Recognition: unknown
FAST: A Synergistic Framework of Attention and State-space Models for Spatiotemporal Traffic Prediction
Pith reviewed 2026-05-10 14:16 UTC · model grok-4.3
The pith
FAST integrates attention for temporal patterns with Mamba state-space modeling for spatial dependencies to forecast traffic flows more accurately than pure approaches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
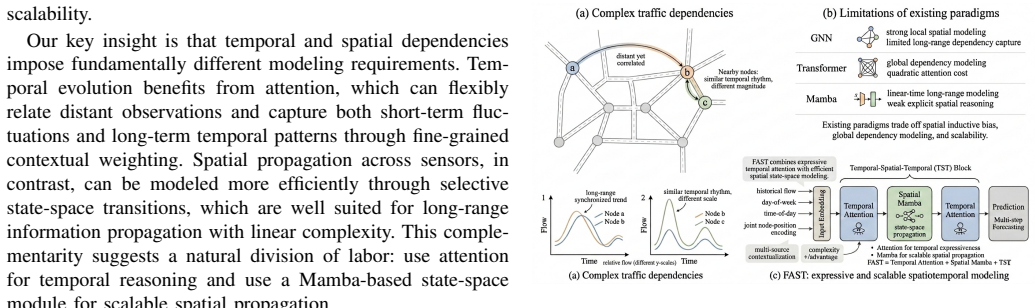
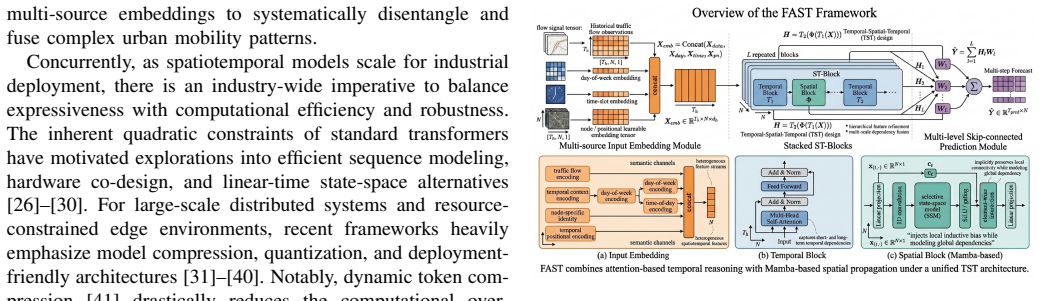
FAST claims that a Temporal-Spatial-Temporal architecture—temporal attention modules for short- and long-range time patterns, a Mamba-based spatial module for linear-complexity long-range sensor interactions, learnable multi-source spatiotemporal embeddings combining flow, temporal context and node information, and multi-level skip prediction for hierarchical fusion—produces lower MAE and RMSE than Transformer, GNN, attention-only, or Mamba-only baselines on the PeMS04, PeMS07, and PeMS08 benchmarks, with reductions up to 4.3 percent in RMSE and 2.8 percent in MAE.
What carries the argument
The Temporal-Spatial-Temporal architecture that places attention modules on either side of a Mamba spatial module, together with the learnable multi-source embedding layer and multi-level skip prediction.
If this is right
- Lower average and root-mean-square errors on standard traffic benchmarks while maintaining linear scaling for spatial components.
- Improved capture of heterogeneous contexts through the joint use of historical flow, temporal markers, and node attributes.
- Hierarchical feature reuse via multi-level skip connections that combines information at multiple resolutions.
- Practical deployment on large sensor graphs without quadratic attention costs for the spatial stage.
Where Pith is reading between the lines
- The same sequencing of attention and state-space blocks could be tested on other grid or graph-based forecasting tasks such as electricity load or weather variables.
- The multi-source embedding strategy might reduce the need for separate preprocessing pipelines when node metadata varies across datasets.
- If the linear spatial modeling proves robust, the framework offers a route to real-time updates on expanding sensor networks without retraining from scratch.
Load-bearing premise
The specific ordering of temporal attention around a spatial state-space module plus the multi-source embedding will deliver gains on traffic sensor data without being tuned exclusively to the patterns in the PeMS collections.
What would settle it
Evaluation of FAST on a different spatiotemporal dataset or a much larger sensor network where its MAE and RMSE no longer improve on the strongest baseline from the Transformer, GNN, attention, or Mamba families.
