Recognition: unknown
HyCal: A Training-Free Prototype Calibration Method for Cross-Discipline Few-Shot Class-Incremental Learning
Pith reviewed 2026-05-10 09:10 UTC · model grok-4.3
The pith
A training-free method blends cosine similarity and Mahalanobis distance on frozen CLIP embeddings to stabilize prototypes against domain imbalance in few-shot continual learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HyCal, operating on frozen CLIP embeddings, combines cosine similarity and Mahalanobis distance to capture complementary geometric properties-directional alignment and covariance-aware magnitude-yielding stable prototypes under imbalanced heterogeneous conditions and mitigating Domain Gravity in cross-discipline variable few-shot class-incremental learning.
What carries the argument
Hybrid Prototype Calibration (HyCal), which blends cosine similarity for directional alignment with Mahalanobis distance for magnitude adjustment on frozen embeddings to counteract prototype drift.
If this is right
- Existing FSCIL methods that assume homogeneous domains and balanced distributions become limited when applied to real-world cross-discipline data.
- Training-free calibration on frozen embeddings preserves efficiency while still delivering retention and adaptation gains.
- Prototype drift from overrepresented low-entropy domains can be reduced without retraining the underlying model.
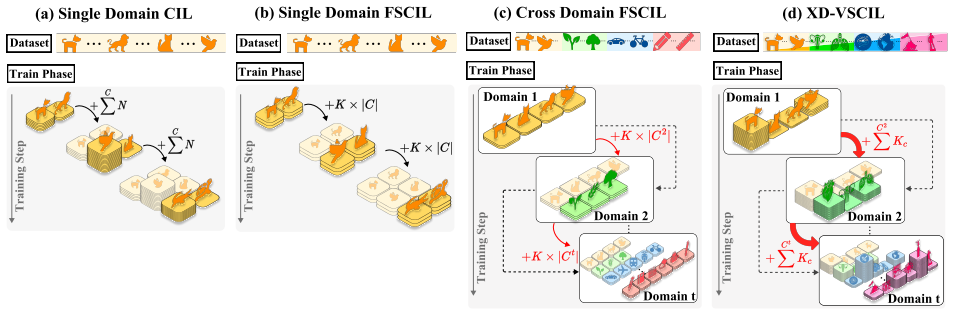
- The XD-VSCIL benchmark makes it possible to measure how well methods handle naturally occurring imbalance across disciplines.
Where Pith is reading between the lines
- The same calibration principle might apply to other pre-trained embedding models if the two distance measures continue to provide complementary information.
- Domains with very different visual entropy levels could be explicitly weighted during calibration to further reduce gravity effects.
- Future continual-learning benchmarks should report domain-imbalance statistics alongside accuracy to reflect the conditions the paper identifies.
- Combining HyCal with lightweight memory replay could test whether the training-free property holds when some adaptation is reintroduced.
Load-bearing premise
That combining cosine similarity and Mahalanobis distance on frozen embeddings is enough to capture the geometric properties needed to stabilize prototypes in every kind of heterogeneous and imbalanced setting.
What would settle it
Running HyCal on an extreme-imbalance test set where one domain supplies 90 percent of samples while another supplies 5 percent and checking whether accuracy on the minority domain still exceeds that of standard prototype-based FSCIL baselines.
