Recognition: unknown
MCSC-Bench: Multimodal Context-to-Script Creation for Realistic Video Production
Pith reviewed 2026-05-10 09:07 UTC · model grok-4.3
The pith
A new benchmark of 11K+ videos trains models to create full production scripts from noisy materials and instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MCSC-Bench is the first large-scale dataset for the full video production reasoning process; each of its 11K+ samples pairs redundant multimodal materials and user instructions with a coherent script that mixes material-based shots, newly planned shots carrying explicit shooting instructions, and shot-aligned voiceovers. The benchmark measures performance across material selection, narrative planning, and conditioned script generation, and includes separate in-domain and out-of-domain splits. Training on the dataset yields models that achieve state-of-the-art results, including an 8B-parameter model that outperforms Gemini-2.5-Pro, while also generalizing to out-of-domain cases and producing
What carries the argument
MCSC-Bench dataset that pairs noisy multimodal inputs with structured scripts containing material-based shots, planned shots, and aligned voiceovers to test the integrated workflow of selection, planning, and generation.
If this is right
- Current multimodal LLMs struggle with structure-aware reasoning when given long, noisy contexts.
- Fine-tuned models reach state-of-the-art on material selection, narrative planning, and script generation.
- An 8B model trained on the benchmark surpasses Gemini-2.5-Pro and generalizes to out-of-domain scenarios.
- Scripts generated by the trained models improve quality in downstream video generation pipelines.
Where Pith is reading between the lines
- The same annotation style could be applied to other creative pipelines such as audio editing or interactive storytelling.
- Smaller open-weight models becoming competitive suggests accessible tools for independent video creators.
- The benchmark exposes a gap in long-context multimodal reasoning that future model architectures must address.
- Integration of the generated scripts into end-to-end AI video systems could reduce manual pre-production effort.
Load-bearing premise
Human-annotated scripts in the 11K videos correctly represent real-world video production reasoning workflows and the chosen metrics accurately measure structure-aware multimodal reasoning under long contexts.
What would settle it
An independent set of real video-production tasks where models trained on MCSC-Bench produce scripts that fail to yield coherent final videos or do not outperform untrained baselines when executed by human crews.
Figures


















read the original abstract
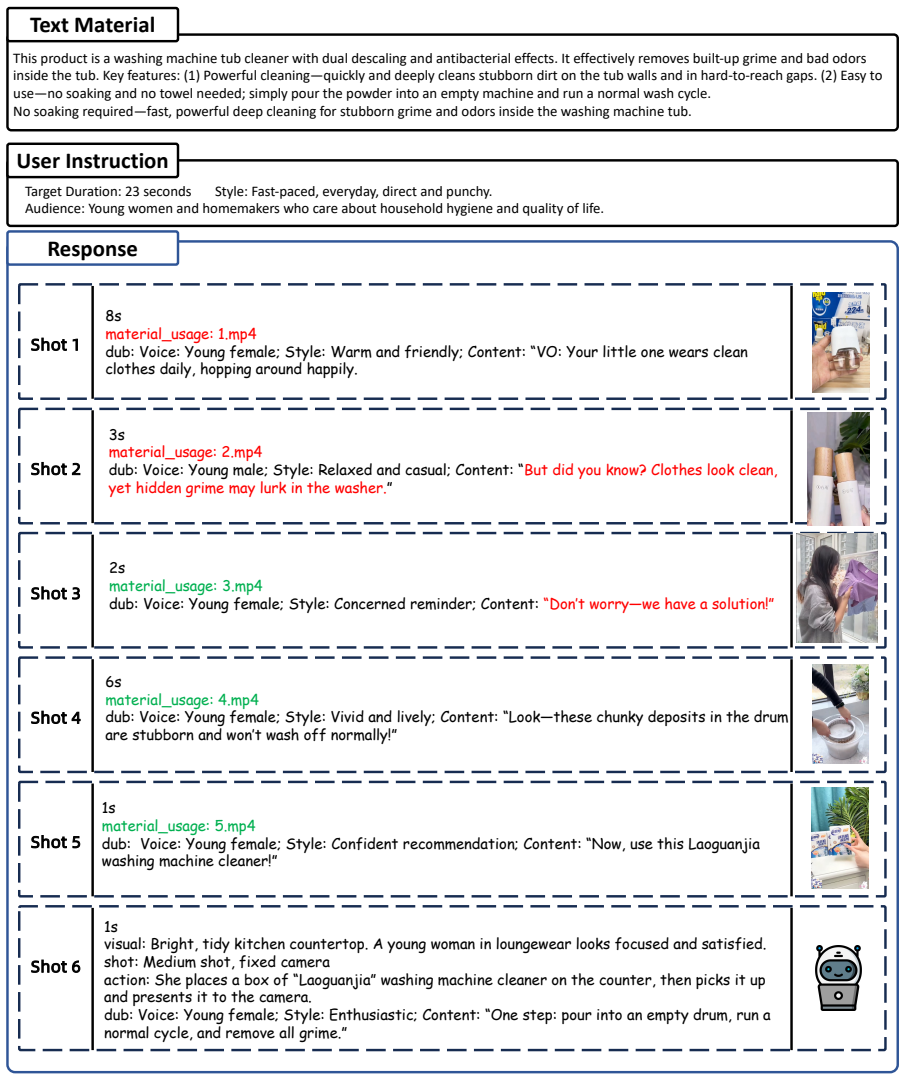