Figures

read the original abstract
Traffic forecasting requires modeling complex temporal dynamics and long-range spatial dependencies over large sensor networks. Existing methods typically face a trade-off between expressiveness and efficiency: Transformer-based models capture global dependencies well but suffer from quadratic complexity, while recent selective state-space models are computationally efficient yet less effective at modeling spatial interactions in graph-structured traffic data. We propose FAST, a unified framework that combines attention and state-space modeling for scalable spatiotemporal traffic forecasting. FAST adopts a Temporal-Spatial-Temporal architecture, where temporal attention modules capture both short- and long-term temporal patterns, and a Mamba-based spatial module models long-range inter-sensor dependencies with linear complexity. To better represent heterogeneous traffic contexts, FAST further introduces a learnable multi-source spatiotemporal embedding that integrates historical traffic flow, temporal context, and node-level information, together with a multi-level skip prediction mechanism for hierarchical feature fusion. Experiments on PeMS04, PeMS07, and PeMS08 show that FAST consistently outperforms strong baselines from Transformer-, GNN-, attention-, and Mamba-based families. In particular, FAST achieves the best MAE and RMSE on all three benchmarks, with up to 4.3\% lower RMSE and 2.8\% lower MAE than the strongest baseline, demonstrating a favorable balance between accuracy, scalability, and generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FAST, a hybrid framework for spatiotemporal traffic forecasting that integrates temporal attention modules with a Mamba-based state-space spatial module in a Temporal-Spatial-Temporal architecture. It introduces a learnable multi-source spatiotemporal embedding combining historical traffic flow, temporal context, and node information, along with a multi-level skip prediction mechanism for hierarchical fusion. The central claim is that this design achieves superior accuracy and scalability over Transformer-, GNN-, attention-, and Mamba-based baselines, with best MAE/RMSE on PeMS04, PeMS07, and PeMS08 and gains up to 4.3% RMSE / 2.8% MAE.
Significance. If the performance claims hold under rigorous validation, the work offers a practical hybrid approach that mitigates the quadratic cost of attention while improving spatial modeling over pure state-space methods for graph-structured data. Credit is due for the explicit comparison across multiple model families and for the multi-source embedding idea aimed at heterogeneous contexts. The favorable accuracy-scalability trade-off, if generalizable, would be a useful contribution to efficient spatiotemporal modeling.
major comments (3)
- [§4] §4 (Experiments): The reported gains lack supporting details on baseline re-implementations, hyperparameter search protocols, statistical significance (e.g., standard deviations over runs), or ablation studies isolating the Mamba spatial module, multi-source embedding, and skip prediction; without these, the central outperformance claim cannot be fully assessed.
- [§4.1] §4.1 (Datasets and Evaluation): All three benchmarks (PeMS04/07/08) share the same data source, sensor density, 5-minute sampling, and regional traffic patterns; the absence of results on METR-LA, PEMS-BAY, or non-traffic spatiotemporal tasks leaves the generalizability of the Temporal-Spatial-Temporal design and learnable embedding untested and risks dataset-specific artifacts.
- [§3.3] §3.3 (Multi-source Embedding): The integration of historical flow, temporal context, and node-level features into the learnable embedding is described at a high level but lacks an explicit equation or algorithmic specification (e.g., how fusion weights are learned or normalized), which is load-bearing for claims of improved heterogeneous context representation.
minor comments (2)
- [Abstract] Abstract: The phrase 'up to 4.3% lower RMSE' does not indicate the specific dataset or strongest baseline against which the maximum improvement occurs.
- [§3] Figure 1 or §3: A schematic of the overall Temporal-Spatial-Temporal flow and skip connections would improve clarity of the architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help improve the clarity and rigor of our work. We address each major comment point-by-point below, indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: §4 (Experiments): The reported gains lack supporting details on baseline re-implementations, hyperparameter search protocols, statistical significance (e.g., standard deviations over runs), or ablation studies isolating the Mamba spatial module, multi-source embedding, and skip prediction; without these, the central outperformance claim cannot be fully assessed.
Authors: We agree that these details are essential for fully substantiating the performance claims. In the revised manuscript, we will expand §4 to include: (i) explicit descriptions of baseline re-implementations (including code sources or re-implementation notes), (ii) the hyperparameter search protocol and ranges used for all models, (iii) mean and standard deviation results over multiple independent runs to demonstrate statistical significance, and (iv) dedicated ablation studies that isolate the contributions of the Mamba-based spatial module, the multi-source embedding, and the multi-level skip prediction mechanism. These additions will be presented in new tables and figures. revision: yes
-
Referee: §4.1 (Datasets and Evaluation): All three benchmarks (PeMS04/07/08) share the same data source, sensor density, 5-minute sampling, and regional traffic patterns; the absence of results on METR-LA, PEMS-BAY, or non-traffic spatiotemporal tasks leaves the generalizability of the Temporal-Spatial-Temporal design and learnable embedding untested and risks dataset-specific artifacts.
