ToxiShield: Promoting Inclusive Developer Communication through Real-Time Toxicity Filtering
Pith reviewed 2026-05-10 12:38 UTC · model grok-4.3
The pith
A browser extension detects toxic code review comments and generates constructive rewrites in real time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
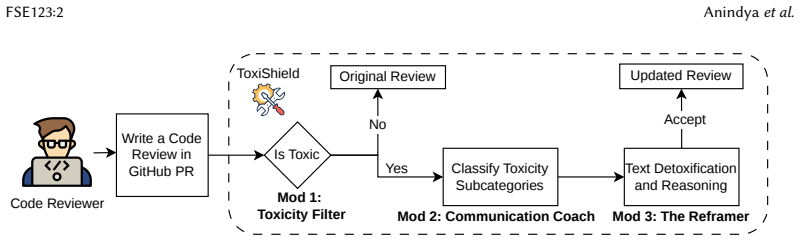
ToxiShield provides a three-part system for GitHub pull requests: a BERT model that flags toxic text, an LLM that assigns fine-grained toxicity categories with explanations, and a fine-tuned Llama model that rewrites toxic comments into constructive alternatives. The authors select the best-performing versions of each component after training on thousands of real code review samples and confirm the overall tool through automated accuracy metrics plus a Technology Acceptance Model survey with ten participants.
What carries the argument
The Reframer module, which takes toxic code review text and produces a revised version that maintains technical content while shifting to a non-toxic, fluent style through fine-tuning on labeled examples.
If this is right
- Developers receive immediate, in-context suggestions that let them revise comments before posting, lowering the chance of escalating conflicts.
- The categorization step supplies concrete reasons for flagged text, giving users repeated practice in recognizing and avoiding toxic patterns.
- Wider use in open source repositories could increase retention of contributors who might otherwise leave after negative review experiences.
- The browser-extension format shows a practical path for adding similar support features directly into existing collaboration platforms.
Where Pith is reading between the lines
- The same detection and rewriting pipeline could be adapted to other developer channels such as commit messages or issue threads without major redesign.
- Over time, repeated exposure to reframed examples might gradually change default communication habits across entire teams or projects.
- Pairing the reframer with static analysis tools could add a check that rewritten comments still accurately describe the technical point under discussion.
Load-bearing premise
The models will keep identifying toxicity correctly and producing useful rewrites when they encounter new comments from projects and developers outside the original training data.
What would settle it
Apply the full ToxiShield pipeline to several hundred recent GitHub pull request comments never seen during training and measure whether human reviewers agree with its toxicity flags and rephrasings at rates substantially above random chance.
Figures





read the original abstract
Toxic interactions during code reviews can undermine teamwork and hinder productivity in software engineering (SE) teams. While prior studies explore toxicity detection and empirical investigation, they lack real-time detoxification tools to support the SE community. To address this gap, we present ToxiShield, a browser extension for GitHub pull requests that is built using three modules: i) Toxicity Filter -- to identify whether a text is toxic, ii) Communication coach -- to facilitate just-in-time fine-grained toxicity categorization with explanations, and iii) The Reframer -- that generates a revised, constructive alternative of a toxic text. For each module, we trained and evaluated multiple deep learning and Large Language Models (LLMs) to identify the best choice. A BERT-based binary detection model, trained on 38,761 code review samples, achieves 98% accuracy and an F1-score of 97% and is the selected one for the Toxicity Filter module. For the Communication Coach, prompt-tuned Claude 3.5 Sonnet achieved the best performance with 39% MCC and 42% F1 in multiclass toxicity classification with detailed reasoning. For Reframer, we evaluated five LLMs using a fine-tuning strategy on a dataset of 10,120 code review comments. The fine-tuned Llama 3.2 model achieves 95.27% style transfer accuracy, 97.03% fluency, 67.07% content preservation, and an 84% J-score. We further validated ToxiShield through a human evaluation using the Technology Acceptance Model with 10 participants, confirming its perceived usefulness and ease of adoption. ToxiShield sets a benchmark for advancing constructive communication in software engineering, driving inclusivity and healthier collaboration in open-source communities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ToxiShield, a browser extension for GitHub pull requests comprising three modules: a BERT-based Toxicity Filter (98% accuracy, 97% F1 on 38,761 code review samples), a prompt-tuned Claude 3.5 Sonnet Communication Coach (39% MCC, 42% F1 for multiclass categorization), and a fine-tuned Llama 3.2 Reframer (95.27% style transfer accuracy, 84% J-score on 10,120 samples). It also reports a Technology Acceptance Model human evaluation with 10 participants confirming perceived usefulness and ease of use. The work positions the tool as a benchmark for real-time detoxification to promote inclusive developer communication.
