Recognition: unknown
M3D-Net: Multi-Modal 3D Facial Feature Reconstruction Network for Deepfake Detection
Pith reviewed 2026-05-10 11:14 UTC · model grok-4.3
The pith
Reconstructing 3D facial geometry and reflectance from single RGB images enables a dual-stream network to detect deepfakes more accurately by fusing complementary features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
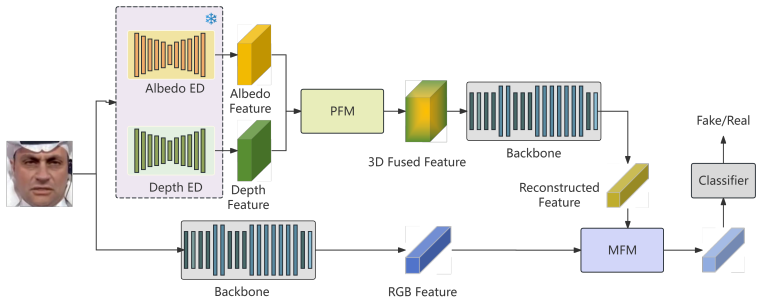
M3D-Net employs an end-to-end dual-stream architecture that reconstructs fine-grained facial geometry and reflectance properties from single-view RGB images via a self-supervised 3D facial reconstruction module. The network further enhances detection performance through a 3D Feature Pre-fusion Module that adaptively adjusts multi-scale features and a Multi-modal Fusion Module that effectively integrates RGB and 3D-reconstructed features using attention mechanisms.
What carries the argument
The self-supervised 3D facial reconstruction module that recovers geometry and reflectance from single-view images, together with the Multi-modal Fusion Module that uses attention to combine the RGB and 3D streams.
Load-bearing premise
The self-supervised 3D facial reconstruction accurately recovers fine-grained geometry and reflectance from single RGB images, and these 3D features supply useful complementary information that improves deepfake detection.
What would settle it
An experiment on a dataset of deepfakes engineered to match real facial 3D geometry while retaining other artifacts, checking whether the full M3D-Net accuracy falls back to the level of an RGB-only baseline.
Figures




read the original abstract
With the rapid advancement of deep learning in image generation, facial forgery techniques have achieved unprecedented realism, posing serious threats to cybersecurity and information authenticity. Most existing deepfake detection approaches rely on the reconstruction of isolated facial attributes without fully exploiting the complementary nature of multi-modal feature representations. To address these challenges, this paper proposes a novel Multi-Modal 3D Facial Feature Reconstruction Network (M3D-Net) for deepfake detection. Our method leverages an end-to-end dual-stream architecture that reconstructs fine-grained facial geometry and reflectance properties from single-view RGB images via a self-supervised 3D facial reconstruction module. The network further enhances detection performance through a 3D Feature Pre-fusion Module (PFM), which adaptively adjusts multi-scale features, and a Multi-modal Fusion Module (MFM) that effectively integrates RGB and 3D-reconstructed features using attention mechanisms. Extensive experiments on multiple public datasets demonstrate that our approach achieves state-of-the-art performance in terms of detection accuracy and robustness, significantly outperforming existing methods while exhibiting strong generalization across diverse scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes M3D-Net, an end-to-end dual-stream architecture for deepfake detection. It incorporates a self-supervised 3D facial reconstruction module to recover fine-grained geometry and reflectance properties from single-view RGB images, a 3D Feature Pre-fusion Module (PFM) for adaptive multi-scale feature adjustment, and a Multi-modal Fusion Module (MFM) that integrates RGB and reconstructed 3D features via attention mechanisms. The authors claim that extensive experiments on multiple public datasets demonstrate state-of-the-art detection accuracy, robustness, and strong generalization across scenarios.
Significance. If the central claims hold, the work could advance multi-modal deepfake detection by exploiting potential 3D inconsistencies in forged faces through self-supervised reconstruction and attention-based fusion. This direction addresses limitations of RGB-only methods and could improve generalization if the 3D features supply genuine complementary signals rather than reconstruction artifacts.
major comments (2)
- [Abstract] Abstract: the claim that the approach 'achieves state-of-the-art performance in terms of detection accuracy and robustness, significantly outperforming existing methods' is unsupported by any quantitative metrics, ablation results, dataset names, or comparison tables. This absence prevents evaluation of the central empirical claim.
