3DRealHead: Few-Shot Detailed Head Avatar
Pith reviewed 2026-05-10 15:15 UTC · model grok-4.3
The pith
Mouth features from driving video let few-shot 3D head avatars capture expressions beyond 3DMM limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
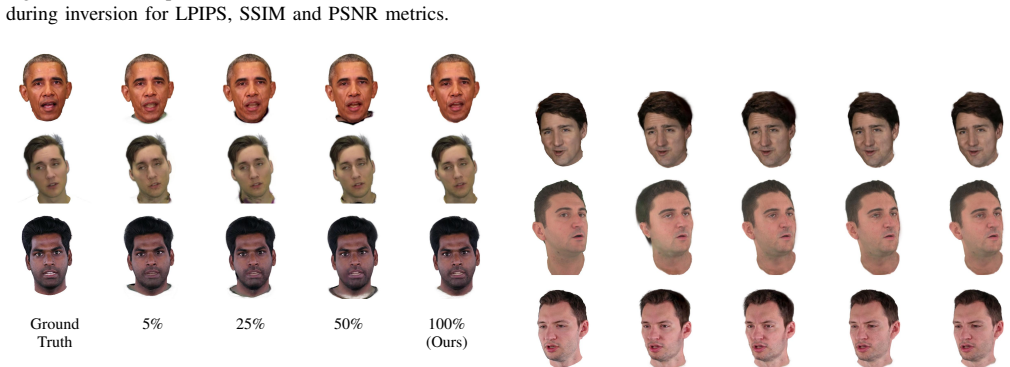
3DRealHead reconstructs 3D head avatars via few-shot inversion of a Style U-Net prior that emits 3D Gaussian primitives. Animation conditions the U-Net on 3DMM expression signals augmented by mouth-region features extracted from the driving video, enabling recovery of facial expressions that cannot be represented by the 3DMM alone and producing closer resemblance to physical reality.
What carries the argument
Style U-Net that emits 3D Gaussian primitives, conditioned on 3DMM-based facial expression signals plus mouth region features extracted from monocular driving video.
If this is right
- A small set of subject photographs suffices to create a renderable 3D head avatar.
- The avatar can be driven by ordinary consumer webcam video.
- Facial expressions gain expressivity through mouth-specific signals not captured by 3DMM.
- Novel-view rendering remains possible through the emitted 3D Gaussian primitives.
- The learned prior supports inversion for new identities without full retraining.
Where Pith is reading between the lines
- The same mouth-augmented conditioning could be added to other 3DMM-based avatar pipelines to raise fidelity.
- Region-specific video features might extend the approach to hands or full-body avatars.
- Gaussian primitive output supports efficient rendering that could suit real-time virtual-reality use.
Load-bearing premise
The head prior learned on the NeRSemble dataset generalizes to unseen subjects for accurate few-shot inversion and the added mouth features integrate without artifacts or identity drift.
What would settle it
Observe whether an unseen subject avatar fails to reproduce a mouth expression visible in the driving video yet absent from 3DMM parameters, or whether mouth features produce visible identity mismatch or rendering artifacts.
Figures














read the original abstract
The human face is central to communication. For immersive applications, the digital presence of a person should mirror the physical reality, capturing the users idiosyncrasies and detailed facial expressions. However, current 3D head avatar methods often struggle to faithfully reproduce the identity and facial expressions, despite having multi-view data or learned priors. Learning priors that capture the diversity of human appearances, especially, for regions with highly person-specific features, like the mouth and teeth region is challenging as the underlying training data is limited. In addition, many of the avatar methods are purely relying on 3D morphable model-based expression control which strongly limits expressivity. To address these challenges, we are introducing 3DRealHead, a few-shot head avatar reconstruction method with a novel expression control signal that is extracted from a monocular video stream of the subject. Specifically, the subject can take a few pictures of themselves, recover a 3D head avatar and drive it with a consumer-level webcam. The avatar reconstruction is enabled via a novel few-shot inversion process of a 3D human head prior which is represented as a Style U-Net that emits 3D Gaussian primitives which can be rendered under novel views. The prior is learned on the NeRSemble dataset. For animating the avatar, the U-Net is conditioned on 3DMM-based facial expression signals, as well as features of the mouth region extracted from the driving video. These additional mouth features allow us to recover facial expressions that cannot be represented by the 3DMM leading to a higher expressivity and closer resemblance to the physical reality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 3DRealHead, a few-shot head avatar reconstruction method. A Style U-Net prior is learned on the NeRSemble dataset to emit 3D Gaussian primitives for novel-view rendering. Reconstruction proceeds via few-shot inversion from a small set of user images. Animation conditions the U-Net on 3DMM expression parameters together with mouth-region features extracted from monocular driving video, with the claim that the added mouth conditioning recovers expressions outside the 3DMM span and yields higher fidelity to physical reality.
