Recognition: unknown
Purging the Gray Zone: Latent-Geometric Denoising for Precise Knowledge Boundary Awareness
Pith reviewed 2026-05-10 13:46 UTC · model grok-4.3
The pith
Geometric denoising in latent space removes ambiguous samples to let language models recognize their own knowledge limits more accurately.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper reveals a gray zone of internal belief ambiguity near the decision hyperplane in latent space that creates label noise during abstention fine-tuning. By constructing a truth hyperplane via linear probes and treating geometric distance as a confidence signal, the GeoDe method filters out these boundary samples while retaining high-fidelity ones, enabling more precise knowledge boundary awareness and improved truthfulness with strong out-of-distribution generalization.
What carries the argument
The GeoDe framework, which builds a truth hyperplane from linear probes on activations and uses geometric distance to purge gray-zone samples during abstention fine-tuning.
If this is right
- Models trained this way produce fewer hallucinations on factual question-answering tasks.
- Abstention behavior improves without requiring changes to model architecture.
- The cleaned training signals support better generalization to questions outside the original training distribution.
- High-confidence samples are preserved, so overall learning capacity is not reduced.
Where Pith is reading between the lines
- The same latent-distance approach could be tested on tasks beyond question answering, such as code completion or dialogue safety, where uncertainty must also be expressed.
- Persistent gray zones across training runs would imply that some knowledge ambiguity is structural rather than purely a data-partitioning problem.
- Extending the method to nonlinear boundaries or multiple probe layers might capture subtler forms of internal conflict.
Load-bearing premise
The main performance bottleneck comes from ambiguous samples clustered near the decision hyperplane, and these can be cleanly identified and removed using linear probes plus geometric distance without discarding useful information or adding new biases.
What would settle it
If a model fine-tuned on the GeoDe-filtered dataset shows no reduction in hallucinations or no gain in abstention accuracy compared with a model trained on the same data partitioned only by response correctness, the geometric denoising step would be shown to add no value.
Figures



read the original abstract
Large language models (LLMs) often exhibit hallucinations due to their inability to accurately perceive their own knowledge boundaries. Existing abstention fine-tuning methods typically partition datasets directly based on response accuracy, causing models to suffer from severe label noise near the decision boundaries and consequently exhibit high rates of abstentions or hallucinations. This paper adopts a latent space representation perspective, revealing a "gray zone" near the decision hyperplane where internal belief ambiguity constitutes the core performance bottleneck. Based on this insight, we propose the **GeoDe** (**Geo**metric **De**noising) framework for abstention fine-tuning. This method constructs a truth hyperplane using linear probes and performs "geometric denoising" by employing geometric distance as a confidence signal for abstention decisions. This approach filters out ambiguous boundary samples while retaining high-fidelity signals for fine-tuning. Experiments across multiple models (Llama3, Qwen3) and benchmark datasets (TriviaQA, NQ, SciQ, SimpleQA) demonstrate that GeoDe significantly enhances model truthfulness and demonstrates strong generalization in out-of-distribution (OOD) scenarios. Code is available at https://github.com/Notbesidemoon/GeoDe.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the GeoDe framework for abstention fine-tuning in LLMs to address hallucinations from poor knowledge boundary perception. It identifies a 'gray zone' of internal belief ambiguity near the decision hyperplane in latent space by fitting linear probes to construct a truth hyperplane, then applies geometric distance-based filtering to remove ambiguous boundary samples while retaining high-fidelity signals. Experiments across Llama3 and Qwen3 models on TriviaQA, NQ, SciQ, and SimpleQA datasets claim significant improvements in truthfulness and strong OOD generalization.
Significance. If the central claims hold, GeoDe could meaningfully advance abstention techniques by providing a latent-geometric alternative to accuracy-based data partitioning, reducing label noise near boundaries. The multi-model and multi-dataset evaluation plus public code availability are positive elements that would support broader adoption if the method's assumptions are validated.
major comments (3)
- [Abstract and §3] Abstract and §3 (Method): The core mechanism relies on linear probes to define the truth hyperplane and Euclidean (or similar) distance to purge the gray zone, but no probe classification accuracy, separability metrics, or held-out validation results are reported. This leaves open whether the distance signal reliably isolates ambiguity or simply reflects probe fitting artifacts, directly undermining the claim that geometric denoising avoids the label noise of prior methods.
- [§4] §4 (Experiments): The gray zone distance threshold is listed as a free parameter with no sensitivity analysis, cross-dataset selection procedure, or ablation showing its effect on the reported truthfulness gains and OOD results (e.g., on SimpleQA). Without this, it is unclear whether the improvements are robust or depend on dataset-specific tuning that could limit generalization.
- [§4.3] §4.3 (OOD evaluation): The strong generalization claim would require an ablation comparing linear probes against non-linear alternatives (e.g., kernel or MLP probes) to test the separability assumption. If the knowledge boundary is entangled or non-linear in representation space, distance-based filtering may discard useful signal or retain noise, weakening both in-distribution and OOD results.
minor comments (3)
- [§2] The introduction of the 'gray zone' concept would benefit from a formal mathematical definition or equation early in §2 or §3 rather than a purely descriptive treatment.
