Recognition: unknown
ZORO: Active Rules for Reliable Vibe Coding
Pith reviewed 2026-05-10 08:35 UTC · model grok-4.3
The pith
ZORO integrates rules directly into AI coding workflows by enriching plans, enforcing compliance with proof requirements, and evolving rules via user feedback, resulting in better rule adherence and shifts in user behavior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
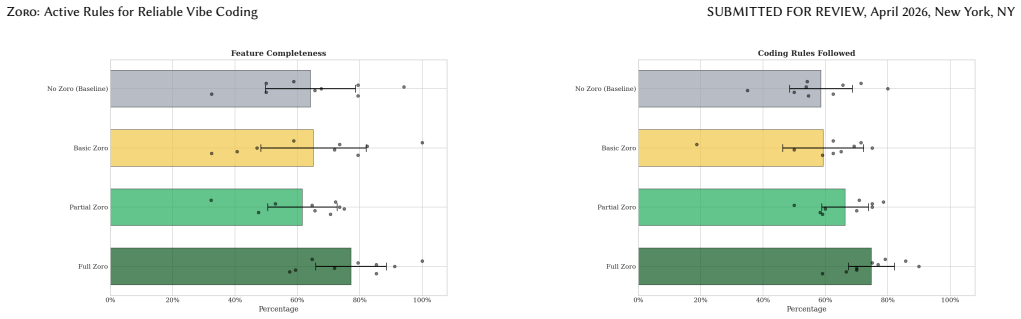
A technical evaluation shows that coding agents follow rules more with ZORO than without. A user study demonstrates a change in people's behavior and cognitive strategies when rules are at the forefront of vibe coding.
Load-bearing premise
The technical evaluation and user study provide unbiased, generalizable evidence that ZORO improves rule adherence and alters user strategies, without unstated limitations in study design or participant selection.
Figures









read the original abstract
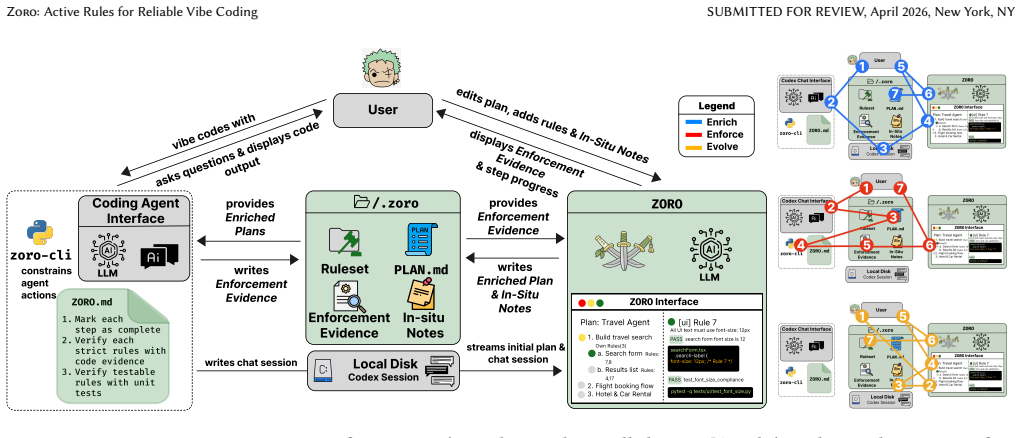
Rules files (e.g., AGENTS\.md, CLAUDE\.md) are the primary mechanism for human-agent alignment when developers vibe code. However, they remain passive: it is not immediately apparent when rules are being used or followed, or how to improve them. To transform rules from passive text into active controls, we introduce ZORO, an interactive interface that integrates directly with a coding agent and anchors rules to every step of the coding process. After an agent generates an initial plan, ZORO enriches the plan with rules, enforces the rules during implementation by requiring the agent prove that each rule was followed, and allows users to provide in-situ feedback when they are unsatisfied with a rule application to evolve the ruleset. A technical evaluation shows that coding agents follow rules more with ZORO than without. A user study demonstrates a change in people's behavior and cognitive strategies when rules are at the forefront of vibe coding. We discuss how making rules active in agentic systems unlocks broader opportunities for human-agent alignment in coding settings and beyond.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ZORO, an interactive interface integrated with coding agents to transform passive rules files (e.g., AGENTS.md) into active controls during vibe coding. ZORO enriches an agent's initial plan with rules, requires the agent to prove rule adherence at each implementation step, and enables in-situ user feedback to evolve the ruleset. The authors report that a technical evaluation demonstrates higher rule-following rates with ZORO than without, and a user study shows shifts in user behavior and cognitive strategies when rules are foregrounded.