Significance. If the central claims on generalization and expressivity are substantiated by quantitative evidence, the work would provide a practical route to consumer-level, high-fidelity head avatars that better capture idiosyncratic mouth and expression details than pure 3DMM pipelines. The 3D-Gaussian representation and learned prior could also support efficient rendering in immersive applications.
major comments (2)
- [Abstract] Abstract: the central claim that mouth-region features enable recovery of expressions outside the 3DMM span is presented without any quantitative metric, ablation isolating the mouth conditioning, or comparison against a 3DMM-only baseline; this evidence is required to support the expressivity improvement.
- [Method] Method section (few-shot inversion description): the assumption that the NeRSemble-trained Style U-Net prior inverts accurately for arbitrary unseen identities from a handful of images is load-bearing for the reconstruction pipeline, yet no cross-subject or cross-dataset reconstruction errors, identity metrics, or failure-case analysis are reported.
minor comments (1)
- [Method] The notation for the combined conditioning signal (3DMM parameters plus mouth features) inside the Style U-Net could be made more explicit to clarify how the two signals are fused without identity drift.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that mouth-region features enable recovery of expressions outside the 3DMM span is presented without any quantitative metric, ablation isolating the mouth conditioning, or comparison against a 3DMM-only baseline; this evidence is required to support the expressivity improvement.
Authors: We agree that the abstract's claim would benefit from explicit quantitative backing. The manuscript already includes qualitative demonstrations of improved mouth and expression fidelity via side-by-side renderings and driving-video comparisons. To directly address the concern, we will add a dedicated ablation subsection that isolates the mouth-feature conditioning, reports quantitative metrics (e.g., mouth-region landmark error and perceptual similarity scores), and compares against a 3DMM-only baseline on a held-out test set. These results will be summarized in the abstract and discussed in the experiments section. revision: yes
-
Referee: [Method] Method section (few-shot inversion description): the assumption that the NeRSemble-trained Style U-Net prior inverts accurately for arbitrary unseen identities from a handful of images is load-bearing for the reconstruction pipeline, yet no cross-subject or cross-dataset reconstruction errors, identity metrics, or failure-case analysis are reported.
Authors: The few-shot inversion is supported by visual results and user studies on diverse real-world subjects in the current experiments. We acknowledge that additional quantitative validation would increase confidence in generalization. We will therefore report cross-subject identity preservation metrics (e.g., cosine similarity of ArcFace embeddings) and reconstruction error statistics on held-out NeRSemble identities. A short failure-case analysis covering challenging conditions (extreme lighting, accessories) will also be added. Cross-dataset evaluation is limited by the availability of comparable multi-view head datasets; we will clarify the scope of generalization accordingly rather than claim broader transfer. revision: partial
Circularity Check
No circularity: method relies on learned priors and external conditioning without self-referential reduction
full rationale
The paper describes a Style U-Net prior trained on the external NeRSemble dataset, followed by few-shot inversion and conditioning on 3DMM parameters plus independently extracted mouth features from driving video. No equations, fitted parameters, or self-citations are presented that reduce the claimed expressivity gain to a tautological reparameterization or input fit. The derivation chain consists of standard neural rendering components and dataset-driven learning, remaining self-contained against external benchmarks without any load-bearing step that collapses by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A Style U-Net trained on NeRSemble can be inverted from a few images to produce view-consistent 3D Gaussian primitives for novel subjects.
