Recognition: unknown
Evo-MedAgent: Beyond One-Shot Diagnosis with Agents That Remember, Reflect, and Improve
Pith reviewed 2026-05-10 12:33 UTC · model grok-4.3
The pith
A self-evolving memory module lets medical AI agents improve chest X-ray diagnosis accuracy across cases without any retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
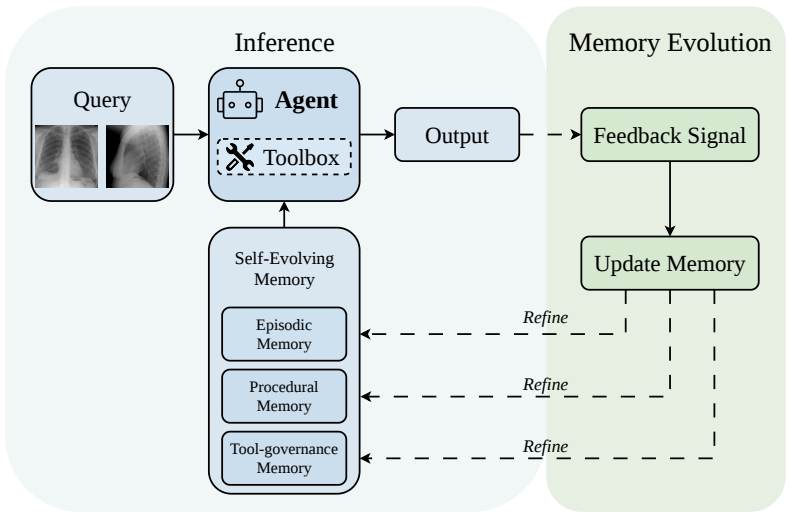
Evo-MedAgent equips a medical agent with a self-evolving memory module containing three stores: retrospective clinical episodes that retrieve problem-solving experiences from similar past cases, an adaptive procedural heuristics bank that evolves diagnostic rules via reflection, and a tool reliability controller that tracks per-tool trustworthiness. When added to tool-augmented LLM agents for chest X-ray interpretation, the memory enables inter-case learning at test time, raising MCQ accuracy on ChestAgentBench from 0.68 to 0.79 on GPT-5-mini and from 0.76 to 0.87 on Gemini-3 Flash while requiring no training.
What carries the argument
The self-evolving memory module with its three stores that retrieve past episodes, refine heuristics through reflection, and track tool reliability to accumulate experience across cases at test time.
If this is right
- Agents with evolving memory outperform static agents on qualitative diagnostic tasks even when the base model is already strong.
- The approach works on top of any frozen model, so hospitals could add the memory layer without retraining or replacing existing systems.
- Per-case cost stays bounded by one retrieval pass plus one reflection call, keeping the system practical for clinical deployment.
- Gains come from inter-case learning rather than from orchestrating more external tools.
Where Pith is reading between the lines
- The same three-store memory pattern could be tested on other imaging modalities such as CT or MRI to check whether the improvement generalizes beyond chest X-rays.
- Over many cases the heuristics bank might grow large enough that retrieval speed becomes a practical limit, suggesting a need for periodic summarization or pruning.
- If the reflection step occasionally produces harmful rules, adding a lightweight human review gate on new heuristics could make the system safer for real use.
- This test-time adaptation method points toward medical AI systems that improve continuously in the field instead of requiring periodic full retraining cycles.
Load-bearing premise
The three memory stores can be maintained and used effectively at test time without introducing new errors or requiring human oversight.
What would settle it
Running the agent on a long sequence of real chest X-ray cases and observing that accuracy stays flat or drops because reflections create incorrect heuristics or the reliability tracker mislabels tools would falsify the claim.
