Recognition: unknown
Blind Bitstream-corrupted Video Recovery via Metadata-guided Diffusion Model
Pith reviewed 2026-05-10 13:54 UTC · model grok-4.3
The pith
A metadata-guided diffusion model recovers bitstream-corrupted videos without any predefined damage masks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
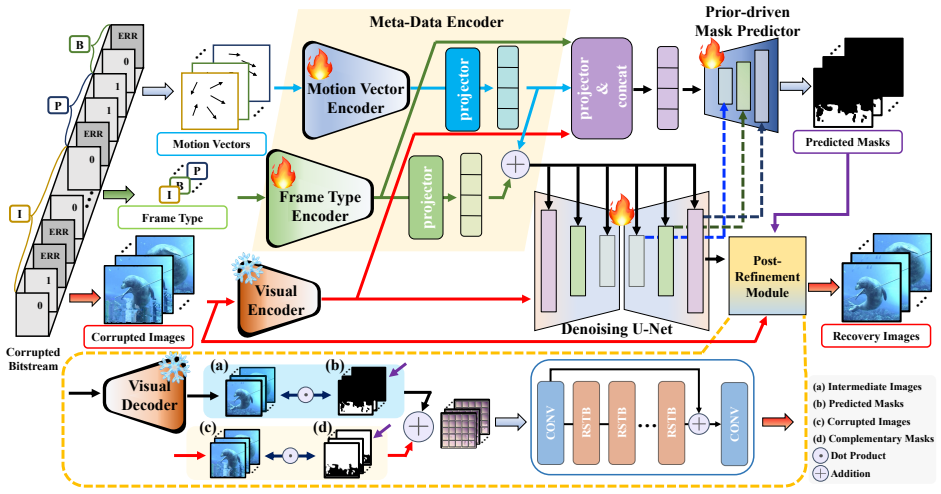
We propose a Metadata-Guided Diffusion Model (M-GDM) that leverages intrinsic video metadata as corruption indicators through a dual-stream metadata encoder which separately embeds motion vectors and frame types before fusing them. This representation interacts with corrupted latent features via cross-attention at each diffusion step. A prior-driven mask predictor generates pseudo masks using both metadata and diffusion priors to separate and recombine intact and recovered regions through hard masking, with a post-refinement module to enhance consistency.
What carries the argument
The Metadata-Guided Diffusion Model (M-GDM) that uses a dual-stream encoder for motion vectors and frame types, cross-attention with diffusion features, and a prior-driven mask predictor to handle blind recovery.
If this is right
- Removes the need for labor-intensive manual annotation of corrupted regions in practical video recovery.
- Accurately identifies and restores content from extensive and irregular degradations using metadata signals.
- Preserves intact regions by generating pseudo masks and applying hard masking.
- Reduces boundary artifacts through post-refinement for seamless integration of recovered parts.
- Outperforms existing methods in blind settings according to extensive experiments.
Where Pith is reading between the lines
- Such an approach could be adapted to other streaming or storage error patterns where partial metadata survives.
- Real-time applications like live video calls might benefit if the diffusion process can be accelerated.
- Testing on videos from different codecs would check whether the metadata guidance generalizes beyond the training distribution.
Load-bearing premise
That intrinsic video metadata such as motion vectors and frame types can still be extracted and remain reliable indicators of corruption locations even from heavily bitstream-corrupted videos.
What would settle it
Running the method on videos where the bitstream corruption also destroys the motion vectors and frame type information, resulting in failure to locate corrupted regions accurately.
Figures




read the original abstract
Bitstream-corrupted video recovery aims to restore realistic content degraded during video storage or transmission. Existing methods typically assume that predefined masks of corrupted regions are available, but manually annotating these masks is labor-intensive and impractical in real-world scenarios. To address this limitation, we introduce a new blind video recovery setting that removes the reliance on predefined masks. This setting presents two major challenges: accurately identifying corrupted regions and recovering content from extensive and irregular degradations. We propose a Metadata-Guided Diffusion Model (M-GDM) to tackle these challenges. Specifically, intrinsic video metadata are leveraged as corruption indicators through a dual-stream metadata encoder that separately embeds motion vectors and frame types before fusing them into a unified representation. This representation interacts with corrupted latent features via cross-attention at each diffusion step. To preserve intact regions, we design a prior-driven mask predictor that generates pseudo masks using both metadata and diffusion priors, enabling the separation and recombination of intact and recovered regions through hard masking. To mitigate boundary artifacts caused by imperfect masks, a post-refinement module enhances consistency between intact and recovered regions. Extensive experiments demonstrate the effectiveness of our method and its superiority in blind video recovery. Code is available at: https://github.com/Shuyun-Wang/M-GDM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a blind setting for bitstream-corrupted video recovery that eliminates the need for predefined masks of corrupted regions. It proposes the Metadata-Guided Diffusion Model (M-GDM), which employs a dual-stream metadata encoder to embed motion vectors and frame types separately before cross-attention fusion with corrupted latent features at each diffusion step. A prior-driven mask predictor generates pseudo-masks from metadata and diffusion priors to enable hard masking for separating intact and recovered regions, followed by a post-refinement module to reduce boundary artifacts. The authors assert that extensive experiments confirm the method's effectiveness and superiority for blind recovery.
