Recognition: unknown
Pangu-ACE: Adaptive Cascaded Experts for Educational Response Generation on EduBench
Pith reviewed 2026-05-10 11:24 UTC · model grok-4.3
The pith
A 1B tutor-router generates draft answers and decides when to escalate educational queries to a 7B specialist, lifting deterministic quality from 0.457 to 0.538 and format validity from 0.707 to 0.866 on 7013 Chinese samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The adaptive cascade accepts 1B-generated drafts when routing signals indicate sufficiency and otherwise escalates to the 7B specialist; on the 7013-sample Chinese archive this raises deterministic quality from 0.457 to 0.538 and format validity from 0.707 to 0.866 relative to the legacy rule_v2 baseline while handling 19.7 percent of requests at the 1B level.
What carries the argument
The 1B tutor-router that produces a draft answer plus routing signals to decide acceptance or escalation to the 7B specialist prompt.
If this is right
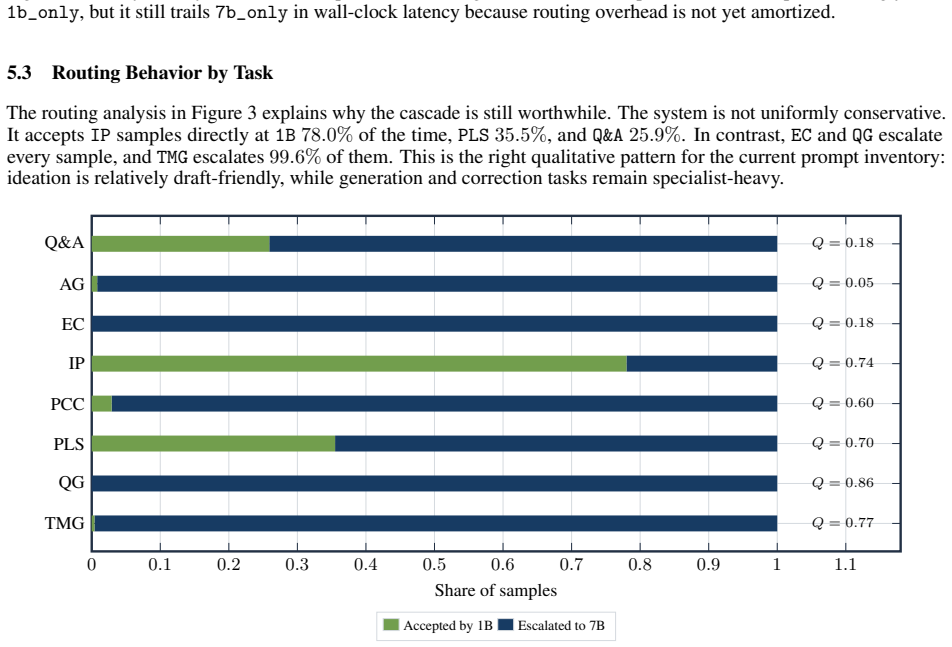
- Task-dependent routing allows high acceptance rates on simpler queries such as IP (78 percent) while reserving the 7B model for harder ones like QG and EC.
- Corrected rescoring of saved JSONL outputs reveals larger gains in format validity than earlier superficial checks suggested.
- The efficiency argument rests on routing selectivity rather than demonstrated wall-clock latency reduction.
- The system still leaves an external baseline gap that requires a valid GPT-5.4 endpoint to close.
Where Pith is reading between the lines
- If routing accuracy were measured directly rather than inferred from acceptance rates, further reductions in average model size might become possible.
- The observed task-specific patterns suggest that per-task router calibration could increase the fraction of requests handled at the 1B level without quality loss.
- The same cascade structure could be tested on non-educational domains where query difficulty also varies widely.
Load-bearing premise
The 1B model's routing signals and draft answers reliably indicate when escalation to the 7B specialist is unnecessary.
What would settle it
A side-by-side quality comparison, on the same 1B-accepted samples, between the 1B drafts and what the 7B model would have produced if always used, to test whether accepted cases truly preserve the higher quality.