Significance. If the reported evaluations hold under scrutiny, the work could meaningfully advance human-agent alignment mechanisms in AI-assisted software development by addressing the passivity of current rules-based approaches. The core idea of anchoring rules to every agent step and supporting iterative refinement has clear applicability beyond coding to other agentic workflows. However, the absence of any methods, metrics, or results details in the manuscript leaves the practical impact and generalizability unassessable at present.
major comments (2)
- [Abstract] Abstract: The central claims rest on a 'technical evaluation' showing improved rule adherence and a 'user study' demonstrating behavioral change, yet no methods, baselines, metrics (e.g., how 'follow rules more' is quantified), sample sizes, controls, or statistical tests are described anywhere in the manuscript. This renders the positive outcomes unverifiable and prevents evaluation of whether the interface actually delivers the stated benefits.
- No evaluation sections present: The manuscript provides no description of the technical evaluation protocol (e.g., agent models tested, rule sets used, proof mechanism implementation, or quantitative comparison results) or the user study design (e.g., tasks, participant recruitment, measurement of 'cognitive strategies,' or qualitative/quantitative findings). These details are load-bearing for the paper's contribution claims.
minor comments (1)
- [Abstract] The abstract uses the term 'vibe coding' without a concise definition or reference to prior usage, which may reduce clarity for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for their careful reading and for identifying the need for greater transparency in our evaluation reporting. The comments correctly note that the current manuscript version does not contain sufficient methodological and results detail to allow independent assessment of the claimed benefits. We will address this by adding dedicated evaluation sections in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims rest on a 'technical evaluation' showing improved rule adherence and a 'user study' demonstrating behavioral change, yet no methods, baselines, metrics (e.g., how 'follow rules more' is quantified), sample sizes, controls, or statistical tests are described anywhere in the manuscript. This renders the positive outcomes unverifiable and prevents evaluation of whether the interface actually delivers the stated benefits.
Authors: We agree that the abstract and main text currently omit the concrete details required to verify the evaluation outcomes. In the revision we will expand the abstract to report key quantitative results (e.g., rule-adherence percentages with and without ZORO, effect sizes) and will insert a new Evaluation section. This section will specify: the LLMs used as agents, the rule sets and proof-generation mechanism, the exact metric for rule adherence (manual coding of each implementation step with inter-rater reliability), baseline conditions, participant/task counts, and the statistical tests performed. The same section will describe the user-study protocol, including recruitment, tasks, measurement of cognitive-strategy shifts (think-aloud transcripts and post-task questionnaires), and both quantitative and qualitative findings. revision: yes
-
Referee: [—] No evaluation sections present: The manuscript provides no description of the technical evaluation protocol (e.g., agent models tested, rule sets used, proof mechanism implementation, or quantitative comparison results) or the user study design (e.g., tasks, participant recruitment, measurement of 'cognitive strategies,' or qualitative/quantitative findings). These details are load-bearing for the paper's contribution claims.
