Building Extraction from Remote Sensing Imagery under Hazy and Low-light Conditions: Benchmark and Baseline
Pith reviewed 2026-05-10 12:01 UTC · model grok-4.3
The pith
A new benchmark and end-to-end network enable reliable building extraction from remote sensing images despite haze and low light.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By integrating spatial-frequency attention, global semantic anchoring, and bidirectional fusion into one framework, HaLoBuild-Net performs building extraction directly from degraded optical remote sensing imagery without a separate restoration stage, delivering better accuracy than cascaded approaches on hazy and low-light data while generalizing to clear conditions.
What carries the argument
The Spatial-Frequency Focus Module (SFFM) that combines large receptive field attention with frequency-aware channel reweighting using stable low-frequency anchors to reduce the impact of meteorological interference on building features.
If this is right
- Building extraction pipelines can skip the error-prone step of restoring images first and extract features directly.
- The network preserves strong performance when applied to standard clear-condition datasets without retraining.
- Global constraints from the multi-scale module help maintain consistent building shapes even when parts of the image are obscured.
- Boundary details remain sharp because the fusion module calibrates semantic and spatial information bidirectionally.
Where Pith is reading between the lines
- The same module design could be adapted for extracting other ground features such as roads or farmland under similar degradations.
- Combining this optical approach with synthetic aperture radar data might yield systems that work in any weather.
- Extending the benchmark to additional degradation types like heavy rain or cloud cover would test broader applicability.
Load-bearing premise
Pairing images taken at different times of the exact same scene produces building labels that stay accurate and pixel-aligned even when one image is severely affected by haze or darkness.
What would settle it
A visual inspection or quantitative check revealing that building outlines in the degraded images deviate substantially from those in the paired clear images would show the labels are unreliable and undermine the benchmark.
Figures











read the original abstract
Building extraction from optical Remote Sensing (RS) imagery suffers from performance degradation under real-world hazy and low-light conditions. However, existing optical methods and benchmarks focus primarily on ideal clear-weather conditions. While SAR offers all-weather sensing, its side-looking geometry causes geometric distortions. To address these challenges, we introduce HaLoBuilding, the first optical benchmark specifically designed for building extraction under hazy and low-light conditions. By leveraging a same-scene multitemporal pairing strategy, we ensure pixel-level label alignment and high fidelity even under extreme degradation. Building upon this benchmark, we propose HaLoBuild-Net, a novel end-to-end framework for building extraction in adverse RS scenarios. At its core, we develop a Spatial-Frequency Focus Module (SFFM) to effectively mitigate meteorological interference on building features by coupling large receptive field attention with frequency-aware channel reweighting guided by stable low-frequency anchors. Additionally, a Global Multi-scale Guidance Module (GMGM) provides global semantic constraints to anchor building topologies, while a Mutual-Guided Fusion Module (MGFM) implements bidirectional semantic-spatial calibration to suppress shallow noise and sharpen weather-induced blurred boundaries. Extensive experiments demonstrate that HaLoBuild-Net significantly outperforms state-of-the-art methods and conventional cascaded restoration-segmentation paradigms on the HaLoBuilding dataset, while maintaining robust generalization on WHU, INRIA, and LoveDA datasets. The source code and datasets are publicly available at: https://github.com/AeroVILab-AHU/HaLoBuilding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HaLoBuilding, the first benchmark dataset for building extraction from optical remote sensing imagery under hazy and low-light conditions, constructed using a same-scene multitemporal pairing strategy to maintain pixel-level label alignment despite degradation. It proposes HaLoBuild-Net, an end-to-end framework with three modules: Spatial-Frequency Focus Module (SFFM) for mitigating meteorological interference via attention and frequency reweighting, Global Multi-scale Guidance Module (GMGM) for semantic constraints on building topologies, and Mutual-Guided Fusion Module (MGFM) for bidirectional calibration to reduce noise and sharpen boundaries. Experiments claim significant outperformance over SOTA methods and cascaded restoration-segmentation approaches on HaLoBuilding, with robust generalization to WHU, INRIA, and LoveDA datasets; code and data are released publicly.
