Recognition: unknown
Seeing Through Experts Eyes A Foundational Vision Language Model Trained on Radiologists Gaze and Reasoning
Pith reviewed 2026-05-10 13:11 UTC · model grok-4.3
The pith
A vision language model trained on radiologists' gaze patterns produces more accurate and verifiable chest X-ray interpretations by mimicking expert attention sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
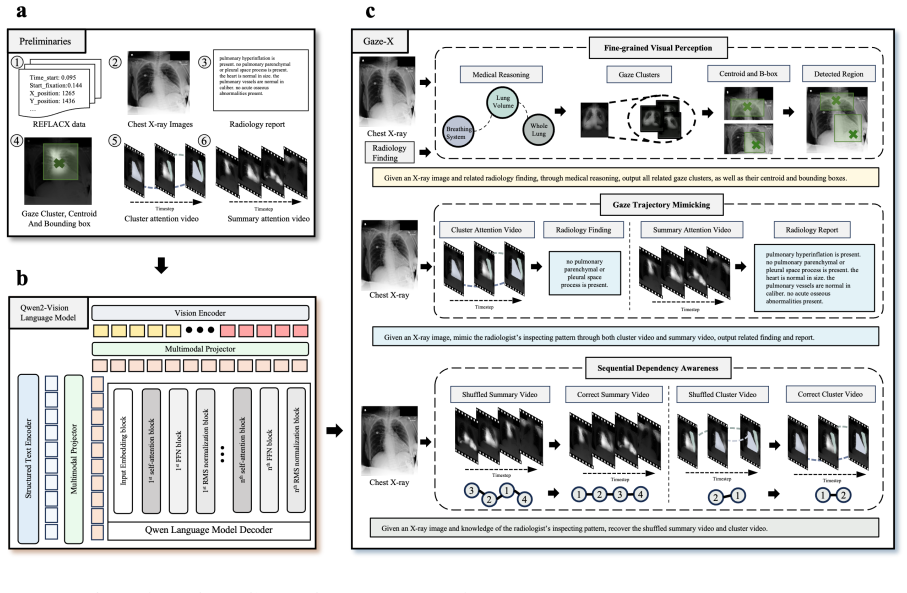
GazeX is a foundational vision language model that leverages radiologists' gaze trajectories and fixation patterns from five experts as a behavioral prior to model diagnostic reasoning. By integrating this data into pretraining on 231,835 radiographic studies along with question-answer pairs and bounding-box annotations, the model learns to examine images in a clinically meaningful sequence and produces outputs that are more accurate, interpretable, and consistent with expert practices across report generation, disease grounding, and visual question answering. Unlike standard systems, it generates evidence artifacts such as inspection trajectories and localized findings that enable efficient
What carries the argument
GazeX, the vision language model that treats radiologists' gaze trajectories and fixation patterns as a behavioral prior to guide spatial and temporal attention during image interpretation.
If this is right
- GazeX generates radiology reports with higher alignment to expert observations and fewer overlooked regions.
- The model produces localized bounding boxes for findings that link directly to its inspection sequence for verification.
- Outputs on visual question answering tasks become more consistent with how radiologists prioritize and sequence their attention.
- The system supplies inspection trajectories as artifacts that support efficient human review and collaboration rather than autonomous reporting.
Where Pith is reading between the lines
- Similar gaze-based priors could be collected and applied to train models for other imaging modalities such as CT or MRI.
- Enforcing systematic attention sequences might reduce the rate of missed diagnoses in high-volume screening settings even if overall accuracy metrics remain similar.
- The approach opens a path for adapting expert behavioral data to non-medical domains that rely on structured visual search, such as industrial inspection.
Load-bearing premise
Gaze patterns recorded from five radiologists provide a generalizable prior that improves performance on clinical tasks without embedding biases specific to those individuals or the imaging protocols used.
What would settle it
Evaluating GazeX on gaze data collected from a new, independent group of radiologists and checking whether the accuracy and consistency gains over a baseline model without gaze pretraining disappear.
