Recognition: unknown
Distributed Variational Quantum Linear Solver
Pith reviewed 2026-05-10 12:32 UTC · model grok-4.3
The pith
Distributed computation and a fast Walsh-Hadamard transform cut VQLS circuit evaluations by 256 times for 10-qubit structured systems while preserving over 99.99 percent fidelity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the D-VQLS framework together with FWHT-based Pauli decomposition and one-percent coefficient thresholding reduces the per-iteration circuit count from O(n * 4^n) to O(n) for sparse structured matrices, yielding a 256-fold reduction to 90,112 circuits for a 10-qubit tridiagonal Toeplitz system while retaining over 99.99 percent fidelity to the exact classical solution; the same approach supplies gate-count and qubit estimates for general matrices and demonstrates near-ideal scaling on up to 96 GPUs.
What carries the argument
The FWHT-based Pauli decomposition with 1 percent coefficient thresholding, which compresses the LCU representation of sparse structured matrices so that the number of terms L drops from exponential to constant for n greater than 6 qubits.
If this is right
- For n greater than 6 the number of LCU terms becomes O(1), turning the dominant cost per iteration into linear in n.
- The supplied gate-count and qubit estimates indicate concrete resource requirements for applying VQLS to arbitrary matrices on early fault-tolerant processors.
- Multi-GPU strong scaling remains near-ideal up to 24 GPUs and weak scaling reaches 95.3 percent efficiency at 96 GPUs while handling 360,448 circuits per iteration.
- The same compression and distribution pattern is validated on Hele-Shaw flow problems, confirming high fidelity outside pure Toeplitz cases.
Where Pith is reading between the lines
- The same thresholding technique may extend to other variational algorithms that rely on LCU or Pauli-string expansions, such as variational quantum eigensolvers for chemistry.
- If the method generalizes beyond the tested structured matrices, it could make quantum linear-system solvers viable for additional engineering problems like fluid dynamics on near-term devices.
- The profiling results on optimal GPU allocation could inform scheduling for any distributed quantum-circuit workload that must evaluate many similar circuits in parallel.
Load-bearing premise
Discarding Pauli coefficients below the 1 percent threshold introduces only negligible error into the variational solution for the class of sparse structured matrices and does not slow optimizer convergence or reduce final accuracy.
What would settle it
Run the identical 10-qubit tridiagonal Toeplitz VQLS instance once with full Pauli coefficients and once with the 1 percent threshold; if the solution fidelity falls materially below 99.99 percent, the compression claim does not hold.
Figures




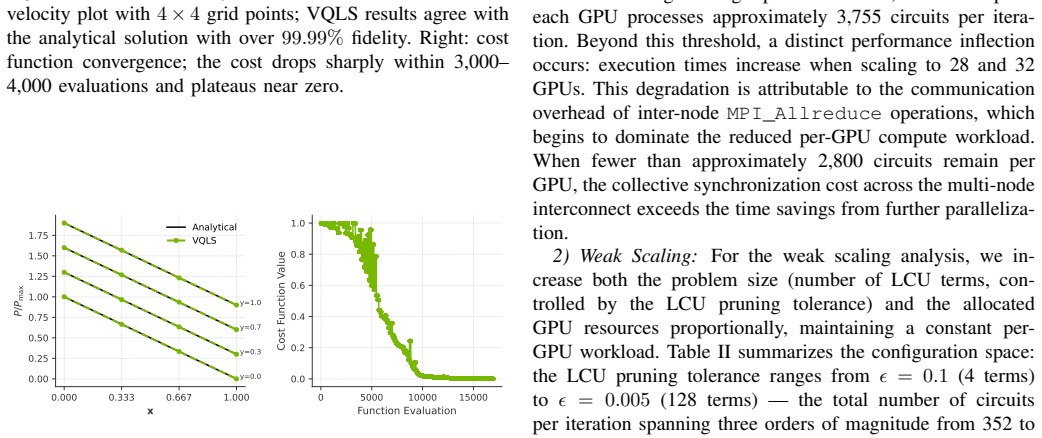




read the original abstract
The Variational Quantum Linear Solver (VQLS), a hybrid quantum-classical algorithm for solving linear systems, faces a practical scalability bottleneck: the Linear Combination of Unitaries (LCU) decomposition requires O(L^2) circuit evaluations per optimizer iteration, where $L$ can grow as 4^n for n-qubit systems for the worst case scenario. We address this computational bottleneck through two complementary strategies. First, we present a distributed VQLS (D-VQLS) framework, built on NVIDIA CUDA-Q, that enables asynchronous, scalable distribution of the O(L^2) cost-function evaluations. Second, a fast Walsh--Hadamard transform (FWHT)-based Pauli decomposition with 1% coefficient thresholding curbs the exponential growth of LCU terms, reducing L from O}(2^n) to O(1) for n > 6 qubits and compressing the per-iteration circuit complexity from O(n * 4^n) to O(n) for sparse, structured matrices. For a 10-qubit tridiagonal Toeplitz system, this yields a 256x reduction, from 23 million to 90,112 circuits per iteration, while preserving over $99.99\%$ solution fidelity. Additionally, to inform feasibility on early fault-tolerant QPUs, the paper provides resource estimates -- gate counts, qubit requirements, and circuit evaluations per iteration -- for VQLS applied to arbitrary matrices. The D-VQLS framework is validated on the NERSC Perlmutter supercomputer using multi-node, multi-GPU ideal state-vector simulations, achieving over 99.99% fidelity against classical solutions on tridiagonal Toeplitz and Hele--Shaw flow benchmarks, with near-ideal strong scaling up to 24 GPUs and 95.3% weak scaling efficiency at 96 GPUs processing 360,448 circuits per iteration for a 10-qubit system. Systematic profiling identifies the optimal resource allocation for distributed quantum circuit workloads, yielding a 2.52x speedup for the configurations studied.