Significance. If the reported performance generalizes, ToxiShield offers a practical, integrated system for toxicity detection, explanation, and constructive reframing directly in code review workflows, addressing a gap in SE tooling. The concrete dataset sizes, multi-model evaluation, and small-scale TAM validation provide a starting point for deployment-oriented research. The combination of filter + coach + reframer is a strength, but the absence of out-of-distribution testing on live GitHub data limits claims about real-world effectiveness.
major comments (2)
- [Abstract] Abstract and Evaluation sections: All performance figures (BERT 98% accuracy/97% F1, Claude 39% MCC, Llama 95.27% style-transfer/84% J-score) are obtained from internal train/test splits of the curated corpora. No baseline comparisons (e.g., against prior toxicity detectors or simpler classifiers), statistical significance tests, confidence intervals, or details on annotation quality and data splits are provided, making it impossible to judge whether the selected models are meaningfully superior or reliable.
- [Evaluation] Deployment and Evaluation sections: The central claim that ToxiShield enables effective real-time filtering, categorization, and reframing inside actual GitHub pull requests is not supported by any held-out evaluation on heterogeneous, temporally current GitHub threads (different projects, languages, reviewer styles, or temporal drift). Toxicity labels and constructive rewrites are context-sensitive; performance on the paper's internal distributions does not establish behavior on the deployment distribution targeted by the browser extension.
minor comments (2)
- [Abstract] Abstract: The phrase 'sets a benchmark' is not justified by the reported experiments; consider rephrasing to 'provides an initial integrated prototype' or similar.
- [Human Evaluation] The human evaluation description (10 participants, TAM) lacks details on participant recruitment, task instructions, and statistical analysis of the survey responses.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important aspects of evaluation rigor and real-world applicability. We address each major comment below and describe the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and Evaluation sections: All performance figures (BERT 98% accuracy/97% F1, Claude 39% MCC, Llama 95.27% style-transfer/84% J-score) are obtained from internal train/test splits of the curated corpora. No baseline comparisons (e.g., against prior toxicity detectors or simpler classifiers), statistical significance tests, confidence intervals, or details on annotation quality and data splits are provided, making it impossible to judge whether the selected models are meaningfully superior or reliable.
Authors: We agree that the current evaluation would be strengthened by explicit baseline comparisons, statistical significance testing, confidence intervals, and fuller details on annotation processes and data splits. In the revised manuscript we will add (1) comparisons against simpler classifiers (e.g., logistic regression on TF-IDF) and representative prior toxicity detectors, (2) McNemar or paired t-tests with p-values, (3) 95% confidence intervals via bootstrapping, and (4) expanded description of the annotation protocol, inter-annotator agreement, and train/validation/test split ratios. These additions will allow readers to better assess model reliability and superiority. revision: yes
-
Referee: [Evaluation] Deployment and Evaluation sections: The central claim that ToxiShield enables effective real-time filtering, categorization, and reframing inside actual GitHub pull requests is not supported by any held-out evaluation on heterogeneous, temporally current GitHub threads (different projects, languages, reviewer styles, or temporal drift). Toxicity labels and constructive rewrites are context-sensitive; performance on the paper's internal distributions does not establish behavior on the deployment distribution targeted by the browser extension.