Figures








read the original abstract
Large scale vision language models have shown promise in automating chest Xray interpretation, yet their clinical utility remains limited by a gap between model outputs and radiologist reasoning. Most systems optimize for semantic information without emulating how experts visually examine medical images, often overlooking critical findings or diverging from established diagnostic workflows. Radiologists follow structured protocols (e.g., the ABCDEF approach) that ensure all clinically relevant regions are systematically examined, reducing missed findings and supporting reliable diagnostic reasoning. We introduce GazeX, a vision language model that leverages radiologists' eye tracking data as a behavioral prior to model expert diagnostic reasoning. By incorporating gaze trajectories and fixation patterns into pretraining, GazeX learns to follow the spatial and temporal structure of radiologist attention and integrates observations in a clinically meaningful sequence. Using a curated dataset of over 30,000 gaze key frames from five radiologists, we demonstrate that GazeX produces more accurate, interpretable, and expert consistent outputs across radiology report generation, disease grounding, and visual question answering, utilizing 231,835 radiographic studies, 780,014 question answer pairs, and 1,162 image sentence pairs with bounding boxes. Unlike autonomous reporting systems, GazeX produces verifiable evidence artifacts, including inspection trajectories and finding linked localized regions, enabling efficient human verification and safe human AI collaboration. Learning through expert eyes provides a practical route toward more trustworthy, explainable, and diagnostically robust AI systems for radiology and beyond.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GazeX, a vision-language model that incorporates radiologists' eye-tracking gaze trajectories and fixation patterns as a behavioral prior during pretraining to emulate expert diagnostic reasoning on chest X-rays. Using a dataset of over 30,000 gaze key frames from five radiologists plus 231,835 radiographic studies, 780,014 QA pairs, and 1,162 image-sentence pairs with bounding boxes, it claims superior accuracy, interpretability, and expert consistency on report generation, disease grounding, and VQA, while generating verifiable inspection trajectories and localized findings for human-AI collaboration.
Significance. If the empirical claims are substantiated, the work could advance clinically aligned AI in medical imaging by bridging the gap between standard VLM optimization and structured expert workflows, offering a route to more explainable and verifiable systems that reduce missed findings and support safe collaboration.
major comments (3)
- [Abstract] Abstract: the claim that GazeX 'produces more accurate, interpretable, and expert consistent outputs' is unsupported by any quantitative metrics, baselines, error bars, statistical tests, or ablation results, making it impossible to evaluate whether the gaze prior contributes to the asserted gains.
- [Method] Method section: no equations, loss terms, or architectural details are supplied for how gaze trajectories and fixation patterns are mathematically incorporated as a behavioral prior (e.g., attention modulation, auxiliary loss, or sequence modeling), preventing assessment of technical soundness or reproducibility.
- [Experiments] Experiments: the central claim that gaze data from five radiologists supplies a transferable expert prior requires evidence of generalization; the manuscript provides no inter-radiologist agreement statistics, gaze-ablation studies, or held-out radiologist/external-site evaluations, leaving open the possibility that reported improvements reflect overfitting to the specific experts' idiosyncratic patterns rather than robust diagnostic reasoning.
minor comments (2)
- [Title] Title: 'Seeing Through Experts Eyes' is grammatically incomplete and should be 'Seeing Through Experts' Eyes'.
- [Abstract] Abstract: the listed dataset sizes lack explicit train/validation/test splits or usage breakdown across pretraining, fine-tuning, and evaluation stages.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us improve the clarity and rigor of our manuscript. We provide detailed responses to each major comment below and indicate the revisions made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that GazeX 'produces more accurate, interpretable, and expert consistent outputs' is unsupported by any quantitative metrics, baselines, error bars, statistical tests, or ablation results, making it impossible to evaluate whether the gaze prior contributes to the asserted gains.
Authors: We agree that the abstract should better reflect the empirical support. The full manuscript includes quantitative evaluations in the Experiments section with metrics for report generation (e.g., BLEU, ROUGE), disease grounding (IoU), and VQA accuracy, along with baseline comparisons. To address the concern, we have revised the abstract to incorporate key quantitative results, including specific improvements over baselines and references to tables with error bars and statistical tests. This makes the claims directly supported by the presented evidence. revision: yes
-
Referee: [Method] Method section: no equations, loss terms, or architectural details are supplied for how gaze trajectories and fixation patterns are mathematically incorporated as a behavioral prior (e.g., attention modulation, auxiliary loss, or sequence modeling), preventing assessment of technical soundness or reproducibility.