- domain assumption Mouth-region features extracted from driving video are complementary to 3DMM expression parameters and can be fused without introducing inconsistencies.
invented entities (1)
-
Style U-Net emitting 3D Gaussian primitives
no independent evidence
Reference graph
Works this paper leans on
-
[1]
S. An, H. Xu, Y . Shi, G. Song, U. Ogras, and L. Luo. Panohead: Geometry-aware 3d full-head synthesis in 360 ◦, 2023
work page 2023
-
[2]
V . Blanz and T. Vetter. A morphable model for the synthesis of 3d faces. InProceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH ’99, page 187–194, USA, 1999. ACM Press/Addison-Wesley Publishing Co
work page 1999
-
[3]
M. C. Buehler, G. Li, E. Wood, L. Helminger, X. Chen, T. Shah, D. Wang, S. Garbin, S. Orts-Escolano, O. Hilliges, D. Lagun, J. Riviere, P. Gotardo, T. Beeler, A. Meka, and K. Sarkar. Cafca: High-quality novel view synthesis of expressive faces from casual few-shot captures. InACM SIGGRAPH Asia 2024 Conference Paper. 2024
work page 2024
-
[4]
M. C. B ¨uhler, K. Sarkar, T. Shah, G. Li, D. Wang, L. Helminger, S. Orts-Escolano, D. Lagun, O. Hilliges, T. Beeler, et al. Preface: A data-driven volumetric prior for few-shot ultra high-resolution face synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 3402–3413, 2023
work page 2023
- [5]
-
[6]
E. Chan, C. Lin, M. Chan, K. Nagano, B. Pan, S. Mello, O. Gallo, L. Guibas, J. Tremblay, S. Khamis, T. Karras, and G. Wetzstein. Efficient geometry-aware 3d generative adversarial networks. pages 16102–16112, 06 2022
work page 2022
-
[7]
X. Chen, M. Mihajlovic, S. Wang, S. Prokudin, and S. Tang. Morphable diffusion: 3d-consistent diffusion for single-image avatar creation. 2024
work page 2024
-
[8]
Y . Chen, L. Wang, Q. Li, H. Xiao, S. Zhang, H. Yao, and Y . Liu. Monogaussianavatar: Monocular gaussian point-based head avatar.ACM SIGGRAPH 2024 Conference Papers, 2023
work page 2024
- [9]
-
[10]
X. Chu, Y . Li, A. Zeng, T. Yang, L. Lin, Y . Liu, and T. Harada. Gpavatar: Generalizable and precise head avatar from image(s), 2024
work page 2024
-
[11]
N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. InProceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05) - V olume 1 - V olume 01, CVPR ’05, page 886–893, USA, 2005. IEEE Computer Society
work page 2005
-
[12]
Y . Deng, D. Wang, X. Ren, X. Chen, and B. Wang. Portrait4d: Learning one-shot 4d head avatar synthesis using synthetic data, 2024
work page 2024
- [13]
- [14]
-
[15]
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio. Generative adversarial networks, 2014
work page 2014
-
[16]
Y . He, X. Gu, X. Ye, C. Xu, Z. Zhao, Y . Dong, W. Yuan, Z. Dong, and L. Bo. Lam: Large avatar model for one-shot animatable gaussian head, 2025
work page 2025
-
[17]
A. Jacobson and Y . Gingold. Skinning: real-time shape deformation. InSIGGRAPH Asia 2014 Courses, SA ’14, New York, NY , USA, 2014. Association for Computing Machinery. 9
work page 2014
-
[18]
J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution, 2016
work page 2016
-
[19]
B. Kabadayi, W. Zielonka, B. L. Bhatnagar, G. Pons-Moll, and J. Thies. Gan-avatar: Controllable personalized gan-based human head avatar. InInternational Conference on 3D Vision (3DV), March 2024
work page 2024
- [20]
-
[21]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization.CoRR, abs/1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[22]
T. Kirschstein, S. Giebenhain, and M. Nießner. Diffusiona- vatars: Deferred diffusion for high-fidelity 3d head avatars. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5481–5492, 2024