Authors: We acknowledge that the reported metrics derive from curated, internal train/test splits rather than live, temporally current GitHub threads spanning diverse projects and reviewer styles. The datasets themselves consist of real code-review comments, and the 10-participant TAM study provides evidence of perceived usefulness in a realistic usage scenario. In revision we will (1) add an explicit limitations subsection discussing the gap between curated and live distributions, (2) report any available qualitative observations from the TAM sessions that touched on context sensitivity, and (3) outline concrete plans for future deployment studies. We cannot, however, retroactively supply new held-out live-GitHub results within the current revision cycle. revision: partial
Circularity Check
No circularity: standard empirical ML training and evaluation
full rationale
The paper presents an applied system built from three independently trained models (BERT binary classifier on 38,761 samples, prompt-tuned Claude for multiclass, fine-tuned Llama 3.2 on 10,120 samples) whose performance numbers are obtained via conventional train/test splits and a 10-participant TAM study. No equations, derivations, uniqueness theorems, or self-citations are invoked to justify the central claims; each reported metric follows directly from the training procedure and external human ratings without reducing to a definitional loop or fitted-input renaming.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026.ToxiShield: Replication Package
Md Awsaf Alam Anindya, Showvik Biswas, Anindya Iqbal, Jaydeb Sarker, and Amiangshu Bosu. 2026.ToxiShield: Replication Package. https://github.com/WSU-SEAL/ToxiShield
work page 2026
-
[2]
Sarthak Bharadwaj, Fabio Santos, and Bianca Trinkenreich. 2025. The Shifting Sands of Toxicity: The Evolving Nature of Interpersonal Challenges in Open Source. In2025 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM). 1–11. doi:10.1109/ESEM64174.2025.00016
-
[3]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology.Qualitative research in psychology3, 2 (2006), 77–101
work page 2006
-
[4]
Kevin Daniel André Carillo, Josianne Marsan, and Bogdan Negoita. 2016. Towards developing a theory of toxicity in the context of free/open source software & peer production communities.SIGOPEN 2016(2016)
work page 2016
-
[5]
Ofer Dekel and Ohad Shamir. 2010. Multiclass-multilabel classification with more classes than examples. InProceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, 137–144
work page 2010
-
[6]
Tanni Dev, Sayma Sultana, and Amiangshu Bosu. 2025. Beyond Binary Moderation: Identifying Fine-Grained Sexist and Misogynistic Behavior on GitHub with Large Language Models. In2025 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM)(Honolulu, Hawai, USA, USA). 1–12. doi:10.1109/ESEM64174.2025.00059
-
[7]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186. doi:10.18653...
-
[8]
Carolyn D Egelman, Emerson Murphy-Hill, Elizabeth Kammer, Margaret Morrow Hodges, Collin Green, Ciera Jaspan, and James Lin. 2020. Predicting developers’ negative feelings about code review. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering. 174–185. doi:10.1145/3377811.3380414
-
[9]
Ramtin Ehsani, Mia Mohammad Imran, Robert Zita, Kostadin Damevski, and Preetha Chatterjee. 2024. Incivility in open source projects: A comprehensive annotated dataset of locked github issue threads. InProceedings of the 21st International Conference on Mining Software Repositories. 515–519. doi:10.1145/3643991.3644887
-
[10]
Ramtin Ehsani, Rezvaneh Rezapour, and Preetha Chatterjee. 2023. Exploring moral principles exhibited in oss: A case study on github heated issues. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 2092–2096
work page 2023
-
[11]
Ramtin Ehsani, Rezvaneh Rezapour, and Preetha Chatterjee. 2025. Analyzing Toxicity in Open Source Software Communications Using Psycholinguistics and Moral Foundations Theory. (2025), 1–8. doi:10.1109/NLBSE66842.2025. 00006
-
[12]
Laura Faulkner. 2003. Beyond the five-user assumption: Benefits of increased sample sizes in usability testing.Behavior Research Methods, Instruments, & Computers35, 3 (2003), 379–383. doi:10.3758/BF03195514
-
[13]
Isabella Ferreira, Jinghui Cheng, and Bram Adams. 2021. The" shut the f** k up" phenomenon: Characterizing incivility in open source code review discussions.Proceedings of the ACM on Human-Computer Interaction5, CSCW2 (2021), 1–35. doi:10.1145/3479497
-
[14]
Isabella Ferreira, Ahlaam Rafiq, and Jinghui Cheng. 2024. Incivility detection in open source code review and issue discussions.Journal of Systems and Software209 (2024), 111935. doi:10.1016/j.jss.2023.111935
-
[15]
Zhenxin Fu, Xiaoye Tan, Nanyun Peng, Dongyan Zhao, and Rui Yan. 2018. Style transfer in text: Exploration and evaluation. InProceedings of the AAAI conference on artificial intelligence, Vol. 32. doi:10.1609/aaai.v32i1.11330
-
[16]
Shai Gretz, Alon Halfon, Ilya Shnayderman, Orith Toledo-Ronen, Artem Spector, Lena Dankin, Yannis Katsis, Ofir Arviv, Yoav Katz, Noam Slonim, and Liat Ein-Dor. 2023. Zero-shot Topical Text Classification with LLMs - an Experimental Study. InFindings of the Association for Computational Linguistics: EMNLP 2023. Association for Computational Linguistics, 96...