Authors: We concur that the manuscript as submitted lacks the required protocol and results descriptions. We will add two new sections: 'Technical Evaluation' and 'User Study.' The former will detail the agent models, rule sets, how the proof-of-adherence step is implemented and checked, quantitative comparison tables, and statistical analysis. The latter will describe study design (within- or between-subjects), participant recruitment and demographics, coding tasks, instruments used to capture behavioral and cognitive changes, and the observed shifts with supporting excerpts. These additions will make the contribution claims directly assessable. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces ZORO as an interactive system for making rules active during agentic coding, supported by claims of a technical evaluation (showing improved rule adherence) and a user study (showing behavioral changes). No equations, mathematical derivations, fitted parameters, self-citations, or uniqueness theorems appear in the text. The central claims rest on described external evaluations rather than reducing to definitions, ansatzes, or self-referential inputs by construction, rendering the presentation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User studies and technical evaluations in HCI reliably capture changes in rule adherence and cognitive strategies.
invented entities (1)
-
ZORO interface
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Agents.md Community. 2024. AGENTS.md: A simple, open format for guiding coding agents. https://agents.md/. Accessed: 2026-03-28
2024
-
[2]
Anthropic. 2025. Claude Code: Agentic coding tool. https://www.anthropic.com/ news/claude-3-7-sonnet. Accessed: 2025-03-28
2025
-
[3]
Anthropic. 2025. Claude Code Documentation: Memory and Context Persistence. https://code.claude.com/docs/en/memory. Accessed: 2026-03-28
2025
-
[4]
Anthropic. 2026. How Claude Remembers Your Project (Claude Code Documen- tation). https://code.claude.com/docs/en/memory Accessed 2026-03-29
2026
-
[5]
Anysphere. 2024. Cursor: The AI-native Code Editor. https://www.cursor.com/. Accessed: 2026-03-28
2024
-
[6]
Shraddha Barke, Michael B James, and Nadia Polikarpova. 2023. Grounded copilot: How programmers interact with code-generating models.Proceedings of the ACM on Programming Languages7, OOPSLA1 (2023), 85–111
2023
-
[7]
Valerie Chen, Alan Zhu, Sebastian Zhao, Hussein Mozannar, David Sontag, and Ameet Talwalkar. 2025. Need Help? Designing Proactive AI Assistants for Pro- gramming. InProceedings of the 2025 CHI Conference on Human Factors in Com- puting Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 881, 18 pages. doi:10.1145/3706598.3714002
-
[8]
Cline. 2025. Customization: Cline Rules. https://docs.cline.bot/customization/ cline-rules. Accessed: 2025-03-28
2025
-
[9]
Cline.bot. 2024. Cline: An open-source autonomous coding agent. https://docs. cline.bot/. Accessed: 2026-03-28
2024
-
[10]
Cursor. 2026. Rules (Cursor Documentation). https://cursor.com/docs/rules Accessed 2026-03-29
2026
-
[11]
Will Epperson, Gagan Bansal, Victor Dibia, Adam Fourney, Jack Gerrits, Erkang Zhu, and Saleema Amershi. 2025. Interactive Debugging and Steering of Multi- Agent AI Systems. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA. doi:10.1145/3706598.3713581
-
[12]
KJ Feng, Kevin Pu, Matt Latzke, Tal August, Pao Siangliulue, Jonathan Bragg, Daniel S Weld, Amy X Zhang, and Joseph Chee Chang. 2024. Cocoa: Co-planning and co-execution with ai agents.arXiv preprint arXiv:2412.10999(2024). Zoro: Active Rules for Reliable Vibe Coding SUBMITTED FOR REVIEW, April 2026, New York, NY
-
[13]
Brubaker, Sarah E Fox, and Haiyi Zhu
Kasra Ferdowsi, Ruanqianqian (Lisa) Huang, Michael B. James, Nadia Polikarpova, and Sorin Lerner. 2024. Validating AI-Generated Code with Live Programming. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 143, 8 pages. doi:10.1145/36...