Significance. If the metadata reliability assumption holds, the work could meaningfully advance practical video restoration by removing labor-intensive mask annotation, a key barrier in prior methods. The combination of metadata guidance with diffusion priors for pseudo-mask generation is a technically interesting approach to the blind setting, and the public code release aids reproducibility. The result would be most impactful if experiments include direct validation of metadata extraction under realistic corruption.
major comments (1)
- [Method section (dual-stream metadata encoder and prior-driven mask predictor)] Method section (dual-stream metadata encoder and prior-driven mask predictor): The pipeline treats motion vectors and frame types as reliable corruption indicators that remain parsable even under heavy bitstream corruption. No quantitative evaluation of metadata extraction success rates, error propagation under packet loss, or fallback behavior is provided. This assumption is load-bearing, because failure of the encoder to receive valid inputs would invalidate the cross-attention fusion, pseudo-mask generation, and subsequent hard-masking step.
minor comments (2)
- [Abstract] Abstract: The statement that 'extensive experiments demonstrate the effectiveness' should briefly reference key metrics (e.g., PSNR/SSIM gains) and baselines to allow readers to assess the claim without reading the full experiments section.
- [Experiments section] Experiments section: Tables comparing against mask-dependent baselines should explicitly note whether those baselines were given oracle masks or adapted to the blind setting, to ensure fair comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for identifying a key assumption in our blind recovery pipeline. We address the major comment below and commit to strengthening the manuscript accordingly.
read point-by-point responses
-
Referee: The pipeline treats motion vectors and frame types as reliable corruption indicators that remain parsable even under heavy bitstream corruption. No quantitative evaluation of metadata extraction success rates, error propagation under packet loss, or fallback behavior is provided. This assumption is load-bearing, because failure of the encoder to receive valid inputs would invalidate the cross-attention fusion, pseudo-mask generation, and subsequent hard-masking step.
Authors: We acknowledge that the parsability of motion vectors and frame types is a foundational assumption for the dual-stream metadata encoder and prior-driven mask predictor. In standard video codecs, these elements reside in slice headers and macroblock-level syntax, which are typically protected by error-resilient coding and packetization schemes; our corruption model follows common packet-loss simulation practices where header information remains decodable even when payload data is lost. We agree, however, that the manuscript would benefit from explicit quantification of this assumption. In the revised version we will add a dedicated subsection reporting metadata extraction success rates under controlled packet-loss ratios (0–30 %), an analysis of error propagation into the cross-attention and mask-prediction stages, and a description of fallback behavior (e.g., defaulting to a uniform mask when parsing fails). revision: yes
Circularity Check
No circularity: empirical generative model with independent evaluation
full rationale
The paper introduces M-GDM, a trained diffusion architecture that processes corrupted video latents via a dual-stream metadata encoder, cross-attention fusion, a prior-driven mask predictor, and post-refinement. All components are learned from data and evaluated on held-out corrupted video sequences; no equations reduce a claimed prediction to a fitted input by construction, no load-bearing self-citations close the argument, and no ansatz or uniqueness claim is smuggled in. The derivation chain consists of architectural design choices followed by standard training and quantitative comparison, remaining self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Video metadata (motion vectors and frame types) are available and serve as reliable corruption indicators
Reference graph
Works this paper leans on
-
[1]
Pix2video: Video editing using image diffusion
Duygu Ceylan, Chun-Hao P Huang, and Niloy J Mitra. Pix2video: Video editing using image diffusion. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 23206–23217, 2023. 3
2023
-
[2]
Motion compensated error concealment for hevc based on block-merging and residual energy
Yueh-Lun Chang, Yuriy A Reznik, Zhifeng Chen, and Pamela C Cosman. Motion compensated error concealment for hevc based on block-merging and residual energy. In 2013 20th International Packet Video Workshop, pages 1–6. IEEE, 2013. 3
2013
-
