation study of a deep learning model.The International Journal of Car- di...
work page 2023
-
[5]
Zihan Wang, Ziyi Sun, Linghua Yu, Zhitian Wang, Lin Li, and Xiaoyan Lu. Machine learning-based prediction of composite risk of cardiovascular events in patients with stable angina pectoris combined with coronary heart disease: development and val- idation of a clinical prediction model for chinese patients.Frontiers in Pharmacology, 14, January 2024
work page 2024
-
[6]
Large language models in medicine.Nature Medicine, 29(8):1930–1940, 2023
AJ Thirunavukarasu, DSJ Ting, K Elangovan, L Gutierrez, TF Tan, and DSW Ting. Large language models in medicine.Nature Medicine, 29(8):1930–1940, 2023
work page 1930
-
[7]
D. Van Veen, C. Van Uden, L. Blankemeier, J. B. Delbrouck, A. Aali, C. Bluethgen, A. Pareek, M. Polacin, E. P. Reis, A. Seehofnerov´ a, N. Rohatgi, P. Hosamani, W. Collins, N. Ahuja, C. P. Langlotz, J. Hom, S. Gatidis, J. Pauly, and A. S. Chaud- hari. Adapted large language models can outper- form medical experts in clinical text summarization. Nature Med...
work page 2024
-
[8]
Karan Singhal, Shekoofeh Azizi, Tao Tu, S. Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, Perry Payne, Martin Seneviratne, Paul Gam- ble, Chris Kelly, Abubakr Babiker, Nathanael Sch¨ arli, Aakanksha Chowdhery, Philip Mansfield, Dina Demner-Fushman, Blaise Ag¨ uera y Arcas, Dale Webster, Greg S. Co...
work page 2023
-
[9]
Jun Kanzawa, Koichiro Yasaka, Nana Fujita, Shin Fujiwara, and Osamu Abe. Automated classifica- tion of brain mri reports using fine-tuned large lan- guage models.Neuroradiology, 12 2024
work page 2024
-
[10]
Dandan Wang and Shiqing Zhang. Large language models in medical and healthcare fields: applica- tions, advances, and challenges.Artificial Intelli- gence Review, 57, 11 2024
work page 2024
-
[11]
M. Omar, S. Soffer, A. W. Charney, I. Landi, G. N. Nadkarni, and E. Klang. Applications of large lan- guage models in psychiatry: a systematic review. Frontiers in Psychiatry, 15:1422807, 2024
work page 2024
-
[12]
Piotr Wo´ znicki, Caroline Laqua, Ina Fiku, Amar Hekalo, Daniel Truhn, Sandy Engelhardt, Jakob Kather, Sebastian Foersch, Tugba Akinci D’Antonoli, Daniel Pinto Dos Santos, Bettina Baeßler, and Fabian Christopher Laqua. Automatic structuring of radiology reports with on-premise open-source large language models.European Ra- diology, 2024
work page 2024
-
[13]
Boonstra, Davy Weissenbacher, Ja- son H
Machteld J. Boonstra, Davy Weissenbacher, Ja- son H. Moore, Graciela Gonzalez-Hernandez, and Folkert W. Asselbergs. Artificial intelligence: Rev- olutionizing cardiology with large language models, 2 2024
work page 2024
-
[14]
McCoy, Faye Yu Ci Ng, Christopher M
Liam G. McCoy, Faye Yu Ci Ng, Christopher M. Sauer, Katelyn Edelwina Yap Legaspi, Bhav Jain, Jack Gallifant, Michael McClurkin, Alessandro Hammond, Deirdre Goode, Judy Gichoya, and Leo Anthony Celi. Understanding and training for the impact of large language models and artificial intelligence in healthcare practice: a narrative re- view, 12 2024
work page 2024
-
[15]
Giorgio Quer and Eric J. Topol. The potential for large language models to transform cardiovascular medicine, 10 2024
work page 2024
-
[16]
Ji Woo Song, Ji Yong Jang, Hyeongsoo Kim, Young-Guk Ko, and Seng Chan You. Transforming free-text coronary angiography reports into struc- tured, analyzable data using large language models. Scientific Reports, 16(1), January 2026
work page 2026
-
[17]
Apresentamos o gpt-5, August 7 2025
OpenAI. Apresentamos o gpt-5, August 7 2025. Accessed: 2026-02-14
work page 2025
-
[18]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ah- mad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aure- lien Rodriguez, Austen Gregerson, A...
work page 2024
-
[19]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chap- lot, Diego de las Casas, Florian Bressand, Gi- anna Lengyel, Guillaume Lample, Lucile Saulnier, L´ elio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth´ ee Lacroix, and William El Sayed. Mistral 7b. 10 2023
work page 2023
-
[20]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xi- aokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai...