- [Method] Self-supervised 3D facial reconstruction module (method description): no quantitative reconstruction metrics (e.g., landmark error, normal-map consistency, or reflectance error) are reported on deepfake versus real test images. This is load-bearing for the claim that 3D features provide complementary information, as higher reconstruction error on fakes could turn the module into an artifact detector rather than a source of true geometry/reflectance signals.
minor comments (1)
- [Abstract] The abstract would be strengthened by briefly stating the specific public datasets used and one or two key performance numbers to ground the SOTA claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have revised the manuscript to strengthen the presentation of our results and the justification for the 3D reconstruction component.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the approach 'achieves state-of-the-art performance in terms of detection accuracy and robustness, significantly outperforming existing methods' is unsupported by any quantitative metrics, ablation results, dataset names, or comparison tables. This absence prevents evaluation of the central empirical claim.
Authors: We agree that the original abstract was too concise and did not include supporting quantitative details. In the revised manuscript we have updated the abstract to name the primary evaluation datasets (FaceForensics++, Celeb-DF, DFDC) and to report the key performance figures from our experiments, including the AUC and accuracy gains over prior state-of-the-art methods. We also explicitly reference the comparison tables and ablation studies that appear in Sections 4 and 5. revision: yes
-
Referee: [Method] Self-supervised 3D facial reconstruction module (method description): no quantitative reconstruction metrics (e.g., landmark error, normal-map consistency, or reflectance error) are reported on deepfake versus real test images. This is load-bearing for the claim that 3D features provide complementary information, as higher reconstruction error on fakes could turn the module into an artifact detector rather than a source of true geometry/reflectance signals.
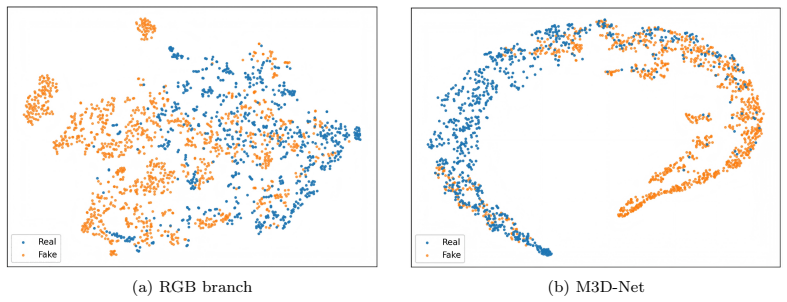
Authors: This observation is correct and highlights an important point. The reconstruction module is trained in a self-supervised manner exclusively on real facial images. When applied to deepfake inputs, the resulting 3D features are intended to expose geometric and reflectance inconsistencies introduced by the forgery. To directly address the concern, the revised manuscript now includes quantitative reconstruction metrics (average landmark error and normal-map consistency) computed separately on real and manipulated test images. These results show measurably higher reconstruction discrepancies on deepfakes, supporting that the 3D stream supplies complementary signals. We have also added qualitative reconstruction examples and attention visualizations from the MFM to illustrate how the fusion module exploits these discrepancies. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper describes an end-to-end dual-stream architecture consisting of a self-supervised 3D facial reconstruction module, a 3D Feature Pre-fusion Module (PFM), and a Multi-modal Fusion Module (MFM) with attention mechanisms. No equations, fitted parameters, or claims are presented that reduce a prediction or result to its own inputs by construction. Performance assertions rest on experimental results across public datasets rather than definitional equivalence or self-referential citations. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