Figures




read the original abstract
Educational assistants should spend more computation only when the task needs it. This paper rewrites our earlier draft around the system that was actually implemented and archived in the repository: a sample-level 1B to 7B cascade for the shared-8 EduBench benchmark. The final system, Pangu-ACE, uses a 1B tutor-router to produce a draft answer plus routing signals, then either accepts the draft or escalates the sample to a 7B specialist prompt. We also correct a major offline evaluation bug: earlier summaries over-credited some open-form outputs that only satisfied superficial format checks. After CPU-side rescoring from saved prediction JSONL, the full Chinese test archive (7013 samples) shows that cascade_final improves deterministic quality from 0.457 to 0.538 and format validity from 0.707 to 0.866 over the legacy rule_v2 system while accepting 19.7% of requests directly at 1B. Routing is strongly task dependent: IP is accepted by 1B 78.0% of the time, while QG and EC still escalate almost always. The current archived deployment does not yet show latency gains, so the defensible efficiency story is routing selectivity rather than wall-clock speedup. We also package a reproducible artifact-first paper workflow and clarify the remaining external-baseline gap: GPT-5.4 re-judging is implemented locally, but the configured provider endpoint and key are invalid, so final sampled-baseline alignment with GPT-5.4 remains pending infrastructure repair.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Pangu-ACE, an adaptive cascaded expert system for educational response generation on the EduBench benchmark. A 1B tutor-router generates draft answers and routing signals for each sample; the draft is accepted or the query is escalated to a 7B specialist. After correcting an offline evaluation bug via CPU-side rescoring of saved JSONL outputs, the system reports gains on the full Chinese test archive (7013 samples): deterministic quality rises from 0.457 to 0.538 and format validity from 0.707 to 0.866 relative to the legacy rule_v2 baseline, while routing 19.7% of requests directly to the 1B model. Routing behavior is strongly task-dependent (78% acceptance on IP, near-zero on QG/EC). The manuscript emphasizes a reproducible artifact-first workflow and notes that the GPT-5.4 baseline comparison remains pending infrastructure repair.
Significance. If the routing decisions are shown to be accurate rather than merely conservative, the work provides a concrete demonstration of selective computation in educational AI, backed by large-scale empirical gains, an explicit bug fix in evaluation, and packaged reproducibility artifacts. The task-dependent acceptance rates and focus on deterministic quality metrics offer a falsifiable efficiency story centered on routing selectivity rather than claimed wall-clock speedups.
major comments (3)
- [cascade_final system and routing description] The central claim that adaptive routing (rather than the 7B specialist alone) drives the observed quality and validity gains rests on the 1B model's routing signals correctly predicting when its draft suffices. No controlled validation against an oracle that escalates only when 7B output demonstrably improves the deterministic quality score is described, nor are precision/recall or false-escalation rates reported. Task-dependent acceptance rates are presented as post-hoc evidence of selectivity but do not test decision quality.
- [evaluation results on full Chinese test archive] Reported metric improvements (deterministic quality 0.457→0.538, format validity 0.707→0.866 on 7013 samples) are given as point estimates without error bars, confidence intervals, or statistical significance tests, weakening the strength of the cross-system comparison.
- [external baseline discussion] The GPT-5.4 baseline re-judging is implemented locally but the provider endpoint and key are invalid, leaving the sampled-baseline alignment pending. This gap affects the external validity of the efficiency and quality claims.
minor comments (2)
- [system implementation] The manuscript could clarify the exact decision rule (thresholds or combination of signals) used by the 1B tutor-router to accept or escalate, ideally with pseudocode or a small example.
- [results] Figure or table presenting per-task acceptance rates and quality deltas would improve readability of the task-dependent routing results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below. Revisions have been made where feasible to incorporate statistical analysis and to clarify limitations, while maintaining the manuscript's focus on routing selectivity and reproducibility.
read point-by-point responses
-
Referee: The central claim that adaptive routing (rather than the 7B specialist alone) drives the observed quality and validity gains rests on the 1B model's routing signals correctly predicting when its draft suffices. No controlled validation against an oracle that escalates only when 7B output demonstrably improves the deterministic quality score is described, nor are precision/recall or false-escalation rates reported. Task-dependent acceptance rates are presented as post-hoc evidence of selectivity but do not test decision quality.
Authors: We agree that an oracle validation comparing 7B outputs on accepted samples would provide stronger evidence of routing decision quality. However, the manuscript frames the contribution around observable selectivity and aggregate gains rather than optimality of the router. The task-dependent acceptance rates (78% on IP versus near-zero on QG/EC) are presented as supporting evidence of non-trivial routing behavior. We have partially revised the manuscript to add an explicit limitations paragraph acknowledging the absence of oracle or precision/recall analysis and to reinforce that the efficiency claim centers on selectivity, not proven routing accuracy. revision: partial
-
Referee: Reported metric improvements (deterministic quality 0.457→0.538, format validity 0.707→0.866 on 7013 samples) are given as point estimates without error bars, confidence intervals, or statistical significance tests, weakening the strength of the cross-system comparison.