Figures








read the original abstract
Pretrained Vision-Language Models (VLMs) like CLIP show promise in continual learning, but existing Few-Shot Class-Incremental Learning (FSCIL) methods assume homogeneous domains and balanced data distributions, limiting real-world applicability where data arises from heterogeneous disciplines with imbalanced sample availability and varying visual complexity. We identify Domain Gravity, a representational asymmetry where data imbalance across heterogeneous domains causes overrepresented or low-entropy domains to disproportionately influence the embedding space, leading to prototype drift and degraded performance on underrepresented or high-entropy domains. To address this, we introduce Cross-Discipline Variable Few-Shot Class-Incremental Learning (XD-VSCIL), a benchmark capturing real-world heterogeneity and imbalance where Domain Gravity naturally intensifies. We propose Hybrid Prototype Calibration (HyCal), a training-free method combining cosine similarity and Mahalanobis distance to capture complementary geometric properties-directional alignment and covariance-aware magnitude-yielding stable prototypes under imbalanced heterogeneous conditions. Operating on frozen CLIP embeddings, HyCal achieves consistent retention-adaptation improvements while maintaining efficiency. Experiments show HyCal effectively mitigates Domain Gravity and outperforms existing methods in imbalanced cross-domain incremental learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies 'Domain Gravity' as a representational asymmetry in cross-discipline few-shot class-incremental learning (XD-VSCIL) with pretrained VLMs such as CLIP, where data imbalance across heterogeneous domains causes prototype drift. It introduces the XD-VSCIL benchmark to capture real-world heterogeneity and imbalance, and proposes HyCal, a training-free prototype calibration method that combines cosine similarity (for directional alignment) and Mahalanobis distance (for covariance-aware magnitude) on frozen CLIP embeddings to yield stable prototypes. The central claim is that HyCal mitigates Domain Gravity, achieves consistent retention-adaptation improvements, maintains efficiency, and outperforms existing FSCIL methods in imbalanced cross-domain settings.
Significance. If the empirical claims hold, the work addresses a practically relevant gap in continual learning by providing an efficient, parameter-free approach for heterogeneous, imbalanced data without requiring model updates or additional training. The XD-VSCIL benchmark could serve as a useful testbed for future methods. However, the significance is tempered by the paper's introduction of the core phenomenon and benchmark, which creates dependence on the authors' framing, and by the absence of demonstrated robustness of the hybrid metric under violated embedding assumptions.
major comments (2)
- [Abstract] Abstract: the claim of outperformance and effective mitigation of Domain Gravity is asserted without any quantitative results, baseline comparisons, statistical tests, ablation studies, or dataset details, rendering it impossible to evaluate whether the data supports the central claims.
- [Method] Method description (hybrid distance formulation): the argument that cosine similarity and Mahalanobis distance capture complementary orthogonal geometric properties sufficient to neutralize Domain Gravity without any adaptation rests on the unverified assumption that frozen CLIP embeddings encode reliable second-order statistics across all disciplines and imbalance levels. No derivation, stability analysis, or ablation is provided to show the hybrid distance remains stable (rather than increasing prototype drift) when high-entropy domains yield near-singular covariances or few-shot estimates are noisy.
minor comments (2)
- [§3] Clarify the precise combination rule for the two metrics (e.g., weighted sum, product, or other) and any hyperparameters involved, even if claimed to be training-free.
- [§4] Provide the exact definition and construction of the XD-VSCIL benchmark, including how domains, imbalance ratios, and class splits are chosen, to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of outperformance and effective mitigation of Domain Gravity is asserted without any quantitative results, baseline comparisons, statistical tests, ablation studies, or dataset details, rendering it impossible to evaluate whether the data supports the central claims.
Authors: We agree that the abstract, being a concise overview, does not include specific quantitative results or details. The full manuscript contains these elements in the experiments section, including baseline comparisons, ablations, and XD-VSCIL dataset descriptions. We will revise the abstract to incorporate key quantitative highlights from our results (e.g., retention-adaptation gains) to better support the claims while maintaining brevity. revision: yes
-
Referee: [Method] Method description (hybrid distance formulation): the argument that cosine similarity and Mahalanobis distance capture complementary orthogonal geometric properties sufficient to neutralize Domain Gravity without any adaptation rests on the unverified assumption that frozen CLIP embeddings encode reliable second-order statistics across all disciplines and imbalance levels. No derivation, stability analysis, or ablation is provided to show the hybrid distance remains stable (rather than increasing prototype drift) when high-entropy domains yield near-singular covariances or few-shot estimates are noisy.