T. Wang, X. Liao, K. P. Chow, X. Lin, Y. Wang, Deepfake detection: A comprehensive survey from the reliability perspective, ACM Computing Surveys 57 (3) (2024) 1–35
2024
- [2]
-
[3]
X. Zhu, H. Wang, H. Fei, Z. Lei, S. Z. Li, Face forgery detection by 3d decomposition, in: Proceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, 2021, pp. 2929–2939
2021
-
[4]
L. Li, J. Bao, T. Zhang, H. Yang, D. Chen, F. Wen, B. Guo, Face x-ray for more general face forgery detection, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 5001–5010
2020
-
[5]
J. Wang, Z. Wu, W. Ouyang, X. Han, J. Chen, Y.-G. Jiang, S.-N. Li, M2tr: Multi-modal multi-scale transformers for deepfake detection, in: Proceedingsofthe2022internationalconferenceonmultimediaretrieval, 2022, pp. 615–623
2022
-
[6]
Z. Guo, Z. Jia, L. Wang, D. Wang, G. Yang, N. Kasabov, Constructing new backbone networks via space-frequency interactive convolution for deepfake detection, IEEE Transactions on Information Forensics and Security 19 (2023) 401–413
2023
-
[7]
Sadhya, X
S. Sadhya, X. Qi, Enhanced deepfake detection leveraging multi- resolution wavelet convolutional networks, in: 2024 IEEE International Conference on Big Data (BigData), IEEE, 2024, pp. 8241–8243
2024
-
[8]
Y. Sun, H. H. Nguyen, C.-S. Lu, Z. Zhang, L. Sun, I. Echizen, General- ized deepfakes detection with reconstructed-blended images and multi- scale feature reconstruction network, in: 2024 IEEE International Joint Conference on Biometrics (IJCB), IEEE, 2024, pp. 1–11
2024
-
[9]
Y. Li, S. Bian, C. Wang, K. Polat, A. Alhudhaif, F. Alenezi, Expos- ing low-quality deepfake videos of social network service using spatial restored detection framework, Expert Systems with Applications 231 (2023) 120646
2023
- [10]
-
[11]
K. Sun, S. Chen, T. Yao, Z. Zhou, J. Ji, X. Sun, C.-W. Lin, R. Ji, Towards general visual-linguistic face forgery detection, in: Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 19576–19586. 25
2025
-
[12]
J. Tian, P. Chen, C. Yu, X. Fu, X. Wang, J. Dai, J. Han, Learning to discover forgery cues for face forgery detection, IEEE Transactions on Information Forensics and Security 19 (2024) 3814–3828
2024
-
[13]
L. B. Baru, R. Boddeda, S. A. Patel, S. M. Gajapaka, Wavelet-driven generalizable framework for deepfake face forgery detection, in: Pro- ceedings of the winter conference on applications of computer vision, 2025, pp. 1661–1669
2025
-
[14]
R.Han, X.Wang, N.Bai, J.Hou, W.Zhang, J.Li, Hsff-net: Hierarchical spectral-feature fusion network for deepfake detection and localization, Neural Networks (2025) 107967
2025
-
[15]
Y. Feng, H. Feng, M. J. Black, T. Bolkart, Learning an animatable detailed 3d face model from in-the-wild images, ACM Transactions on Graphics (ToG) 40 (4) (2021) 1–13
2021
-
[16]
S. Wu, C. Rupprecht, A. Vedaldi, Unsupervised learning of probably symmetric deformable 3d objects from images in the wild, in: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recog- nition, 2020, pp. 1–10
2020
-
[17]
Zhang, Y
Z. Zhang, Y. Ge, R. Chen, Y. Tai, Y. Yan, J. Yang, C. Wang, J. Li, F. Huang, Learning to aggregate and personalize 3d face from in-the- wild photo collection, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 14214–14224
2021
-
[18]
W. Guan, W. Wang, J. Dong, B. Peng, T. Tan, Robust face-swap de- tection based on 3d facial shape information, in: CAAI international conference on artificial intelligence, Springer, 2022, pp. 404–415
2022
-
[19]
Zhang, H
W. Zhang, H. Liu, F. Liu, R. Ramachandra, C. Busch, Effective pre- sentation attack detection driven by face related task, in: European Conference on Computer Vision, Springer, 2022, pp. 408–423
2022
-
[20]
Jourabloo, Y