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a distributed variational quantum linear solver (D-VQLS) framework on NVIDIA CUDA-Q for asynchronous parallelization of the O(L^2) LCU cost-function evaluations in VQLS. It further proposes an FWHT-based Pauli decomposition combined with 1% coefficient thresholding to reduce the number of terms L from exponential to effectively constant for n>6 qubits on sparse structured matrices, reporting a 256x reduction (23 million to 90,112 circuits per iteration) for a 10-qubit tridiagonal Toeplitz system while retaining >99.99% fidelity to the classical solution. The framework is validated via ideal state-vector simulations on the NERSC Perlmutter supercomputer, showing near-ideal strong scaling to 24 GPUs and 95.3% weak scaling efficiency at 96 GPUs, together with resource estimates for early fault-tolerant hardware.
Significance. If the fidelity preservation under thresholding generalizes, the combination of algorithmic compression and distributed execution would meaningfully advance the practical reach of VQLS beyond small-scale demonstrations by mitigating the dominant LCU scaling bottleneck. The concrete supercomputer scaling data and gate-count estimates constitute a useful engineering contribution for assessing near-term feasibility.
major comments (2)
- [Abstract and results section on FWHT decomposition] Abstract and the 10-qubit benchmark paragraph: the headline 256x circuit reduction and >99.99% fidelity claim rest on the 1% FWHT coefficient threshold, yet no operator-norm bound, condition-number perturbation analysis, or propagation of the discarded terms through the variational cost landscape min_θ ⟨ψ(θ)|A'†A'|ψ(θ)⟩ is supplied. The support is limited to empirical outcomes on two structured matrices; without such analysis it is unclear whether coherent accumulation of the sub-threshold coefficients can shift the optimizer minimum or degrade convergence for other sparse matrices in the claimed target class.
- [Resource estimates for fault-tolerant QPUs] Resource-estimate section: the gate-count and circuit-evaluation projections for arbitrary matrices assume the same LCU structure as the structured benchmarks, but the manuscript does not quantify how the thresholding approximation alters the effective condition number or the number of required optimizer iterations, which directly affects the total resource estimate.
minor comments (2)
- The definition of L after thresholding is introduced without an explicit formula relating the retained Pauli weight to system size n; adding this would clarify the claimed O(1) scaling for n>6.
- Figure captions for the scaling plots should state the precise number of circuits evaluated per iteration and the ansatz depth used, to allow direct comparison with other VQLS implementations.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments on our manuscript. We address each major comment point by point below, providing the strongest honest defense of our work. Where the comments identify areas needing clarification or additional discussion, we indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract and results section on FWHT decomposition] Abstract and the 10-qubit benchmark paragraph: the headline 256x circuit reduction and >99.99% fidelity claim rest on the 1% FWHT coefficient threshold, yet no operator-norm bound, condition-number perturbation analysis, or propagation of the discarded terms through the variational cost landscape min_θ ⟨ψ(θ)|A'†A'|ψ(θ)⟩ is supplied. The support is limited to empirical outcomes on two structured matrices; without such analysis it is unclear whether coherent accumulation of the sub-threshold coefficients can shift the optimizer minimum or degrade convergence for other sparse matrices in the claimed target class.