Authors: The hybrid metric is motivated by the complementary nature of directional (cosine) and covariance-aware (Mahalanobis) distances to counter prototype drift from domain imbalance, as motivated in the method section. We do not provide a formal derivation or explicit stability analysis for edge cases like near-singular covariances. Our empirical results across disciplines support stability, but we acknowledge the gap and will add a discussion on covariance regularization (e.g., shrinkage estimators), a brief stability argument, and an ablation on high-entropy/noisy few-shot regimes in the revised manuscript. revision: partial
Circularity Check
No significant circularity detected in the claimed derivation.
full rationale
The paper introduces Domain Gravity as an observed representational asymmetry in heterogeneous imbalanced settings and defines the XD-VSCIL benchmark to study it, then proposes the training-free HyCal combination of cosine similarity and Mahalanobis distance on frozen CLIP embeddings. No equations, first-principles derivations, or predictions are shown that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The complementarity of the two metrics is presented as a design choice whose efficacy is evaluated empirically on the new benchmark rather than asserted tautologically. This is a standard non-circular contribution pattern for a new problem formulation and method.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained VLMs such as CLIP produce embeddings that remain useful for incremental learning across heterogeneous domains when frozen.
invented entities (1)
-
Domain Gravity
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Distributions of angles in random packing on spheres.The Journal of Ma- chine Learning Research, 14(1):1837–1864, 2013
Tony Cai, Jianqing Fan, and Tiefeng Jiang. Distributions of angles in random packing on spheres.The Journal of Ma- chine Learning Research, 14(1):1837–1864, 2013. 5
2013
-
[2]
Online continual learning from imbalanced data
Aristotelis Chrysakis and Marie-Francine Moens. Online continual learning from imbalanced data. InInt. Conf. Mach. Learn.JMLR.org, 2020. 1
2020
-
[3]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InIEEE Conf. Comput. Vis. Pattern Recog., pages 3606–3613, 2014. 3, 4, 8
2014
-
[4]
The mnist database of handwritten digit images for machine learning research [best of the web].IEEE Signal Processing Magazine, 29(6):141–142, 2012
Li Deng. The mnist database of handwritten digit images for machine learning research [best of the web].IEEE Signal Processing Magazine, 29(6):141–142, 2012. 4, 9
2012
-
[5]
Clip-adapter: Better vision-language models with feature adapters.Int
Peng Gao, Shijie Geng, Renrui Zhang, Teli Ma, Rongyao Fang, Yongfeng Zhang, Hongsheng Li, and Yu Qiao. Clip-adapter: Better vision-language models with feature adapters.Int. J. Comput. Vis., 132(2):581–595, 2024. 1, 3
2024
-
[6]
Fecam: Exploiting the heterogeneity of class distributions in exemplar-free continual learning.Adv
Dipam Goswami, Yuyang Liu, Bartłomiej Twardowski, and Joost Van De Weijer. Fecam: Exploiting the heterogeneity of class distributions in exemplar-free continual learning.Adv. Neural Inform. Process. Syst., 36:6582–6595, 2023. 1, 2, 3, 6, 7, 8, 5, 10
2023
-
[7]
Calibrating higher-order statistics for few-shot class-incremental learning with pre-trained vision transform- ers
Dipam Goswami, Bartłomiej Twardowski, and Joost Van De Weijer. Calibrating higher-order statistics for few-shot class-incremental learning with pre-trained vision transform- ers. InIEEE Conf. Comput. Vis. Pattern Recog., pages 4075– 4084, 2024. 1, 2, 3
2024
-
[8]