Significance. If the benchmark labels are verifiably accurate and the performance gains hold under rigorous controls, this addresses a practical gap in real-world remote sensing applications where haze and low light are prevalent, such as disaster monitoring and urban mapping. The end-to-end design avoids error propagation from separate restoration steps, and public release of data/code enables reproducibility and further research.
major comments (2)
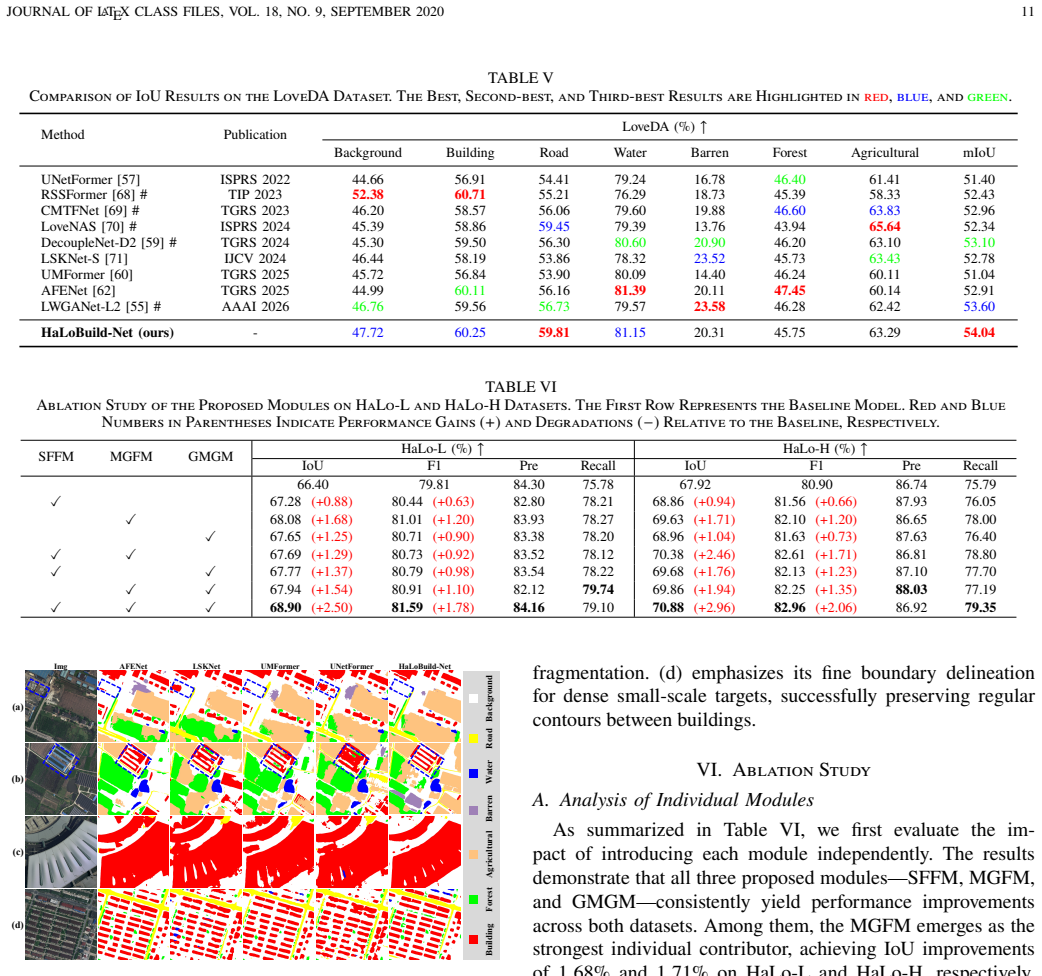
- [HaLoBuilding benchmark construction] In the HaLoBuilding benchmark construction section: the claim that the same-scene multitemporal pairing strategy 'ensure[s] pixel-level label alignment and high fidelity even under extreme degradation' is load-bearing for all downstream claims, yet the manuscript provides no quantitative validation such as registration error statistics (e.g., RMSE or overlap metrics), temporal change detection rates, or analysis of failure cases induced by haze-induced registration drift or scene changes (new construction, vegetation). Without this, label noise could inflate apparent method performance and undermine the generalization results reported on HaLoBuilding.
- [Experiments and ablations] In the experimental results and ablation sections: while outperformance is asserted, the paper should provide per-module ablation tables (isolating SFFM, GMGM, MGFM contributions) and stratified error analysis across degradation severity levels to substantiate that gains are not artifacts of the new benchmark or dataset-specific tuning.
minor comments (2)
- [Dataset description] Clarify the precise composition of HaLoBuilding (number of image pairs, haze/low-light severity distribution, and how labels were transferred) with a dedicated table for transparency.
