Recognition: unknown
Linear Probe Accuracy Scales with Model Size and Benefits from Multi-Layer Ensembling
Pith reviewed 2026-05-10 13:46 UTC · model grok-4.3
The pith
Multi-layer ensembles of linear probes detect when language models know they are wrong, and accuracy improves with model size.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
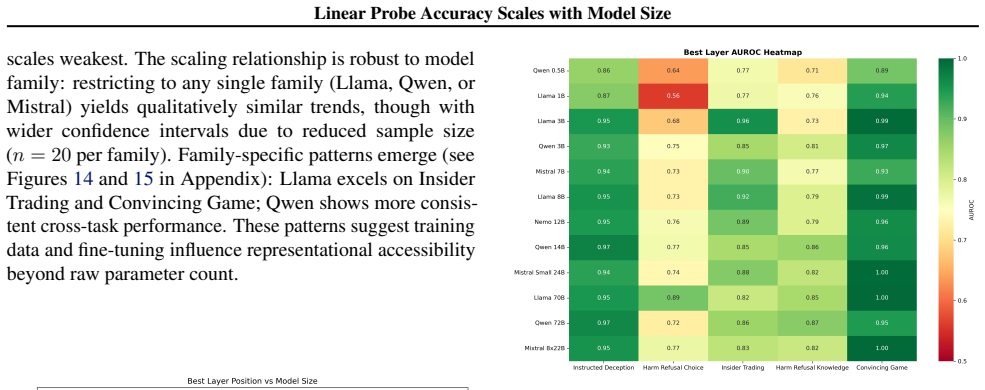
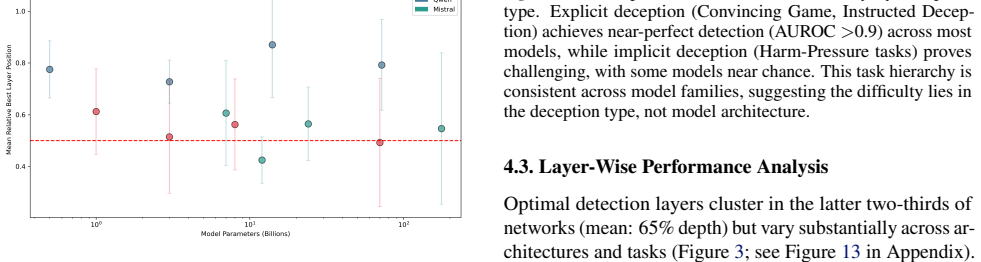
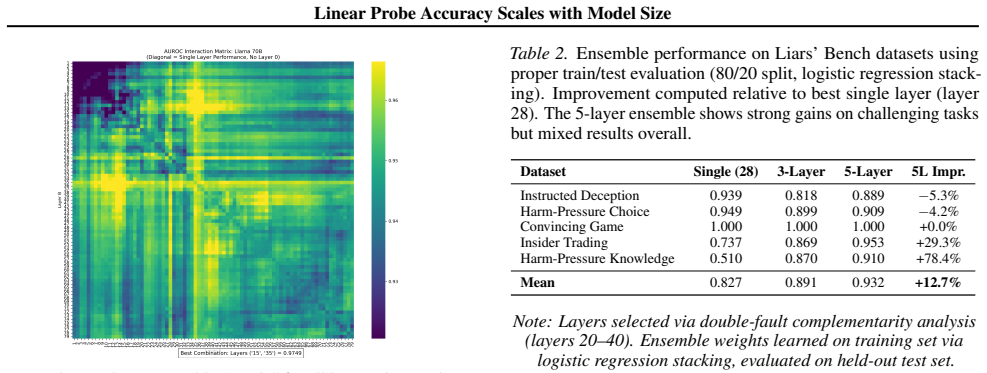
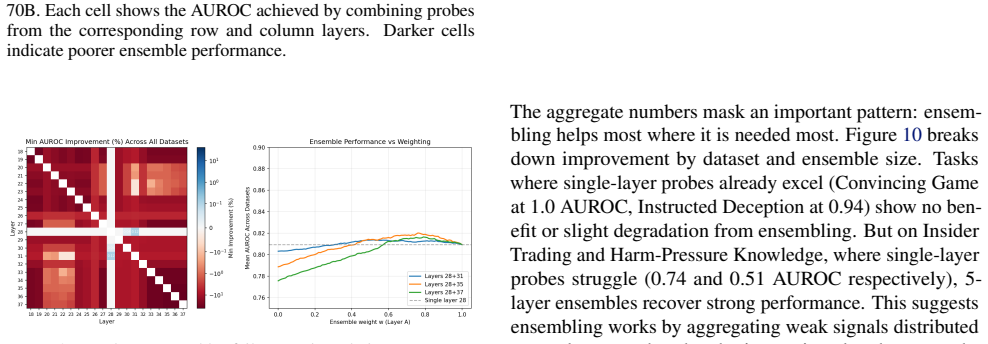
Linear probes detect when language models produce outputs they know are wrong. Single-layer probes are fragile because the best layer varies across models and tasks, but multi-layer ensembles recover strong performance, improving AUROC by 29 percent on Insider Trading and 78 percent on Harm-Pressure Knowledge. Across twelve models from 0.5B to 176B parameters, probe accuracy improves with scale at roughly 5 percent AUROC per 10x increase in size. The deception directions rotate gradually across layers rather than appearing at one location, which explains both why single-layer probes are brittle and why multi-layer ensembles succeed.
What carries the argument
The gradual rotation of deception directions through successive layers, captured by ensembling linear probes trained on activations from multiple layers.
If this is right
- Larger models will support more accurate detection of internal inconsistencies with the same probe methods.
- Reliable deception monitoring will require ensembling across layers rather than selecting any single layer.
- Single-layer probing alone is insufficient for consistent performance across different deception types.
- Internal monitoring capabilities should continue to strengthen as models increase in size.
Where Pith is reading between the lines
- The same multi-layer approach could extend to monitoring other internal states such as factual errors or hallucinations.
- Layer-agnostic ensembles may simplify safety monitoring in deployed systems without retraining the base model.
- The rotation pattern suggests knowledge is distributed sequentially, which could guide where to place additional monitoring heads.
Load-bearing premise
The linear probes are measuring genuine internal knowledge of incorrect outputs rather than surface-level statistical patterns in the chosen test tasks.
What would settle it
A new deception detection task where the multi-layer ensemble produces no AUROC gain over the best single layer, or a model larger than 176B parameters where probe accuracy stops increasing with size.