Informa- tion retrieval optimization for non-exemplar class incremen- tal learning
Shuai Guo, Yang Gu, Yuan Ma, Yingwei Zhang, Weining Weng, Jun Liu, Weiwei Dai, and Yiqiang Chen. Informa- tion retrieval optimization for non-exemplar class incremen- tal learning. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 717–726, 2024. 1
2024
-
[9]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2019. 4, 8
2019
-
[10]
Dynamically anchored prompting for task-imbalanced continual learning
Chenxing Hong, Yan Jin, Zhiqi Kang, Yizhou Chen, Mengke Li, Yang Lu, and Hanzi Wang. Dynamically anchored prompting for task-imbalanced continual learning. InIJCAI, pages 4127–4135, 2024. 3
2024
-
[11]
Online continual learning via logit adjusted softmax.Trans
Zhehao Huang, Tao Li, Chenhe Yuan, Yingwen Wu, and Xi- aolin Huang. Online continual learning via logit adjusted softmax.Trans. Mach. Learn. Res., 2024, 2024. 1
2024
-
[12]
Open- clip, 2021
Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Han- naneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. Open- clip, 2021. 3
2021
-
[13]
Deep learning of multi- element abundances from high-resolution spectroscopic data.Monthly Notices of the Royal Astronomical Society, 483(3):3255–3277, 2018
Henry W Leung and Jo Bovy. Deep learning of multi- element abundances from high-resolution spectroscopic data.Monthly Notices of the Royal Astronomical Society, 483(3):3255–3277, 2018. 4, 9
2018
-
[14]
The double-ellipsoid ge- ometry of clip
Meir Yossef Levi and Guy Gilboa. The double-ellipsoid ge- ometry of clip. InInt. Conf. Learn. Represent., pages 33999– 34019. PMLR, 2025. 2
2025
-
[15]
Blip-2: bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: bootstrapping language-image pre-training with frozen image encoders and large language models. InInt. Conf. Mach. Learn., pages 19730–19742, 2023. 3
2023
-
[16]
Clms: Bridging domain gaps in medical imaging segmentation with source-free continual learning for robust knowledge transfer and adaptation.Medical Image Analysis, 100:103404, 2025
Weilu Li, Yun Zhang, Hao Zhou, Wenhan Yang, Zhi Xie, and Yao He. Clms: Bridging domain gaps in medical imaging segmentation with source-free continual learning for robust knowledge transfer and adaptation.Medical Image Analysis, 100:103404, 2025. 1
2025
-
[17]
Hehai Lin, Hui Liu, Shilei Cao, Jing Li, Haoliang Li, and Wenya Wang
Peiyuan Liao, Xiuyu Li, Xihui Liu, and Kurt Keutzer. The artbench dataset: Benchmarking generative models with art- works.arXiv preprint arXiv:2206.11404, 2022. 4, 8
-
[18]
Lada: Scalable label-specific clip adapter for con- tinual learning
Mao-Lin Luo, Zi-Hao Zhou, Tong Wei, and Min-Ling Zhang. Lada: Scalable label-specific clip adapter for con- tinual learning. InInt. Conf. Mach. Learn., pages 41604– 41619. PMLR, 2025. 1, 2
2025
-
[19]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine-grained visual classi- fication of aircraft.arXiv preprint arXiv:1306.5151, 2013. 4, 8
work page internal anchor Pith review arXiv 2013
-
[20]
John Wiley & Sons, 2024
Kanti V Mardia, John T Kent, and Charles C Taylor.Multi- variate analysis. John Wiley & Sons, 2024. 5
2024
-
[21]
Pip: Prototypes-injected prompt for federated class incremental learning
Muhammad Anwar Ma’sum, Mahardhika Pratama, Savitha Ramasamy, Lin Liu, Habibullah Habibullah, and Ryszard Kowalczyk. Pip: Prototypes-injected prompt for federated class incremental learning. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 1670–1679, 2024. 1
2024
-
[22]
Ranpac: Random projections and pre-trained models for continual learning