Figures


read the original abstract
Tool-augmented large language model (LLM) agents can orchestrate specialist classifiers, segmentation models, and visual question-answering modules to interpret chest X-rays. However, these agents still solve each case in isolation: they fail to accumulate experience across cases, correct recurrent reasoning mistakes, or adapt their tool-use behavior without expensive reinforcement learning. While a radiologist naturally improves with every case, current agents remain static. In this work, we propose Evo-MedAgent, a self-evolving memory module that equips a medical agent with the capacity for inter-case learning at test time. Our memory comprises three complementary stores: (1)~\emph{Retrospective Clinical Episodes} that retrieve problem-solving experiences from similar past cases, (2)~an \emph{Adaptive Procedural Heuristics} bank curating priority-tagged diagnostic rules that evolves via reflection, much like a physician refining their internal criteria, and (3)~a \emph{Tool Reliability Controller} that tracks per-tool trustworthiness. On ChestAgentBench, Evo-MedAgent raises multiple-choice question (MCQ) accuracy from 0.68 to 0.79 on GPT-5-mini, and from 0.76 to 0.87 on Gemini-3 Flash. With a strong base model, evolving memory improves performance more effectively than orchestrating external tools on qualitative diagnostic tasks. Because Evo-MedAgent requires no training, its per-case overhead is bounded by one additional retrieval pass and a single reflection call, making it deployable on top of any frozen model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Evo-MedAgent, a self-evolving memory module for tool-augmented LLM agents performing chest X-ray diagnosis. The module comprises three test-time stores—Retrospective Clinical Episodes for retrieving similar past cases, Adaptive Procedural Heuristics that evolve diagnostic rules via reflection, and a Tool Reliability Controller that tracks per-tool performance—enabling inter-case learning without training or external supervision. On the ChestAgentBench benchmark, the approach is reported to improve MCQ accuracy from 0.68 to 0.79 with GPT-5-mini and from 0.76 to 0.87 with Gemini-3 Flash, with bounded per-case overhead.
Significance. If the reported gains prove robust and attributable to the memory design, the work offers a practical, training-free method for cumulative improvement in medical agents. This could meaningfully advance deployable agent systems in healthcare by addressing the static nature of current one-shot agents, while the no-training constraint and low overhead are clear strengths for real-world use.
major comments (2)
- [Experimental evaluation] Experimental evaluation (results on ChestAgentBench): The accuracy gains (0.68 to 0.79 and 0.76 to 0.87) are presented without details on baseline agent configurations (e.g., whether non-evolving agents already incorporated memory or reflection), number of runs, statistical significance, error bars, or dataset characteristics. This information is required to confirm that improvements stem from the proposed three-store memory rather than other factors.
- [Method section] Method section describing the three memory stores: The update and retrieval procedures for Retrospective Clinical Episodes, Adaptive Procedural Heuristics, and Tool Reliability Controller are outlined at a conceptual level, but lack concrete mechanisms, pseudocode, or analysis showing how reflection avoids error accumulation or requires no human oversight at test time. This directly bears on the central claim of reliable self-evolution.
minor comments (2)
- [Abstract and results] The abstract and results would benefit from explicit comparison to standard retrieval-augmented generation or longer-context baselines to isolate the contribution of the specific three-store design.
- Notation for the memory stores and reflection process could be formalized (e.g., via equations or algorithms) to improve clarity and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving clarity in the experimental setup and methodological descriptions. We address each major comment below and have revised the manuscript to provide the requested details and expansions.
read point-by-point responses
-
Referee: [Experimental evaluation] Experimental evaluation (results on ChestAgentBench): The accuracy gains (0.68 to 0.79 and 0.76 to 0.87) are presented without details on baseline agent configurations (e.g., whether non-evolving agents already incorporated memory or reflection), number of runs, statistical significance, error bars, or dataset characteristics. This information is required to confirm that improvements stem from the proposed three-store memory rather than other factors.