[3]
Free-form video inpainting with 3d gated convolution and temporal patchgan
Ya-Liang Chang, Zhe Yu Liu, Kuan-Ying Lee, and Winston Hsu. Free-form video inpainting with 3d gated convolution and temporal patchgan. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9066– 9075, 2019. 6
2019
-
[4]
Bi-sequential video error concealment method using adaptive homography-based registration.IEEE Transactions on circuits and systems for video technology, 30(6):1535–1549, 2019
Byungjin Chung and Changhoon Yim. Bi-sequential video error concealment method using adaptive homography-based registration.IEEE Transactions on circuits and systems for video technology, 30(6):1535–1549, 2019. 3
2019
-
[5]
Flow-edge guided video completion
Chen Gao, Ayush Saraf, Jia-Bin Huang, and Johannes Kopf. Flow-edge guided video completion. InComputer Vision– ECCV 2020: 16th European Conference, Glasgow, UK, Au- gust 23–28, 2020, Proceedings, Part XII 16, pages 713–729. Springer, 2020. 3
2020
-
[6]
Tokenflow: Consistent diffusion features for consistent video editing
Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Tokenflow: Consistent diffusion features for consistent video editing.arXiv preprint arXiv:2307.10373, 2023. 3
-
[7]
Error compensation framework for flow-guided video inpainting
Jaeyeon Kang, Seoung Wug Oh, and Seon Joo Kim. Error compensation framework for flow-guided video inpainting. InEuropean conference on computer vision, pages 375–390. Springer, 2022. 3
2022
-
[8]
A review of temporal video error conceal- ment techniques and their suitability for hevc and vvc.Mul- timedia Tools and Applications, 80(8):12685–12730, 2021
Mohammad Kazemi, Mohammad Ghanbari, and Shervin Shirmohammadi. A review of temporal video error conceal- ment techniques and their suitability for hevc and vvc.Mul- timedia Tools and Applications, 80(8):12685–12730, 2021. 3
2021
-
[9]
Deep video inpainting
Dahun Kim, Sanghyun Woo, Joon-Young Lee, and In So Kweon. Deep video inpainting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5792–5801, 2019. 6
2019
-
[10]
Sequential error con- cealment for video/images by sparse linear prediction.IEEE Transactions on Multimedia, 15(4):957–969, 2013
J ´an Koloda, Jan Østergaard, Søren H Jensen, Victoria S´anchez, and Antonio M Peinado. Sequential error con- cealment for video/images by sparse linear prediction.IEEE Transactions on Multimedia, 15(4):957–969, 2013. 3
2013
-
[11]
Flow-guided video inpainting with scene tem- plates
Dong Lao, Peihao Zhu, Peter Wonka, and Ganesh Sun- daramoorthi. Flow-guided video inpainting with scene tem- plates. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 14599–14608, 2021. 3
2021
-
[12]
Towards an end-to-end framework for flow-guided video inpainting
Zhen Li, Cheng-Ze Lu, Jianhua Qin, Chun-Le Guo, and Ming-Ming Cheng. Towards an end-to-end framework for flow-guided video inpainting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17562–17571, 2022. 2, 3, 6, 8
2022
-
[13]
Swinir: Image restoration us- ing swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration us- ing swin transformer. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1833–1844,
-
[14]
Error concealment algorithm for hevc coded video using block partition decisions
Ting-Lan Lin, Neng-Chieh Yang, Ray-Hong Syu, Chin- Chie Liao, and Wei-Lin Tsai. Error concealment algorithm for hevc coded video using block partition decisions. In 2013 IEEE International Conference on Signal Processing, Communication and Computing (ICSPCC 2013), pages 1–5. IEEE, 2013. 3
2013
-
[15]
Fuseformer: Fusing fine-grained information in transformers for video inpainting
Rui Liu, Hanming Deng, Yangyi Huang, Xiaoyu Shi, Lewei Lu, Wenxiu Sun, Xiaogang Wang, Jifeng Dai, and Hong- sheng Li. Fuseformer: Fusing fine-grained information in transformers for video inpainting. InProceedings of the IEEE/CVF international conference on computer vision, pages 14040–14049, 2021. 3
2021
-
[16]
Bitstream-corrupted video recov- ery: a novel benchmark dataset and method.Advances in Neural Information Processing Systems, 36, 2024
Tianyi Liu, Kejun Wu, Yi Wang, Wenyang Liu, Kim-Hui Yap, and Lap-Pui Chau. Bitstream-corrupted video recov- ery: a novel benchmark dataset and method.Advances in Neural Information Processing Systems, 36, 2024. 2, 3, 6, 8
2024
-
[17]
The 2017 DAVIS Challenge on Video Object Segmentation
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Ar- bel´aez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017. 6
work page internal anchor Pith review arXiv 2017
-
[18]
Fatezero: Fus- ing attentions for zero-shot text-based video editing
Chenyang Qi, Xiaodong Cun, Yong Zhang, Chenyang Lei, Xintao Wang, Ying Shan, and Qifeng Chen. Fatezero: Fus- ing attentions for zero-shot text-based video editing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15932–15942, 2023. 3