Mark D McDonnell, Dong Gong, Amin Parvaneh, Ehsan Abbasnejad, and Anton Van den Hengel. Ranpac: Random projections and pre-trained models for continual learning. Adv. Neural Inform. Process. Syst., 36:12022–12053, 2023. 3, 6, 7, 8, 5, 10
2023
-
[23]
Continual learning using a kernel-based method over foundation mod- els
Saleh Momeni, Sahisnu Mazumder, and Bing Liu. Continual learning using a kernel-based method over foundation mod- els. InAAAI, pages 19528–19536, 2025. 3, 6, 7, 8, 5, 10
2025
-
[24]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. InIn- dian Conference on Computer Vision, Graphics and Image Processing, 2008. 4, 9
2008
-
[25]
Interpreting the linear structure of vision-language model embedding spaces
Isabel Papadimitriou, Huangyuan Su, Thomas Fel, Sham M Kakade, and Stephanie Gil. Interpreting the linear structure of vision-language model embedding spaces. InSecond Con- ference on Language Modeling, 2025. 6, 2
2025
-
[26]
Understanding the feature norm for out- of-distribution detection
Jaewoo Park, Jacky Chen Long Chai, Jaeho Yoon, and An- drew Beng Jin Teoh. Understanding the feature norm for out- of-distribution detection. InInt. Conf. Comput. Vis., pages 1557–1567, 2023. 2
2023
-
[27]
Jianing Qi, Jiawei Liu, Hao Tang, and Zhigang Zhu. Be- yond semantics: Rediscovering spatial awareness in vision- language models.arXiv preprint arXiv:2503.17349, 2025. 6, 2
-
[28]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InInt. Conf. Mach. Learn., pages 8748–8763. PmLR,
-
[29]
Liu, Abhijit Guha Roy, Shreyas Padhy, and Balaji Lakshminarayanan
Jie Ren, Stanislav Fort, Jeremiah Liu, Abhijit Guha Roy, Shreyas Padhy, and Balaji Lakshminarayanan. A simple fix to mahalanobis distance for improving near-ood detection. arXiv preprint arXiv:2106.09022, 2021. 7
-
[30]
Mos: Model surgery for pre- trained model-based class-incremental learning
Hai-Long Sun, Da-Wei Zhou, Hanbin Zhao, Le Gan, De- Chuan Zhan, and Han-Jia Ye. Mos: Model surgery for pre- trained model-based class-incremental learning. InAAAI, pages 20699–20707, 2025. 1
2025
-
[31]
Few-shot out of domain intent detection with covariance corrected ma- halanobis distance.AAAI Workshop on Uncertainty Reason- ing and Quantification in Decision Making, 2023
Jayasimha Talur, Oleg Smirnov, and Paul Missault. Few-shot out of domain intent detection with covariance corrected ma- halanobis distance.AAAI Workshop on Uncertainty Reason- ing and Quantification in Decision Making, 2023. 2
2023
-
[32]
Few-shot class- incremental learning
Xiaoyu Tao, Xiaopeng Hong, Xinyuan Chang, Songlin Dong, Xing Wei, and Yihong Gong. Few-shot class- incremental learning. InIEEE Conf. Comput. Vis. Pattern Recog., pages 12183–12192, 2020. 1, 2
2020
-
[33]
What makes clip more robust to long-tailed pre-training data? a controlled study for transferable in- sights.Adv
Xin Wen, Bingchen Zhao, Yilun Chen, Jiangmiao Pang, and Xiaojuan Qi. What makes clip more robust to long-tailed pre-training data? a controlled study for transferable in- sights.Adv. Neural Inform. Process. Syst., 37:36567–36601,
-
[34]
Defying imbalanced forgetting in class incremental learning
Shixiong Xu, Gaofeng Meng, Xing Nie, Bolin Ni, Bin Fan, and Shiming Xiang. Defying imbalanced forgetting in class incremental learning. InAAAI, pages 16211–16219, 2024. 1, 3
2024
-
[35]
Advancing cross- domain discriminability in continual learning of vision- language models.Adv
Yicheng Xu, Yuxin Chen, Jiahao Nie, Yusong Wang, Huip- ing Zhuang, and Manabu Okumura. Advancing cross- domain discriminability in continual learning of vision- language models.Adv. Neural Inform. Process. Syst., 37: 51552–51576, 2024. 1, 2, 3, 6, 7, 8, 5, 10
2024
-
[36]
Medmnist clas- sification decathlon: A lightweight automl benchmark for medical image analysis