Authors: We acknowledge the limitation that all reported experiments use PeMS datasets, which, while standard in the traffic forecasting literature, share certain characteristics. PeMS04/07/08 do differ in sensor count, time spans, and traffic volumes, providing some diversity. To strengthen generalizability claims, we will add a discussion of these dataset variations and their implications for the Temporal-Spatial-Temporal design. We will also include results on METR-LA and PEMS-BAY if additional experiments can be completed within the revision timeline; otherwise, we will explicitly note this as a limitation and outline planned future evaluations on non-traffic spatiotemporal tasks to test broader applicability. revision: partial
-
Referee: §3.3 (Multi-source Embedding): The integration of historical flow, temporal context, and node-level features into the learnable embedding is described at a high level but lacks an explicit equation or algorithmic specification (e.g., how fusion weights are learned or normalized), which is load-bearing for claims of improved heterogeneous context representation.
Authors: We thank the referee for highlighting this gap. The multi-source embedding is a core component, and its description in §3.3 was indeed high-level. In the revised manuscript, we will add explicit mathematical formulations, including the equations for combining historical traffic flow, temporal context, and node-level features, the learnable fusion parameters, and the normalization procedure (e.g., via softmax or layer normalization). We will also include a pseudocode snippet or algorithmic description of the embedding computation to make the mechanism fully reproducible and to better support the claims regarding heterogeneous context representation. revision: yes
Circularity Check
No circularity: empirical claims rest on external baselines
full rationale
The paper proposes a Temporal-Spatial-Temporal architecture with attention, Mamba spatial modules, learnable multi-source embeddings, and multi-level skip prediction as design choices. Its central claims consist of empirical outperformance (MAE/RMSE) on PeMS04/07/08 versus independent Transformer/GNN/Mamba baselines. No equations, fitted parameters, or self-citations are shown reducing any result to the inputs by construction; the evaluation uses standard external benchmarks rather than internal definitions or self-referential predictions.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable multi-source spatiotemporal embedding
axioms (1)
- domain assumption Mamba-based models can effectively capture long-range spatial dependencies in graph-structured data with linear complexity.
invented entities (1)
-
multi-level skip prediction mechanism
no independent evidence
Forward citations
Cited by 1 Pith paper
-
LLM-Augmented Traffic Signal Control with LSTM-Based Traffic State Prediction and Safety-Constrained Decision Support
An LLM-augmented framework combining LSTM traffic prediction, structured LLM reasoning, and safety-constrained filtering improves simulated traffic efficiency under dynamic conditions with zero safety violations.
Reference graph
Works this paper leans on
-
[1]
Bayesian critique-tune-based reinforcement learning with adaptive pressure for multi-intersection traffic signal control,
W. Duan, Z. Gao, J. He, and J. Xian, “Bayesian critique-tune-based reinforcement learning with adaptive pressure for multi-intersection traffic signal control,”IEEE Transactions on Intelligent Transportation Systems, vol. 26, no. 10, pp. 14 968–14 983, 2025
2025
-
[2]
Spatiotemporal multi-view continual dictionary learning with graph diffusion,
S. Wu and J. Zhang, “Spatiotemporal multi-view continual dictionary learning with graph diffusion,”Knowledge-Based Systems, vol. 316, p. 113388, 2025
2025
-
[3]
Multi-resolution context augmentation and dual channel attention for 3d lane detection,
Q. Ning, J. Zhang, Y . Xie, K. Liu, K. Gao, B. Chen, G. Chen, Q. Fan, H. Liu, and R. Du, “Multi-resolution context augmentation and dual channel attention for 3d lane detection,”IEEE Internet of Things Journal, 2025
2025
-
[4]
Tur- boreg: Turboclique for robust and efficient point cloud registration,
S. Yan, P. Shi, Z. Zhao, K. Wang, K. Cao, J. Wu, and J. Li, “Tur- boreg: Turboclique for robust and efficient point cloud registration,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 26 371–26 381