- [Figures] Improve figure captions and legends in the qualitative comparison figures to explicitly label degradation conditions and method names for easier cross-reference with quantitative tables.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: In the HaLoBuilding benchmark construction section: the claim that the same-scene multitemporal pairing strategy 'ensure[s] pixel-level label alignment and high fidelity even under extreme degradation' is load-bearing for all downstream claims, yet the manuscript provides no quantitative validation such as registration error statistics (e.g., RMSE or overlap metrics), temporal change detection rates, or analysis of failure cases induced by haze-induced registration drift or scene changes (new construction, vegetation). Without this, label noise could inflate apparent method performance and undermine the generalization results reported on HaLoBuilding.
Authors: We thank the referee for highlighting this critical aspect. The same-scene multitemporal pairing strategy was specifically designed to achieve pixel-level alignment by matching degraded images with clear reference images from identical geographic locations and minimal temporal gaps. We acknowledge that the current manuscript lacks explicit quantitative validation of registration accuracy and potential failure modes. In the revised manuscript, we will add registration error statistics (RMSE and overlap metrics), temporal change detection rates, and a dedicated analysis of failure cases arising from haze-induced drift or scene alterations such as new construction or vegetation changes. This addition will directly substantiate the benchmark's label fidelity. revision: yes
-
Referee: In the experimental results and ablation sections: while outperformance is asserted, the paper should provide per-module ablation tables (isolating SFFM, GMGM, MGFM contributions) and stratified error analysis across degradation severity levels to substantiate that gains are not artifacts of the new benchmark or dataset-specific tuning.
Authors: We agree that isolating module contributions and providing stratified analysis are necessary to rigorously validate the design choices and exclude benchmark-specific artifacts. In the revised manuscript, we will include comprehensive per-module ablation tables that separately quantify the impact of SFFM, GMGM, and MGFM. We will also add stratified error analysis broken down by degradation severity levels (e.g., mild, moderate, and severe haze/low-light conditions) on HaLoBuilding to demonstrate that the observed gains are attributable to the proposed components rather than tuning effects. revision: yes
Circularity Check
No circularity; empirical benchmark and network proposal are self-contained
full rationale
The paper introduces the HaLoBuilding dataset via a same-scene multitemporal pairing strategy and proposes HaLoBuild-Net with modules SFFM, GMGM, and MGFM for building extraction under haze and low light. All claims rest on empirical training and testing against the constructed labels and external datasets (WHU, INRIA, LoveDA), with no mathematical derivation chain, fitted parameters renamed as predictions, or load-bearing self-citations that reduce the central result to its own inputs by construction. The pairing strategy is presented as a data-construction method rather than a self-referential prediction, and performance metrics are measured directly against the resulting annotations without circular re-use of fitted quantities.
Axiom & Free-Parameter Ledger
free parameters (1)
- network hyperparameters and module design choices
axioms (1)
- domain assumption Same-scene multitemporal pairing provides pixel-level accurate labels under extreme hazy and low-light degradation
Reference graph
Works this paper leans on
-
[1]
Automatic building rooftop extraction from aerial images via hierarchical RGB-D priors,
