Recognition: unknown
From Tokens to Steps: Verification-Aware Speculative Decoding for Efficient Multi-Step Reasoning
Pith reviewed 2026-05-10 11:10 UTC · model grok-4.3
The pith
SpecGuard shifts speculative decoding from token-level to step-level verification using only internal model signals for multi-step reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
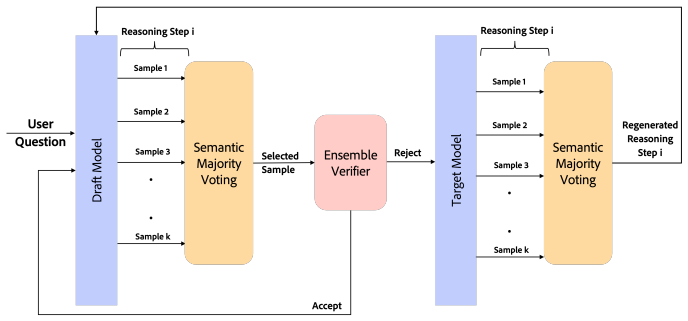
SpecGuard samples multiple draft candidates at each reasoning step and selects the most consistent step, which is then validated using an ensemble of an attention-based grounding score that measures attribution to the input and previously accepted steps together with a log-probability-based score that captures token-level confidence; these signals jointly decide whether to accept the step or recompute it with the target model, producing higher final accuracy and lower latency than token-only or reward-based alternatives.
What carries the argument
Ensemble of attention-based grounding score and log-probability-based score for deciding acceptance of entire reasoning steps
If this is right
- Accuracy rises by 3.6% on standard reasoning benchmarks
- End-to-end latency drops by about 11% versus standard speculative decoding
- The method outperforms reward-guided speculative decoding without the added model or latency
- Compute is spent only on steps the internal signals flag as uncertain
- No external verifiers or fine-tuning are required for the verification step
Where Pith is reading between the lines
- The same internal-signal approach could be tested on code generation or planning tasks where step consistency also matters.
- If the ensemble works across model sizes, it may reduce reliance on separate reward models for safety or alignment checks.
- Dynamic weighting between the attention and probability scores might further improve results on different reasoning domains.
- The selective-recompute pattern suggests a general template for making any autoregressive generation more robust without external oracles.
Load-bearing premise
The two internal signals together are reliable enough to catch bad reasoning steps without missing errors or needing external reward models.
What would settle it
A reasoning benchmark where steps that receive high scores from both the attention grounding and log-probability signals still produce more wrong final answers than always recomputing every step with the target model.
Figures



read the original abstract
Speculative decoding (SD) accelerates large language model inference by allowing a lightweight draft model to propose outputs that a stronger target model verifies. However, its token-centric nature allows erroneous steps to propagate. Prior approaches mitigate this using external reward models, but incur additional latency, computational overhead, and limit generalizability. We propose SpecGuard, a verification-aware speculative decoding framework that performs step-level verification using only model-internal signals. At each step, SpecGuard samples multiple draft candidates and selects the most consistent step, which is then validated using an ensemble of two lightweight model-internal signals: (i) an attention-based grounding score that measures attribution to the input and previously accepted steps, and (ii) a log-probability-based score that captures token-level confidence. These signals jointly determine whether a step is accepted or recomputed using the target, allocating compute selectively. Experiments across a range of reasoning benchmarks show that SpecGuard improves accuracy by 3.6% while reducing latency by ~11%, outperforming both SD and reward-guided SD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpecGuard, a verification-aware speculative decoding framework that shifts from token-level to step-level verification in LLM inference for multi-step reasoning. It samples multiple draft candidates per step and uses an ensemble of two internal signals—an attention-based grounding score measuring attribution to the input and prior steps, plus a log-probability confidence score—to decide acceptance or recomputation with the target model, claiming this avoids external reward models while delivering 3.6% higher accuracy and ~11% lower latency than standard SD and reward-guided SD across reasoning benchmarks.
Significance. If the empirical claims hold under rigorous validation, the approach could meaningfully improve the efficiency-accuracy tradeoff for complex reasoning tasks by eliminating reliance on external reward models and their associated overhead, offering a more generalizable path for speculative decoding in production settings.
major comments (2)
- [§3.2, §3.3] §3.2 and §3.3: The ensemble of attention-grounding and log-probability scores is presented as sufficient for reliable step validation, but no ablation is reported isolating each component's contribution or failure modes (e.g., when attention attribution is noisy), which is load-bearing for the central claim that internal signals alone suffice without external rewards.
- [§5] §5 (Experiments): The headline results (3.6% accuracy gain, ~11% latency reduction) are stated without specifying the exact benchmarks, draft/target model sizes, number of candidates sampled per step, number of independent runs, error bars, or statistical tests, preventing assessment of whether the gains are robust or reproducible.
minor comments (2)
- [Abstract, §1] Abstract and §1: The phrase 'a range of reasoning benchmarks' should explicitly list the datasets (e.g., GSM8K, MATH) to allow immediate evaluation of scope.