2025
-
[5]
Spatiotemporal align- ment for remote sensing image recovery via terrain-aware diffusion,
Z. Yu, H. Jiang, P. Wang, Z. Lin, and Y . Xiang, “Spatiotemporal align- ment for remote sensing image recovery via terrain-aware diffusion,” ICASSP 2026, 2026
2026
-
[6]
Difflow3d: Toward robust uncertainty-aware scene flow estimation with iterative diffusion-based refinement,
J. Liu, G. Wang, W. Ye, C. Jiang, J. Han, Z. Liu, G. Zhang, D. Du, and H. Wang, “Difflow3d: Toward robust uncertainty-aware scene flow estimation with iterative diffusion-based refinement,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 15 109–15 119
2024
-
[7]
Dvlo: Deep visual-lidar odometry with local-to-global feature fusion and bi- directional structure alignment,
J. Liu, D. Zhuo, Z. Feng, S. Zhu, C. Peng, Z. Liu, and H. Wang, “Dvlo: Deep visual-lidar odometry with local-to-global feature fusion and bi- directional structure alignment,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 475–493
2024
-
[8]
Stg- avatar: Animatable human avatars via spacetime gaussian,
G. Jiang, T. Zhang, D. Li, Z. Zhao, H. Li, M. Li, and H. Wang, “Stg- avatar: Animatable human avatars via spacetime gaussian,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025, pp. 20 058–20 065
2025
-
[9]
J. Chan, Z. Zhao, and Y .-L. Liu, “Adagar: Adaptive gabor representation for dynamic scene reconstruction,”arXiv preprint arXiv:2601.00796, 2026
-
[10]
Learn from global correlations: Enhancing evolutionary algorithm via spectral gnn,
K. Ouyang, Z. Ke, S. Fu, L. Liu, P. Zhao, and D. Hu, “Learn from global correlations: Enhancing evolutionary algorithm via spectral gnn,” arXiv preprint arXiv:2412.17629, 2024
-
[11]
A stable technical feature with gru-cnn-ga fusion,
Z. Ke, J. Shen, X. Zhao, X. Fu, Y . Wang, Z. Li, L. Liu, and H. Mu, “A stable technical feature with gru-cnn-ga fusion,”Applied Soft Computing, p. 114302, 2025
2025
-
[12]
Research and practice of advertisement recommendation algorithm based on graph neural network,
K. Liu, S. Yang, and J. Xia, “Research and practice of advertisement recommendation algorithm based on graph neural network,” inProceed- ings of the 2nd International Symposium on Integrated Circuit Design and Integrated Systems, 2025, pp. 210–215
2025
-
[13]
Efficient cold-start recommendation via bpe token-level embedding initialization with llm,
Y . Zhao, X. Han, Q. o. Leng, Q. Sun, H. Lyu, and C. Zhou, “Efficient cold-start recommendation via bpe token-level embedding initialization with llm,” in2025 3rd International Conference on Artificial Intelligence and Automation Control (AIAC). IEEE, 2025, pp. 194–198
2025
-
[14]
Priordrive: Enhancing online hd mapping with unified vector priors,
S. Zeng, X. Chang, X. Liu, Y . Yuan, S. Liang, Z. Pan, M. Xu, and X. Wei, “Priordrive: Enhancing online hd mapping with unified vector priors,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 15, 2026, pp. 12 313–12 321
2026
-
[15]
MAGMA: A Multi-Graph based Agentic Memory Architecture for AI Agents
D. Jiang, Y . Li, G. Li, and B. Li, “Magma: A multi-graph based agentic memory architecture for ai agents,”arXiv preprint arXiv:2601.03236, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Decentralized graph-based multi-agent reinforcement learning using reward machines,
J. Hu, Z. Xu, W. Wang, G. Qu, Y . Pang, and Y . Liu, “Decentralized graph-based multi-agent reinforcement learning using reward machines,” Neurocomputing, vol. 564, p. 126974, 2024
2024
-
[17]
arXiv preprint , arXiv:2508.09241
F. Ji, J. Yang, Z. Song, Y . Wang, Z. Cui, Y . Li, Q. Jiang, M. Fang, and X. Chen, “Finestate-bench: A comprehensive benchmark for fine- grained state control in gui agents,”arXiv preprint arXiv:2508.09241, 2025
-
[18]
Intent: Invariance and discrimination-aware noise mitigation for robust composed image retrieval,
Z. Chen, Y . Hu, Z. Fu, Z. Li, J. Huang, Q. Huang, and Y . Wei, “Intent: Invariance and discrimination-aware noise mitigation for robust composed image retrieval,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 25, 2026, pp. 20 463–20 471
2026
-
[19]
Hud: Hierar- chical uncertainty-aware disambiguation network for composed video retrieval,
Z. Chen, Y . Hu, Z. Li, Z. Fu, H. Wen, and W. Guan, “Hud: Hierar- chical uncertainty-aware disambiguation network for composed video retrieval,” inProceedings of the ACM International Conference on Multimedia, 2025, p. 6143–6152