A. Jourabloo, Y. Liu, X. Liu, Face de-spoofing: Anti-spoofing via noise modeling, in: Proceedings of the European conference on computer vi- sion (ECCV), 2018, pp. 290–306. 26
2018
-
[21]
H. Kato, Y. Ushiku, T. Harada, Neural 3d mesh renderer, in: Proceed- ings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3907–3916
2018
-
[22]
Johnson, A
J. Johnson, A. Alahi, L. Fei-Fei, Perceptual losses for real-time style transfer and super-resolution, in: Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14, Springer, 2016, pp. 694–711
2016
-
[23]
X. Li, W. Wang, X. Hu, J. Yang, Selective kernel networks, in: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 510–519
2019
- [24]
-
[25]
Rossler, D
A. Rossler, D. Cozzolino, L. Verdoliva, C. Riess, J. Thies, M. Nießner, Faceforensics++: Learning to detect manipulated facial images, in: Pro- ceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 1–11
2019
-
[26]
The DeepFake Detection Challenge (DFDC) Dataset
B. Dolhansky, J. Bitton, B. Pflaum, J. Lu, R. Howes, M. Wang, C. C. Ferrer, The deepfake detection challenge (dfdc) dataset, arXiv preprint arXiv:2006.07397 (2020)
work page internal anchor Pith review arXiv 2006
-
[27]
Dufour, A
N. Dufour, A. Gully, Contributing data to deepfake detection research, accessed: 2025-06-29 (2019). URLhttps://ai.googleblog.com/2019/09/contributing-data-to-deepfake-detection.html
2025
-
[28]
arXiv preprint arXiv:1910.08854 , year=
B. Dolhansky, R. Howes, B. Pflaum, N. Baram, C. C. Ferrer, The deepfake detection challenge (dfdc) preview dataset, arXiv preprint arXiv:1910.08854 (2019)
- [29]
-
[30]
Y. Li, X. Yang, P. Sun, H. Qi, S. Lyu, Celeb-df (v2): a new dataset for deepfake forensics [j], arXiv preprint arXiv (2019). 27
2019
-
[31]
2889–2898
L.Jiang, R.Li, W.Wu, C.Qian, C.C.Loy, Deeperforensics-1.0: Alarge- scale dataset for real-world face forgery detection, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2889–2898
2020
-
[32]
Chollet, Xception: Deep learning with depthwise separable convolu- tions, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp
F. Chollet, Xception: Deep learning with depthwise separable convolu- tions, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1251–1258
2017
-
[33]
Afchar, V
D. Afchar, V. Nozick, J. Yamagishi, I. Echizen, Mesonet: a compact fa- cial video forgery detection network, in: 2018 IEEE international work- shop on information forensics and security (WIFS), IEEE, 2018, pp. 1–7
2018
-
[34]
Y. Li, S. Lyu, Exposing deepfake videos by detecting face warping arti- facts, arXiv preprint arXiv:1811.00656 (2018)
work page Pith review arXiv 2018
-
[35]
H. Dang, F. Liu, J. Stehouwer, X. Liu, A. K. Jain, On the detection of digital face manipulation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern recognition, 2020, pp. 5781–5790
2020
-
[36]
Y. Qian, G. Yin, L. Sheng, Z. Chen, J. Shao, Thinking in frequency: Face forgery detection by mining frequency-aware clues, in: European conference on computer vision, Springer, 2020, pp. 86–103
2020
-
[37]
Y. Luo, Y. Zhang, J. Yan, W. Liu, Generalizing face forgery detection with high-frequency features, in: Proceedings of the IEEE/CVF confer- enceoncomputervisionandpatternrecognition, 2021, pp.16317–16326
2021
-
[38]
Z. Yan, Y. Zhang, Y. Fan, B. Wu, Ucf: Uncovering common features for generalizable deepfake detection, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22412–22423
2023
-
[39]
J. Cao, C. Ma, T. Yao, S. Chen, S. Ding, X. Yang, End-to-end reconstruction-classification learning for face forgery detection, in: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 4113–4122. 28
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.