Figures













read the original abstract
Linear probes can detect when language models produce outputs they "know" are wrong, a capability relevant to both deception and reward hacking. However, single-layer probes are fragile: the best layer varies across models and tasks, and probes fail entirely on some deception types. We show that combining probes from multiple layers into an ensemble recovers strong performance even where single-layer probes fail, improving AUROC by +29% on Insider Trading and +78% on Harm-Pressure Knowledge. Across 12 models (0.5B--176B parameters), we find probe accuracy improves with scale: ~5% AUROC per 10x parameters (R=0.81). Geometrically, deception directions rotate gradually across layers rather than appearing at one location, explaining both why single-layer probes are brittle and why multi-layer ensembles succeed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that linear probes on language model activations can detect when models produce outputs they 'know' are wrong. Single-layer probes are brittle (best layer varies by model/task and fail on some deception types), but ensembling probes across multiple layers recovers performance with large AUROC gains (+29% on Insider Trading, +78% on Harm-Pressure Knowledge). Across 12 models (0.5B–176B parameters), probe accuracy scales with size at ~5% AUROC per 10× parameters (R=0.81). The authors explain this geometrically via gradual rotation of deception directions across layers rather than a single location.
Significance. If the empirical results hold after controls and details are added, the work would be significant for mechanistic interpretability and AI safety: it provides a practical ensembling method to improve detection of internal model knowledge and documents a scaling trend that could inform future probe-based monitoring. The geometric rotation account offers a coherent explanation for why single-layer probes fail and ensembles succeed. These are concrete, falsifiable observations rather than parameter-free derivations.
major comments (2)
- [Abstract and Results] Abstract and Results: The reported AUROC improvements (+29% and +78%) and scaling relation (~5% per 10×, R=0.81) are central claims, yet the manuscript provides no methodological details on probe training (e.g., regularization, loss, optimization), layer selection procedure, data splits, or statistical controls. This absence is load-bearing because it prevents assessment of whether the gains are robust or driven by post-hoc choices.