2025
-
[20]
Refine: Composed video retrieval via shared and differential semantics enhance- ment,
Y . Hu, Z. Li, Z. Chen, Q. Huang, Z. Fu, M. Xu, and L. Nie, “Refine: Composed video retrieval via shared and differential semantics enhance- ment,”ACM Transactions on Multimedia Computing, Communications and Applications, 2026
2026
-
[21]
Tri- subspaces disentanglement for multimodal sentiment analysis,
C. Meng, J. Luo, Z. Yan, Z. Yu, R. Fu, Z. Gan, and C. Ouyang, “Tri- subspaces disentanglement for multimodal sentiment analysis,”CVPR 2026, 2026
2026
-
[22]
Cotextor: Training- free modular multilingual text editing via layered disentanglement and depth-aware fusion,
Z. Yu, M. Y . I. Idris, P. Wang, and R. Qureshi, “Cotextor: Training- free modular multilingual text editing via layered disentanglement and depth-aware fusion,” inNeurIPS 2025, 2025
2025
-
[23]
DynamicNER: A dynamic, multilingual, and fine-grained dataset for LLM-based named entity recognition,
H. Luo, Y . Jin, Y . Wang, X. Li, T. Shang, X. Liu, R. Chen, K. Wang, H. Salam, Q. Wen, and Z. Liu, “DynamicNER: A dynamic, multilingual, and fine-grained dataset for LLM-based named entity recognition,” in Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 16 511–16 535
2025
-
[24]
L. Hu, Y . Xin, B. Shen, H. Cai, and L. Jin, “Codes: A context-efficient framework for enhancing small language models via domain-specific adaptation and model ensembling,”Preprints, March 2026. [Online]. Available: https://doi.org/10.20944/preprints202603.1152.v1
-
[25]
Parameter-efficient and student-friendly knowledge distillation,
J. Rao, X. Meng, L. Ding, S. Qi, X. Liu, M. Zhang, and D. Tao, “Parameter-efficient and student-friendly knowledge distillation,”IEEE Trans. Multim., pp. 1–12, 2023
2023
-
[26]
L. Lai, Z. Cheng, K. Cheng, and X. Qi, “Do transformers always win? an empirical study of semantic embeddings for short-text e-commerce reviews,” Mar. 2026, research Square preprint, Version 1, posted 20 March 2026. [Online]. Available: https://doi.org/10.21203/rs.3.rs- 9163424/v1
-
[27]
Reg- former: an efficient projection-aware transformer network for large-scale point cloud registration,
J. Liu, G. Wang, Z. Liu, C. Jiang, M. Pollefeys, and H. Wang, “Reg- former: an efficient projection-aware transformer network for large-scale point cloud registration,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8451–8460
2023
-
[28]
Autoneural: Co-designing vision-language models for npu inference,
W. Chen, L. Wu, Y . Hu, Z. Li, Z. Cheng, Y . Qian, L. Zhu, Z. Hu, L. Liang, Q. Tang, Z. Liu, and H. Yang, “Autoneural: Co-designing vision-language models for npu inference,” 2025. [Online]. Available: https://arxiv.org/abs/2512.02924
-
[29]
REA-RL: Reflection-aware online reinforcement learning for efficient reasoning,
H. Deng, W. Jiao, X. Liu, J. Rao, and M. Zhang, “REA-RL: Reflection-aware online reinforcement learning for efficient reasoning,” inThe Fourteenth International Conference on Learning Representations (ICLR), 2026. [Online]. Available: https://openreview.net/forum?id=E6keG5QDct
2026
-
[30]
arXiv preprint arXiv:2602.19320 , year=
D. Jiang, Y . Li, S. Wei, J. Yang, A. Kishore, A. Zhao, D. Kang, X. Hu, F. Chen, Q. Liet al., “Anatomy of agentic memory: Taxonomy and empirical analysis of evaluation and system limitations,”arXiv preprint arXiv:2602.19320, 2026
-
[31]
Efficient partitioning vision transformer on edge devices for distributed inference,
X. Liu, Y . Song, X. Li, Y . Sun, H. Lan, Z. Liu, L. Jiang, and J. Li, “Efficient partitioning vision transformer on edge devices for distributed inference,” in2025 IEEE 45th International Conference on Distributed Computing Systems (ICDCS). IEEE, 2025, pp. 286–296
2025
-
[32]
Fedlpa: One- shot federated learning with layer-wise posterior aggregation,
X. Liu, L. Liu, F. Ye, Y . Shen, X. Li, L. Jiang, and J. Li, “Fedlpa: One- shot federated learning with layer-wise posterior aggregation,”Advances in Neural Information Processing Systems, vol. 37, pp. 81 510–81 548, 2024
2024
-
[33]
One-shot federated learning methods: A practical guide,
X. Liu, Z. Tang, X. Li, Y . Song, S. Ji, Z. Liu, B. Han, L. Jiang, and J. Li, “One-shot federated learning methods: A practical guide,”arXiv preprint arXiv:2502.09104, 2025
-
[34]
Fastpillars: A deployment-friendly pillar-based 3d detector,
