Complex Interpolation of Matrices with an application to Multi-Manifold Learning
Pith reviewed 2026-05-10 12:57 UTC · model grok-4.3
The pith
Exact log-linearity of the operator norm under matrix interpolation holds if and only if the two symmetric positive definite matrices share a common eigenvector.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Generically, the function x maps to log of the operator norm of A to the power 1-x times B to the power x is linear on the interval from 0 to 1 if and only if A and B have a shared eigenvector. This follows from the spectral properties of the interpolated family. When the linearity holds only approximately, the principal singular vectors of the interpolation must lie close to the dominant eigenvectors of both A and B. The equivalence supplies a theoretical foundation for detecting common latent factors in multiview data sets by examining the interpolation behavior.
What carries the argument
The one-parameter interpolation family A^{1-x} B^x and the exact log-linearity of its operator norm as a detector of shared eigenvectors.
If this is right
- Shared eigenvectors can be detected by checking whether the log of the operator norm is linear in the interpolation parameter.
- Approximate log-linearity implies that the leading eigenvectors of the two matrices are nearly aligned.
- The interpolation test directly yields a method for multi-manifold learning that isolates common latent structures in multiview data.
- Deviations from log-linearity can be used to highlight distinct structures between the views.
Where Pith is reading between the lines
- The same log-linearity test could be applied to pairs of covariance matrices arising from different sensors or modalities.
- Pairwise checks might be chained to handle more than two matrices and identify structures shared across several views.
- Numerical verification on synthetic data with controlled eigenvector overlap would directly probe the stability bounds.
Load-bearing premise
The matrices are symmetric positive definite so that the real-valued powers are well-defined, and the configuration is generic with no accidental alignments outside the shared-eigenvector case.
What would settle it
Generate two symmetric positive definite matrices that share a leading eigenvector and verify that log of the operator norm is exactly linear across several values of x; repeat the check with matrices that share no eigenvectors and confirm that the log-norm curve deviates from linearity.
Figures
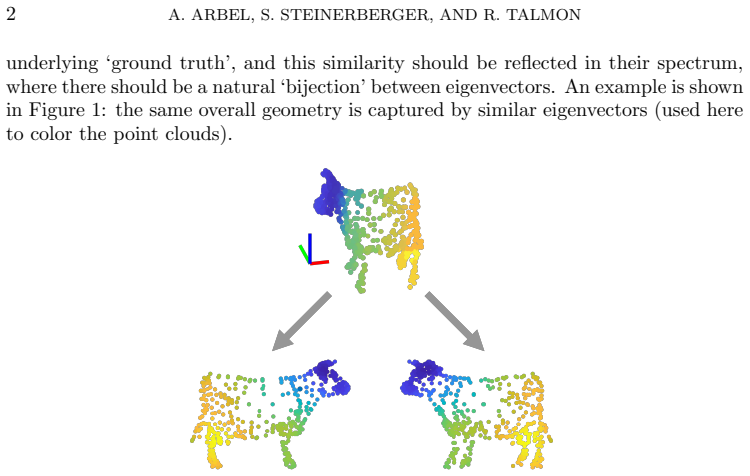





read the original abstract
Given two symmetric positive-definite matrices $A, B \in \mathbb{R}^{n \times n}$, we study the spectral properties of the interpolation $A^{1-x} B^x$ for $0 \leq x \leq 1$. The presence of `common structures' in $A$ and $B$, eigenvectors pointing in a similar direction, can be investigated using this interpolation perspective. Generically, exact log-linearity of the operator norm $\|A^{1-x} B^x\|$ is equivalent to the existence of a shared eigenvector in the original matrices; stability bounds show that approximate log-linearity forces principal singular vectors to align with leading eigenvectors of both matrices. These results give rise to and provide theoretical justification for a multi-manifold learning framework that identifies common and distinct latent structures in multiview data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the spectral properties of the matrix interpolation A^{1-x} B^x for symmetric positive-definite matrices A, B. It claims that, generically, exact log-linearity of the operator norm ||A^{1-x} B^x|| is equivalent to the existence of a shared eigenvector in A and B, provides stability bounds showing that approximate log-linearity forces alignment of principal singular vectors with leading eigenvectors, and uses these results to justify a multi-manifold learning framework for detecting common and distinct latent structures in multiview data.
Significance. If the equivalence and stability results hold after necessary qualification, the work supplies a spectral criterion for identifying shared principal structures via norm behavior under interpolation, offering theoretical support for multi-view manifold methods. The stability bounds constitute a practical strength for noisy data settings.
major comments (2)
- Abstract: The statement that 'Generically, exact log-linearity of the operator norm ||A^{1-x} B^x|| is equivalent to the existence of a shared eigenvector' is imprecise in both directions. Submultiplicativity and ||A^p|| = ||A||^p for SPD A imply ||A^{1-x} B^x|| ≤ ||A||^{1-x} ||B||^x always, with equality for all x only when the leading right singular vector of B^x aligns with the leading left singular vector of A^{1-x} for every x. When maximal eigenvalues are simple, this forces the leading eigenvectors of A and B to coincide. The converse fails for non-principal shared eigenvectors, as the norm remains strictly below the product bound. The stability bounds correctly reference 'principal singular vectors' and 'leading eigenvectors,' indicating the exact-case claim requires the same restriction. This qualification is load-bearing for the multi-manifold application, since non-principal '
- Main text (theorem on exact log-linearity, likely §3 or §4): The generic-case assumption must be stated explicitly (e.g., simple maximal eigenvalues, no unexpected alignments). Without it, the equivalence does not hold even for principal eigenvectors, weakening the link to 'common structures' in the learning framework.
minor comments (2)
- Abstract: Add one sentence specifying that the operator norm is the spectral norm and that the generic setting assumes distinct maximal eigenvalues.