-
[14]
GitHub. 2026. Adding Repository Custom Instructions for GitHub Copi- lot. https://docs.github.com/copilot/customizing-copilot/adding-custom- instructions-for-github-copilot Accessed 2026-03-29
2026
- [15]
-
[16]
Google Cloud. 2025. What is vibe coding? https://cloud.google.com/discover/ what-is-vibe-coding. Accessed: 2026-03-28
2025
-
[17]
Gaole He, Gianluca Demartini, and Ujwal Gadiraju. 2025. Plan-then-execute: An empirical study of user trust and team performance when using llm agents as a daily assistant. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–22
2025
-
[18]
Shelton, Fanny Chevalier, Kari Kraus, and Niklas Elmqvist
Md Naimul Hoque, Tasfia Mashiat, Bhavya Ghai, Cecilia D. Shelton, Fanny Cheva- lier, Kari Kraus, and Niklas Elmqvist. 2024. The HaLLMark Effect: Supporting Provenance and Transparent Use of Large Language Models in Writing with Interactive Visualization. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). Association ...
- [19]
-
[20]
Andrej Karpathy. 2025.There’s a new kind of coding I call “vibe coding, ”. Retrieved March 28, 2026 from https://x.com/karpathy/status/1886192184808149383
-
[21]
Majeed Kazemitabaar, Jack Williams, Ian Drosos, Tovi Grossman, Austin Zachary Henley, Carina Negreanu, and Advait Sarkar. 2024. Improving Steering and Verification in AI-Assisted Data Analysis with Interactive Task Decomposition. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology(Pittsburgh, PA, USA)(UIST ’24). Associ...
-
[22]
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. 2026. LLMs Get Lost in Multi-Turn Conversation. InInternational Conference on Learning Representations (ICLR). https://arxiv.org/abs/2505.06120 ICLR 2026 Oral (preprint: arXiv:2505.06120)
work page internal anchor Pith review arXiv 2026
-
[23]
Philippe Laban, Jesse Vig, Marti Hearst, Caiming Xiong, and Chien-Sheng Wu
-
[24]
Beyond the Chat: Executable and Verifiable Text-Editing with LLMs. In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology(Pittsburgh, PA, USA)(UIST ’24). Association for Computing Machin- ery, New York, NY, USA, Article 20, 23 pages. doi:10.1145/3654777.3676419
-
[25]
Lee, David Porfirio, Xinyu Jessica Wang, Kevin Chenkai Zhao, and Bilge Mutlu
Christine P. Lee, David Porfirio, Xinyu Jessica Wang, Kevin Chenkai Zhao, and Bilge Mutlu. 2025. VeriPlan: Integrating Formal Verification and LLMs into End- User Planning. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 247, 19 pages. doi:10.1145/370...
-
[26]
Jenny T Liang, Chenyang Yang, and Brad A Myers. 2024. A large-scale survey on the usability of ai programming assistants: Successes and challenges. In Proceedings of the 46th IEEE/ACM international conference on software engineering. 1–13
2024
-
[27]
Vera Liao and Justin Vaughan
Q. Vera Liao and Justin Vaughan. 2024. AI Transparency in the Age of LLMs: A Human-Centered Research Agenda. Harvard Data Science Review (online). https://hdsr.mitpress.mit.edu/pub/aelql9qy Accessed 2026-03-29
