Recognition: unknown
Response-Aware User Memory Selection for LLM Personalization
Pith reviewed 2026-05-10 12:36 UTC · model grok-4.3
The pith
Selecting LLM user memory by mutual information with model outputs yields more human-aligned and higher-quality personalization than similarity-based selection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RUMS selects user memory items by measuring the mutual information between a subset of memory and the model's outputs, identifying items that reduce response uncertainty and sharpen predictions beyond semantic similarity. This information-theoretic foundation enables more principled user memory selection that aligns more closely with human selection compared to state-of-the-art methods and models 400 times larger. Memory items selected using RUMS also produce better response quality while incurring up to 95 percent lower computational cost.
What carries the argument
RUMS (Response-Utility optimization for Memory Selection), which estimates mutual information between candidate memory subsets and the LLM output distribution to rank and retain the most informative items.
Load-bearing premise
Mutual information between memory subsets and LLM outputs can be reliably estimated at inference time, and selecting higher values directly produces better and more human-aligned responses.
What would settle it
A head-to-head human evaluation in which responses generated with RUMS-selected memory receive no higher quality ratings than those generated with similarity-selected memory.
Figures

















































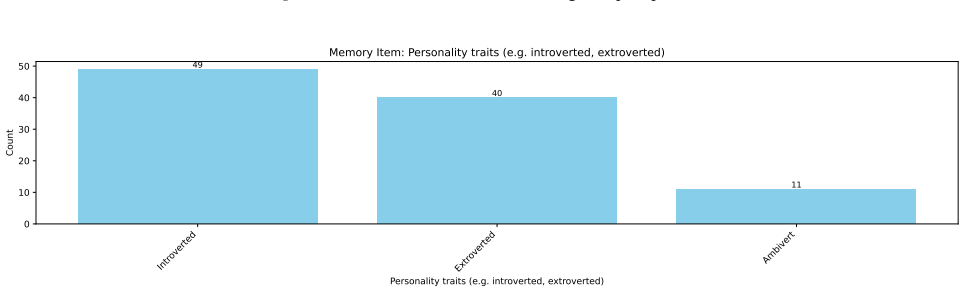






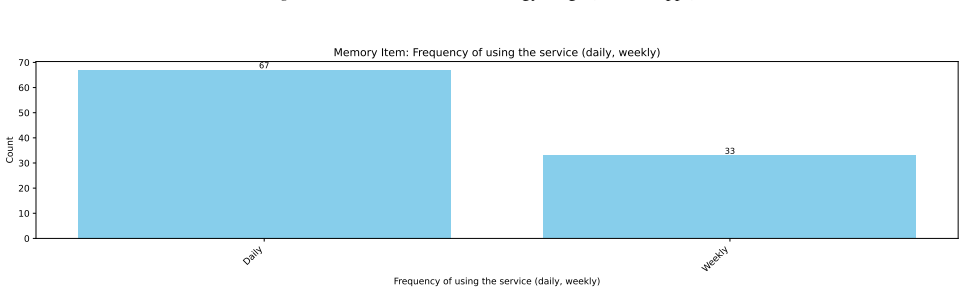




read the original abstract
A common approach to personalization in large language models (LLMs) is to incorporate a subset of the user memory into the prompt at inference time to guide the model's generation. Existing methods select these subsets primarily using similarity between user memory items and input queries, ignoring how features actually affect the model's response distribution. We propose Response-Utility optimization for Memory Selection (RUMS), a novel method that selects user memory items by measuring the mutual information between a subset of memory and the model's outputs, identifying items that reduce response uncertainty and sharpen predictions beyond semantic similarity. We demonstrate that this information-theoretic foundation enables more principled user memory selection that aligns more closely with human selection compared to state-of-the-art methods, and models $400\times$ larger. Additionally, we show that memory items selected using RUMS result in better response quality compared to existing approaches, while having up to $95\%$ reduction in computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Response-Utility optimization for Memory Selection (RUMS), a method for LLM personalization that selects subsets of user memory by maximizing mutual information between the memory items and the model's output distribution. This is positioned as superior to semantic similarity baselines because it directly targets reduction in response uncertainty. The authors claim improved alignment with human memory selections, higher response quality, and up to 95% computational cost reduction, while outperforming models 400x larger.