S. Zhou, X. Zhang, X. Chu, B. Zhang, Z. Zhao, and X. Lu, “Fastpillars: A deployment-friendly pillar-based 3d detector,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[35]
GSQ- tuning: Group-shared exponents integer in fully quantized training for LLMs on-device fine-tuning,
S. Zhou, S. Wang, Z. Yuan, M. Shi, Y . Shang, and D. Yang, “GSQ- tuning: Group-shared exponents integer in fully quantized training for LLMs on-device fine-tuning,” inFindings of the Association for Computational Linguistics: ACL 2025. Vienna, Austria: Association for Computational Linguistics, Jul. 2025, pp. 22 971–22 988
2025
-
[36]
Yolov8- dds: A lightweight model based on pruning and distillation for early detection of root mold in barley seedling,
J. Huang, Z. Ma, Y . Wu, Y . Bao, Y . Wang, Z. Su, and L. Guo, “Yolov8- dds: A lightweight model based on pruning and distillation for early detection of root mold in barley seedling,”Information Processing in Agriculture, vol. 12, no. 4, pp. 581–594, 2025
2025
-
[37]
Filter-and-refine: A MLLM based cascade system for industrial-scale video content moderation,
Z. Wang, J. Shi, H. Liang, X. Shen, V . Wen, Z. Chen, Y . Wu, Z. Zhang, and H. Xiong, “Filter-and-refine: A MLLM based cascade system for industrial-scale video content moderation,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track), 2025, pp. 873–880
2025
-
[38]
Echo-2: A large scale distributed rollout framework for cost-efficient reinforcement learning,
J. Xiao, M. Chen, Q. Ren, S. Jingwei, J. Huang, Y . Deng, C. Tong, W. Chen, S. Wang, Z. Biet al., “Echo-2: A large scale distributed rollout framework for cost-efficient reinforcement learning,”arXiv preprint arXiv:2602.02192, 2026
-
[39]
An efficient solution method for solving convex separable quadratic optimization problems,
S. Li, J. Wu, C. Lu, Z. Deng, and S.-C. Fang, “An efficient solution method for solving convex separable quadratic optimization problems,” arXiv preprint arXiv:2510.11554, 2025
-
[40]
A semidefinite relaxation based global algorithm for two-level graph partition problem
J. Wu, C. Lu, S. Li, and Z. Deng, “A semidefinite relaxation based global algorithm for two-level graph partition problem.”Journal of Industrial & Management Optimization, vol. 19, no. 9, 2023
2023
-
[41]
Comptrack: Information bottleneck-guided low-rank dynamic token compression for point cloud tracking,
S. Zhou, Y . Cao, J. Nie, Y . Fu, Z. Zhao, X. Lu, and S. Wang, “Comptrack: Information bottleneck-guided low-rank dynamic token compression for point cloud tracking,” inThe Fortieth AAAI Conference on Artificial Intelligence, 2025. [Online]. Available: https://openreview.net/forum?id=nXExYROmVe
2025
-
[42]
Regime-dependent volatility dynamics: Evidence from time-series analysis,
K. Cheng, X. Qi, Z. Cheng, L. Lai, and X. Liu, “Regime-dependent volatility dynamics: Evidence from time-series analysis,” Jan. 2026, sSRN working paper. Date Written: January 24, 2026; posted March 11, 2026. [Online]. Available: https://dx.doi.org/10.2139/ssrn.6321958
- [43]
-
[44]
J. Rao, X. Liu, H. Deng, Z. Lin, Z. Yu, J. Wei, X. Meng, and M. Zhang, “Dynamic sampling that adapts: Self-aware iterative data persistent optimization for mathematical reasoning,” inFindings of the Association for Computational Linguistics: ACL 2026, 2026. [Online]. Available: https://arxiv.org/abs/2505.16176
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
NoiseBox: Towards More Efficient and Effective Learning with Noisy Labels,
C. Feng, G. Tzimiropoulos, and I. Patras, “NoiseBox: Towards More Efficient and Effective Learning with Noisy Labels,”IEEE Transactions on Circuits and Systems for Video Technology, 7 2024
2024
-
[46]
PROSAC: Provably safe certification for machine learning models under adversarial attacks,
C. Feng, Z. Liu, Z. Zhi, I. Bogunovic, C. Gerner-Beuerle, and M. Ro- drigues, “PROSAC: Provably safe certification for machine learning models under adversarial attacks,” inThe 39th Annual AAAI Conference on Artificial Intelligence (AAAI) [Oral], 2025
2025
-
[47]
Noisy but valid: Robust statistical evaluation of LLMs with imperfect judges,
C. Feng, M. Shen, A. Balashankar, C. Gerner-Beuerle, and M. Rodrigues, “Noisy but valid: Robust statistical evaluation of LLMs with imperfect judges,” inThe Fourteenth International Conference on Learning Representations (ICLR), 2026. [Online]. Available: https://openreview.net/forum?id=hEhxreaLdU
2026
-
[48]