Authors: We acknowledge this omission in the original submission. In the revised manuscript, we have substantially expanded the Method section to include the mathematical details. We now provide the equations for the gaze-augmented pretraining objective, which combines the standard vision-language modeling loss with an auxiliary gaze prediction loss that encourages the model to predict fixation sequences. Additionally, we describe the architectural integration where gaze trajectories are processed through a dedicated encoder and used to modulate cross-attention layers in the vision-language transformer. Pseudocode and implementation details are included to ensure reproducibility. revision: yes
-
Referee: [Experiments] Experiments: the central claim that gaze data from five radiologists supplies a transferable expert prior requires evidence of generalization; the manuscript provides no inter-radiologist agreement statistics, gaze-ablation studies, or held-out radiologist/external-site evaluations, leaving open the possibility that reported improvements reflect overfitting to the specific experts' idiosyncratic patterns rather than robust diagnostic reasoning.
Authors: We appreciate the referee highlighting the need for stronger evidence of generalization. In the revised manuscript, we have added inter-radiologist agreement statistics, computed as average overlap in fixation maps (Jaccard index of 0.68), demonstrating consistency among the five experts. We have also included ablation studies that isolate the contribution of the gaze prior, showing performance degradation when it is removed. Regarding held-out radiologist or external-site evaluations, our current dataset is limited to the five radiologists from a single institution; we have added this as an explicit limitation in the Discussion section and outline plans for future multi-site validation. We believe the ablations and agreement stats provide initial support for the prior's value beyond idiosyncrasies. revision: partial
- The absence of held-out radiologist or external-site evaluations, which would require new data collection not feasible in the current revision.
Circularity Check
No significant circularity; derivation relies on independent external gaze data as input
full rationale
The paper introduces GazeX by training on an external curated dataset of over 30,000 gaze key frames from five radiologists plus large radiographic studies and QA pairs. The abstract describes incorporating gaze trajectories as a behavioral prior into pretraining, followed by empirical evaluation on report generation, grounding, and VQA. No equations, self-definitional reductions, fitted parameters presented as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on independent data collection and downstream task performance rather than any tautological loop back to model outputs or prior author results.
Axiom & Free-Parameter Ledger
free parameters (1)
- Gaze integration hyperparameters
axioms (1)
- domain assumption Radiologist gaze patterns reflect systematic and optimal diagnostic reasoning that can be transferred to improve model outputs
Reference graph
Works this paper leans on
-
[1]
& Zhou, L
Wang, Z., Han, H., Wang, L., Li, X. & Zhou, L. Automated radiographic report generation purely on transformer: A multicriteria supervised approach.IEEE Transactions on Medical Imaging41, 2803–2813 (2022)
2022
-
[2]
Moor, M.et al.Foundation models for generalist medical artificial intelligence.Nature616, 259–265 (2023)
2023
-
[3]
Liu, F.et al.A multimodal multidomain multilingual medical foundation model for zero shot clinical diagnosis.npj Digital Medicine8, 86 (2025)
2025
-
[4]
Yang, S.et al.Radiology report generation with a learned knowledge base and multi-modal align- ment.Medical Image Analysis86, 102798 (2023)
2023
-
[5]
Gao, D.et al.Simulating doctors’ thinking logic for chest x-ray report generation via transformer- based semantic query learning.Medical Image Analysis91, 102982 (2024)
2024
-
[6]
M., van Geel, K
Nobel, J. M., van Geel, K. & Robben, S. G. Structured reporting in radiology: a systematic review to explore its potential.European radiology32, 2837–2854 (2022)
2022
-