Significance. If the mutual-information objective can be approximated efficiently and shown to preserve ordering that correlates with actual response quality and human preference, the work would supply a more principled, information-theoretic alternative to heuristic memory selection in personalized LLMs. The claimed cost savings and cross-model scaling results would be of practical interest for deployment.
major comments (2)
- [Abstract and §3 (Method)] The central claim rests on estimating I(M;Y) where Y is the LLM's token-level output distribution. The abstract asserts both human alignment and 95% cost reduction, yet provides no description of the proxy (single forward pass, top-k entropy, gradient surrogate, etc.) used to make this tractable at inference time. Without an explicit approximation and a validation that it preserves the claimed information-theoretic ordering, the superiority over semantic similarity cannot be evaluated.
- [Experiments section] Table 2 (or equivalent results table) reports gains in alignment and quality, but the manuscript does not state the number of independent generations per candidate subset, the Monte-Carlo sample size for MI estimation, or any statistical significance tests. These details are load-bearing for the claim that RUMS measurably reduces response uncertainty beyond baselines.
minor comments (2)
- [Abstract] The abstract phrase 'models $400×$ larger' is unclear; it should be rephrased to 'outperforms models 400× larger' or similar for readability.
- [§3] Notation for the memory subset M and response Y should be introduced consistently in the method section and reused in equations; current usage mixes 'subset of memory' and 'memory items' without a single definition.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and have revised the paper to improve clarity and completeness where appropriate.
read point-by-point responses
-
Referee: [Abstract and §3 (Method)] The central claim rests on estimating I(M;Y) where Y is the LLM's token-level output distribution. The abstract asserts both human alignment and 95% cost reduction, yet provides no description of the proxy (single forward pass, top-k entropy, gradient surrogate, etc.) used to make this tractable at inference time. Without an explicit approximation and a validation that it preserves the claimed information-theoretic ordering, the superiority over semantic similarity cannot be evaluated.
Authors: We thank the referee for highlighting this point. We agree that the original manuscript did not provide sufficient detail on the practical approximation for estimating I(M;Y) at inference time. We have revised Section 3 to explicitly describe the proxy: a Monte Carlo approximation that samples from the top-k tokens of the LLM output distribution using a single forward pass per memory subset. We have also added a validation analysis (new subsection in §3 and appendix) demonstrating that this approximation preserves the relative ordering of memory subsets with high fidelity to more expensive exact computations on smaller models. These changes directly support the superiority claims over semantic similarity while clarifying the source of the reported cost reductions. revision: yes
-
Referee: [Experiments section] Table 2 (or equivalent results table) reports gains in alignment and quality, but the manuscript does not state the number of independent generations per candidate subset, the Monte-Carlo sample size for MI estimation, or any statistical significance tests. These details are load-bearing for the claim that RUMS measurably reduces response uncertainty beyond baselines.
Authors: We agree that these details are essential for evaluating the claims. We have revised the Experiments section to explicitly state that we performed 5 independent generations per candidate subset when measuring response quality, used a Monte-Carlo sample size of 20 for MI estimation, and applied paired t-tests for statistical significance (all reported p-values < 0.05). These specifications and the corresponding test results have been added to the text describing Table 2, confirming that the observed gains in alignment and quality are statistically reliable. revision: yes
Circularity Check
No circularity: RUMS introduces independent MI-based selection objective
full rationale
The paper defines RUMS as a new optimization that selects memory subsets via mutual information with the LLM output distribution, explicitly contrasting it with semantic similarity baselines. No equations, derivations, or claims reduce this objective to a fitted parameter, self-citation chain, or input by construction. The information-theoretic criterion is presented as a first-principles proposal whose practical estimation and superiority are evaluated separately; the central claim therefore remains self-contained and does not collapse into its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mutual information between memory subsets and LLM output distributions can be practically estimated and used for selection
Forward citations
Cited by 1 Pith paper
-
When Are LLM Inferences Acceptable? User Reactions and Control Preferences for Inferred Personal Information
Users show curiosity over concern toward LLM inferences of personal information, with acceptability depending on context, alignment with expectations, and who uses the inferences rather than just the content.
Reference graph
Works this paper leans on
-
[1]
findings-emnlp.592/
URL https://aclanthology.org/2024. findings-emnlp.592/. Gadgil, S., Covert, I., and Lee, S.-I. Estimating con- ditional mutual information for dynamic feature selec- tion. InProceedings of the 42nd International Con- ference on Learning Representations (ICLR). OpenRe- view.net, 2024. URL https://openreview.net/ pdf?id=Oju2Qu9jvn. Geifman, Y . and El-Yaniv...