Real-world video creation often involves a complex reasoning workflow of selecting relevant shots from noisy materials, planning missing shots for narrative completeness, and organizing them into coherent storylines. However, existing benchmarks focus on isolated sub-tasks and lack support for evaluating this full process. To address this gap, we propose Multimodal Context-to-Script Creation (MCSC), a new task that transforms noisy multimodal inputs and user instructions into structured, executable video scripts. We further introduce MCSC-Bench, the first large-scale MCSC dataset, comprising 11K+ well-annotated videos. Each sample includes: (1) redundant multimodal materials and user instructions; (2) a coherent, production-ready script containing material-based shots, newly planned shots (with shooting instructions), and shot-aligned voiceovers. MCSC-Bench supports comprehensive evaluation across material selection, narrative planning, and conditioned script generation, and includes both in-domain and out-of-domain test sets. Experiments show that current multimodal LLMs struggle with structure-aware reasoning under long contexts, highlighting the challenges posed by our benchmark. Models trained on MCSC-Bench achieve SOTA performance, with an 8B model surpassing Gemini-2.5-Pro, and generalize to out-of-domain scenarios. Downstream video generation guided by the generated scripts further validates the practical value of MCSC. Datasets will be public soon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Multimodal Context-to-Script Creation (MCSC) task for generating structured, production-ready video scripts from noisy multimodal materials and user instructions. It presents MCSC-Bench, a new dataset of 11K+ human-annotated videos that include redundant materials, instructions, material-based shots, newly planned shots with shooting instructions, and shot-aligned voiceovers. The work evaluates current multimodal LLMs, reports that they struggle with structure-aware reasoning under long contexts, shows that models fine-tuned on MCSC-Bench achieve SOTA results (including an 8B model surpassing Gemini-2.5-Pro), demonstrates out-of-domain generalization, and validates the scripts via downstream video generation.
Significance. If the annotations prove reliable and the empirical results are reproducible with full metrics and protocols, the benchmark would meaningfully advance evaluation of end-to-end video production reasoning beyond isolated subtasks. It supplies a large-scale training resource and highlights practical challenges in long-context multimodal planning, with potential downstream utility for realistic video pipelines.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments: The central SOTA claim that an 8B model surpasses Gemini-2.5-Pro (plus OOD generalization) is stated without any specific metrics, baseline details, error bars, or experimental protocol. This prevents assessment of whether the reported superiority is load-bearing or artifactual.
- [Dataset construction] Dataset construction (likely §3): The human-annotated 'coherent, production-ready scripts' are presented as faithful targets for material selection, narrative planning, and script generation, yet no inter-annotator agreement statistics, expert validation against real production workflows, or ablation on alternative valid scripts are provided. This directly undermines the supervised training results and automatic metric rankings.