2024
-
[28]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Association for Computational Linguistics 12 (2024), 157–173. doi:10.1162/tacl_a_00638
-
[29]
Ryan Lopopolo. 2026. Harness Engineering: Leveraging Codex in an Agent-First World. OpenAI Blog. https://openai.com/index/harness-engineering/ Accessed: 2026-03-27
2026
-
[30]
Jenny Ma, Riya Sahni, Karthik Sreedhar, and Lydia B. Chilton. 2025. Agent- DynEx: Nudging the Mechanics and Dynamics of Multi-Agent Simulations. arXiv:2504.09662 [cs.MA] https://arxiv.org/abs/2504.09662
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Jenny GuangZhen Ma, Karthik Sreedhar, Vivian Liu, Pedro A Perez, Sitong Wang, Riya Sahni, and Lydia B Chilton. 2025. Dynex: Dynamic code synthesis with structured design exploration for accelerated exploratory programming. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–27
2025
-
[32]
Peya Mowar, Yi-Hao Peng, Jason Wu, Aaron Steinfeld, and Jeffrey P Bigham. 2025. CodeA11y: Making AI Coding Assistants Useful for Accessible Web Development. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 45, 15 pages. doi:10.1145/3706598.3713335
-
[33]
OpenAI. 2024. Codex Guides: Introduction to AI Agents and AGENTS.md. https: //developers.openai.com/codex/guides/agents-md. Accessed: 2026-03-28
2024
-
[34]
OpenAI. 2026. Custom Instructions with AGENTS.md (Codex Documentation). https://developers.openai.com/codex/guides/agents-md/ Accessed 2026-03-29
2026
-
[35]
Yi-Hao Peng, Dingzeyu Li, Jeffrey P Bigham, and Amy Pavel. 2025. Morae: Proactively Pausing UI Agents for User Choices. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology (UIST ’25). Association for Computing Machinery, New York, NY, USA, Article 198, 14 pages. doi:10. 1145/3746059.3747797
-
[36]
Savvas Petridis, Benjamin D Wedin, James Wexler, Mahima Pushkarna, Aaron Donsbach, Nitesh Goyal, Carrie J Cai, and Michael Terry. 2024. Constitution- maker: Interactively critiquing large language models by converting feedback into principles. InProceedings of the 29th International Conference on Intelligent User Interfaces. 853–868
2024
-
[37]
Kevin Pu, Daniel Lazaro, Ian Arawjo, Haijun Xia, Ziang Xiao, Tovi Grossman, and Yan Chen. 2025. Assistance or Disruption? Exploring and Evaluating the Design and Trade-offs of Proactive AI Programming Support. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA. d...
-
[38]
Omar Shaikh, Shardul Sapkota, Shan Rizvi, Eric Horvitz, Joon Sung Park, Diyi Yang, and Michael S Bernstein. 2025. Creating general user models from computer use. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. 1–23
2025
-
[39]
Shreya Shankar, Bhavya Chopra, Mawil Hasan, Stephen Lee, Bjoern Hartmann, Joseph Hellerstein, Aditya Parameswaran, and Eugene Wu. 2025. Steering se- mantic data processing with docwrangler. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. 1–18
2025
-
[40]