Authors: We acknowledge that the reported 256x reduction and fidelity results rely on empirical validation for the two specific structured matrices tested (tridiagonal Toeplitz and Hele-Shaw flow). The manuscript does not include an operator-norm bound, condition-number perturbation analysis, or explicit propagation of discarded coefficients through the variational cost function. This is a valid limitation for generalizing the thresholding approach. In the revised manuscript we will update the abstract and results sections to explicitly qualify these claims as empirical for the tested matrix classes and add a discussion paragraph on the potential for coherent accumulation of sub-threshold terms to affect the optimizer. We believe this addresses the concern by increasing transparency while preserving the concrete performance numbers demonstrated in simulation. revision: partial
-
Referee: [Resource estimates for fault-tolerant QPUs] Resource-estimate section: the gate-count and circuit-evaluation projections for arbitrary matrices assume the same LCU structure as the structured benchmarks, but the manuscript does not quantify how the thresholding approximation alters the effective condition number or the number of required optimizer iterations, which directly affects the total resource estimate.
Authors: The resource estimates are baseline projections for the standard LCU-based VQLS on arbitrary matrices and do not incorporate the FWHT thresholding, which is presented separately as an optimization for sparse structured systems. The manuscript therefore does not quantify any change in effective condition number or optimizer iterations under thresholding. We will revise the resource-estimate section to state this distinction clearly, noting that thresholding reduces L (and thus circuit evaluations) for the structured cases but that any secondary effects on iteration count remain outside the current scope. revision: yes
- A rigorous operator-norm bound or perturbation analysis showing how 1% FWHT coefficient thresholding affects the variational cost landscape and convergence for general sparse matrices beyond the two empirically tested cases.
Circularity Check
No significant circularity; claims rest on empirical benchmarks
full rationale
The paper introduces a distributed VQLS framework and an FWHT-based Pauli decomposition with 1% thresholding as practical techniques to reduce LCU circuit counts. These are presented as algorithmic choices, with the reported 256x reduction and >99.99% fidelity demonstrated via explicit state-vector simulations on tridiagonal Toeplitz and Hele-Shaw matrices, cross-validated against independent classical solvers. No derivation step equates an output to its input by construction, no fitted parameter is relabeled as a prediction, and no load-bearing premise relies on self-citation chains or imported uniqueness theorems. The thresholding is an empirical heuristic whose error impact is assessed only through the reported fidelity numbers, not through any tautological reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- coefficient threshold =
0.01
axioms (1)
- domain assumption Thresholding small coefficients in the Pauli decomposition of the linear operator preserves variational solution fidelity for sparse structured matrices.
Reference graph
Works this paper leans on
-
[1]
On the asymptotic complexity of matrix multiplication,
D. Coppersmith and S. Winograd, “On the asymptotic complexity of matrix multiplication,”SIAM Journal on Computing, vol. 11, no. 3, pp. 472–492, 1982. [Online]. Available: https://doi.org/10.1137/0211038
-
[2]
L. N. Trefethen and D. Bau,Numerical linear algebra. SIAM, 2022
2022
-
[3]
Quantum algorithm for linear systems of equations,
A. W. Harrow, A. Hassidim, and S. Lloyd, “Quantum algorithm for linear systems of equations,”Physical review letters, vol. 103, no. 15, p. 150502, 2009. [Online]. Available: https://doi.org/10.1103/ PhysRevLett.103.150502
2009
-
[4]
Quantum computing in the NISQ era and beyond,
