SENSE: Stereo OpEN Vocabulary SEmantic Segmentation
Pith reviewed 2026-05-10 08:13 UTC · model grok-4.3
The pith
Stereo image pairs supply geometric cues that improve accuracy in open-vocabulary semantic segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
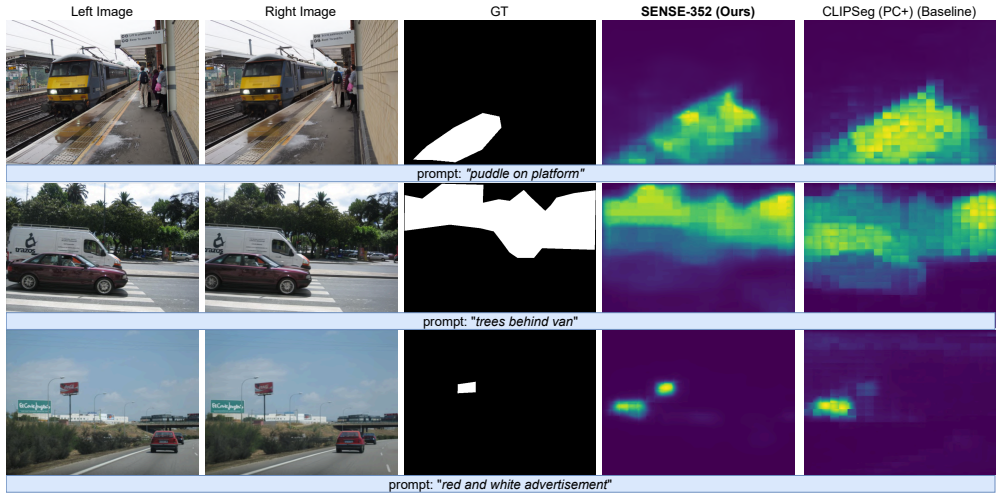
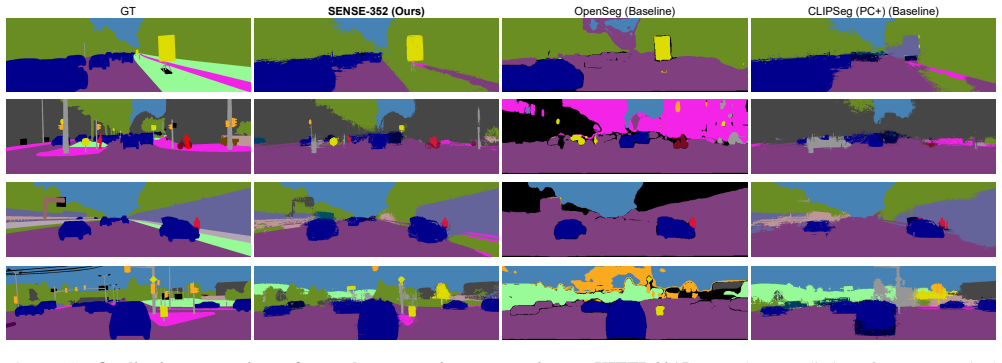
SENSE is the first stereo open-vocabulary semantic segmentation method. It uses stereo image pairs to introduce geometric cues that improve spatial reasoning inside vision-language models. Trained on PhraseStereo, the approach raises Average Precision by 2.9 percent over the baseline and 0.76 percent over the strongest competing method while delivering relative mIoU gains of 3.5 percent on Cityscapes and 18 percent on KITTI.