2024
-
[2]
Gemma 2: Improving Open Language Models at a Practical Size
Curran Associates Inc. ISBN 9781510860964. Gemma Team. Gemma 2: Improving open language models at a practical size, 2024. URL https://arxiv.org/ abs/2408.00118. Gneiting, T. and Raftery, A. E. Strictly proper scoring rules, prediction, and estimation.Journal of the American Statistical Association, 102(477):359–378, 2007. Hagstr¨om, L., Kim, Y ., Yu, H., ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
He, P., Liu, X., Gao, J., and Chen, W
URL https://openreview.net/forum? id=xQCXInDq0m. He, P., Liu, X., Gao, J., and Chen, W. DEBERTA: Decoding- enhanced BERT with disentangled attention. InIn- ternational Conference on Learning Representations,
-
[4]
URL https://openreview.net/forum? id=XPZIaotutsD. Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Renard Lavaud, L., Lachaux, 9 Response-Aware User Memory Selection M.-A., Stock, P., Le Scao, T., Lavril, T., Wang, T., Lacroix, T., and El Sayed, W. Mistral 7B, 2...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/n19-1028 2023
-
[5]
A survey of personalized large language models: Progress and future directions
URL https://aclanthology.org/2023. findings-acl.695/. Li, Y . Unlocking context constraints of LLMs: Enhancing context efficiency of LLMs with self-information-based content filtering. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP 2023), 2023. URL https://arxiv.org/ abs/2304.12102. Li, Y ., Liang, D., Zhan...
-
[6]
URL https://openreview.net/forum? id=xKDZAW0He3. Rajeev, M. A., Ramamurthy, R., Trivedi, P., Yadav, V ., Bamgbose, O., Madhusudhan, S. T., Zou, J., and Ra- jani, N. Cats confuse reasoning LLM: Query agnostic adversarial triggers for reasoning models. InSecond Con- ference on Language Modeling, 2025. URL https: //openreview.net/forum?id=VrEPiN5WhM. Ravfoge...
-
[7]
emnlp-main.87/
URL https://aclanthology.org/2022. emnlp-main.87/. Zhao, W., Ren, X., Hessel, J., Cardie, C., Choi, Y ., and Deng, Y . Wildchat: 1m chatGPT interaction logs in the wild. InThe Twelfth International Conference on Learning Representations (ICLR 2024), Spotlight Poster,
2022
-
[8]
12 Response-Aware User Memory Selection A
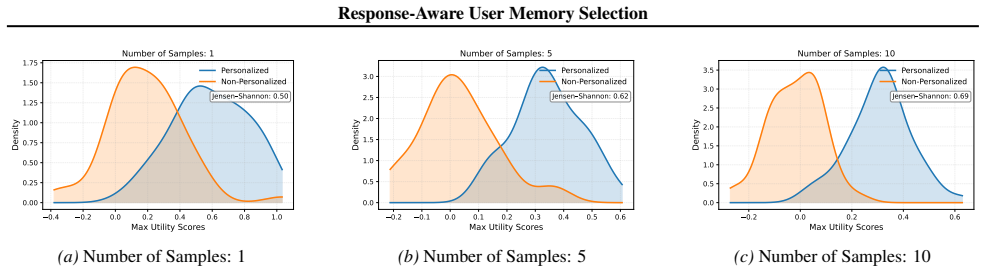
URL https://openreview.net/forum? id=Bl8u7ZRlbM. 12 Response-Aware User Memory Selection A. Additional Experimentation In this section, we present additional experiments to supplement our main results. A.1. Robustness Analysis of Utility Scores In H1, we hypothesized that RUMS-Utility, the maximum utility scores, can reliably distinguish between user inpu...
2024
-
[9]
In May 1994 the Chan- nel Tunnel was opened by Queen Elizabeth II and which French President?
Sequential Conditional Interaction GapGiven an ordering of memory items, we define δi = [U(S i)−U(S i−1]− U({i}), where Si is the prefix subset. This measures how much the conditional contributions of each memory item deviates from independence. Table 5 summarizes the measured combinatorial gaps across both synthetic and real-world datasets. We find the f...
2024
-
[10]
overall”: “2
**Interactive Activities**: Engage in activities like grammar charades or sentence-building races with friends or family. This adds a social element to learning. 3. **Threshold Learning**: Set small, achievable goals and reward yourself when you reach them. This creates a sense of accomplishment and makes the process more enjoyable. 4. **Join a Language G...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.