work page 2024
-
[23]
T. Kirschstein, S. Giebenhain, J. Tang, M. Georgopoulos, and M. Nießner. GGHead: Fast and Generalizable 3D Gaussian Heads. InSIGGRAPH Asia 2024 Conference Papers, SA ’24, New York, NY , USA, 2024. Association for Computing Machinery
work page 2024
-
[24]
T. Kirschstein, S. Qian, S. Giebenhain, T. Walter, and M. Nießner. Nersemble: Multi-view radiance field reconstruc- tion of human heads.ACM Trans. Graph., 42(4), jul 2023
work page 2023
-
[25]
T. Kirschstein, J. Romero, A. Sevastopolsky, M. Nießner, and S. Saito. Avat3r: Large animatable gaussian reconstruction model for high-fidelity 3d head avatars. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 12089–12100, October 2025
work page 2025
-
[26]
Y . Lan, F. Tan, D. Qiu, Q. Xu, K. Genova, Z. Huang, S. Fanello, R. Pandey, T. Funkhouser, C. C. Loy, and Y . Zhang. Gaussian3diff: 3d gaussian diffusion for 3d full head synthesis and editing. InECCV, 2024
work page 2024
-
[27]
T. Li, T. Bolkart, M. J. Black, H. Li, and J. Romero. Learning a model of facial shape and expression from 4D scans. ACM Transactions on Graphics, (Proc. SIGGRAPH Asia), 36(6):194:1–194:17, 2017
work page 2017
-
[28]
S. Lombardi, J. Saragih, T. Simon, and Y . Sheikh. Deep appearance models for face rendering.ACM Trans. Graph., 37(4):68:1–68:13, July 2018
work page 2018
-
[29]
S. Lombardi, T. Simon, G. Schwartz, M. Zollhoefer, Y . Sheikh, and J. Saragih. Mixture of volumetric primitives for efficient neural rendering.ACM Trans. Graph., 40(4), jul 2021
work page 2021
-
[30]
J. Martinez, E. Kim, J. Romero, T. Bagautdinov, S. Saito, S.-I. Yu, S. Anderson, M. Zollh¨ofer, T.-L. Wang, S. Bai, C. Li, S.-E. Wei, R. Joshi, W. Borsos, T. Simon, J. Saragih, P. Theodosis, A. Greene, A. Josyula, S. M. Maeta, A. I. Jewett, S. Venshtain, C. Heilman, Y .-T. Chen, S. Fu, M. E. A. Elshaer, T. Du, L. Wu, S.-C. Chen, K. Kang, M. Wu, Y . Emad, ...
work page 2024
-
[31]
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. InECCV, 2020
work page 2020
-
[32]
T. M ¨uller, A. Evans, C. Schied, and A. Keller. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph., 41(4):102:1–102:15, July 2022
work page 2022
-
[33]
S. Qian. Vhap: Versatile head alignment with adaptive appearance priors, sep 2024
work page 2024
-
[34]
S. Qian, T. Kirschstein, L. Schoneveld, D. Davoli, S. Gieben- hain, and M. Nießner. Gaussianavatars: Photorealistic head avatars with rigged 3d gaussians. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20299–20309, 2024
work page 2024
-
[35]
G. Retsinas, P. P. Filntisis, R. Danecek, V . F. Abrevaya, A. Roussos, T. Bolkart, and P. Maragos. 3d facial expres- sions through analysis-by-neural-synthesis. InConference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[36]
A. R ¨ossler, D. Cozzolino, L. Verdoliva, C. Riess, J. Thies, and M. Nießner. Faceforensics: A large-scale video dataset for forgery detection in human faces.arXiv, 2018
work page 2018
-
[37]
A. R ¨ossler, D. Cozzolino, L. Verdoliva, C. Riess, J. Thies, and M. Nießner. Faceforensics++: Learning to detect manipulated facial images. InICCV 2019, 2019
work page 2019
- [38]
-
[39]
doi:10.48550/arXiv.2301.09515 , urldate =
A. Sauer, T. Karras, S. Laine, A. Geiger, and T. Aila. StyleGAN-T: Unlocking the power of GANs for fast large- scale text-to-image synthesis. volume abs/2301.09515, 2023
-
[40]