- [§3.1] §3.1: The multi-candidate sampling procedure lacks a precise description of how candidates are generated and ranked before scoring, including any additional forward-pass cost.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. The comments highlight important areas for improving the rigor of our claims regarding the internal verification signals and the reproducibility of our experimental results. We address each point below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2, §3.3] §3.2 and §3.3: The ensemble of attention-grounding and log-probability scores is presented as sufficient for reliable step validation, but no ablation is reported isolating each component's contribution or failure modes (e.g., when attention attribution is noisy), which is load-bearing for the central claim that internal signals alone suffice without external rewards.
Authors: We agree that an ablation study isolating the attention-grounding score, the log-probability score, and their ensemble would provide stronger empirical support for the claim that internal signals suffice. In the revised manuscript, we have added a dedicated ablation subsection (new §3.4) that reports performance when using each signal in isolation versus the combined ensemble. We also include a qualitative analysis of failure modes, such as cases where attention attribution is noisy due to long contexts or weak prior-step references, and show that the ensemble reduces error propagation compared to either signal alone. These additions directly address the load-bearing aspect of our central claim. revision: yes
-
Referee: [§5] §5 (Experiments): The headline results (3.6% accuracy gain, ~11% latency reduction) are stated without specifying the exact benchmarks, draft/target model sizes, number of candidates sampled per step, number of independent runs, error bars, or statistical tests, preventing assessment of whether the gains are robust or reproducible.
Authors: We acknowledge that the original presentation of results lacked sufficient detail for full reproducibility assessment. In the revised manuscript, §5 has been expanded to explicitly report the complete set of benchmarks, the sizes of the draft and target models, the number of draft candidates sampled per step, the number of independent runs, error bars (standard deviation across runs), and the statistical tests performed. These details are now presented in the main experimental section rather than being summarized at a high level. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces SpecGuard as a verification-aware speculative decoding method that relies on internal attention-grounding and log-probability signals for step-level acceptance decisions. All load-bearing claims are empirical: accuracy and latency improvements are measured directly against baselines (standard SD and reward-guided SD) on reasoning benchmarks. No equations, fitted parameters, or uniqueness theorems are defined in terms of the target results; the method description provides an independent mechanism (multi-candidate sampling plus ensemble scoring) whose validity is tested externally rather than presupposed by construction or self-citation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Accelerating Large Language Model Decoding with Speculative Sampling
Specs: Faster test-time scaling through speculative drafts. InES-FoMo III: 3rd Work- shop on Efficient Systems for Foundation Models. Charlie Chen, Sebastian Borgeaud, Geoffrey Irv- ing, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. 2023. Accelerating large language modeldecodingwithspeculativesampling.arXiv preprint arXiv:2302.01318. Guoxin Chen...
work page internal anchor Pith review arXiv 2023
-
[2]
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sa- hoo, Caiming Xiong, and Tong Zhang
Raft: Reward ranked finetuning for gener- ative foundation model alignment.Transactions on Machine Learning Research, 2023. Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sa- hoo, Caiming Xiong, and Tong Zhang. 2024. Rlhf workflow: From reward modeling to online rlhf a comprehensive practical alignment recipe of ite...
2023
-
[3]
Break the sequential dependency of llm in- ference using lookahead decoding. InProceedings of the 41st International Conference on Machine Learning, pages 14060–14079. Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, and 1 others. 2024. Olympiadbench: A challenging benchmark for promot...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
InInternational Conference on Machine Learning, pages 19274–19286
Fast inference from transformers via spec- ulative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR. Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. 2024. Eagle: Speculative sam- pling requires rethinking feature uncertainty. In International Conference on Machine Learning, pages 28935–28948. PMLR. Baohao Liao, Yuhu...
2024
-
[5]
Specreason: Fast and ac- curate inference-time compute via speculative reasoning
Awq: Activation-aware weight quantiza- tion for on-device llm compression and accel- eration.Proceedings of machine learning and systems, 6:87–100. Michael Metel, Peng Lu, Boxing Chen, Mehdi Reza- gholizadeh, and Ivan Kobyzev. 2024. Draft on the fly: Adaptive self-speculative decoding using cosine similarity. InFindings of the Association for Computationa...
-
[6]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Spectr: Fast speculative decoding via opti- mal transport.Advances in Neural Information Processing Systems, 36:30222–30242. Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, and 1 others. 2024. Gemini 1.5: Un- locking multimodal understanding across mil- lions of tok...
work page internal anchor Pith review arXiv 2024
-
[7]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11263–11282
Draft& verify: Lossless large language model acceleration via self-speculative decoding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11263–11282. Jin Peng Zhou, Kaiwen Wang, Jonathan D Chang, Zhaolin Gao, Nathan Kallus, Kilian Q Wein- berger, Kianté Brantley, and Wen Sun. 2025. q...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.