S. Xu, X. Pan, E. Li, B. Wu, S. Bu, W. Dong, S. Xiang, and X. Zhang, “Automatic building rooftop extraction from aerial images via hierarchical RGB-D priors,”IEEE Trans. Geosci. Remote Sens., vol. 56, no. 12, pp. 7369–7387, 2018
work page 2018
-
[2]
Z. Zheng, Y. Zhong, J. Wang, A. Ma, and L. Zhang, “Building damage assessment for rapid disaster response with a deep object-based semantic change detection framework: From natural disasters to man-made disasters,”Remote Sens. Environ., vol. 265, p. 112636, 2021
work page 2021
-
[3]
W. Lu, H.-D. Li, C. Wang, S.-B. Chen, C. H. Ding, J. Tang, and B. Luo, “UnravelNet: A backbone for enhanced multi-scale and low-quality feature extraction in remote sensing object detection,”ISPRS J. Photogramm. Remote Sens., vol. 231, pp. 431–442, 2026
work page 2026
-
[4]
LEGNet: A lightweight edge-gaussian network for low-quality remote sensing image object detection,
W. Lu, S.-B. Chen, H.-D. Li, Q.-L. Shu, C. H. Q. Ding, J. Tang, and B. Luo, “LEGNet: A lightweight edge-gaussian network for low-quality remote sensing image object detection,” inProc. IEEE Conf. Int. Conf. Comput. Vis., October 2025, pp. 2844–2853
work page 2025
-
[5]
Rsrefseg 2: Decoupling referring remote sensing image segmentation with foundation models,
K. Chen, C. Liu, B. Chen, J. Zhang, Z. Zou, and Z. Shi, “Rsrefseg 2: Decoupling referring remote sensing image segmentation with foundation models,”IEEE Trans. Geosci. Remote Sens., vol. 64, pp. 1–20, 2026
work page 2026
-
[6]
D. Zhang, Y. Pan, J. Zhang, T. Hu, J. Zhao, N. Li, and Q. Chen, “A generalized approach based on convolutional neural networks for large area cropland mapping at very high resolution,”Remote Sens. Environ., vol. 247, p. 111912, 2020
work page 2020
-
[7]
Fully convolutional networks for semantic segmentation,
E. Shelhamer, J. Long, and T. Darrell, “Fully convolutional networks for semantic segmentation,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 4, pp. 640–651, 2017
work page 2017
-
[8]
Building extraction from remote sensing images with sparse token transformers,
K. Chen, Z. Zou, and Z. Shi, “Building extraction from remote sensing images with sparse token transformers,”Remote Sens., vol. 13, no. 21, p. 4441, 2021
work page 2021
-
[9]
C. Zhang, W. Jiang, Y. Zhang, W. Wang, Q. Zhao, and C. Wang, “Trans- former and cnn hybrid deep neural network for semantic segmentation of very-high-resolution remote sensing imagery,”IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–20, 2022
work page 2022
-
[10]
Easy-net: A lightweight building extraction network based on building features,
H. Huang, J. Liu, and R. Wang, “Easy-net: A lightweight building extraction network based on building features,”IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–15, 2024
work page 2024
-
[11]
End-to-end semantic segmen- tation network for low-light scenes,
H. Mu, G. Zhang, M. Zhou, and Z. Cao, “End-to-end semantic segmen- tation network for low-light scenes,” inProc. IEEE Int. Conf. Robot. Autom., 2024, pp. 7725–7731
work page 2024
-
[12]
Nightadapter: Learning a frequency adapter for generalizable night-time scene segmentation,
Q. Bi, J. Yi, H. Huang, H. Zheng, H. Zhan, Y. Huang, Y. Li, X. Wu, and Y. Zheng, “Nightadapter: Learning a frequency adapter for generalizable night-time scene segmentation,” inProc. IEEE Conf. Comput. Vis. Pattern Recog., 2025, pp. 23 838–23 849
work page 2025
-
[13]
F. Dornaika, A. Moujahid, Y. El Merabet, and Y. Ruichek, “Building detection from orthophotos using a machine learning approach: An empirical study on image segmentation and descriptors,”Expert Syst. Appl., vol. 58, pp. 130–142, 2016
work page 2016
-
[14]
Toward automatic building footprint delineation from aerial images using cnn and regularization,
S. Wei, S. Ji, and M. Lu, “Toward automatic building footprint delineation from aerial images using cnn and regularization,”IEEE Trans. Geosci. Remote Sens., vol. 58, no. 3, pp. 2178–2189, 2020