Z. Shao, Z. Wang, Z. Li, D. Wang, X. Lin, Y . Zhang, M. Fan, and Z. Wang. SplattingAvatar: Realistic Real-Time Human Avatars with Mesh-Embedded Gaussian Splatting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[41]
I. Sobel and G. M. Feldman. An isotropic 3×3 image gradient operator. 1990
work page 1990
-
[42]
J. Sun, X. Wang, L. Wang, X. Li, Y . Zhang, H. Zhang, and Y . Liu. Next3d: Generative neural texture rasterization for 3d-aware head avatars. InCVPR, 2023
work page 2023
- [43]
- [44]
- [45]
-
[46]
L. Wang, X. Zhao, J. Sun, Y . Zhang, H. Zhang, T. Yu, and Y . Liu. Styleavatar: Real-time photo-realistic portrait avatar from a single video. InACM SIGGRAPH 2023 Conference Proceedings, 2023
work page 2023
-
[47]
T. Wang, B. Zhang, T. Zhang, S. Gu, J. Bao, T. Baltrusaitis, J. Shen, D. Chen, F. Wen, Q. Chen, and B. Guo. Rodin: A generative model for sculpting 3d digital avatars using diffusion. pages 4563–4573, 06 2023
work page 2023
-
[48]
Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli. Image quality assessment: From error visibility to structural similar- 10 ity.Image Processing, IEEE Transactions on, 13:600 – 612, 05 2004
work page 2004
-
[49]
C.-h. Wuu, N. Zheng, S. Ardisson, R. Bali, D. Belko, E. Brockmeyer, L. Evans, T. Godisart, H. Ha, X. Huang, A. Hypes, T. Koska, S. Krenn, S. Lombardi, X. Luo, K. McPhail, L. Millerschoen, M. Perdoch, M. Pitts, A. Richard, J. Saragih, J. Saragih, T. Shiratori, T. Simon, M. Stewart, A. Trimble, X. Weng, D. Whitewolf, C. Wu, S.- I. Yu, and Y . Sheikh. Multif...
work page 2022
- [50]
-
[51]
L. Xie, X. Wang, H. Zhang, C. Dong, and Y . Shan. Vfhq: A high-quality dataset and benchmark for video face super- resolution. InThe IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2022
work page 2022
-
[52]
Y . Xu, B. Chen, Z. Li, H. Zhang, L. Wang, Z. Zheng, and Y . Liu. Gaussian head avatar: Ultra high-fidelity head avatar via dynamic gaussians. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[53]
Y . Xu, H. Zhang, L. Wang, X. Zhao, H. Huang, G. Qi, and Y . Liu. Latentavatar: Learning latent expression code for expressive neural head avatar. InACM SIGGRAPH 2023 Conference Proceedings, SIGGRAPH ’23, New York, NY , USA, 2023. Association for Computing Machinery
work page 2023
-
[54]
Z. Yu, Z. Bai, A. Meka, F. Tan, Q. Xu, R. Pandey, S. Fanello, H. S. Park, and Y . Zhang. One2avatar: Generative implicit head avatar for few-shot user adaptation, 2024
work page 2024
- [55]
-
[56]
X. Zhao, J. Sun, L. Wang, J. Suo, and Y . Liu. Invertavatar: In- cremental gan inversion for generalized head avatars. InACM SIGGRAPH 2024 Conference Papers, SIGGRAPH ’24, New York, NY , USA, 2024. Association for Computing Machinery
work page 2024
- [57]
-
[58]
W. Zielonka, T. Bagautdinov, S. Saito, M. Zollh ¨ofer, J. Thies, and J. Romero. Drivable 3d gaussian avatars. InI3DV, March 2025
work page 2025
-
[59]
W. Zielonka, T. Bolkart, T. Beeler, and J. Thies. Gaussian eigen models for human heads. InCVPR, June 2025
work page 2025
-
[60]
W. Zielonka, T. Bolkart, and J. Thies. Instant volumetric head avatars. InCVPR, pages 4574–4584, 2023
work page 2023
-
[61]
W. Zielonka, S. J. Garbin, A. Lattas, G. Kopanas, P. Gotardo, T. Beeler, J. Thies, and T. Bolkart. Synthetic prior for few-shot drivable head avatar inversion. InCVPR, June 2025. 11 3DRealHead: Few-Shot Detailed Head Avatar Supplemental Document A. ARCHITECTUREDETAILS Our model employs a Style U-Net [46] with two iden- tical encoders and a common decoder....
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.