[7]
Hosny, A., Parmar, C., Quackenbush, J., Schwartz, L. H. & Aerts, H. J. Artificial intelligence in radiology.Nature Reviews Cancer18, 500–510 (2018)
2018
-
[8]
Tanno, R.et al.Collaboration between clinicians and vision–language models in radiology report generation.Nature Medicine31, 599–608 (2025)
2025
-
[9]
Neves, J.et al.Shedding light on ai in radiology: A systematic review and taxonomy of eye gaze-driven interpretability in deep learning.European Journal of Radiology172, 111341 (2024)
2024
-
[10]
Awasthi, A.et al.Modeling radiologists’ cognitive processes using a digital gaze twin to enhance radiology training.Scientific reports15, 13685 (2025)
2025
-
[11]
D.Chest X-rays for Medical Students(Wiley–Blackwell, 2011)
Christopher Clarke, A. D.Chest X-rays for Medical Students(Wiley–Blackwell, 2011)
2011
-
[12]
Kool, D. R. & Blickman, J. G. Advanced trauma life support®. abcde from a radiological point of view.Emergency radiology14, 135–141 (2007)
2007
-
[13]
Ma, C.et al.Eye-gaze guided multi-modal alignment for medical representation learning.Ad- vances in Neural Information Processing Systems37, 6126–6153 (2024)
2024
-
[14]
Awasthi, A., Le, N., Deng, Z., Wu, C. C. & Nguyen, H. V . Collaborative integration of ai and human expertise to improve detection of chest radiograph abnormalities.Radiology: Artificial Intelligencee240277 (2025)
2025
-
[15]
Dong, F., Nie, S., Chen, M., Xu, F. & Li, Q. Keyword-based ai assistance in the generation of radiology reports: A pilot study.npj Digital Medicine8, 490 (2025)
2025
-
[16]
Wang, X.et al.A survey of deep-learning-based radiology report generation using multimodal inputs.Medical Image Analysis103627 (2025)
2025
-
[17]
& Koo, C
Milam, M. & Koo, C. The current status and future of fda-approved artificial intelligence tools in chest radiology in the united states.Clinical Radiology78, 115–122 (2023)
2023
-
[18]
Yu, F.et al.Evaluating progress in automatic chest x-ray radiology report generation.Patterns4 (2023). 21
2023
-
[19]
Li, S.et al.An organ-aware diagnosis framework for radiology report generation.IEEE Transac- tions on Medical Imaging43, 4253–4265 (2024)
2024
-
[20]
K.et al.Diagnostic accuracy and clinical value of a domain-specific multimodal genera- tive ai model for chest radiograph report generation.Radiology314, e241476 (2025)
Hong, E. K.et al.Diagnostic accuracy and clinical value of a domain-specific multimodal genera- tive ai model for chest radiograph report generation.Radiology314, e241476 (2025)
2025
-
[21]
& Wan, X
Chen, Z., Song, Y ., Chang, T.-H. & Wan, X. Generating radiology reports via memory-driven transformer. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing(2020)
2020
-
[22]
& Wan, X
Chen, Z., Shen, Y ., Song, Y . & Wan, X. Cross-modal memory networks for radiology report generation. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics, 5904–5914 (Association for Computational Linguistics, 2021)
2021
-
[23]
Yang, S., Wu, X., Ge, S., Zhou, S. K. & Xiao, L. Knowledge matters: Chest radiology report generation with general and specific knowledge.Medical image analysis80, 102510 (2022)
2022
-
[24]
J.et al.Computational anatomy for multi-organ analysis in medical imaging: A review.Medical Image Analysis56, 44–67 (2019)
Cerrolaza, J. J.et al.Computational anatomy for multi-organ analysis in medical imaging: A review.Medical Image Analysis56, 44–67 (2019)
2019
-
[25]
E.et al.Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports.Scientific data6, 317 (2019)
Johnson, A. E.et al.Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports.Scientific data6, 317 (2019)
2019
-
[26]
Demner-Fushman, D.et al.Preparing a collection of radiology examinations for distribution and retrieval.Journal of the American Medical Informatics Association23, 304–310 (2016)
2016
-
[27]
& Rueckert, D
Tanida, T., M ¨uller, P., Kaissis, G. & Rueckert, D. Interactive and explainable region-guided ra- diology report generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7433–7442 (2023)
2023
-
[28]
IEEE Transactions on Medical Imaging44, 2892–2905 (2025)
Yang, Y .et al.Spatio-temporal and retrieval-augmented modeling for chest x-ray report generation. IEEE Transactions on Medical Imaging44, 2892–2905 (2025)