Shreya Shankar, J. D. Zamfirescu-Pereira, Björn Hartmann, Aditya G. Parameswaran, and Ian Arawjo. 2024. Who Validates the Validators? Align- ing LLM-Assisted Evaluation of LLM Outputs with Human Preferences. InPro- ceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (UIST ’24). Association for Computing Machinery, New York,...
-
[41]
Priyan Vaithilingam, Munyeong Kim, Frida-Cecilia Acosta-Parenteau, Daniel Lee, Amine Mhedhbi, Elena L Glassman, and Ian Arawjo. 2025. Semantic Commit: Helping Users Update Intent Specifications for AI Memory at Scale. InProceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. 1–18
2025
-
[42]
Ruotong Wang, Ruijia Cheng, Denae Ford, and Thomas Zimmermann. 2024. Investigating and Designing for Trust in AI-powered Code Generation Tools. In The 2024 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’24). ACM, 1475–1493. doi:10.1145/3630106.3658984
-
[43]
Litao Yan, Alyssa Hwang, Zhiyuan Wu, and Andrew Head. 2024. Ivie: Lightweight Anchored Explanations of Just-Generated Code. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 140, 15 pages. doi:10.1145/3613904.3642239
-
[44]
Litao Yan, Jeffrey Tao, Lydia B Chilton, and Andrew Head. 2025. Answering Developer Questions with Annotated Agent-Discovered Program Traces. In Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology (UIST ’25). Association for Computing Machinery, New York, NY, USA, Article 29, 14 pages. doi:10.1145/3746059.3747652
-
[45]
Qian Yang, JD Zamfirescu-Pereira, Jessie Jia, and Asad Nabi. 2025. TrumanBench: Profiling LLMs’ Ability to Help Non-Programmers Modify a Real-World Code Base. (2025)
2025
-
[46]
JD Zamfirescu-Pereira, Eunice Jun, Michael Terry, Qian Yang, and Bjoern Hart- mann. 2025. Beyond code generation: Llm-supported exploration of the program design space. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–17
2025
-
[47]
Default green color that is used in the header in the frontend
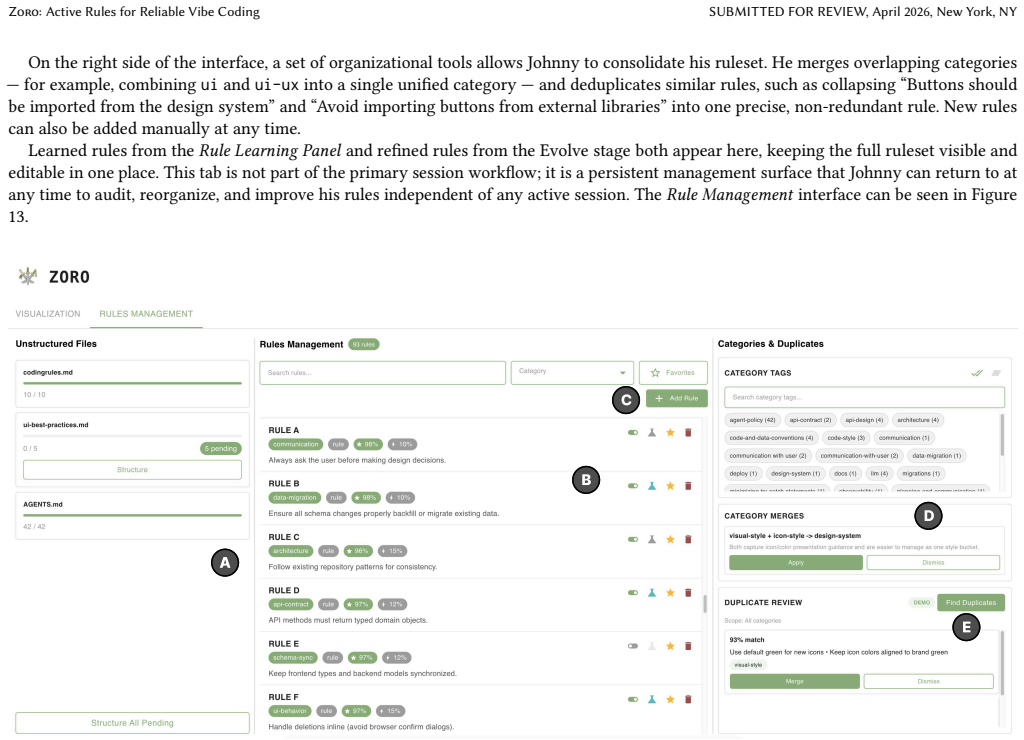
Xuanming Zhang, Sitong Wang, Jenny Ma, Alyssa Hwang, Zhou Yu, and Lydia B Chilton. 2024. JumpStarter: Human-AI Planning with Task-Structured Context Curation.arXiv preprint arXiv:2410.03882(2024). SUBMITTED FOR REVIEW, April 2026, New York, NY Ma et al. A System A.1 Library and Frameworks Zoro’s interface is written in Typescript and React. The backend is...
-
[48]
Call`zoro update-step <step-id> in_progress`when work begins
-
[49]
" --evidence
Call`zoro prove-rule <step-id> --rule "..." --evidence "..."`for each required rule
-
[50]
<rule␣text>
Only after required rule evidence is submitted, call`zoro update-step <step-id> completed`. ## Hard Stops - Do not mark a step`completed`before required`zoro prove-rule`calls. - Do not start the next step while the current step is incomplete. - If evidence is missing or weak, remain on the current step and add better proof. ## Evidence Guidance (Concise) ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.