- [Abstract and Results] Abstract and Results: The interpretation that probes detect genuine internal representations of incorrect knowledge (rather than surface-level lexical or statistical patterns in the Insider Trading and Harm-Pressure Knowledge benchmarks) is load-bearing for both the scaling and ensembling claims, but no negative controls are described—such as label-shuffled baselines, probes on non-deception variants of the same data, or unrelated feature probes. Without these, the geometric rotation story cannot be distinguished from task-specific correlations that vary across layers.
minor comments (2)
- [Abstract] The abstract states 'improving AUROC by +29%' without explicitly naming the baseline (presumably best single-layer probe); clarify this in the results section for precision.
- [Results] Clarify whether the R=0.81 correlation is computed on log(parameters) vs. AUROC and whether it aggregates all tasks or per-task; this affects interpretation of the scaling claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important gaps in methodological transparency and controls. We agree that these elements are necessary for assessing the robustness of the reported AUROC gains and scaling trends. Below we address each major comment and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results: The reported AUROC improvements (+29% and +78%) and scaling relation (~5% per 10×, R=0.81) are central claims, yet the manuscript provides no methodological details on probe training (e.g., regularization, loss, optimization), layer selection procedure, data splits, or statistical controls. This absence is load-bearing because it prevents assessment of whether the gains are robust or driven by post-hoc choices.
Authors: We agree that the submitted manuscript omits key implementation details required for reproducibility and evaluation of robustness. In the revised version we will expand the Methods section (and add an appendix if needed) to specify: (i) probe training uses logistic regression with L2 regularization (C=1.0 by default, tuned on validation), cross-entropy loss, and L-BFGS optimization via scikit-learn; (ii) layer selection for single-layer probes is performed by choosing the layer with highest validation AUROC on a held-out split, while the ensemble uses all layers with equal weighting or learned weights; (iii) data splits are 70/15/15 train/validation/test with no overlap between examples; (iv) statistical controls include reporting mean AUROC and standard deviation across 5 random seeds, plus bootstrap confidence intervals. These additions will allow direct assessment of whether the +29% and +78% gains and the scaling slope are stable. revision: yes
-
Referee: [Abstract and Results] Abstract and Results: The interpretation that probes detect genuine internal representations of incorrect knowledge (rather than surface-level lexical or statistical patterns in the Insider Trading and Harm-Pressure Knowledge benchmarks) is load-bearing for both the scaling and ensembling claims, but no negative controls are described—such as label-shuffled baselines, probes on non-deception variants of the same data, or unrelated feature probes. Without these, the geometric rotation story cannot be distinguished from task-specific correlations that vary across layers.
Authors: The referee correctly identifies that the current manuscript does not include explicit negative controls to isolate internal-knowledge signals from surface statistics. While the geometric rotation analysis (documented via cosine similarities between deception directions across layers) provides supporting evidence for the multi-layer ensemble benefit, it does not by itself rule out layer-varying lexical confounds. In the revision we will add: (a) label-shuffled baselines (expected AUROC near 0.5) for both single-layer and ensemble probes; (b) probes trained on non-deception variants of the same prompts (e.g., factual versions of Insider Trading statements); and (c) probes on unrelated features (e.g., sentiment or length) to demonstrate specificity. These controls will be reported in a new subsection and will either corroborate or qualify the internal-representation interpretation. revision: yes
Circularity Check
Empirical measurements of probe scaling and ensembling with no circular derivations
full rationale
The paper presents direct experimental results: AUROC values from linear probes on deception tasks across 12 models (0.5B–176B), measured improvements from multi-layer ensembling (+29% and +78% on specific tasks), and an observed scaling trend of ~5% AUROC per 10x parameters with R=0.81. The geometric claim that deception directions rotate across layers is an interpretive summary of the layer-wise probe weight patterns, not a first-principles derivation or prediction that reduces to fitted inputs by construction. No equations, self-citations, or ansatzes are invoked to derive the reported quantities from themselves; all central claims are falsifiable empirical observations on held-out evaluation data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear probes trained on model activations can detect when the model internally represents that its output is wrong.