- Notation: Ensure consistent use of ||·|| throughout; clarify whether any results extend to other norms.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight important points on precision in the abstract and explicit assumptions in the theorems. We address each below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Abstract: The statement that 'Generically, exact log-linearity of the operator norm ||A^{1-x} B^x|| is equivalent to the existence of a shared eigenvector' is imprecise in both directions. Submultiplicativity and ||A^p|| = ||A||^p for SPD A imply ||A^{1-x} B^x|| ≤ ||A||^{1-x} ||B||^x always, with equality for all x only when the leading right singular vector of B^x aligns with the leading left singular vector of A^{1-x} for every x. When maximal eigenvalues are simple, this forces the leading eigenvectors of A and B to coincide. The converse fails for non-principal shared eigenvectors, as the norm remains strictly below the product bound. The stability bounds correctly reference 'principal singular vectors' and 'leading eigenvectors,' indicating the exact-case claim requires the same restriction. This qualification is load-bearing for the multi-manifold application, since non-principal '
Authors: We agree that the abstract phrasing is imprecise and will revise it to specify equivalence to a shared leading (principal) eigenvector. The submultiplicativity argument correctly shows that log-linearity of the norm requires alignment of leading singular vectors throughout the interpolation path, forcing coincidence of leading eigenvectors when maximal eigenvalues are simple. Non-principal shared eigenvectors do not produce equality, as they do not govern the operator norm. The stability results already focus on principal singular vectors and leading eigenvectors, so we will align the exact-case claim with this restriction. This will clarify the link to common principal structures in the multi-manifold framework without altering the core results. revision: yes
-
Referee: Main text (theorem on exact log-linearity, likely §3 or §4): The generic-case assumption must be stated explicitly (e.g., simple maximal eigenvalues, no unexpected alignments). Without it, the equivalence does not hold even for principal eigenvectors, weakening the link to 'common structures' in the learning framework.
Authors: We will add an explicit statement of the generic assumptions to the theorem on exact log-linearity, including simplicity of the maximal eigenvalues and absence of unexpected eigenvector alignments. This qualification ensures the equivalence holds rigorously for principal eigenvectors and strengthens the connection to identifying common latent structures in the multiview learning application. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives the claimed equivalence between exact log-linearity of the operator norm of the matrix interpolation and the existence of a shared eigenvector directly from the spectral theory of symmetric positive-definite matrices and submultiplicativity of the operator norm. No step reduces by construction to a fitted parameter, a self-definition, or a load-bearing self-citation; the multi-manifold learning framework is presented as an application justified by the independent mathematical results rather than the reverse. The derivation is self-contained against standard external benchmarks in linear algebra.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A and B are symmetric positive-definite matrices in R^{n x n}
Reference graph
Works this paper leans on
-
[1]
A kernel method for canonical correlation analysis
[1]S. Akaho,A kernel method for canonical correlation analysis, arXiv preprint cs/0609071, (2006). [2]F. R. Bach and M. I. Jordan,Kernel independent component analysis, Journal of Machine Learning Research, 3 (2002), pp. 1–48. [3]R. Bhatia,Positive definite matrices, Princeton university press,
work page Pith review arXiv 2006
-
[2]
[4]R. R. Coifman and S. Lafon,Diffusion maps, Applied and computational harmonic analysis, 21 (2006), pp. 5–30. [5]R. R. Coifman, N. F. Marshall, and S. Steinerberger,A common variable minimax theorem for graphs, Foundations of Computational Mathematics, 23 (2023), pp. 493–517. [6]H. O. Cordes,Spectral theory of linear differential operators and compariso...
work page 2006
-
[3]
[7]F. Dietrich, O. Yair, R. Mulayoff, R. Talmon, and I. G. Kevrekidis,Spectral discovery of jointly smooth features for multimodal data, SIAM Journal on Mathematics of Data Science, 4 (2022), pp. 410–430. [8]C. Dsilva, R. Talmon, R. Coifman, and I. Kevrekidis,Parsimonious representation of nonlinear dynamical systems through manifold learning: A chemotaxi...
work page 2022
-
[4]
Heinz,Beitr¨ age zur st¨ orungstheorie der spektralzerleung, Mathematische Annalen, 123 (1951), pp
[11]E. Heinz,Beitr¨ age zur st¨ orungstheorie der spektralzerleung, Mathematische Annalen, 123 (1951), pp. 415–438. [12]H. Hotelling,Relations between two sets of variates, Biometrika, 28 (1936), pp. 321–377. [13]T. Kato,Notes on some inequalities for linear operators, Mathematische Annalen, 125 (1952), pp. 208–212. [14]O. Katz, R. R. Lederman, and R. Tal...
work page 1951
-
[5]
L ¨owner, ¨Uber monotone matrixfunktionen, Mathematische Zeitschrift, 38 (1934), pp
[16]K. L ¨owner, ¨Uber monotone matrixfunktionen, Mathematische Zeitschrift, 38 (1934), pp. 177–
work page 1934
-
[6]
[17]A. McIntosh,Heinz inequalities and perturbation of spectral families, Macquarie Mathematics Reports, (1979). [18]T. Michaeli, W. Wang, and K. Livescu,Nonparametric canonical correlation analysis, in International conference on machine learning, PMLR, 2016, pp. 1967–1976. [19]B. Øksendal,The ito formula and the martingale representation theorem, in Sto...
work page 1979
-
[7]
[24]R. Talmon and H.-T. Wu,Latent common manifold learning with alternating diffusion: Analysis and applications, Applied and Computational Harmonic Analysis, 47 (2019), pp. 848–892. [25]D. V. Widder,Functions harmonic in a strip, Proceedings of the American Mathematical Society, 12 (1961), pp. 67–72
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.