work page 2020
-
[15]
H. Zhang, Y. Liao, H. Yang, G. Yang, and L. Zhang, “A local–global dual- stream network for building extraction from very-high-resolution remote sensing images,”IEEE Trans. Neural Netw. Learn. Syst., vol. 33, no. 3, pp. 1269–1283, 2022
work page 2022
-
[16]
J. Chen, Y. Jiang, L. Luo, and W. Gong, “ASF-Net: Adaptive screening feature network for building footprint extraction from remote-sensing images,”IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–13, 2022
work page 2022
-
[17]
Q. Zhu, C. Liao, H. Hu, X. Mei, and H. Li, “MAP-Net: Multiple attending path neural network for building footprint extraction from remote sensed imagery,”IEEE Trans. Geosci. Remote Sens., vol. 59, no. 7, pp. 6169– 6181, 2021
work page 2021
-
[18]
H. Guo, Q. Shi, B. Du, L. Zhang, D. Wang, and H. Ding, “Scene- driven multitask parallel attention network for building extraction in high- resolution remote sensing images,”IEEE Trans. Geosci. Remote Sens., vol. 59, no. 5, pp. 4287–4306, 2021
work page 2021
-
[19]
X. Pan, F. Yang, L. Gao, Z. Chen, B. Zhang, H. Fan, and J. Ren, “Building extraction from high-resolution aerial imagery using a generative adver- sarial network with spatial and channel attention mechanisms,”Remote Sens., vol. 11, no. 8, p. 917, 2019
work page 2019
-
[20]
Multiscale building extraction with refined attention pyramid networks,
Q. Tian, Y. Zhao, Y. Li, J. Chen, X. Chen, and K. Qin, “Multiscale building extraction with refined attention pyramid networks,”IEEE Geosci. Remote Sens. Lett., vol. 19, pp. 1–5, 2022
work page 2022
-
[21]
H. Guo, B. Du, L. Zhang, and X. Su, “A coarse-to-fine boundary refinement network for building footprint extraction from remote sensing imagery,” ISPRS J. Photogramm. Remote Sens., vol. 183, pp. 240–252, 2022
work page 2022
-
[22]
Y. Zhou, Z. Chen, B. Wang, S. Li, H. Liu, D. Xu, and C. Ma, “BOMSC-Net: Boundary optimization and multi-scale context awareness based building extraction from high-resolution remote sensing imagery,”IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–17, 2022
work page 2022
-
[23]
H. Guo, X. Su, C. Wu, B. Du, and L. Zhang, “Decoupling semantic and edge representations for building footprint extraction from remote sensing images,”IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–16, 2023
work page 2023
-
[24]
Z. Liu, Q. Shi, and J. Ou, “LCS: A collaborative optimization framework of vector extraction and semantic segmentation for building extraction,” IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–15, 2022
work page 2022
-
[25]
UANet: An uncertainty- aware network for building extraction from remote sensing images,
J. Li, W. He, W. Cao, L. Zhang, and H. Zhang, “UANet: An uncertainty- aware network for building extraction from remote sensing images,”IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–13, 2024
work page 2024
-
[26]
M. Yang, L. Zhao, L. Ye, W. Jia, H. Jiang, and Z. Yang, “EGAFNet: An edge guidance and scale-aware adaptive fusion network for building extraction from remote sensing images,”IEEE Trans. Geosci. Remote Sens., vol. 63, pp. 1–13, 2025
work page 2025
-
[27]
Multiscale feature learning by transformer for building extraction from satellite images,
X. Chen, C. Qiu, W. Guo, A. Yu, X. Tong, and M. Schmitt, “Multiscale feature learning by transformer for building extraction from satellite images,”IEEE Geosci. Remote Sens. Lett., vol. 19, pp. 1–5, 2022
work page 2022
-
[28]
Transferring transformer-based models for cross-area building extraction from remote sensing images,
C. Qiu, H. Li, W. Guo, X. Chen, A. Yu, X. Tong, and M. Schmitt, “Transferring transformer-based models for cross-area building extraction from remote sensing images,”IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 15, pp. 4104–4116, 2022
work page 2022
-
[29]