-
[17]
Sanuri Dananja Gunawardena, Peter Devine, Isabelle Beaumont, Lola Piper Garden, Emerson Murphy-Hill, and Kelly Blincoe. 2022. Destructive criticism in software code review impacts inclusion.Proceedings of the ACM on Human-Computer Interaction6, CSCW2 (2022), 1–29. doi:10.1145/3555183
-
[18]
Keyan Guo, Alexander Hu, Jaden Mu, Ziheng Shi, Ziming Zhao, Nishant Vishwamitra, and Hongxin Hu. 2023. An Investigation of Large Language Models for Real-World Hate Speech Detection. In2023 International Conference on Machine Learning and Applications (ICMLA). 1568–1573. doi:10.1109/ICMLA58977.2023.00237
-
[19]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[20]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
-
[21]
InInternational Conference on Learning Representations
LoRA: Low-Rank Adaptation of Large Language Models. InInternational Conference on Learning Representations. https://openreview.net/forum?id=nZeVKeeFYf9 Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE123. Publication date: July 2026. FSE123:22 Anindyaet al
work page 2026
-
[22]
Mia Mohammad Imran, Robert Zita, Rahat Rizvi Rahman, Preetha Chatterjee, and Kostadin Damevski. 2026. Toxicity Ahead: Forecasting Conversational Derailment on GitHub. InProceedings of the 2026 IEEE/ACM 48th International Conference on Software Engineering (ICSE ’26)(Rio de Janeiro, Brazil). ACM, Rio de Janeiro, Brazil. doi:10.1145/3744916. 3787839
-
[23]
Satyanarayana Chowdary Kadiyala, Jaydeb Sarker, and Bianca Trinkenreich. 2026. How should self-deprecation comments be classified? A toxicity analysis study on Zephyr. InProceedings of the 5th ACM/IEEE International Workshop on NL-based Software Engineering (NLBSE). doi:10.1145/3786164.3788447
-
[24]
Anjali Khurana, Hariharan Subramonyam, and Parmit K Chilana. 2024. Why and when llm-based assistants can go wrong: Investigating the effectiveness of prompt-based interactions for software help-seeking. InProceedings of the 29th International Conference on Intelligent User Interfaces. 288–303. doi:10.1145/3640543.3645200
-
[25]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners.Advances in neural information processing systems35 (2022), 22199–22213
work page 2022
-
[26]
Deepak Kumar, Patrick Gage Kelley, Sunny Consolvo, Joshua Mason, Elie Bursztein, Zakir Durumeric, Kurt Thomas, and Michael Bailey. 2021. Designing Toxic Content Classification for a Diversity of Perspectives. InSeventeenth Symposium on Usable Privacy and Security (SOUPS 2021). USENIX Association, 299–318. https://www.usenix.org/ conference/soups2021/prese...