Dynamic neural fortresses: An adaptive shield for model extraction defense,
S. Luan, Z. Wang, L. Shen, Z. Gu, C. Wu, and D. Tao, “Dynamic neural fortresses: An adaptive shield for model extraction defense,” in The Thirteenth International Conference on Learning Representations, 2025
2025
-
[49]
Agentauditor: Human-level safety and security evaluation for llm agents,
H. Luo, S. Dai, C. Ni, X. Li, G. Zhang, K. Wang, T. Liu, and H. Salam, “Agentauditor: Human-level safety and security evaluation for llm agents,” 2026
2026
-
[50]
From voice to safety: Language ai powered pilot-atc communication understanding for airport surface movement collision risk assessment,
Y . Pang, A. P. Kendall, A. Porcayo, M. Barsotti, A. Jain, and J.-P. Clarke, “From voice to safety: Language ai powered pilot-atc communication understanding for airport surface movement collision risk assessment,” Transportation Research Part C: Emerging Technologies, vol. 184, p. 105540, 2026
2026
-
[51]
Reinforcement learning driven integrated detection and mitigation of uav gps spoofing attacks,
J. Hu, M. Ammar, B. Z. Hussain, J. Kim, and I. Khan, “Reinforcement learning driven integrated detection and mitigation of uav gps spoofing attacks,”IEEE Internet of Things Journal, 2025
2025
-
[52]
A fully data-driven approach for realistic traffic signal control using offline reinforcement learning,
J. Li, S. p. Lin, T. Shi, C. Tian, Y . Mei, J. Song, X. Zhan, and R. Li, “A fully data-driven approach for realistic traffic signal control using offline reinforcement learning,”Data Science for Transportation, vol. 7, no. 3, pp. 1–18, 2025
2025
-
[53]
Ccma: A framework for cascading cooperative multi-agent in autonomous driving merging using large language models,
M. Zhang, Z. Fang, T. Wang, S. Lu, X. Wang, and T. Shi, “Ccma: A framework for cascading cooperative multi-agent in autonomous driving merging using large language models,”Expert Systems with Applications, vol. 282, p. 127717, 2025
2025
-
[54]
Towards cleaner heating production in rural areas: Identifying optimal regional renewable systems with a case in ningxia, china,
J. He, Y . Wu, J. Wu, S. Li, F. Liu, J. Zhou, and M. Liao, “Towards cleaner heating production in rural areas: Identifying optimal regional renewable systems with a case in ningxia, china,”Sustainable Cities and Society, vol. 75, p. 103288, 2021
2021
-
[55]
Reasoning-enhanced domain-adaptive pretraining of mul- timodal large language models for short video content governance,
Z. Wang, Y . Sun, H. Wang, B. Jing, X. Shen, X. Dong, Z. Hao, H. Xiong, and Y . Song, “Reasoning-enhanced domain-adaptive pretraining of mul- timodal large language models for short video content governance,” in Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, 2025, pp. 1104–1112
2025
-
[56]
When rules fall short: Agent-driven discovery of emerging content issues in short video platforms,
C. Yu, H. Wang, J. Chen, Z. Wang, B. Deng, Z. Hao, H. Xiong, and Y . Song, “When rules fall short: Agent-driven discovery of emerging content issues in short video platforms,” 2026
2026
-
[57]
Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving,
S. Zeng, X. Chang, M. Xie, X. Liu, Y . Bai, Z. Pan, M. Xu, X. Wei, and N. Guo, “Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving,”arXiv preprint arXiv:2505.17685, 2025
-
[58]
S. Zeng, D. Qi, X. Chang, F. Xiong, S. Xie, X. Wu, S. Liang, M. Xu, and X. Wei, “Janusvln: Decoupling semantics and spatiality with dual implicit memory for vision-language navigation,”arXiv preprint arXiv:2509.22548, 2025
-
[59]
Forecasting freeway traffic flow for intelligent transporta- tion systems application,
B. L. Smith, “Forecasting freeway traffic flow for intelligent transporta- tion systems application,” Ph.D. dissertation, University of Virginia, 1995
1995
-
[60]
Short-term traffic flow prediction using seasonal ARIMA model with limited input data,
S. V . Kumar and L. Vanajakshi, “Short-term traffic flow prediction using seasonal ARIMA model with limited input data,”European Transport Research Review, vol. 7, pp. 1–9, 2015
2015
-
[61]
Predicting short-term traffic flow in urban based on multivariate linear regression model,
D. Li, “Predicting short-term traffic flow in urban based on multivariate linear regression model,”Journal of Intelligent & Fuzzy Systems, vol. 39, no. 2, pp. 1417–1427, 2020
2020
-
[62]
Travel-time prediction with support vector regression,