2025
-
[29]
Hu, X.et al.Interpretable medical image visual question answering via multi-modal relationship graph learning.Medical Image Analysis97, 103279 (2024)
2024
- [30]
-
[31]
InEuropean conference on computer vision, 1–21 (Springer, 2022)
Boecking, B.et al.Making the most of text semantics to improve biomedical vision–language processing. InEuropean conference on computer vision, 1–21 (Springer, 2022)
2022
-
[32]
& Rueckert, D
M ¨uller, P., Kaissis, G. & Rueckert, D. Chex: Interactive localization and region description in chest x-rays. InEuropean Conference on Computer Vision, 92–111 (Springer, 2024)
2024
-
[33]
Deng, J., Yang, Z., Chen, T., Zhou, W. & Li, H. Transvg: End-to-end visual grounding with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, 1769–1779 (2021)
2021
-
[34]
Cid, Y . D.et al.Development and validation of open-source deep neural networks for comprehen- sive chest x-ray reading: a retrospective, multicentre study.The Lancet Digital Health6, e44–e57 (2024)
2024
-
[35]
Du, C.et al.Human-like object concept representations emerge naturally in multimodal large language models.Nature Machine Intelligence1–16 (2025). 22
2025
-
[36]
Doerig, A.et al.High-level visual representations in the human brain are aligned with large language models.Nature Machine Intelligence1–15 (2025)
2025
-
[37]
J.et al.LoRA: Low-rank adaptation of large language models
Hu, E. J.et al.LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations(2022)
2022
-
[38]
Ester, M., Kriegel, H.-P., Sander, J. & Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. InProceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, 226–231 (AAAI Press, 1996)
1996
-
[39]
& Zhou, L
Wang, Z., Liu, L., Wang, L. & Zhou, L. R2gengpt: Radiology report generation with frozen llms. Meta-Radiology1, 100033 (2023)
2023
-
[40]
& Chen, H
Jin, H., Che, H., Lin, Y . & Chen, H. Promptmrg: diagnosis-driven prompts for medical report generation. InProceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence(AAAI Press, 2024)
2024
-
[41]
InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23 (Curran Associates Inc., 2023)
Li, C.et al.Llava-med: training a large language-and-vision assistant for biomedicine in one day. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23 (Curran Associates Inc., 2023)
2023
-
[42]
Wu, C.et al.Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data.Nature Communications16, 7866 (2025)
2025
- [43]
-
[44]
Contactdoctor-bio-medical-multimodal-llama-3-8b-v1: A high-performance biomedical multimodal llm (2024)
ContactDoctor. Contactdoctor-bio-medical-multimodal-llama-3-8b-v1: A high-performance biomedical multimodal llm (2024)
2024
-
[45]
Medgemma hugging face (2025)
Google. Medgemma hugging face (2025). Accessed: [Insert Date Accessed, e.g., 2025-05-20]
2025
-
[46]
Xu, W.et al.Lingshu: A generalist foundation model for unified multimodal medical understand- ing and reasoning.arXiv preprint arXiv:2506.07044(2025)
work page internal anchor Pith review arXiv 2025
-
[47]
& Zhu, W.-J
Papineni, K., Roukos, S., Ward, T. & Zhu, W.-J. Bleu: a method for automatic evaluation of ma- chine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, 311–318 (2002)
2002
-
[48]
& Agarwal, A
Lavie, A. & Agarwal, A. METEOR: An automatic metric for MT evaluation with high levels of correlation with human judgments. InProceedings of the Second Workshop on Statistical Machine Translation, 228–231 (Association for Computational Linguistics, 2007)
2007
-
[49]
Rouge: A package for automatic evaluation of summaries
Lin, C.-Y . Rouge: A package for automatic evaluation of summaries. InText summarization branches out, 74–81 (2004)
2004
-
[50]
InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1500–1519 (Association for Computational Linguistics, 2020)
Smit, A.et al.Combining automatic labelers and expert annotations for accurate radiology report labeling using BERT. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1500–1519 (Association for Computational Linguistics, 2020). 23 5 Data availability All the datasets we use are listed in Methods and are publ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.