work page 2021
-
[27]
J. Richard Landis and Gary G. Koch. 1977. The Measurement of Observer Agreement for Categorical Data.Biometrics 33, 1 (March 1977), 159. doi:10.2307/2529310
-
[28]
2005.The Technology Acceptance Model
Qingxiong Ma and Liping Liu. 2005.The Technology Acceptance Model. doi:10.4018/9781591404743.ch006.ch000
-
[29]
Courtney Miller, Sophie Cohen, Daniel Klug, Bogdan Vasilescu, and Christian Kästner. 2022. " Did you miss my comment or what?" understanding toxicity in open source discussions. InProceedings of the 44th International Conference on Software Engineering. 710–722. doi:10.1145/3510003.3510111
-
[30]
Shyamal Mishra and Preetha Chatterjee. 2024. Exploring ChatGPT for Toxicity Detection in GitHub(ICSE-NIER’24). Association for Computing Machinery, New York, NY, USA, 6–10. doi:10.1145/3639476.3639777
-
[31]
Subhabrata Mukherjee, Ahmed Hassan Awadallah, and Jianfeng Gao. 2021. XtremeDistilTransformers: Task Transfer for Task-agnostic Distillation. doi:10.48550/ARXIV.2106.04563
-
[32]
Emerson Murphy-Hill, Jill Dicker, Delphine Carlson, Marian Harbach, Ambar Murillo, and Tao Zhou. 2024. Did Gerrit’s Respectful Code Review Reminders Reduce Comment Toxicity? InEquity, Diversity, and Inclusion in Software Engineering: Best Practices and Insights. Apress Berkeley, CA, 309–321. doi:10.1007/978-1-4842-9651-6_18
-
[33]
Emerson Murphy-Hill, Ciera Jaspan, Carolyn Egelman, and Lan Cheng. 2022. The pushback effects of race, ethnicity, gender, and age in code review.Commun. ACM65, 3 (2022), 52–57. doi:10.1145/3474097
-
[34]
Nicole Novielli, Fabio Calefato, Filippo Lanubile, and Alexander Serebrenik. 2021. Assessment of off-the-shelf SE- specific sentiment analysis tools: An extended replication study.Empirical Software Engineering26, 4 (2021), 77. doi:10.1007/s10664-021-09960-w
-
[35]
Phil Sidney Ostheimer, Mayank Kumar Nagda, Marius Kloft, and Sophie Fellenz. 2024. Text Style Transfer Evaluation Using Large Language Models. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). ELRA and ICCL, Torino, Italia, 15802–15822. https:// aclanthology.org/202...
work page 2024
-
[36]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics. 311–318
work page 2002
-
[37]
Shrimai Prabhumoye, Yulia Tsvetkov, Ruslan Salakhutdinov, and Alan W Black. 2018. Style Transfer Through Back- Translation. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Iryna Gurevych and Yusuke Miyao (Eds.). Association for Computational Linguistics, Melbourne, Australia, 866–876. doi:...
-
[38]
Huilian Sophie Qiu, Bogdan Vasilescu, Christian Kästner, Carolyn Egelman, Ciera Jaspan, and Emerson Murphy-Hill
-
[39]
Detecting interpersonal conflict in issues and code review: cross pollinating open- and closed-source approaches. InProceedings of the 2022 ACM/IEEE 44th International Conference on Software Engineering: Software Engineering in Society(Pittsburgh, Pennsylvania)(ICSE-SEIS ’22). Association for Computing Machinery, New York, NY, USA, 41–55. doi:10.1145/3510...
-
[40]
Md Shamimur Rahman, Zadia Codabux, and Chanchal K Roy. 2024. Do Words Have Power? Understanding and Fostering Civility in Code Review Discussion.Proceedings of the ACM on Software Engineering1, FSE (2024), 1632–1655. doi:10.1145/3660780
-
[41]
Naveen Raman, Minxuan Cao, Yulia Tsvetkov, Christian Kästner, and Bogdan Vasilescu. 2020. Stress and burnout in open source: Toward finding, understanding, and mitigating unhealthy interactions. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering: New Ideas and Emerging Results. 57–60. doi:10.1145/3377816.3381732
-
[42]
Sarthak Roy, Ashish Harshvardhan, Animesh Mukherjee, and Punyajoy Saha. 2023. Probing LLMs for hate speech detection: strengths and vulnerabilities. InFindings of the Association for Computational Linguistics: EMNLP 2023. Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE123. Publication date: July 2026. ToxiShield: Promoting Inclusive Developer Communic...