J. Preskill, “Quantum computing in the NISQ era and beyond,” Quantum, vol. 2, p. 79, 2018. [Online]. Available: https://doi.org/10. 22331/q-2018-08-06-79
2018
-
[5]
Quantum algorithms for systems of linear equations inspired by adiabatic quantum computing,
Y . Subas ¸ı, R. D. Somma, and D. Orsucci, “Quantum algorithms for systems of linear equations inspired by adiabatic quantum computing,” Physical review letters, vol. 122, no. 6, p. 060504, 2019. [Online]. Available: https://doi.org/10.1103/PhysRevLett.122.060504
-
[6]
D. An and L. Lin, “Quantum linear system solver based on time-optimal adiabatic quantum computing and quantum approximate optimization algorithm,”ACM Transactions on Quantum Computing, vol. 3, no. 2, pp. 1–28, 2022. [Online]. Available: https://doi.org/10.1145/3498331
-
[7]
Optimal scaling quantum linear-systems solver via discrete adiabatic theorem,
P. C. Costa, D. An, Y . R. Sanders, Y . Su, R. Babbush, and D. W. Berry, “Optimal scaling quantum linear-systems solver via discrete adiabatic theorem,”PRX quantum, vol. 3, no. 4, p. 040303, 2022. [Online]. Available: https://doi.org/10.1103/PRXQuantum.3.040303
-
[8]
Optimal polynomial based quantum eigenstate filtering with application to solving quantum linear systems,
L. Lin and Y . Tong, “Optimal polynomial based quantum eigenstate filtering with application to solving quantum linear systems,”Quantum, vol. 4, p. 361, 2020. [Online]. Available: https://doi.org/10.22331/ q-2020-11-11-361
2020
-
[9]
LuGo: an Enhanced Quantum Phase Estimation Implementation,
C. Lu, M. Gopalakrishanan Meena, and K. C. Gottiparthi, “LuGo: an Enhanced Quantum Phase Estimation Implementation,”arXiv preprint arXiv:2503.15439, 2025. [Online]. Available: https://arxiv.org/abs/2503. 15439
-
[10]
A. Gily ´en, Y . Su, G. H. Low, and N. Wiebe, “Quantum singular value transformation and beyond: exponential improvements for quantum matrix arithmetics,” inProceedings of the 51st annual ACM SIGACT symposium on theory of computing, 2019, pp. 193–204. [Online]. Available: https://doi.org/10.1145/3313276.3316366
-
[11]
S. Chakraborty, A. Gily ´en, and S. Jeffery, “The power of block- encoded matrix powers: improved regression techniques via faster hamiltonian simulation,”arXiv preprint arXiv:1804.01973, 2018. [Online]. Available: https://arxiv.org/abs/1804.01973
-
[12]
Explicit quantum circuits for block encodings of certain sparse matrices,
D. Camps, L. Lin, R. Van Beeumen, and C. Yang, “Explicit quantum circuits for block encodings of certain sparse matrices,”SIAM Journal on Matrix Analysis and Applications, vol. 45, no. 1, pp. 801–827,
-
[13]
Available: https://doi.org/10.1137/22M1484298
[Online]. Available: https://doi.org/10.1137/22M1484298
-
[14]
Block-encoding structured matrices for data input in quantum computing,
C. S ¨underhauf, E. Campbell, and J. Camps, “Block-encoding structured matrices for data input in quantum computing,”Quantum, vol. 8, p. 1226, 2024. [Online]. Available: https://doi.org/10.22331/ q-2024-01-11-1226
2024
-
[15]
Variational quantum linear solver,
C. Bravo-Prieto, R. LaRose, M. Cerezo, Y . Subasi, L. Cincio, and P. J. Coles, “Variational quantum linear solver,”Quantum, vol. 7, p. 1188,
-
[16]
Available: https://doi.org/10.22331/q-2023-11-22-1188
[Online]. Available: https://doi.org/10.22331/q-2023-11-22-1188
-
[17]
R. Demirdjian, D. Gunlycke, C. A. Reynolds, J. D. Doyle, and S. Tafur, “Variational quantum solutions to the advection–diffusion equation for applications in fluid dynamics,”Quantum Information Processing, vol. 21, no. 9, p. 322, 2022. [Online]. Available: https://doi.org/10.1007/s11128-022-03667-7
-
[18]
Quantum computing and preconditioners for hydrological linear systems,
J. Golden, D. O’Malley, and H. Viswanathan, “Quantum computing and preconditioners for hydrological linear systems,”Scientific Reports, vol. 12, no. 1, p. 22285, 2022. [Online]. Available: https://doi.org/10.1038/s41598-022-25727-9
-
[19]
Towards a quantum algorithm for the incompressible nonlinear navier-stokes equations,