- [Evaluation and OOD] Evaluation metrics and OOD split: No concrete definitions or breakdowns are given for the metrics used to score material selection, narrative planning, and conditioned script generation, nor for how the out-of-domain test set differs from in-domain data. These details are required to support the generalization claim.
minor comments (2)
- [Abstract] The abstract states that 'Datasets will be public soon' but provides no timeline, access mechanism, or licensing details.
- [Task definition] Notation for the three evaluation axes (material selection, narrative planning, conditioned script generation) should be defined consistently when first introduced.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications from the manuscript and outlining revisions where appropriate to strengthen the presentation of results, dataset quality, and evaluation details.
read point-by-point responses
-
Referee: [Abstract and Experiments] The central SOTA claim that an 8B model surpasses Gemini-2.5-Pro (plus OOD generalization) is stated without any specific metrics, baseline details, error bars, or experimental protocol. This prevents assessment of whether the reported superiority is load-bearing or artifactual.
Authors: We appreciate the referee's concern regarding the self-contained nature of the abstract. The specific metrics (F1 for material selection, planning accuracy, and generation quality scores), full baseline comparisons including Gemini-2.5-Pro, error bars from multiple runs, and the complete experimental protocol are reported in Section 4.2, Table 2, and Section 4.1. The OOD results appear in Section 4.3 and Table 5. To address the comment directly, we will revise the abstract to include key quantitative highlights of the SOTA and generalization results while keeping it concise. revision: partial
-
Referee: [Dataset construction] The human-annotated 'coherent, production-ready scripts' are presented as faithful targets for material selection, narrative planning, and script generation, yet no inter-annotator agreement statistics, expert validation against real production workflows, or ablation on alternative valid scripts are provided. This directly undermines the supervised training results and automatic metric rankings.
Authors: We agree that demonstrating annotation reliability is essential for a supervised benchmark. Section 3.2 describes the annotation pipeline, which involved professional video editors following detailed guidelines for material selection, shot planning, and voiceover alignment, with multiple review rounds. We will add inter-annotator agreement statistics (e.g., Fleiss' kappa for shot-level decisions) in the revised Section 3. We will also expand the description of expert consultations with industry professionals to validate against real production workflows. Regarding alternative valid scripts, we will include a new analysis in the experiments section examining script variability and its effect on automatic metrics, as the task inherently permits some valid alternatives while prioritizing coverage and coherence. revision: yes
-
Referee: [Evaluation and OOD] No concrete definitions or breakdowns are given for the metrics used to score material selection, narrative planning, and conditioned script generation, nor for how the out-of-domain test set differs from in-domain data. These details are required to support the generalization claim.
Authors: The metrics and OOD construction are defined in the manuscript, but we acknowledge they could be presented more explicitly. Section 4.1 provides the definitions: material selection uses precision/recall/F1 on shot overlap; narrative planning is scored via event coverage and logical sequence metrics; conditioned script generation uses BLEU-4, ROUGE-L, METEOR, plus human evaluation on coherence and relevance. The OOD test set (Section 3.4) comprises videos from unseen genres, sources, and styles not present in the training or in-domain test data, with per-domain breakdowns in Table 5. We will revise Section 4 to include more granular metric formulas, component-wise breakdowns, and an expanded explanation of the OOD split construction to fully support the generalization claims. revision: yes
Circularity Check
No circularity: new benchmark construction and empirical model evaluation are independent of self-referential fits or definitions.
full rationale
The paper introduces a new task (MCSC) and dataset (MCSC-Bench) via human annotation of 11K+ videos, then reports empirical results of training and evaluating multimodal LLMs on held-out in-domain and out-of-domain splits using standard metrics. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The SOTA claim (8B model > Gemini-2.5-Pro) and OOD generalization rest on direct comparison against external models on the new test sets, not on any reduction to the training inputs by construction. Annotation quality concerns are validity issues, not circularity per the defined patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gpt-4 techni- cal report.arXiv preprint arXiv:2303.08774. Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-vl: A versatile vision- language model for understanding, localization, text reading, and beyond.Preprint, arXiv:2308.12966. Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, and 1 others. 2025a. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631. Shuai Bai, Keqin Chen...