Authors: We accept this point. The evaluation was performed by rescoring saved JSONL outputs on the full 7013-sample Chinese test archive. We have added bootstrap-derived 95% confidence intervals for all reported metrics and a brief statement on the statistical significance of the observed improvements in the revised results section. revision: yes
-
Referee: The GPT-5.4 baseline re-judging is implemented locally but the provider endpoint and key are invalid, leaving the sampled-baseline alignment pending. This gap affects the external validity of the efficiency and quality claims.
Authors: We thank the referee for highlighting this. The manuscript already notes that GPT-5.4 re-judging remains pending infrastructure repair. We have revised the external-baseline discussion to state this limitation more prominently and to clarify that the core claims concern internal gains over rule_v2 together with the packaged reproducibility artifacts. revision: partial
Circularity Check
No significant circularity; empirical benchmark results on held-out samples
full rationale
The paper presents an implemented cascaded 1B-to-7B system evaluated on the full Chinese test archive of 7013 samples, reporting deterministic quality and format validity improvements plus task-dependent acceptance rates. No equations, derivations, or first-principles claims appear; the central results are direct empirical measurements after rescoring saved outputs. Routing selectivity is described via observed acceptance rates rather than any fitted parameter renamed as a prediction or self-referential definition. Self-citations, if present, are not load-bearing for any core claim, and the work remains self-contained against external benchmarks without reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Educational response quality and format validity can be measured deterministically from model outputs on EduBench.
Reference graph
Works this paper leans on
-
[1]
T. Cai, Y . Li, Z. Geng, H. Peng, J. D. Lee, D. Chen, and T. Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads. InInternational Conference on Machine Learning, 2024
2024
- [2]
-
[3]
L. Chen, M. Zaharia, and J. Zou. Frugalgpt: How to use large language models while reducing cost and improving performance.arXiv preprint arXiv:2305.05176, 2023
work page internal anchor Pith review arXiv 2023
-
[4]
T. Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. InInternational Conference on Learning Representations, 2024
2024
-
[5]
T. Dao, D. Y . Fu, S. Ermon, A. Rudra, and C. Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. InAdvances in Neural Information Processing Systems, 2022. 9 Pangu-ACE: Adaptive Cascaded Experts on EduBench
2022
-
[6]
Hwang et al
I. Hwang et al. Routellm: Learning to route llms with preference data. InInternational Conference on Machine Learning, 2024
2024
-
[7]
Kahneman.Thinking, fast and slow
D. Kahneman.Thinking, fast and slow. Macmillan, 2011
2011
-
[8]
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and J. E. Gonzalez. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating Systems Principles, 2023
2023
-
[9]
Leviathan, M
Y . Leviathan, M. Kalman, and Y . Matias. Fast inference from transformers via speculative decoding. In International Conference on Machine Learning, 2023
2023
-
[10]
Y . Li, F. Wei, C. Zhang, and H. Zhang. Eagle: Speculative sampling requires rethinking feature uncertainty. In International Conference on Machine Learning, 2024
2024
-
[11]
Schick, J
T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, L. Zettlemoyer, N. Cancedda, and T. Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems, 2023
2023
-
[12]
Shinn, F
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, 2023
2023
-
[13]
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y . Lin, et al. A survey on large language model based autonomous agents. InFrontiers of Computer Science, 2024
2024
-
[14]
X. Wang, J. Wei, D. Schuurmans, Q. V . Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Dai. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations, 2023
2023
-
[15]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, and D. Zhou. Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 35:24824–24837, 2022
2022
-
[16]
System 2 atten- tion (is something you might need too)
J. Weston and S. Sukhbaatar. System 2 attention (is something you might need too).arXiv preprint arXiv:2311.11829, 2023
-
[17]
Xu et al
Y . Xu et al. Large language models for education: A survey and outlook.arXiv preprint, 2024
2024
-
[18]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023
2023
-
[19]
E. Zelikman et al. Quiet-star: Language models can teach themselves to think before speaking.arXiv preprint arXiv:2403.09629, 2024
-
[20]
J. Zeng, Y . Zha, W. Wang, Y . Wang, C. Ma, X. Liu, L. Luo, X. Yang, H. Wu, W. Zeng, X. Zhang, J. Huang, W. Du, S. Yang, W. Ye, R. Luo, X. Liu, Y . Wang, C. Xiao, Z. Li, X. Zhu, K. Chen, Q. Dong, W. Gao, Z. Sui, B. Chang, K. Kuang, R. Wang, and F. Huang. Edubench: Evaluating llms as comprehensive education agents.arXiv preprint arXiv:2412.13047, 2024. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.