Recognition: unknown
QuantileMark: A Message-Symmetric Multi-bit Watermark for LLMs
Pith reviewed 2026-05-10 14:06 UTC · model grok-4.3
The pith
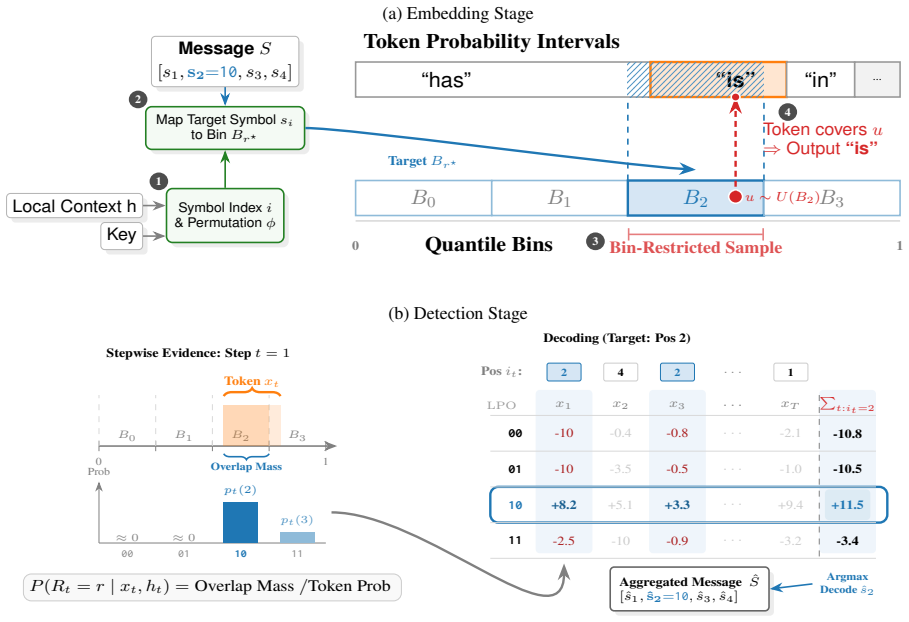
QuantileMark embeds multi-bit messages by partitioning the cumulative probability interval into equal-mass bins.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
QuantileMark embeds the message inside the quantile of the cumulative distribution function by partitioning [0,1) into M equal-mass bins and restricting the next-token sample to the bin indexed by the message. This construction guarantees message-unbiasedness: the expected token distribution conditioned on a uniform random message equals the unwatermarked model distribution. The equal-mass design further ensures that every message receives identical evidence strength during verification, which reconstructs the same partitions under teacher forcing and aggregates posterior bin probabilities.
What carries the argument
The equal-mass partition of the cumulative probability interval [0,1) into M bins, from which the model is forced to sample the token belonging to the message-assigned bin.
Load-bearing premise
The verifier can exactly reconstruct the same cumulative-probability partitions that were used at generation time, even when tokens were sampled rather than chosen by greedy decoding.
What would settle it
Measuring whether the average next-token distribution over a uniform sample of messages deviates from the base model's distribution on held-out prompts.
Figures





read the original abstract
As large language models become standard backends for content generation, practical provenance increasingly requires multi-bit watermarking. In provider-internal deployments, a key requirement is message symmetry: the message itself should not systematically affect either text quality or verification outcomes. Vocabulary-partition watermarks can break message symmetry in low-entropy decoding: some messages are assigned most of the probability mass, while others are forced to use tail tokens. This makes embedding quality and message decoding accuracy message-dependent. We propose QuantileMark, a white-box multi-bit watermark that embeds messages within the continuous cumulative probability interval $[0, 1)$. At each step, QuantileMark partitions this interval into $M$ equal-mass bins and samples strictly from the bin assigned to the target symbol, ensuring a fixed $1/M$ probability budget regardless of context entropy. For detection, the verifier reconstructs the same partition under teacher forcing, computes posteriors over latent bins, and aggregates evidence for verification. We prove message-unbiasedness, a property ensuring that the base distribution is recovered when averaging over messages. This provides a theoretical foundation for generation-side symmetry, while the equal-mass design additionally promotes uniform evidence strength across messages on the detection side. Empirical results on C4 continuation and LFQA show improved multi-bit recovery and detection robustness over strong baselines, with negligible impact on generation quality. Our code is available at GitHub (https://github.com/zzzjunlin/QuantileMark).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes QuantileMark, a white-box multi-bit watermark for LLMs that partitions the continuous cumulative probability interval [0,1) into M equal-mass bins at each step and samples from the bin corresponding to the target message. It proves message-unbiasedness (the base distribution is recovered when averaging over messages) and reports improved multi-bit recovery and detection robustness on C4 continuation and LFQA tasks relative to vocabulary-partition baselines, with negligible quality degradation. Code is released.
Significance. If the central claims hold, the work supplies a theoretically grounded alternative to vocabulary-partition watermarks that avoids message-dependent bias in low-entropy contexts. The equal-mass construction and the explicit proof of message-unbiasedness constitute a clear advance; the public code release further strengthens the contribution by enabling direct reproducibility.
minor comments (3)
- [§3.1] §3.1: the description of how the verifier recomputes the exact same partition boundaries under teacher forcing would benefit from an explicit small example (e.g., a 3-token sequence with M=4) showing that the bin edges are identical for both greedy and sampled tokens.
- [Table 2] Table 2: the reported AUC values for multi-bit detection would be easier to interpret if the number of bits per token and the exact false-positive rate threshold were stated in the caption rather than only in the text.
- [§4.3] §4.3: the sentence claiming 'uniform evidence strength across messages' should be accompanied by a brief quantitative check (e.g., variance of per-message detection scores) to make the claim directly verifiable from the reported experiments.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the theoretical contribution (equal-mass partitioning and message-unbiasedness proof), and recommendation of minor revision. The referee correctly notes the advantages over vocabulary-partition baselines in low-entropy settings and the value of the public code release.
Circularity Check
No significant circularity identified
full rationale
The paper derives message-unbiasedness directly from the equal-mass partitioning of the [0,1) interval into M bins, each assigned exactly 1/M probability mass by construction. This ensures that averaging the modified distributions over all messages recovers the base distribution as a straightforward mathematical consequence of the uniform bin probabilities, independent of context entropy. The verifier reconstruction under teacher forcing follows identically because partitions are deterministic functions of the prefix and model output distribution alone. No equations reduce a claimed prediction to a fitted parameter, no self-citations bear load on the central property, and no ansatz or uniqueness theorem is imported. The derivation is self-contained against the stated construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- M
axioms (1)
- standard math The cumulative distribution function of any discrete distribution over tokens can be partitioned into M contiguous intervals each having total probability mass exactly 1/M.
Reference graph
Works this paper leans on
-
[1]
MirrorMark: Generalizable Mirrored Sampling for Multi-bit LLM Watermarking
Invisible entropy: Towards safe and efficient low-entropy LLM watermarking. InProceedings of the 2025 Conference on Empirical Methods in Natu- ral Language Processing, pages 6727–6744, Suzhou, China. Association for Computational Linguistics. Karl Moritz Hermann, Tomas Kocisky, Edward Grefen- stette, Lasse Espeholt, Will Kay, Mustafa Suleyman, and Phil Bl...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
coherence
Towards codable watermarking for injecting multi-bits information to LLMs. InThe Twelfth Inter- national Conference on Learning Representations. Yihan Wu, Zhengmian Hu, Hongyang Zhang, and Heng Huang. 2024. Dipmark: A stealthy, efficient and resilient watermark for large language models. In Proceedings of the 41st International Conference on Machine Learn...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.