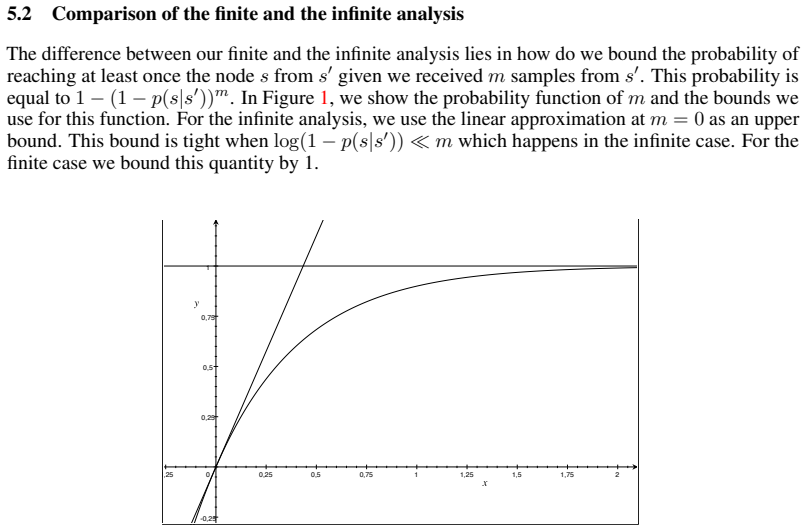
Blazing the trails before beating the path: Sample-efficient Monte-Carlo planning
Pith reviewed 2026-05-10 12:13 UTC · model grok-4.3
The pith
TrailBlazer extends Monte-Carlo sampling to alternating max and expectation problems in MDPs, with sample complexity depending on the number of near-optimal states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TrailBlazer is an extension of Monte-Carlo sampling to problems that alternate maximization over actions and expectation over next states. It achieves sample complexity guarantees that depend on a measure of the quantity of near-optimal states by identifying and focusing on the subset of states reachable by near-optimal policies without prior knowledge of the optimal policy.
What carries the argument
TrailBlazer algorithm, which identifies and prioritizes sampling along trajectories reachable by near-optimal policies in an alternating max-expectation MDP structure.
If this is right
- Planning remains computationally efficient and avoids exponential running time.
- Sample requirements scale with the quantity of near-optimal states instead of total states.
- The approach applies to MDPs with either finite or infinite transitions from each state-action pair.
- No prior knowledge of the optimal policy is required to achieve the improved sample bounds.
Where Pith is reading between the lines
- The focus on near-optimal reachable sets could be adapted to other tree-search methods that currently explore entire action spaces.
- In practice this would lower the cost of planning when many states lead to clearly suboptimal outcomes.
- Similar ideas might reduce sample needs in continuous-state settings by approximating the near-optimal subset.
Load-bearing premise
The MDP provides a generative model that can be queried for next-state samples, and the algorithm can locate the relevant subset of near-optimal reachable states on its own.
What would settle it
Compare the number of samples TrailBlazer needs versus a standard Monte-Carlo planner to reach a target policy value in an MDP where only a small fraction of states are reachable by near-optimal policies.
Figures
read the original abstract
You are a robot and you live in a Markov decision process (MDP) with a finite or an infinite number of transitions from state-action to next states. You got brains and so you plan before you act. Luckily, your roboparents equipped you with a generative model to do some Monte-Carlo planning. The world is waiting for you and you have no time to waste. You want your planning to be efficient. Sample-efficient. Indeed, you want to exploit the possible structure of the MDP by exploring only a subset of states reachable by following near-optimal policies. You want guarantees on sample complexity that depend on a measure of the quantity of near-optimal states. You want something, that is an extension of Monte-Carlo sampling (for estimating an expectation) to problems that alternate maximization (over actions) and expectation (over next states). But you do not want to StOP with exponential running time, you want something simple to implement and computationally efficient. You want it all and you want it now. You want TrailBlazer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TrailBlazer, an algorithm that extends Monte-Carlo sampling to MDPs with alternating maximization over actions and expectation over next states. It claims sample-efficient planning by focusing exploration on the subset of states reachable by near-optimal policies, yielding sample-complexity bounds governed by a measure of the quantity of such near-optimal states. The approach assumes access to a generative model and aims to remain computationally efficient and simple to implement without incurring exponential running time.
Significance. If the claimed bounds hold and are non-vacuous, the result would be a meaningful contribution to sample-efficient planning in structured MDPs. By deriving complexity from the measure of near-optimal reachable states rather than the full state space, the work provides a principled way to exploit MDP structure without prior knowledge of the optimal policy. The extension from pure expectation estimation to max/exp alternation is a natural generalization that could apply to a range of planning problems.
minor comments (2)
- [Abstract] The abstract is written in an informal, first-person narrative style. A more conventional technical abstract would improve readability and align with journal conventions.
- [Introduction] Clarify the precise definition of the near-optimal state measure early in the paper and contrast it explicitly with related notions such as the set of states visited by epsilon-optimal policies in prior MDP literature.