D. Zhou, G. Wang, G. He, T. Long, R. Yin, Z. Zhang, S. Chen, and B. Luo, “Robust building extraction for high spatial resolution remote sensing images with self-attention network,”Sensors, vol. 20, no. 24, p. 7241, 2020
work page 2020
-
[30]
S. Wang, X. Hou, and X. Zhao, “Automatic building extraction from high- resolution aerial imagery via fully convolutional encoder-decoder network with non-local block,”IEEE Access, vol. 8, pp. 7313–7322, 2020
work page 2020
-
[31]
Building extraction with vision transformer,
L. Wang, S. Fang, X. Meng, and R. Li, “Building extraction with vision transformer,”IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–11, 2022
work page 2022
-
[32]
P. Zhu, Z. Song, J. Liu, J. Yan, X. Luo, and Y. Tao, “Mshformer: A multiscale hybrid transformer network with boundary enhancement for vhr remote sensing image building extraction,”IEEE Trans. Geosci. Remote Sens., vol. 63, pp. 1–16, 2025
work page 2025
-
[33]
M. Wang, L. Su, C. Yan, S. Xu, P. Yuan, X. Jiang, and B. Zhang, “RSBuilding: Toward general remote sensing image building extraction and change detection with foundation model,”IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–17, 2024
work page 2024
-
[34]
G. Xu, M. Deng, J. Zhu, G. Sun, Z. Gou, Y. Guo, and J. Chen, “A dual-contrast adaptation network coupling global context and geometry information for cross-domain building extraction,”IEEE Trans. Geosci. Remote Sens., vol. 63, pp. 1–16, 2025. JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 14
work page 2025
-
[35]
Hit: Building mapping with hierarchical transformers,
M. Zhang, Q. Liu, and Y. Wang, “Hit: Building mapping with hierarchical transformers,”IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–16, 2024
work page 2024
-
[36]
Zero- reference deep curve estimation for low-light image enhancement,
C. Guo, C. Li, J. Guo, C. C. Loy, J. Hou, S. Kwong, and R. Cong, “Zero- reference deep curve estimation for low-light image enhancement,” in Proc. IEEE Conf. Comput. Vis. Pattern Recog., 2020, pp. 1780–1789
work page 2020
-
[37]
AOD-Net: All-in-one dehazing network,
B. Li, X. Peng, Z. Wang, J. Xu, and D. Feng, “AOD-Net: All-in-one dehazing network,” inProc. IEEE Conf. Int. Conf. Comput. Vis., 2017, pp. 4780–4788
work page 2017
-
[38]
H. Wang, Y. Chen, Y. Cai, L. Chen, Y. Li, M. A. Sotelo, and Z. Li, “SFNet-N: An improved sfnet algorithm for semantic segmentation of low-light autonomous driving road scenes,”IEEE Trans. Intell. Transp. Syst., vol. 23, no. 11, pp. 21 405–21 417, 2022
work page 2022
-
[39]
Learning semantic-aware knowledge guidance for low-light image enhancement,
Y. Wu, C. Pan, G. Wang, Y. Yang, J. Wei, C. Li, and H. T. Shen, “Learning semantic-aware knowledge guidance for low-light image enhancement,” inProc. IEEE Conf. Comput. Vis. Pattern Recog., 2023, pp. 1662–1671
work page 2023
-
[40]
K. A. Hashmi, G. Kallempudi, D. Stricker, and M. Z. Afzal, “Featenhancer: Enhancing hierarchical features for object detection and beyond under low-light vision,” inProc. IEEE Conf. Int. Conf. Comput. Vis., 2023, pp. 6725–6735
work page 2023
-
[41]
Disentangle then parse: Night-time semantic segmentation with illumination disentangle- ment,
Z. Wei, L. Chen, T. Tu, P. Ling, H. Chen, and Y. Jin, “Disentangle then parse: Night-time semantic segmentation with illumination disentangle- ment,” inProc. IEEE Conf. Int. Conf. Comput. Vis., 2023, pp. 21 536– 21 546
work page 2023
-
[42]
Learning with nested scene modeling and cooperative architecture search for low-light vision,
R. Liu, L. Ma, T. Ma, X. Fan, and Z. Luo, “Learning with nested scene modeling and cooperative architecture search for low-light vision,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 5, pp. 5953–5969, 2023
work page 2023
-
[43]
Boosting Object Detection with Zero- Shot Day-Night Domain Adaptation,
Z. Du, M. Shi, and J. Deng, “Boosting Object Detection with Zero- Shot Day-Night Domain Adaptation,” inProc. IEEE Conf. Comput. Vis. Pattern Recog., 2024, pp. 12 666–12 676
