Calibrate-Then-Delegate: Safety Monitoring with Risk and Budget Guarantees via Model Cascades
Pith reviewed 2026-05-10 13:03 UTC · model grok-4.3
The pith
A delegation-value probe calibrated via multiple hypothesis testing enables model cascades that guarantee computation budgets while improving safety detection over uncertainty-based escalation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CTD builds on a novel delegation value probe that directly predicts the benefit of escalation to the expert model and calibrates a threshold on the DV signal via multiple hypothesis testing to yield finite-sample guarantees on the delegation rate under the data distribution encountered at deployment.
What carries the argument
The delegation value probe, a lightweight model operating on the same internal representations as the safety probe, which directly predicts escalation benefit and supports threshold calibration for budget control.
If this is right
- Safety monitoring accuracy improves at every fixed computation budget compared with uncertainty-based delegation.
- Over-delegation is reduced because escalation occurs only when the probe predicts a net benefit.
- Budget allocation automatically adapts to input difficulty in a streaming, per-instance fashion.
- Probabilistic guarantees on delegation rate hold without requiring group labels or distributional assumptions on subgroups.
Where Pith is reading between the lines
- The same DV-probe-plus-calibration pattern could be applied to other cost-sensitive decision cascades such as medical triage or autonomous system monitoring.
- If internal representations remain informative across model updates, the approach reduces the frequency of full expert calls in long-running production systems.
- The multiple hypothesis testing step could be reused for other finite-sample risk controls in sequential ML pipelines where exact budget adherence matters.
- Evaluating CTD across a wider range of base models and safety tasks would test whether the internal-representation assumption generalizes beyond the four datasets studied.
Load-bearing premise
The delegation value probe can reliably predict the actual benefit of escalation to the expert model on unseen instances, and the multiple hypothesis testing procedure yields valid finite-sample guarantees on the delegation rate.
What would settle it
Run the calibrated CTD on a fresh held-out sample drawn from the same distribution as the calibration set and check whether the observed delegation fraction exceeds the claimed probabilistic bound or whether safety metrics fail to exceed those of an uncertainty-based cascade at the same average budget.
Figures








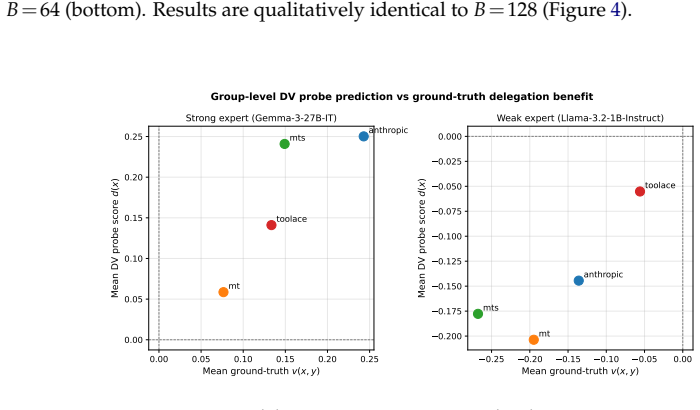




read the original abstract
Monitoring LLM safety at scale requires balancing cost and accuracy: a cheap latent-space probe can screen every input, but hard cases should be escalated to a more expensive expert. Existing cascades delegate based on probe uncertainty, but uncertainty is a poor proxy for delegation benefit, as it ignores whether the expert would actually correct the error. To address this problem, we introduce Calibrate-Then-Delegate (CTD), a model-cascade approach that provides probabilistic guarantees on the computation cost while enabling instance-level (streaming) decisions. CTD builds on a novel delegation value (DV) probe, a lightweight model operating on the same internal representations as the safety probe that directly predicts the benefit of escalation. To enforce budget constraints, CTD calibrates a threshold on the DV signal using held-out data via multiple hypothesis testing, yielding finite-sample guarantees on the delegation rate. Evaluated on four safety datasets, CTD consistently outperforms uncertainty-based delegation at every budget level, avoids harmful over-delegation, and adapts budget allocation to input difficulty without requiring group labels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Calibrate-Then-Delegate (CTD), a model-cascade framework for LLM safety monitoring. A lightweight delegation-value (DV) probe operating on the same internal representations as the safety model predicts the benefit of escalation to an expert; a threshold on the DV score is then calibrated on held-out data via multiple hypothesis testing to deliver finite-sample guarantees on the delegation (budget) rate. Experiments on four safety datasets report that CTD outperforms uncertainty-based delegation at every budget level, avoids harmful over-delegation, and allocates budget adaptively to input difficulty without requiring group labels.