2023
-
[19]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. Sam 2: Segment anything in images and videos. arXiv preprint arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2, 3, 4
2022
-
[21]
Video error concealment using deep neural networks
Arun Sankisa, Arjun Punjabi, and Aggelos K Katsaggelos. Video error concealment using deep neural networks. In 2018 25th IEEE International Conference on Image Process- ing (ICIP), pages 380–384. IEEE, 2018. 3
2018
-
[22]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 3
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[23]
Videocomposer: Compositional video synthesis with motion controllability.Advances in Neural Information Processing Systems, 36, 2024
Xiang Wang, Hangjie Yuan, Shiwei Zhang, Dayou Chen, Ji- uniu Wang, Yingya Zhang, Yujun Shen, Deli Zhao, and Jin- gren Zhou. Videocomposer: Compositional video synthesis with motion controllability.Advances in Neural Information Processing Systems, 36, 2024. 3, 5
2024
-
[24]
Towards language-driven video inpainting via multimodal large language models
Jianzong Wu, Xiangtai Li, Chenyang Si, Shangchen Zhou, Jingkang Yang, Jiangning Zhang, Yining Li, Kai Chen, Yun- hai Tong, Ziwei Liu, et al. Towards language-driven video inpainting via multimodal large language models. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12501–12511, 2024. 3, 4, 6
2024
-
[25]
Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 7623–7633, 2023. 3, 4
2023
-
[26]
A spatial-focal error concealment scheme for cor- rupted focal stack video
Kejun Wu, Yi Wang, Wenyang Liu, Kim-Hui Yap, and Lap- Pui Chau. A spatial-focal error concealment scheme for cor- rupted focal stack video. In2023 Data Compression Confer- ence (DCC), pages 91–100. IEEE, 2023. 3
2023
-
[27]
Semi-supervised video inpaint- ing with cycle consistency constraints
Zhiliang Wu, Hanyu Xuan, Changchang Sun, Weili Guan, Kang Zhang, and Yan Yan. Semi-supervised video inpaint- ing with cycle consistency constraints. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22586–22595, 2023. 2
2023
-
[28]
Generative adversarial networks based error con- cealment for low resolution video
Chongyang Xiang, Jiajun Xu, Chuan Yan, Qiang Peng, and Xiao Wu. Generative adversarial networks based error con- cealment for low resolution video. InICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1827–1831. IEEE, 2019. 3
2019
-
[29]
Deep flow-guided video inpainting
Rui Xu, Xiaoxiao Li, Bolei Zhou, and Chen Change Loy. Deep flow-guided video inpainting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3723–3732, 2019. 3
2019
-
[30]
The 2nd large-scale video object segmentation challenge-video object segmenta- tion track, 2019
Linjie Yang, Yuchen Fan, and Ning Xu. The 2nd large-scale video object segmentation challenge-video object segmenta- tion track, 2019. 6
2019
-
[31]
Hybrid spatial and temporal error concealment for distributed video coding
Shuiming Ye, Mourad Ouaret, Frederic Dufaux, and Touradj Ebrahimi. Hybrid spatial and temporal error concealment for distributed video coding. In2008 IEEE International Conference on Multimedia and Expo, pages 633–636. IEEE,
-
[32]
Learning joint spatial-temporal transformations for video inpainting
Yanhong Zeng, Jianlong Fu, and Hongyang Chao. Learning joint spatial-temporal transformations for video inpainting. InComputer Vision–ECCV 2020: 16th European Confer- ence, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVI 16, pages 528–543. Springer, 2020. 3
2020
-
[33]
Inertia-guided flow completion and style fusion for video inpainting
Kaidong Zhang, Jingjing Fu, and Dong Liu. Inertia-guided flow completion and style fusion for video inpainting. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 5982–5991, 2022. 3
2022
-
[34]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 6
2018
-
[35]
Avid: Any-length video inpainting with diffusion model, 2024
Zhixing Zhang, Bichen Wu, Xiaoyan Wang, Yaqiao Luo, Luxin Zhang, Yinan Zhao, Peter Vajda, Dimitris Metaxas, and Licheng Yu. Avid: Any-length video inpainting with diffusion model.arXiv preprint arXiv:2312.03816, 2023. 2, 3
-
[36]
Ciri: Curricular inactivation for residue- aware one-shot video inpainting
Weiying Zheng, Cheng Xu, Xuemiao Xu, Wenxi Liu, and Shengfeng He. Ciri: Curricular inactivation for residue- aware one-shot video inpainting. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 13012–13022, 2023. 3
2023
-
[37]
ProPainter: Improving propagation and transformer for video inpainting
Shangchen Zhou, Chongyi Li, Kelvin C.K Chan, and Chen Change Loy. ProPainter: Improving propagation and transformer for video inpainting. InProceedings of IEEE International Conference on Computer Vision (ICCV), 2023. 2, 3, 6, 8
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.