-
[43]
Elvis Saravia. 2022. Prompt Engineering Guide.https://github.com/dair-ai/Prompt-Engineering-Guide(12 2022)
work page 2022
-
[44]
Jaydeb Sarker, Sayma Sultana, Steven R Wilson, and Amiangshu Bosu. 2023. ToxiSpanSE: An explainable toxicity detection in code review comments. In2023 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM). IEEE, 1–12. doi:10.1109/ESEM56168.2023.10304855
-
[45]
Jaydeb Sarker, Asif Kamal Turzo, and Amiangshu Bosu. 2020. A benchmark study of the contemporary toxicity detectors on software engineering interactions. In2020 27th Asia-Pacific Software Engineering Conference (APSEC). IEEE, 218–227. doi:10.1109/APSEC51365.2020.00030
-
[46]
Jaydeb Sarker, Asif Kamal Turzo, and Amiangshu Bosu. 2025. The Landscape of Toxicity: An Empirical Investigation of Toxicity on GitHub.Proceedings of the ACM on Software Engineering2, FSE (2025), 623–646. doi:10.1145/3715744
-
[47]
Jaydeb Sarker, Asif Kamal Turzo, Ming Dong, and Amiangshu Bosu. 2023. Automated Identification of Toxic Code Reviews Using ToxiCR.ACM Transactions on Software Engineering and Methodology32, 5 (July 2023), 1–32. doi:10. 1145/3583562
work page 2023
-
[48]
Sulayman K Sowe, Ioannis Stamelos, and Lefteris Angelis. 2008. Understanding knowledge sharing activities in free/open source software projects: An empirical study.Journal of Systems and Software81, 3 (2008), 431–446. doi:10.1016/j.jss.2007.03.086
-
[49]
Sayma Sultana, Jaydeb Sarker, Farzana Israt, Rajshakhar Paul, and Amiangshu Bosu. 2025. Automated Identification of Sexual Orientation and Gender Identity Discriminatory Texts from Issue Comments.ACM Transactions on Software Engineering Methodology (TOSEM)34 (2025). doi:10.1145/3757739
-
[50]
Xiaofei Sun, Xiaoya Li, Jiwei Li, Fei Wu, Shangwei Guo, Tianwei Zhang, and Guoyin Wang. 2023. Text Classification via Large Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2023. 8990–9005. doi:10.18653/v1/2023.findings-emnlp.603
-
[51]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Bianca Trinkenreich, Mariam Guizani, Igor Wiese, Tayana Conte, Marco Gerosa, Anita Sarma, and Igor Steinmacher
-
[53]
Pots of gold at the end of the rainbow: what is success for open source contributors?IEEE Transactions on Software Engineering48, 10 (2021), 3940–3953. doi:10.1109/TSE.2021.3108032
-
[54]
Robert A Virzi. 1992. Refining the test phase of usability evaluation: how many subjects is enough?Human factors34, 4 (1992), 457–468
work page 1992
- [55]
-
[56]
Alex Warstadt, Amanpreet Singh, and Samuel R. Bowman. 2019. Neural Network Acceptability Judgments.Transactions of the Association for Computational Linguistics7 (09 2019), 625–641. doi:10.1162/tacl_a_00290
-
[57]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou
-
[58]
InAdvances in Neural Information Processing Systems, Vol
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems, Vol. 35. Curran Associates, Inc., 24824–24837. https://proceedings.neurips.cc/paper_files/paper/ 2022/file/9d5609613524ecf4f15af0f7b31abca4-Paper-Conference.pdf
work page 2022
-
[59]
John Wieting, Taylor Berg-Kirkpatrick, Kevin Gimpel, and Graham Neubig. 2019. Beyond BLEU: Training Neural Machine Translation with Semantic Similarity. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Anna Korhonen, David Traum, and Lluís Màrquez (Eds.). Association for Computational Linguistics, Florence, Italy,...
-
[60]
Frances Zlotnick. 2017. GitHub Open Source Survey 2017. http://opensourcesurvey.org/2017/. doi:10.5281/zenodo. 806811 Received 2025-09-10; accepted 2026-03-24 Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE123. Publication date: July 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.