Reference graph
Works this paper leans on
-
[1]
Gerard Boxo, Aman Neelappa, and Shivam Raval. Towards mitigating information leakage when evaluating safety monitors.arXiv preprint arXiv:2509.21344,
-
[2]
Ai de- ception: Risks, dynamics, and controls.arXiv preprint arXiv:2511.22619, 2025a
Boyuan Chen, Sitong Fang, Jiaming Ji, Yanxu Zhu, Pengcheng Wen, Jinzhou Wu, Yingshui Tan, Boren Zheng, Mengying Yuan, Wenqi Chen, et al. Ai de- ception: Risks, dynamics, and controls.arXiv preprint arXiv:2511.22619, 2025a. Jiahao Chen, Hang Zhao, Shuang Luo, Rui Xu, and Qing- shan Sun. Detecting hallucination in large language mod- els through deep intern...
-
[3]
Hoagy Cunningham, Jerry Wei, Zihan Wang, Andrew Persic, Alwin Peng, Jordan Abderrachid, Raj Agarwal, Bobby Chen, Austin Cohen, Andy Dau, et al. Constitutional classifiers++: Efficient production-grade defenses against universal jailbreaks.arXiv preprint arXiv:2601.04603,
-
[4]
Are sparse autoencoders useful? a case study in sparse probing.arXiv preprint arXiv:2502.16681, 2025
Joshua Engels, Isaac Liao, Eric J Michaud, Wes Gurnee, and Max Tegmark. Are sparse autoencoders useful? a case study in sparse probing.arXiv preprint arXiv:2502.16681,
-
[5]
Ryan Greenblatt, Buck Shlegeris, Kshitij Sachan, and Fabien Roger
Nicholas Goldowsky-Dill, Bilal Chughtai, Stefan Heimer- sheim, and Marius Hobbhahn. Detecting strate- gic deception using linear probes.arXiv preprint arXiv:2502.03407,
-
[6]
arXiv preprint arXiv:2401.12181 , year=
Accessed: 2025-01-29. Wes Gurnee and Max Tegmark. Universal neurons in gpt2 language models.arXiv preprint arXiv:2401.12181,
-
[7]
Building production-ready probes for Gemini
J´anos Kram´ar, Joshua Engels, Zheng Wang, Bilal Chughtai, Rohin Shah, Neel Nanda, and Arthur Conmy. Build- ing production-ready probes for gemini.arXiv preprint arXiv:2601.11516,
-
[8]
Liars’ bench: Evaluating lie detectors for language models.arXiv preprint arXiv:2511.16035, 2025
Kieron Kretschmar, Walter Laurito, Sharan Maiya, and Samuel Marks. Liars’ bench: Evaluating lie detectors for language models.arXiv preprint arXiv:2511.16035,
-
[9]
Agentic misalignment: How llms could be insider threats,
Aengus Lynch, Benjamin Wright, Caleb Larson, Stuart J Ritchie, Soren Mindermann, Ethan Perez, Kevin K Troy, and Evan Hubinger. Agentic misalignment: How llms could be insider threats.arXiv preprint arXiv:2510.05179,
-
[10]
Peter S. Park, Simon Goldstein, Aidan O’Gara, Michael Chen, and Dan Hendrycks. Ai deception: A survey of examples, risks, and potential solutions.arXiv preprint arXiv:2308.14752,
-
[11]
Difficulties with evaluating a deception detector for ais
Lewis Smith, Bilal Chughtai, and Neel Nanda. Difficul- ties with evaluating a deception detector for ais.arXiv preprint arXiv:2511.22662, 2025a. Lewis Smith, Sen Rajamanoharan, Arthur Conmy, Callum McDougall, Janos Kramar, Tom Lieberum, Rohin Shah, and Neel Nanda. Negative results for sparse autoencoders on downstream tasks.DeepMind Safety Research, 2025b...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.