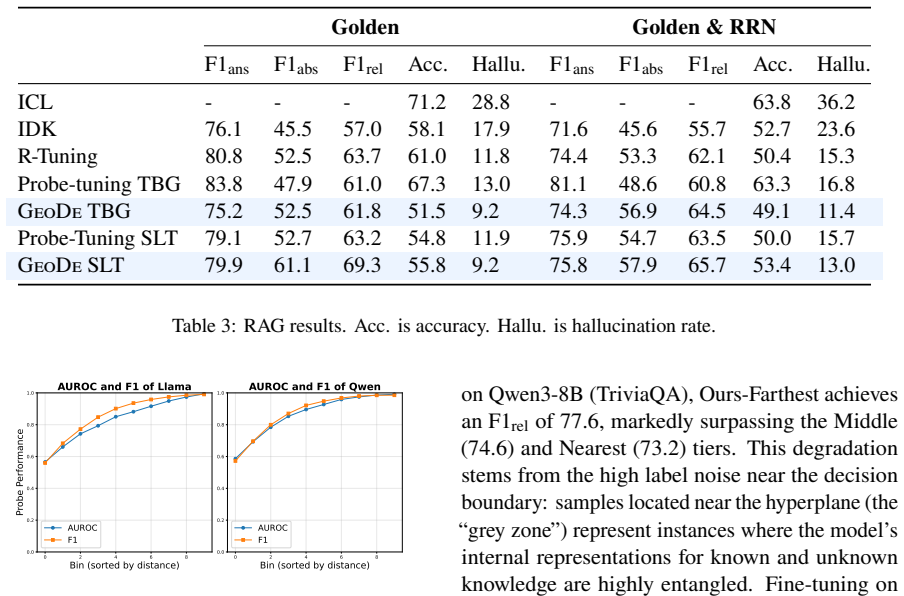
- [Figures] Figure captions and axis labels in the experimental results could more explicitly indicate which models and datasets correspond to each panel for quicker reader comprehension.
- [Related Work] A few citations to recent abstention or uncertainty estimation works (e.g., on probe-based confidence) appear missing from the related work section.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and will incorporate revisions to strengthen the empirical validation of the method.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): The core mechanism relies on linear probes to define the truth hyperplane and Euclidean (or similar) distance to purge the gray zone, but no probe classification accuracy, separability metrics, or held-out validation results are reported. This leaves open whether the distance signal reliably isolates ambiguity or simply reflects probe fitting artifacts, directly undermining the claim that geometric denoising avoids the label noise of prior methods.
Authors: We acknowledge that explicit probe accuracy and separability metrics were not reported in the original manuscript. The downstream gains in truthfulness and OOD performance provide indirect support, but we agree this is insufficient to rule out fitting artifacts. In the revision we will add a dedicated paragraph in §3 reporting probe classification accuracy on held-out validation splits for each model-dataset pair, plus separability metrics (e.g., decision margin and distance-to-boundary correlation with label noise). These additions will directly address the concern. revision: yes
-
Referee: [§4] §4 (Experiments): The gray zone distance threshold is listed as a free parameter with no sensitivity analysis, cross-dataset selection procedure, or ablation showing its effect on the reported truthfulness gains and OOD results (e.g., on SimpleQA). Without this, it is unclear whether the improvements are robust or depend on dataset-specific tuning that could limit generalization.
Authors: The threshold was selected via validation performance, yet we did not present sensitivity results. We will add an ablation subsection (and corresponding figure) in §4 that varies the threshold across a range for all datasets, including SimpleQA, and reports the resulting truthfulness and abstention rates. This will demonstrate stability within a reasonable interval and clarify the selection procedure. revision: yes
-
Referee: [§4.3] §4.3 (OOD evaluation): The strong generalization claim would require an ablation comparing linear probes against non-linear alternatives (e.g., kernel or MLP probes) to test the separability assumption. If the knowledge boundary is entangled or non-linear in representation space, distance-based filtering may discard useful signal or retain noise, weakening both in-distribution and OOD results.
Authors: We chose linear probes to maintain an interpretable hyperplane and because prior literature on LLM representations indicates that many semantic distinctions, including knowledge boundaries, are approximately linearly separable. We did not run non-linear probe ablations due to scope and compute limits. In the revision we will expand §4.3 with a discussion of this assumption, supported by citations, and note that non-linear probes risk overfitting to noise near the boundary. A limited appendix comparison on one model is feasible and will be included if space permits. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper proposes fitting linear probes on latent activations labeled by response accuracy to define a truth hyperplane, then using Euclidean (or similar) distance to that hyperplane as a filtering signal for 'gray zone' samples during abstention fine-tuning. This is a standard data-driven probing technique followed by downstream application; the probe fit is not renamed or re-presented as a prediction, nor does any claimed result reduce to the input labels by construction. Evaluation occurs on held-out benchmarks (TriviaQA, NQ, SciQ, SimpleQA) across models, providing external validation separate from the probe training. No self-citations, uniqueness theorems, or ansatzes are invoked to justify core steps. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- gray zone distance threshold
axioms (1)
- domain assumption Linear probes can construct an accurate truth hyperplane separating known from unknown in the model's latent space.
invented entities (1)
-
gray zone
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ontheuniversaltruthfulnesshyperplaneinside LLMs. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 18199–18224, Miami, Florida, USA. Associa- tion for Computational Linguistics. Samuel Marks and Max Tegmark. 2024. The geometry of truth: Emergent linear structure in large language model representations of true/...
-
[2]
Measuring short-form factuality in large language models
Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems, volume 36, pages 53728–53741. Curran Associates, Inc. Aviv Slobodkin, Omer Goldman, Avi Caciularu, Ido Dagan, and Shauli Ravfogel. 2023. The curious case of hallucinatory (un)answerability: Finding truths in the hidden state...
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.