Simulated Author's Rebuttal
We thank the referee for their positive summary of TrailBlazer and for recommending minor revision. The description accurately reflects the algorithm's extension of Monte-Carlo methods to alternating max/exp steps and its focus on near-optimal reachable states. No specific major comments were provided in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The provided abstract and context describe TrailBlazer as a direct algorithmic extension of Monte-Carlo sampling to max/exp alternation in MDPs, with sample-complexity bounds expressed in terms of an externally defined measure of near-optimal reachable states. No equations, proofs, or self-citations are shown that would reduce the claimed guarantees to a fitted parameter, a self-referential quantity, or an ansatz imported from prior author work. The generative-model assumption and focus mechanism are presented as standard inputs rather than outputs of the analysis. This matches the reader's non-circular assessment; the central claim retains independent content relative to its stated assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The MDP is equipped with a generative model that returns next-state samples on demand.
Reference graph
Works this paper leans on
-
[1]
Finite-time analysis of the multiarmed bandit problem.Machine Learning, 47(2-3):235–256, 2002
Peter Auer, Nicolò Cesa-Bianchi, and Paul Fischer. Finite-time analysis of the multiarmed bandit problem.Machine Learning, 47(2-3):235–256, 2002
work page 2002
-
[2]
Princeton University Press, Princeton, NJ, 1957
Richard Bellman.Dynamic Programming. Princeton University Press, Princeton, NJ, 1957
work page 1957
-
[3]
Athena Scientific, Belmont, MA, 1996
Dimitri Bertsekas and John Tsitsiklis.Neuro-Dynamic Programming. Athena Scientific, Belmont, MA, 1996
work page 1996
-
[4]
Browne, Edward Powley, Daniel Whitehouse, Simon M
Cameron B. Browne, Edward Powley, Daniel Whitehouse, Simon M. Lucas, Peter I. Cowling, Philipp Rohlfshagen, Stephen Tavener, Diego Perez, Spyridon Samothrakis, and Simon Colton. A survey of Monte Carlo tree search methods.IEEE Transactions on Computational Intelligence and AI in Games, 4(1):1–43, 2012
work page 2012
-
[5]
Sébastien Bubeck and Rémi Munos. Open-loop optimistic planning. InConference on Learning Theory, 2010
work page 2010
-
[6]
Optimistic planning for Markov decision processes
Lucian Bu¸ soniu and Rémi Munos. Optimistic planning for Markov decision processes. In International Conference on Artificial Intelligence and Statistics, 2012
work page 2012
-
[7]
Rémi Coulom. Efficient selectivity and backup operators in Monte-Carlo tree search.Computers and games, 4630:72–83, 2007
work page 2007
-
[8]
Modification of UCT with patterns in Monte-Carlo Go
Sylvain Gelly, Wang Yizao, Rémi Munos, and Olivier Teytaud. Modification of UCT with patterns in Monte-Carlo Go. Technical report, Inria, 2006. URL https://hal.inria.fr/ inria-00117266
work page 2006
-
[9]
Arthur Guez, David Silver, and Peter Dayan. Efficient Bayes-adaptive reinforcement learning using sample-based search.Neural Information Processing Systems, 2012
work page 2012
-
[10]
Optimistic Planning of Deterministic Systems
Jean-Francois Hren and Rémi Munos. Optimistic Planning of Deterministic Systems. In European Workshop on Reinforcement Learning, 2008
work page 2008
-
[11]
Michael Kearns, Yishay Mansour, and Andrew Y . Ng. A sparse sampling algorithm for near- optimal planning in large Markov decision processes. InInternational Conference on Artificial Intelligence and Statistics, 1999
work page 1999
-
[12]
Bandit-based Monte-Carlo planning
Levente Kocsis and Csaba Szepesvári. Bandit-based Monte-Carlo planning. InEuropean Conference on Machine Learning, 2006
work page 2006
-
[13]
Rémi Munos. From bandits to Monte-Carlo tree search: The optimistic principle applied to optimization and planning.Foundations and Trends in Machine Learning, 7(1):1–130, 2014
work page 2014
-
[14]
Monte-Carlo planning in large POMDPs
David Silver and Joel Veness. Monte-Carlo planning in large POMDPs. InNeural Information Processing Systems, 2010
work page 2010
-
[15]
David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driess- che, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Mastering the...
work page 2016
-
[16]
Optimistic planning in Markov decision processes using a generative model
Balázs Szörényi, Gunnar Kedenburg, and Rémi Munos. Optimistic planning in Markov decision processes using a generative model. InNeural Information Processing Systems, 2014
work page 2014
-
[17]
Thomas J Walsh, Sergiu Goschin, and Michael L Littman. Integrating sample-based planning and model-based reinforcement learning.AAAI Conference on Artificial Intelligence, 2010. 12 A Additional notation for the analysis In this part, we define new quantities to be used in the other part of the appendix. For all MAX nodes i and time t, we denote µs,t i the...
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.