work page 2025
-
[21]
Eriksen, S¨ oren M¨ oller, and Jesper Ryg
Alexander V. Eriksen, S¨ oren M¨ oller, and Jesper Ryg. Use of gpt-4 to diagnose complex clinical cases. NEJM AI, 1(1), November 2024
work page 2024
-
[22]
G. Liu, X. Ma, Y. Zhang, et al. Gpt4: The indis- pensable helper for neurosurgeons in the new era. Annals of Biomedical Engineering, 51:2113–2115, 2023
work page 2023
-
[23]
Adams, Daniel Truhn, Felix Busch, Avan Kader, Stefan M
Lisa C. Adams, Daniel Truhn, Felix Busch, Avan Kader, Stefan M. Niehues, Marcus R. Makowski, and Keno K. Bressem. Leveraging gpt-4 for post hoc transformation of free-text radiology reports into structured reporting: A multilingual feasibil- ity study.Radiology, 307, 5 2023
work page 2023
-
[24]
Steiner, Can Kirmizibayrak, Rory Pilgrim, Daniel Golden, and Lin Yang
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, C´ ıan Hughes, Charles Lau, Justin Chen, Fereshteh Mahvar, Liron Yatziv, Tiffany Chen, Bram Sterling, Ste- fanie Anna Baby, Susanna Maria Baby, Jeremy Lai, Samuel Schmidgall, Lu Yang, Kejia Chen, Per Bjornsson, Shashir Reddy, Rya...
work page 2025
-
[25]
Llama 2: Open foundation and fine-tuned chat models, 2023
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Niko- lay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cris- tian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony H...
work page 2023
- [26]
-
[27]
Smith, Christopher Parisien, Colin Compas, Cheryl Martin, An- 14 thony B
Xi Yang, Aokun Chen, Nima PourNejatian, Hoo Chang Shin, Kaleb E. Smith, Christopher Parisien, Colin Compas, Cheryl Martin, An- 14 thony B. Costa, Mona G. Flores, Ying Zhang, Tanja Magoc, Christopher A. Harle, Gloria Lipori, Du- ane A. Mitchell, William R. Hogan, Elizabeth A. Shenkman, Jiang Bian, and Yonghui Wu. A large language model for electronic healt...
work page 2022
-
[28]
Khaled Saab, Tao Tu, Wei-Hung Weng, Ryutaro Tanno, David Stutz, Ellery Wulczyn, Fan Zhang, Tim Strother, Chunjong Park, Elahe Vedadi, Juanma Zambrano Chaves, Szu-Yeu Hu, Mike Schaekermann, Aishwarya Kamath, Yong Cheng, David G. T. Barrett, Cathy Cheung, Basil Mustafa, Anil Palepu, Daniel McDuff, Le Hou, Tomer Golany, Luyang Liu, Jean baptiste Alayrac, Nei...
work page 2024
-
[29]
Ferreira, Pedro Chaves, and Luis B
Miguel Nunes, Jo˜ ao Bon´ e, Jo˜ ao C. Ferreira, Pedro Chaves, and Luis B. Elvas. Medialbertina: An eu- ropean portuguese medical language model.Com- puters in Biology and Medicine, 182, 11 2024
work page 2024
-
[30]
BioBERTpt - a Portuguese neural language model for clinical named entity recognition
Elisa Terumi Rubel Schneider, Jo˜ ao Vitor Andri- oli de Souza, Julien Knafou, Lucas Emanuel Silva e Oliveira, Jenny Copara, Yohan Bonescki Gumiel, Lucas Ferro Antunes de Oliveira, Emerson Cabr- era Paraiso, Douglas Teodoro, and Cl´ audia Maria Cabral Moro Barra. BioBERTpt - a Portuguese neural language model for clinical named entity recognition. InProce...