Authors: The non-evolving baseline consists of the standard tool-augmented LLM agent that processes each chest X-ray case in isolation without access to any of the three memory stores, reflection, or inter-case updates. We have revised the experimental evaluation section to explicitly describe this baseline configuration, report results aggregated over five independent runs using different random seeds for reproducibility, include error bars as standard deviations across runs, provide p-values from paired t-tests (p < 0.01 for both GPT-5-mini and Gemini-3 Flash), and detail the ChestAgentBench dataset (500 cases drawn from public chest X-ray sources with associated multiple-choice diagnostic questions). These additions confirm that the reported gains are attributable to the self-evolving memory module rather than other factors. revision: yes
-
Referee: [Method section] Method section describing the three memory stores: The update and retrieval procedures for Retrospective Clinical Episodes, Adaptive Procedural Heuristics, and Tool Reliability Controller are outlined at a conceptual level, but lack concrete mechanisms, pseudocode, or analysis showing how reflection avoids error accumulation or requires no human oversight at test time. This directly bears on the central claim of reliable self-evolution.
Authors: We have expanded the method section with concrete mechanisms, including pseudocode for the update and retrieval procedures of each store. Retrospective Clinical Episodes use embedding similarity for retrieval and append new episodes only after outcome verification. Adaptive Procedural Heuristics employ a reflection step that generates a self-critique, applies consistency filtering against the current case's tool outputs and final answer, and merges rules with priority tags to limit propagation of errors. The Tool Reliability Controller maintains per-tool success rates via exponential moving averages. We added analysis showing that these self-verification steps reduce error accumulation and that the entire process runs autonomously at test time with no human oversight or external supervision required. revision: yes
Circularity Check
No significant circularity: empirical system with test-time updates
full rationale
The paper describes an engineering architecture for a medical LLM agent augmented with three test-time memory stores (retrospective episodes, adaptive heuristics, tool reliability) that are updated via LLM reflection on a frozen base model. No mathematical derivations, equations, fitted parameters, or predictions are present. Performance claims rest solely on reported accuracy lifts on ChestAgentBench (0.68→0.79 and 0.76→0.87), which are external benchmark measurements rather than quantities that reduce to the system's own inputs by construction. Self-citations, if any, are not load-bearing for any derivation. The approach is self-contained as an empirical demonstration of inter-case accumulation without training.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reflection on past cases produces useful updates to diagnostic heuristics without introducing systematic bias.
- domain assumption Retrieval of similar past episodes improves current-case reasoning.
invented entities (3)
-
Retrospective Clinical Episodes store
no independent evidence
-
Adaptive Procedural Heuristics bank
no independent evidence
-
Tool Reliability Controller
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Remember Me, Refine Me: A Dynamic Procedural Memory Framework for Experience-Driven Agent Evolution
Zouying Cao, Jiaji Deng, Li Yu, Weikang Zhou, Zhaoyang Liu, Bolin Ding, and Hai Zhao. Remember me, refine me: A dynamic procedural memory framework for experience-driven agent evolution.arXiv preprint arXiv:2512.10696, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, and Benyou Wang. Huatuogpt-o1, towards medical complex reasoning with llms.arXiv preprint arXiv:2412.18925, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