work page internal anchor Pith review arXiv
-
[3]
Boyu Chen, Zhengrong Yue, Siran Chen, Zikang Wang, Yang Liu, Peng Li, and Yali Wang
The creativity maze: Explor- ing creativity in screenplay writing.Psychology of Aesthetics, Creativity, and the Arts, 8(4):384. Boyu Chen, Zhengrong Yue, Siran Chen, Zikang Wang, Yang Liu, Peng Li, and Yali Wang. 2025a. Lvagent: Long video understanding by multi-round dynamical collaboration of mllm agents. InProceedings of the IEEE/CVF International Conf...
-
[4]
arXiv preprint arXiv:2501.05884
Text-to-edit: Controllable end-to-end video ad creation via multimodal llms. arXiv preprint arXiv:2501.05884. Peggy Chi, Zheng Sun, Katrina Panovich, and Irfan Essa
-
[5]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261. Yanqi Dai, Huanran Hu, Lei Wang, Shengjie Jin, Xu Chen, and Zhiwu Lu
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Mmrole: A com- prehensive framework for developing and evaluat- ing multimodal role-playing agents.arXiv preprint arXiv:2408.04203. Ken Dancyger. 2018.The technique of film and video editing: history, theory, and practice. Routledge. Sibo Dong, Ismail Shaheen, Maggie Shen, Rupayan Mallick, and Sarah Adel Bargal
-
[7]
Tinyfusion: Diffusion transformers learned shallow
Tbstar-edit: From image editing pattern shifting to consistency enhance- ment.Preprint, arXiv:2510.04483. Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, and 1 oth- ers
-
[8]
arXiv preprint arXiv:2312.10300
Shot2story20k: A new benchmark for comprehensive understanding of multi-shot videos. arXiv preprint arXiv:2312.10300. Liu He, Yizhi Song, Hejun Huang, Pinxin Liu, Yunlong Tang, Daniel Aliaga, and Xin Zhou. 2024a. Kubrick: Multimodal agent collaborations for synthetic video generation.arXiv preprint arXiv:2408.10453. Xuan He, Dongfu Jiang, Ge Zhang, Max Ku...
-
[9]
Animate-a-story: Storytelling with retrieval- augmented video generation,
Animate-a-story: Storytelling with retrieval-augmented video generation.arXiv preprint arXiv:2307.06940. Roberto Henschel, Levon Khachatryan, Hayk Poghosyan, Daniil Hayrapetyan, Vahram Tade- vosyan, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi
-
[10]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Cogvideo: Large-scale pre- training for text-to-video generation via transformers. arXiv preprint arXiv:2205.15868. Ziwei Ji, Yan Xu, I Cheng, Samuel Cahyawijaya, Rita Frieske, Etsuko Ishii, Min Zeng, Andrea Madotto, Pascale Fung, and 1 others
work page internal anchor Pith review arXiv
-
[11]
arXiv preprint arXiv:2203.00314
Vscript: Con- trollable script generation with visual presentation. arXiv preprint arXiv:2203.00314. Dan Kondratyuk, Lijun Yu, Xiuye Gu, José Lezama, Jonathan Huang, Grant Schindler, Rachel Hornung, Vighnesh Birodkar, Jimmy Yan, Ming-Chang Chiu, and 1 others
-
[12]
Videopoet: A large language model for zero-shot video generation.arXiv:2312.14125,
Videopoet: A large language model for zero-shot video generation.arXiv preprint arXiv:2312.14125. Junnan Li, Yongkang Wong, Qi Zhao, and Mohan S Kankanhalli
-
[13]
From shots to stories: Llm-assisted video editing with unified language representations.arXiv preprint arXiv:2505.12237. Chin-Yew Lin
-
[14]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee
Improving visual storytelling with multimodal large language models.arXiv preprint arXiv:2407.02586. Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023a. Visual instruction tuning.Advances in neural information processing systems, 36:34892– 34916. Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023b. G-eval: Nlg e...