M. Gopalakrishnan Meena, Y . Zhang, W. Jiang, Y . Lin, S. G ¨unther, and X. Gao, “Towards a quantum algorithm for the incompressible nonlinear navier-stokes equations,” in2024 IEEE International Conference on Quantum Computing and Engineering (QCE), vol. 1. IEEE, 2024, pp. 662–668. [Online]. Available: https://doi.org/10.1109/QCE59457.2024. 10821279
-
[20]
A hybrid quantum-classical framework for computational fluid dynamics,
C.-C. Ye, N.-B. An, T.-Y . Ma, M.-H. Dou, W. Bai, D.-J. Sun, Z.-Y . Chen, and G.-P. Guo, “A hybrid quantum-classical framework for computational fluid dynamics,”Physics of Fluids, vol. 36, no. 12, 2024. [Online]. Available: https://doi.org/10.1063/5.0238193
-
[21]
F. S. D. Bosco, R. Lineswala, A. Chopraet al., “Demonstration of scalability and accuracy of variational quantum linear solver for computational fluid dynamics,”arXiv preprint arXiv:2409.03241, 2024. [Online]. Available: https://arxiv.org/abs/2409.03241
-
[22]
DeepOHeat: Operator Learning-based Ultra-fast Thermal Simulation in 3D-IC Design,
J.-S. Kim, A. McCaskey, B. Heim, M. Modani, S. Stanwyck, and T. Costa, “Cuda quantum: The platform for integrated quantum- classical computing,” in2023 60th ACM/IEEE Design Automation Conference (DAC). IEEE, 2023, pp. 1–4. [Online]. Available: https://doi.org/10.1109/DAC56929.2023.10247886
-
[23]
I. Loaiza, A. Sankar Brahmachari, and A. F. Izmaylov, “Majorana tensor decomposition: A unifying framework for decompositions of fermionic hamiltonians to linear combination of unitaries,”Quantum Science and Technology, vol. 10, no. 3, p. 035035, 2025. [Online]. Available: https://doi.org/10.1088/2058-9565/adb427
-
[24]
A Linear Combination of Unitaries Decomposition for the Laplace Operator
T. Hogancamp, R. Demirdjian, and D. Gunlycke, “A linear combination of unitaries decomposition for the laplace operator,”arXiv preprint arXiv:2601.06370, 2026. [Online]. Available: https://arxiv.org/abs/2601. 06370
-
[25]
Pauli decomposition via the fast walsh-hadamard transform,
T. N. Georges, B. K. Berntson, C. S ¨underhauf, and A. V . Ivanov, “Pauli decomposition via the fast walsh-hadamard transform,”New Journal of Physics, vol. 27, no. 3, p. 033004, 2025. [Online]. Available: https://doi.org/10.1088/1367-2630/adb44d
-
[26]
Tridiagonal toeplitz matrices: properties and novel applications,
S. Noschese, L. Pasquini, and L. Reichel, “Tridiagonal toeplitz matrices: properties and novel applications,”Numerical linear algebra with applications, vol. 20, no. 2, pp. 302–326, 2013. [Online]. Available: https://doi.org/10.1002/nla.1811
-
[27]
Solving the Hele–Shaw flow using the Harrow–Hassidim–Lloyd algorithm on superconducting devices: A study of efficiency and challenges,
M. Gopalakrishnan Meena, K. C. Gottiparthi, J. G. Lietz, A. Georgiadou, and E. A. Coello P ´erez, “Solving the Hele–Shaw flow using the Harrow–Hassidim–Lloyd algorithm on superconducting devices: A study of efficiency and challenges,”Physics of Fluids, vol. 36, no. 10,
-
[28]
Available: https://doi.org/10.1063/5.0231929
[Online]. Available: https://doi.org/10.1063/5.0231929
-
[29]
Quantum CFD simulations for heat transfer applications,
C. Lu, Z. Hu, B. Xie, and N. Zhang, “Quantum CFD simulations for heat transfer applications,” inASME International Mechanical Engineering Congress and Exposition, vol. 84584. American Society of Mechanical Engineers, 2020, p. V010T10A050. [Online]. Available: https://doi.org/10.1115/IMECE2020-23915
-
[30]
A hybrid quantum-classical CFD methodology with benchmark HHL solutions
L. Lapworth, “A hybrid quantum-classical CFD methodology with benchmark HHL solutions,”arXiv preprint arXiv:2206.00419, 2022. [Online]. Available: https://arxiv.org/abs/2206.00419
-
[31]
Synthesis of quantum-logic circuits,
V . V . Shende, I. L. Markov, and S. S. Bullock, “Synthesis of quantum-logic circuits,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 25, no. 6, pp. 1000–1010,
-
[32]
Available: https://doi.org/10.1109/TCAD.2005.855930
[Online]. Available: https://doi.org/10.1109/TCAD.2005.855930
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.