Chexagent: Towards a foundation model for chest x-ray interpretation
Zhihong Chen, Maya Varma, Jean-Benoit Delbrouck, Magdalini Paschali, Louis Blankemeier, Dave Van Veen, Jeya Maria Jose Valanarasu, Alaa Youssef, Joseph Paul Cohen, Eduardo Pontes Reis, et al. Chexagent: Towards a foundation model for chest x-ray interpretation. InAAAI 2024 Spring Symposium on Clinical F oundation Models, 2024
2024
-
[4]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
Cl-bench: A benchmark for context learning
Shihan Dou, Ming Zhang, Zhangyue Yin, Chenhao Huang, Yujiong Shen, Junzhe Wang, Jiayi Chen, Yuchen Ni, Junjie Ye, Cheng Zhang, et al. Cl-bench: A benchmark for context learning. arXiv preprint arXiv:2602.03587, 2026
-
[6]
Deliberate practice and the acquisition and maintenance of expert perfor- mance in medicine and related domains.Academic medicine, 79(Supplement_2):S70–S81, 2004
K Anders Ericsson. Deliberate practice and the acquisition and maintenance of expert perfor- mance in medicine and related domains.Academic medicine, 79(Supplement_2):S70–S81, 2004
2004
-
[7]
Medrax: Medical reasoning agent for chest x-ray
Adibvafa Fallahpour, Jun Ma, Alif Munim, Hongwei Lyu, and Bo Wang. Medrax: Medical reasoning agent for chest x-ray. InInternational Conference on Machine Learning, pages 15661–15676. PMLR, 2025
2025
-
[8]
Haozhen Gong, Xiaozhong Ji, Yuansen Liu, Wenbin Wu, Xiaoxiao Yan, Jingjing Liu, Kai Wu, Jiazhen Pan, Bailiang Jian, Jiangning Zhang, et al. Med-cmr: A fine-grained benchmark integrating visual evidence and clinical logic for medical complex multimodal reasoning.arXiv preprint arXiv:2512.00818, 2025
-
[9]
The landscape of medical agents: A survey
Xiaobin Hu, Yunhang Qian, Jiaquan Yu, Jingjing Liu, Peng Tang, Xiaozhong Ji, Chengming Xu, Jiawei Liu, Xiaoxiao Yan, Xinlei Yu, et al. The landscape of medical agents: A survey. Authorea Preprints, 2025
2025
-
[10]
Mdagents: An adaptive collaboration of llms for medical decision-making.Advances in Neural Information Processing Systems, 37:79410–79452, 2024
Yubin Kim, Chanwoo Park, Hyewon Jeong, Yik S Chan, Xuhai Xu, Daniel McDuff, Hyeon- hoon Lee, Marzyeh Ghassemi, Cynthia Breazeal, and Hae W Park. Mdagents: An adaptive collaboration of llms for medical decision-making.Advances in Neural Information Processing Systems, 37:79410–79452, 2024. 7
2024
-
[11]
Mmedagent: Learning to use medical tools with multi-modal agent
Binxu Li, Tiankai Yan, Yuanting Pan, Jie Luo, Ruiyang Ji, Jiayuan Ding, Zhe Xu, Shilong Liu, Haoyu Dong, Zihao Lin, et al. Mmedagent: Learning to use medical tools with multi-modal agent. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 8745–8760, 2024
2024
-
[12]
Llava-med: Training a large language-and-vision assistant for biomedicine in one day
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day. volume 36, pages 28541–28564, 2023
2023
-
[13]
Che Liu, Haozhe Wang, Jiazhen Pan, Zhongwei Wan, Yong Dai, Fangzhen Lin, Wenjia Bai, Daniel Rueckert, and Rossella Arcucci. Beyond distillation: Pushing the limits of medical llm reasoning with minimalist rule-based rl.arXiv preprint arXiv:2505.17952, 2025
-
[14]
Jiazhen Pan, Bailiang Jian, Paul Hager, Yundi Zhang, Che Liu, Friedrike Jungmann, Hong- wei Bran Li, Chenyu You, Junde Wu, Jiayuan Zhu, et al. Beyond benchmarks: Dynamic, automatic and systematic red-teaming agents for trustworthy medical language models.arXiv preprint arXiv:2508.00923, 2025
-
[15]
Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning
Jiazhen Pan, Che Liu, Junde Wu, Fenglin Liu, Jiayuan Zhu, Hongwei Bran Li, Chen Chen, Cheng Ouyang, and Daniel Rueckert. Medvlm-r1: Incentivizing medical reasoning capability of vision-language models (vlms) via reinforcement learning. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 337–347. Springer, 2025