Significance. If the DV probe generalizes and the multiple-hypothesis-testing calibration yields valid finite-sample control under deployment conditions, the work supplies a principled, instance-level mechanism that simultaneously improves safety performance and supplies explicit probabilistic budget guarantees—features that would be valuable for scalable, cost-controlled LLM safety pipelines.
major comments (3)
- [Abstract, §3] Abstract and §3 (Method): The central claim of 'finite-sample guarantees on the delegation rate' is asserted via multiple hypothesis testing on held-out data, yet no theorem statement, proof sketch, or explicit list of assumptions (i.i.d. sampling, no distribution shift between calibration and deployment) appears. Without this, it is impossible to verify whether the reported guarantees follow from the calibration procedure or survive the distribution shift that the skeptic correctly flags as a weakest assumption.
- [§3.2, §4] §4 (Experiments) and §3.2 (DV probe): The performance superiority at every budget level rests on the DV probe accurately predicting actual expert correction benefit on unseen instances. The manuscript supplies no calibration plots, correlation metrics, or ablation showing P(expert fixes error | DV score) on held-out or shifted data; the reported outperformance therefore cannot be separated from possible overfitting of the probe to the calibration distribution.
- [§4] §4 (Experiments): While consistent outperformance is claimed across four datasets, the text provides no statistical significance tests, standard-error bars across random seeds, or sensitivity analysis to the single free parameter (DV threshold). This leaves the robustness of the 'avoids harmful over-delegation' and 'adapts budget allocation' claims unverified.
minor comments (2)
- [Abstract] The abstract states results on 'four safety datasets' without naming them; the datasets should be identified in the abstract or first paragraph of the introduction.
- [§3] Notation for the DV probe output, calibrated threshold, and delegation indicator is introduced piecemeal; a compact symbol table would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of guarantees, probe validation, and experimental robustness.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Method): The central claim of 'finite-sample guarantees on the delegation rate' is asserted via multiple hypothesis testing on held-out data, yet no theorem statement, proof sketch, or explicit list of assumptions (i.i.d. sampling, no distribution shift between calibration and deployment) appears. Without this, it is impossible to verify whether the reported guarantees follow from the calibration procedure or survive the distribution shift that the skeptic correctly flags as a weakest assumption.
Authors: We agree that a formal theorem would improve verifiability. In the revised manuscript we will insert a theorem statement in §3 that precisely characterizes the finite-sample control on the delegation rate achieved by the multiple-hypothesis-testing threshold calibration. A proof sketch will be added to the appendix. The assumptions will be stated explicitly: (i) calibration samples are i.i.d. draws from the data-generating distribution, and (ii) deployment inputs are drawn from the same distribution (no shift). We will also note, as the skeptic already flags in the paper, that the no-shift assumption is the weakest link and that the guarantees are conditional on it; we will discuss sensitivity to mild shifts in the limitations section. revision: yes
-
Referee: [§3.2, §4] §4 (Experiments) and §3.2 (DV probe): The performance superiority at every budget level rests on the DV probe accurately predicting actual expert correction benefit on unseen instances. The manuscript supplies no calibration plots, correlation metrics, or ablation showing P(expert fixes error | DV score) on held-out or shifted data; the reported outperformance therefore cannot be separated from possible overfitting of the probe to the calibration distribution.
Authors: We will add, in the revised §4 and appendix, calibration plots of DV score versus observed expert benefit together with quantitative correlation metrics (Pearson and Spearman) computed on the held-out calibration split of each dataset. We will also include an ablation that reports the empirical probability that the expert corrects an error conditional on binned DV scores. While the four datasets already provide some distributional diversity, we acknowledge that explicit shifted-data experiments are absent; we will add a limitations paragraph discussing the risk of overfitting to the calibration distribution and the consequent need for periodic re-calibration in deployment. revision: yes
-
Referee: [§4] §4 (Experiments): While consistent outperformance is claimed across four datasets, the text provides no statistical significance tests, standard-error bars across random seeds, or sensitivity analysis to the single free parameter (DV threshold). This leaves the robustness of the 'avoids harmful over-delegation' and 'adapts budget allocation' claims unverified.
Authors: We will revise the experimental section to report standard-error bars computed over five independent random seeds for all curves. We will add paired statistical significance tests (t-tests with Bonferroni correction) comparing CTD against each baseline at every budget level. Finally, we will include a sensitivity analysis in the appendix that varies the DV threshold around the calibrated value and shows the resulting changes in delegation rate, safety improvement, and over-delegation metrics. These additions will directly substantiate the robustness claims. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper trains a delegation value (DV) probe on internal representations to predict escalation benefit (a distinct target from the safety probe's output), then applies multiple hypothesis testing on held-out data to calibrate a threshold and obtain finite-sample guarantees on delegation rate. This uses external calibration data and standard statistical procedures rather than reducing any claim to a fitted parameter or self-defined quantity by construction. No load-bearing self-citations, ansatzes, or renamings of known results are present in the described chain; the guarantees remain statistically grounded outside the model's internal fits.
Axiom & Free-Parameter Ledger
free parameters (1)
- DV threshold
axioms (1)
- domain assumption The DV probe produces a signal whose ordering reflects true escalation benefit on new inputs
invented entities (1)
-
Delegation Value (DV) probe
no independent evidence
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.