work page 2024
-
[44]
S. Ji, S. Wei, and M. Lu, “Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set,” IEEE Trans. Geosci. Remote Sens., vol. 57, no. 1, pp. 574–586, 2019
work page 2019
-
[45]
Can semantic labeling methods generalize to any city? the inria aerial image labeling benchmark,
E. Maggiori, Y. Tarabalka, G. Charpiat, and P. Alliez, “Can semantic labeling methods generalize to any city? the inria aerial image labeling benchmark,” inProc. IEEE Int. Geosci. Remote Sens. Symp., 2017, pp. 3226–3229
work page 2017
-
[46]
Machine Learning for Aerial Image Labeling,
V. Mnih, “Machine Learning for Aerial Image Labeling,” Ph.D. disserta- tion, University of Toronto, Toronto, Canada, 2013
work page 2013
-
[47]
Spacenet 6: Multi-sensor all weather mapping dataset,
J. Shermeyer, D. Hogan, J. Brown, A. Van Etten, N. Weir, F. Pacifici, R. H¨ansch, A. Bastidas, S. Soenen, T. Bacastow, and R. Lewis, “Spacenet 6: Multi-sensor all weather mapping dataset,” inProc. IEEE Conf. Comput. Vis. Pattern Recog. Worksh., 2020, pp. 768–777
work page 2020
-
[48]
The multi-temporal urban development spacenet dataset,
A. Van Etten, D. Hogan, J. M. Manso, J. Shermeyer, N. Weir, and R. Lewis, “The multi-temporal urban development spacenet dataset,” inProc. IEEE Conf. Comput. Vis. Pattern Recog., 2021, pp. 6394–6403
work page 2021
-
[49]
Openearthmap: A benchmark dataset for global high-resolution land cover mapping,
J. Xia, N. Yokoya, B. Adriano, and C. Broni-Bediako, “Openearthmap: A benchmark dataset for global high-resolution land cover mapping,” in Proc. IEEE/CVF Winter Conf. Appl. Comput. Vis., 2023, pp. 6243–6253
work page 2023
-
[50]
LoveDA: A remote sensing land-cover dataset for domain adaptive semantic segmentation,
J. Wang, Z. Zheng, A. Ma, X. Lu, and Y. Zhong, “LoveDA: A remote sensing land-cover dataset for domain adaptive semantic segmentation,” inProc. Adv. Neural Inform. Process. Syst., vol. 1, 2021
work page 2021
-
[51]
UA Vid: A semantic segmentation dataset for uav imagery,
Y. Lyu, G. Vosselman, G.-S. Xia, A. Yilmaz, and M. Y. Yang, “UA Vid: A semantic segmentation dataset for uav imagery,”ISPRS J. Photogramm. Remote Sens., vol. 165, pp. 108–119, 2020
work page 2020
-
[52]
Results of the ISPRS benchmark on urban object detection and 3D building reconstruction,
F. Rottensteiner, G. Sohn, M. Gerke, J. D. Wegner, U. Breitkopf, and J. Jung, “Results of the ISPRS benchmark on urban object detection and 3D building reconstruction,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 93, pp. 256–271, 2014
work page 2014
-
[53]
An oriented object detector for hazy remote sensing images,
B. Liu, S.-B. Chen, J.-X. Wang, J. Tang, and B. Luo, “An oriented object detector for hazy remote sensing images,”IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–11, 2024
work page 2024
-
[54]
Real- World remote sensing image dehazing: Benchmark and baseline,
Z.-H. Zhu, W. Lu, S.-B. Chen, C. H. Q. Ding, J. Tang, and B. Luo, “Real- World remote sensing image dehazing: Benchmark and baseline,”IEEE Trans. Geosci. Remote Sens., vol. 63, pp. 1–14, 2025
work page 2025
-
[55]
LWGANet: A lightweight group attention backbone for remote sensing visual tasks,
W. Lu, S.-B. Chen, C. H. Ding, J. Tang, and B. Luo, “LWGANet: A lightweight group attention backbone for remote sensing visual tasks,” Proc. AAAI Conf. Artif. Intell., 2026
work page 2026
-
[56]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” in Proc. Int. Conf. Learn. Represent., 2019
work page 2019
-
[57]
L. Wang, R. Li, C. Zhang, S. Fang, C. Duan, X. Meng, and P. M. Atkinson, “UNetFormer: A unet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery,”ISPRS J. Photogramm. Remote Sens., vol. 190, p. 196–214, Aug. 2022
work page 2022
-
[58]
SACANet: Scene-aware class attention network for semantic segmen- tation of remote sensing images,