2025
-
[16]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceed- ings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
2023
-
[17]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: a temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956, 2025
work page internal anchor Pith review arXiv 2025
-
[18]
arXiv preprint arXiv:2405.07960 , year =
Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffrey Jopling, and Michael Moor. Agentclinic: a multimodal agent benchmark to evaluate ai in simulated clinical environments. arXiv preprint arXiv:2405.07960, 2024
-
[19]
Weixiang Shen, Yanzhu Hu, Che Liu, Junde Wu, Jiayuan Zhu, Chengzhi Shen, Min Xu, Yueming Jin, Benedikt Wiestler, Daniel Rueckert, et al. Medopenclaw: Auditable medical imaging agents reasoning over uncurated full studies.arXiv preprint arXiv:2603.24649, 2026
work page internal anchor Pith review arXiv 2026
-
[20]
Ehragent: Code empowers large language models for few-shot complex tabular reasoning on electronic health records
Wenqi Shi, Ran Xu, Yuchen Zhuang, Yue Yu, Jieyu Zhang, Hang Wu, Yuanda Zhu, Joyce C Ho, Carl Yang, and May Dongmei Wang. Ehragent: Code empowers large language models for few-shot complex tabular reasoning on electronic health records. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 22315–22339, 2024
2024
-
[21]
Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
2023
-
[22]
Dynamic cheatsheet: Test-time learning with adaptive memory
Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. Dynamic cheatsheet: Test-time learning with adaptive memory. pages 7080–7106, 2026
2026
-
[23]
Rahul Thapa, Qingyang Wu, Kevin Wu, Harrison Zhang, Angela Zhang, Eric Wu, Haotian Ye, Suhana Bedi, Nevin Aresh, Joseph Boen, et al. Disentangling reasoning and knowledge in medical large language models.arXiv preprint arXiv:2505.11462, 2025
-
[24]
Ziyue Wang, Junde Wu, Linghan Cai, Chang Han Low, Xihong Yang, Qiaxuan Li, and Yueming Jin. Medagent-pro: Towards evidence-based multi-modal medical diagnosis via reasoning agentic workflow.arXiv preprint arXiv:2503.18968, 2025. 8
-
[25]
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
Tianxin Wei, Noveen Sachdeva, Benjamin Coleman, Zhankui He, Yuanchen Bei, Xuying Ning, Mengting Ai, Yunzhe Li, Jingrui He, Ed H Chi, et al. Evo-memory: Benchmarking llm agent test-time learning with self-evolving memory.arXiv preprint arXiv:2511.20857, 2025
work page internal anchor Pith review arXiv 2025
-
[26]
Junde Wu, Minhao Hu, Jiayuan Zhu, Jiazhen Pan, Yuyuan Liu, Min Xu, and Yueming Jin. Git context controller: Manage the context of llm-based agents like git.arXiv preprint arXiv:2508.00031, 2025
-
[27]
Mmed-rag: Versatile multimodal rag system for medical vision language models
Peng Xia, Kangyu Zhu, Haoran Li, Tianze Wang, Weijia Shi, Sheng Wang, Linjun Zhang, James Zou, and Huaxiu Yao. Mmed-rag: Versatile multimodal rag system for medical vision language models. InThe Thirteenth International Conference on Learning Representations
-
[28]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations
-
[29]
An agentic system for rare disease diagnosis with traceable reasoning.Nature, pages 1–10, 2026
Weike Zhao, Chaoyi Wu, Yanjie Fan, Pengcheng Qiu, Xiaoman Zhang, Yuze Sun, Xiao Zhou, Shuju Zhang, Yu Peng, Yanfeng Wang, et al. An agentic system for rare disease diagnosis with traceable reasoning.Nature, pages 1–10, 2026
2026
-
[30]
Ask patients with patience: Enabling llms for human-centric medical dialogue with grounded reasoning
Jiayuan Zhu, Jiazhen Pan, Yuyuan Liu, Fenglin Liu, and Junde Wu. Ask patients with patience: Enabling llms for human-centric medical dialogue with grounded reasoning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2846–2857, 2025. 9
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.