work page 2020
-
[31]
Developing a virtual diagnosis and health as- sistant chatbot leveraging llama3
Anjali Patel, Rajpurohit Shivani, and Manjunatha P B. Developing a virtual diagnosis and health as- sistant chatbot leveraging llama3. In2024 8th In- ternational Conference on Computational System and Information Technology for Sustainable Solu- tions (CSITSS), pages 1–6, 2024
work page 2024
-
[32]
Laura Bergomi. Reshaping free-text radiology notes into structured reports with generative transform- ers.Artificial Intelligence in Medicine, 154, 2024
work page 2024
-
[33]
Jenish Maharjan, Anurag Garikipati, Navan Preet Singh, Leo Cyrus, Mayank Sharma, Madalina Ciobanu, Gina Barnes, Rahul Thapa, Qingqing Mao, and Ritankar Das. Openmedlm: prompt en- gineering can out-perform fine-tuning in medical question-answering with open-source large language models.Scientific Reports, 14, 12 2024
work page 2024
-
[34]
H Adam, J Lin, J Lin, H Keenan, A Wilson, and M Ghassemi. Clinical information extraction with large language models: A case study on organ pro- curement.AMIA Annu Symp Proc, 2024:115–123, May 22 2025
work page 2024
- [35]
-
[36]
Large lan- guage models in cardiology: A systematic review, 9 2024
Moran Gendler, Girish N Nadkarni, Karin Sudri, Michal Cohen-Shelly, Benjamin S Glicksberg, Orly Efros, Shelly Soffer, and Eyal Klang. Large lan- guage models in cardiology: A systematic review, 9 2024
work page 2024
-
[37]
Ibraheem Altamimi, Abdullah Alhumimidi, Salem Alshehri, Abdullah Alrumayan, Thamir Al-khlaiwi, Sultan A. Meo, and Mohamad-Hani Temsah. The scientific knowledge of three large lan- guage models in cardiology: multiple-choice ques- tions examination-based performance.Annals of Medicine and Surgery, 86(6):3261–3266, June 2024
work page 2024
-
[38]
P. C. Lee, S. K. Sharma, S. Motaganahalli, and A. Huang. Evaluating the clinical decision-making ability of large language models using mksap-19 car- diology questions.JACC: Advances, 2(9), 2023
work page 2023
-
[39]
Nola, Nikola Pavlovi´ c, andˇSime Manola
Andrej Novak, Ivan Zeljkovi´ c, Fran Rode, Ante Lisiˇ ci´ c, Iskra A. Nola, Nikola Pavlovi´ c, andˇSime Manola. The pulse of artificial intelligence in cardi- ology: A comprehensive evaluation of state-of-the- art large language models for potential use in clin- ical cardiology.medRxiv, Dec 2024. Preprint, not peer-reviewed
work page 2024
-
[40]
R. E. Harskamp and L. De Clercq. Performance of chatgpt as an ai-assisted decision support tool in medicine: a proof-of-concept study for interpret- ing symptoms and management of common car- diac conditions (amstelheart-2).Acta Cardiologica, 79(3):358–366, May 2024. Epub 2024 Feb 13
work page 2024
-
[41]
Ashish Sarraju, Dennis Bruemmer, Erik Van Iter- son, Leslie Cho, Fatima Rodriguez, and Luke Laffin. Appropriateness of cardiovascular disease preven- tion recommendations obtained from a popular on- line chat-based artificial intelligence model.JAMA, 329(10):842–844, Feb 2023
work page 2023
-
[42]
F. Dimitriadis, S. Alkagiet, L. Tsigkriki, P. Kleit- sioti, G. Sidiropoulos, D. Efstratiou, T. Askalidi, A. Tsaousidis, M. Siarkos, P. Giannakopoulou, A. D. Mavrogianni, J. Zarifis, and G. Koulaouzidis. Chatgpt and patients with heart failure.Angiology, Mar 2024. Epub ahead of print. 15
work page 2024
-
[43]
C. W. Riddell, C. Chan, H. McGrinder, N. J. Earle, K. K. Poppe, and R. N. Doughty. College-level read- ing is required to understand chatgpts answers to lay questions relating to heart failure.European Journal of Heart Failure, 25(12), 2023
work page 2023
- [44]
-
[45]
CardioBERTpt: Transformer-based models for cardiology language representation in portuguese
Elisa Terumi Rubel Schneider, Yohan Bonescki Gumiel, Jo˜ ao Vitor Andrioli de Souza, Lilian Mie Mukai, Lucas Emanuel Silva e Oliveira, Ma- rina de S´ a Rebelo, Marco Antonio Gutierrez, Jos´ e Eduardo Krieger, Douglas Teodoro, Cl´ audia Moro, and Emerson Cabrera Paraiso. CardioBERTpt: Transformer-based models for cardiology language representation in portu...
work page 2023
-
[46]
Pritam Mukherjee, Benjamin Hou, Ricardo B. Lan- fredi, and Ronald M. Summers. Feasibility of using the privacy-preserving large language model vicuna for labeling radiology reports.Radiology, 309, 10 2023
work page 2023
-
[47]
Xingyao Zhang, Cao Xiao, Lucas M. Glass, and Ji- meng Sun. Deepenroll: Patient-trial matching with deep embedding and entailment prediction. InPro- ceedings of The Web Conference 2020, pages 1029– 1037, 2020
work page 2020
-
[48]
Hugging face – the ai community building the fu- ture.https://huggingface.co/, 2026. Accessed: 2026-02-16
work page 2026
-
[49]
Hugging Face. Guidance — text generation infer- ence documentation.https://huggingface.co/ docs/text-generation-inference/conceptual/ guidance, 2026. Accessed: 2026-02-10
work page 2026
-
[50]
Luca Beurer-Kellner, Marc Fischer, and Martin Vechev. Guiding llms the right way: fast, non- invasive constrained generation. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024. Figure 8: Distribution of the CAG procedures from Hos- pital de Santa Maria per year. Original Zero-Shot Prompt ´Es um especialista em...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.