X. Ma, R. Che, T. Hong, M. Ma, Z. Zhao, T. Feng, and W. Zhang, “SACANet: Scene-aware class attention network for semantic segmen- tation of remote sensing images,” inProc. IEEE Int. Conf. Multimedia and Expo., 2023, pp. 828–833
work page 2023
-
[59]
W. Lu, S.-B. Chen, Q.-L. Shu, J. Tang, and B. Luo, “DecoupleNet: A lightweight backbone network with efficient feature decoupling for remote sensing visual tasks,”IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1– 13, 2024
work page 2024
-
[60]
L. Li, J. Yi, H. Fan, and H. Lin, “A lightweight semantic segmentation network based on self-attention mechanism and state space model for efficient urban scene segmentation,”IEEE Trans. Geosci. Remote Sens., vol. 63, pp. 1–15, 2025
work page 2025
-
[61]
X. Ma, R. Lian, Z. Wu, H. Guo, F. Yang, M. Ma, S. Wu, Z. Du, W. Zhang, and S. Song, “Logcan++: Adaptive local-global class-aware network for semantic segmentation of remote sensing images,”IEEE Transactions on Geoscience and Remote Sensing, vol. 63, pp. 1–16, 2025
work page 2025
-
[62]
Adaptive frequency enhancement network for remote sensing image semantic segmentation,
F. Gao, M. Fu, J. Cao, J. Dong, and Q. Du, “Adaptive frequency enhancement network for remote sensing image semantic segmentation,” IEEE Trans. Geosci. Remote Sens., vol. 63, pp. 1–15, 2025
work page 2025
-
[63]
Global structure- aware diffusion process for low-light image enhancement,
J. Hou, Z. Zhu, J. Hou, H. Liu, H. Zeng, and H. Yuan, “Global structure- aware diffusion process for low-light image enhancement,”Proc. Adv. Neural Inform. Process. Syst., vol. 36, pp. 79 734–79 747, 2023
work page 2023
-
[64]
Dea-net: Single image dehazing based on detail-enhanced convolution and content-guided attention,
Z. Chen, Z. He, and Z.-M. Lu, “Dea-net: Single image dehazing based on detail-enhanced convolution and content-guided attention,”IEEE Trans. Image Process., vol. 33, pp. 1002–1015, 2024
work page 2024
-
[65]
Polybuilding: Polygon transformer for building extraction,
Y. Hu, Z. Wang, Z. Huang, and Y. Liu, “Polybuilding: Polygon transformer for building extraction,”ISPRS J. Photogramm. Remote Sens., vol. 199, pp. 15–27, 2023
work page 2023
-
[66]
BCTNet: Bi-branch cross- fusion transformer for building footprint extraction,
L. Xu, Y. Li, J. Xu, Y. Zhang, and L. Guo, “BCTNet: Bi-branch cross- fusion transformer for building footprint extraction,”IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–14, 2023
work page 2023
-
[67]
Y. Li, D. Hong, C. Li, J. Yao, and J. Chanussot, “Hd-net: High-resolution decoupled network for building footprint extraction via deeply supervised body and boundary decomposition,”ISPRS J. Photogramm. Remote Sens., vol. 209, pp. 51–65, 2024
work page 2024
-
[68]
RSSFormer: Foreground saliency enhancement for remote sensing land-cover segmen- tation,
R. Xu, C. Wang, J. Zhang, S. Xu, W. Meng, and X. Zhang, “RSSFormer: Foreground saliency enhancement for remote sensing land-cover segmen- tation,”IEEE Trans. Image Process., vol. 32, pp. 1052–1064, 2023
work page 2023
-
[69]
H. Wu, P. Huang, M. Zhang, W. Tang, and X. Yu, “CMTFNet: Cnn and multiscale transformer fusion network for remote-sensing image semantic segmentation,”IEEE Trans. Geosci. Remote Sens., vol. 61, pp. 1–12, 2023
work page 2023
-
[70]
LoveNAS: Towards multi-scene land-cover mapping via hierarchical searching adaptive network,
J. Wang, Y. Zhong, A. Ma, Z. Zheng, Y. Wan, and L. Zhang, “LoveNAS: Towards multi-scene land-cover mapping via hierarchical searching adaptive network,”ISPRS J. Photogramm. Remote Sens., vol. 209, pp. 265–278, 2024
work page 2024
-
[71]
LSKNet: A foundation lightweight backbone for remote sensing,
Y. Li, X. Li, Y. Dai, Q. Hou, L. Liu, Y. Liu, M.-M. Cheng, and J. Yang, “LSKNet: A foundation lightweight backbone for remote sensing,”Int. J. Comput. Vis., vol. 133, no. 3, pp. 1410–1431, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.