Jiancheng Yang, Rui Shi, and Bingbing Ni. Medmnist clas- sification decathlon: A lightweight automl benchmark for medical image analysis. InIEEE 18th International Sympo- sium on Biomedical Imaging (ISBI), pages 191–195, 2021. 3, 4, 9
2021
-
[37]
Boosting continual learning of vision-language models via mixture-of-experts adapters
Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Ping Hu, Dong Wang, Huchuan Lu, and You He. Boosting continual learning of vision-language models via mixture-of-experts adapters. InIEEE Conf. Comput. Vis. Pattern Recog., pages 23219– 23230, 2024. 1, 2
2024
-
[38]
Class-incremental learning: A survey.IEEE Trans
Da-Wei Zhou, Qi-Wei Wang, Zhi-Hong Qi, Han-Jia Ye, De- Chuan Zhan, and Ziwei Liu. Class-incremental learning: A survey.IEEE Trans. Pattern Anal. Mach. Intell., 2024. 4
2024
-
[39]
Learning to prompt for vision-language models.Int
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.Int. J. Comput. Vis., 130(9):2337–2348, 2022. 3 HYCAL: A Training-Free Prototype Calibration Method for Cross-Discipline Few-Shot Class-Incremental Learning Supplementary Material
2022
-
[40]
Supplementary on the complementary roles and mutual information between cosine and Mahalanobis measures This supplementary section provides additional analysis supporting the complementary relationship between cosine similarity and Mahalanobis distance, as formalized in The- orem 1 and Theorem 2. While both measures are computed from the same embedding pa...
-
[41]
Additional ablation study To further evaluate the stability and design choices of HY- CAL, we conduct ablation studies on three components: ro- bustness to domain order, sensitivity to hyperparameters, and the effect of different image–text embedding fusion strategies. These analyses assess whether the method main- tains consistent performance under diffe...
1993
-
[42]
Efficiency analysis Because HYCALkeeps the pretrained backbone frozen and updates only class prototypes and regularized precision ma- trices for newly introduced classes, its computational cost scales with the number of new classes rather than with full model retraining. Unlike prior approaches that recompute statistics over all classes or domains in XD-V...
-
[43]
Implementation details We use the Vision Transformer (ViT-B/16) model with a frozen CLIP text encoder for all experi- ments
Detailed experimental setting 10.1. Implementation details We use the Vision Transformer (ViT-B/16) model with a frozen CLIP text encoder for all experi- ments. The model weights are loaded from the openai/clip-vit-base-patch16checkpoint. The image encoder’s parameters are kept frozen throughout all experiments. All experiments were conducted using Py- To...
1993
-
[44]
The Balanced-in-Class Domain setting results are provided in Tab
Numerical results of Balanced-in-class do- main and Cross-scale imbalance settings For completeness, we provide the numerical values for the Balanced-in-class domain and Cross-scale imbalance set- tings. The Balanced-in-Class Domain setting results are provided in Tab. 12, and the Cross-scale imbalance setting results are summarized in Tab. 13
-
[45]
Accordingly, its effectiveness depends on the quality of the underlying representation space
Limitations HYCALis designed for settings in which frozen pre- trained representations are already sufficiently informative and where prototype-level calibration is preferable to back- bone adaptation. Accordingly, its effectiveness depends on the quality of the underlying representation space. When newly arriving tasks come from domains that lie far out-...
1900
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.