-
[15]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Video-chatgpt: Towards detailed video understanding via large vision and language models.arXiv preprint arXiv:2306.05424. Louis Mahon and Mirella Lapata
work page internal anchor Pith review arXiv
-
[16]
arXiv preprint arXiv:2410.19809 (2024)
Screenwriter: Automatic screenplay generation and movie sum- marisation.arXiv preprint arXiv:2410.19809. Chenyu Mu, Xin He, Qu Yang, Wanshun Chen, Jiadi Yao, Huang Liu, Zihao Yi, Bo Zhao, Xingyu Chen, Ruotian Ma, and 1 others
- [17]
-
[18]
Integrat- ing video and text: A balanced approach to multi- modal summary generation and evaluation.arXiv preprint arXiv:2505.06594. PySceneDetect. Pyscenedetect. www.scenedetect. com. Accessed: 2026-01-22. Dongjun Qian, Kai Su, Yiming Tan, Qishuai Diao, Xian Wu, Chang Liu, Bingyue Peng, and Zehuan Yuan
-
[19]
arXiv preprint arXiv:2504.05673
Vc-llm: Automated advertisement video creation from raw footage using multi-modal llms. arXiv preprint arXiv:2504.05673. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others
-
[20]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300. Yan Shu, Zheng Liu, Peitian Zhang, Minghao Qin, Junjie Zhou, Zhengyang Liang, Tiejun Huang, and Bo Zhao
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Skyscript-100m: 1,000,000,000 pairs of scripts and shooting scripts for short drama.arXiv preprint arXiv:2408.09333. Taobao. Taobao. www.taobao.com. Accessed: 2026- 01-09. TikTok. Tiktok. https://www.tiktok.com. Ac- cessed: 2026-01-09. Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, and 1 others
-
[22]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314. Bryan Wang, Yuliang Li, Zhaoyang Lv, Haijun Xia, Yan Xu, and Raj Sodhi. 2024a. Lave: Llm-powered agent assistance and language augmentation for video editing. InProceedings of the 29th International Conference on Intelligent User Interfaces, pages 699–
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Lvbench: An extreme long video understanding benchmark.CoRR, abs/2406.08035, 2024
Write-a- video: computational video montage from themed text.ACM Trans. Graph., 38(6):177–1. Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Xiaotao Gu, Shiyu Huang, Bin Xu, Yuxiao Dong, and 1 others. 2024b. Lvbench: An extreme long video understanding benchmark.arXiv preprint arXiv:2406.08035. Yuetian Weng, Mingfei Han, Haoyu He, Xia...
-
[24]
arXiv preprint arXiv:2503.07314 (2025)
Au- tomated movie generation via multi-agent cot plan- ning.arXiv preprint arXiv:2503.07314. Dingyi Yang, Chunru Zhan, Ziheng Wang, Biao Wang, Tiezheng Ge, Bo Zheng, and Qin Jin. 2024a. Syn- chronized video storytelling: Generating video nar- rations with structured storyline.arXiv preprint arXiv:2405.14040. Dongjie Yang, Suyuan Huang, Chengqiang Lu, Xi- ...
-
[25]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Llava-video: Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713. Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chen- hui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You
-
[26]
Open-Sora: Democratizing Efficient Video Production for All
Open-sora: De- mocratizing efficient video production for all.arXiv preprint arXiv:2412.20404. Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yong- ping Xiong, Bo Zhang, and 1 others
work page internal anchor Pith review arXiv
-
[27]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479. Junchen Zhu, Huan Yang, Huiguo He, Wenjing Wang, Zixi Tuo, Wen-Huang Cheng, Lianli Gao, Jingkuan Song, and Jianlong Fu
work page internal anchor Pith review arXiv
-
[28]
We apply our trained evaluator to score generated scripts across the 6 dimensions, and take the average normalized score as the reward signal
to enhance response quality on top of MCSC-8B. We apply our trained evaluator to score generated scripts across the 6 dimensions, and take the average normalized score as the reward signal. The RL training is con- ducted with a learning rate of 1e-6 with AdamW optimizer, an effective batch size of 128, and KL regularization (β= 0.01 ). The vision encoder ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.