C.-H. Wu, J.-M. Ho, and D.-T. Lee, “Travel-time prediction with support vector regression,”IEEE Transactions on Intelligent Transportation Systems, vol. 5, no. 4, pp. 276–281, 2004
2004
-
[63]
Diffusion convolutional recurrent neural network: Data-driven traffic forecasting,
Y . Li, R. Yu, C. Shahabi, and Y . Liu, “Diffusion convolutional recurrent neural network: Data-driven traffic forecasting,” inInternational Con- ference on Learning Representations (ICLR), 2018
2018
-
[64]
Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting,
B. Yu, H. Yin, and Z. Zhu, “Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting,”arXiv, 2017
2017
-
[65]
Graph wavenet for deep spatial-temporal graph modeling,
Z. Wu, S. Pan, G. Long, J. Jiang, and C. Zhang, “Graph wavenet for deep spatial-temporal graph modeling,”arXiv, 2019
2019
-
[66]
Spatial-temporal fusion graph neural networks for traffic flow forecasting,
M. Li and Z. Zhu, “Spatial-temporal fusion graph neural networks for traffic flow forecasting,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 35, 2021, pp. 4189–4196
2021
-
[67]
Adaptive graph convolutional recurrent network for traffic forecasting,
L. Bai, L. Yao, C. Li, X. Wang, and C. Wang, “Adaptive graph convolutional recurrent network for traffic forecasting,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 17 804–17 815
2020
-
[68]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems (NeurIPS), 2017, pp. 5998– 6008
2017
-
[69]
Gman: A graph multi-attention network for traffic prediction,
C. Zheng, X. Fan, C. Wang, and J. Qi, “Gman: A graph multi-attention network for traffic prediction,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 34, 2020, pp. 1234–1241
2020
-
[70]
Towards spatio- temporal aware traffic time series forecasting,
R.-G. Cirstea, B. Yang, C. Guo, T. Kieu, and S. Pan, “Towards spatio- temporal aware traffic time series forecasting,” inProceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE), 2022, pp. 2900–2913
2022
-
[71]
A time series is worth 64 words: Long-term forecasting with transformers,
Y . Nie, N. H. Nguyen, P. Sinthong, and J. Kalagnanam, “A time series is worth 64 words: Long-term forecasting with transformers,”arXiv, 2022
2022
-
[72]
itrans- former: Inverted transformers are effective for time series forecasting,
Y . Liu, T. Hu, H. Zhang, H. Wu, S. Wang, L. Ma, and M. Long, “itrans- former: Inverted transformers are effective for time series forecasting,” arXiv, 2023
2023
-
[73]
Adaptive context length optimization with low-frequency truncation for multi-agent reinforcement learning,
W. Duan, Y . Yu, J. He, and Y . Shi, “Adaptive context length optimization with low-frequency truncation for multi-agent reinforcement learning,” inThe Thirty-ninth Annual Conference on Neural Information Process- ing Systems
-
[74]
Hippo: Recurrent memory with optimal polynomial projections,
A. Gu, T. Dao, S. Ermon, A. Rudra, and C. R ´e, “Hippo: Recurrent memory with optimal polynomial projections,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 1474– 1487
2020
-
[75]
Efficiently modeling long sequences with structured state spaces,
A. Gu, K. Goel, and C. R ´e, “Efficiently modeling long sequences with structured state spaces,”arXiv, 2021
2021
-
[76]
Mamba: Linear-time sequence modeling with selective state spaces,
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,”arXiv, 2023
2023
-
[77]
U-mamba: Enhancing long-range depen- dency for biomedical image segmentation,
J. Ma, F. Li, and B. Wang, “U-mamba: Enhancing long-range depen- dency for biomedical image segmentation,”arXiv, 2024
2024
-
[78]
Vision mamba: Efficient visual representation learning with bidirectional state space model,
L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang, “Vision mamba: Efficient visual representation learning with bidirectional state space model,”arXiv, 2024
2024
-
[79]
Videomamba: State space model for efficient video understanding,
K. Li, X. Li, Y . Wang, Y . He, Y . Wang, L. Wang, and Y . Qiao, “Videomamba: State space model for efficient video understanding,” arXiv, 2024
2024
-
[80]
Graph neural controlled differential equations for traffic forecasting,
J. Choi, H. Choi, J. Hwang, and N. Park, “Graph neural controlled differential equations for traffic forecasting,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 36, 2022, pp. 6367–6374
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.