What carries the argument
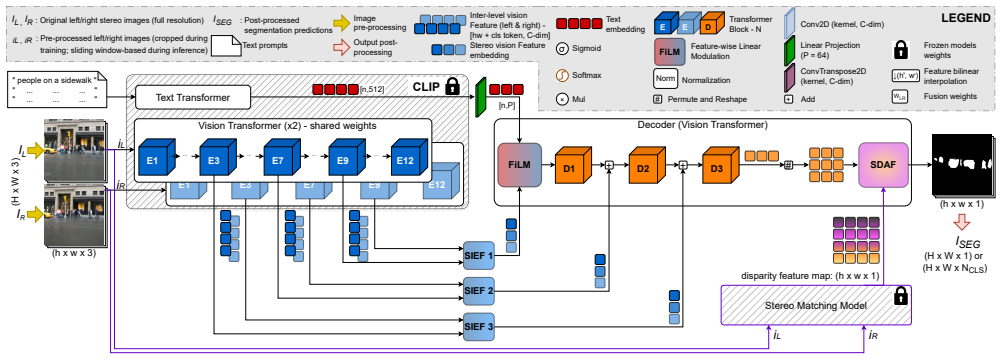
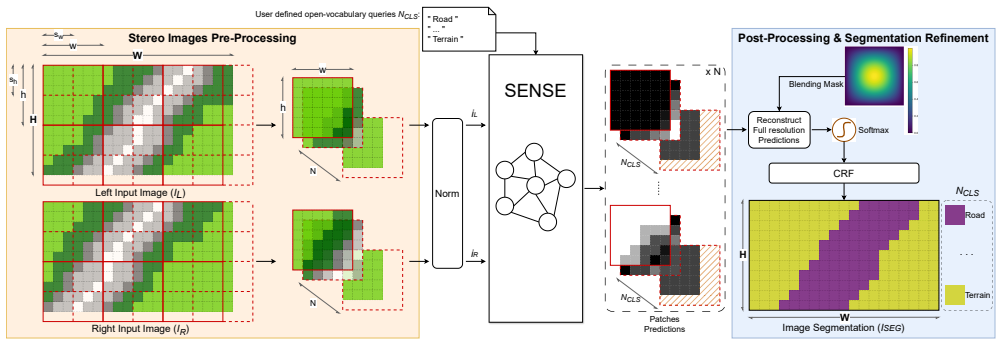
SENSE, the method that fuses stereo-derived geometric cues with vision-language model features to produce open-vocabulary segmentations.
If this is right
- More precise handling of object boundaries and occlusions in open-vocabulary tasks.
- Stronger zero-shot generalization across datasets when geometry augments semantics.
- Improved support for phrase-grounded segmentation in stereo-equipped robotic systems.
- Joint semantic-geometry reasoning enables more accurate natural-language scene understanding for autonomous vehicles.
Where Pith is reading between the lines
- The stereo cue mechanism could transfer to other multi-view camera rigs common in vehicles.
- Robustness testing under varying stereo quality would clarify when the geometric benefit holds.
Load-bearing premise
Stereo image pairs reliably supply geometric cues that improve segmentation accuracy without errors from stereo matching, calibration, or occlusions outweighing the gains.
What would settle it
A controlled test on scenes with known stereo matching failures, such as low-texture regions or deliberately miscalibrated pairs, where SENSE shows no improvement or worse performance than the single-image baseline.
Figures







read the original abstract
Open-vocabulary semantic segmentation enables models to segment objects or image regions beyond fixed class sets, offering flexibility in dynamic environments. However, existing methods often rely on single-view images and struggle with spatial precision, especially under occlusions and near object boundaries. We propose SENSE, the first work on Stereo OpEN Vocabulary SEmantic Segmentation, which leverages stereo vision and vision-language models to enhance open-vocabulary semantic segmentation. By incorporating stereo image pairs, we introduce geometric cues that improve spatial reasoning and segmentation accuracy. Trained on the PhraseStereo dataset, our approach achieves strong performance in phrase-grounded tasks and demonstrates generalization in zero-shot settings. On PhraseStereo, we show a +2.9% improvement in Average Precision over the baseline method and +0.76% over the best competing method. SENSE also provides a relative improvement of +3.5% mIoU on Cityscapes and +18% on KITTI compared to the baseline work. By jointly reasoning over semantics and geometry, SENSE supports accurate scene understanding from natural language, essential for autonomous robots and Intelligent Transportation Systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SENSE, the first stereo-based approach to open-vocabulary semantic segmentation. It leverages stereo image pairs to supply geometric cues for improved spatial reasoning and boundary precision, trains on a newly introduced PhraseStereo dataset, and reports gains of +2.9% AP on PhraseStereo over baseline (+0.76% over best competitor), +3.5% mIoU on Cityscapes, and +18% mIoU on KITTI relative to prior single-view baselines. The work also claims zero-shot generalization.
Significance. If the performance gains can be causally attributed to stereo geometric cues rather than dataset or architecture changes, the work would be a meaningful first step in combining stereo vision with vision-language models for open-vocabulary tasks. This is relevant for robotics and ITS applications where stereo cameras are common. The new PhraseStereo dataset is a concrete positive contribution that could support future research.
major comments (2)
- [§4 (Experiments)] §4 (Experiments) and associated tables: the central claim that stereo pairs supply geometric cues improving open-vocabulary segmentation is not supported by controlled ablations. No experiments fix the VLM backbone, training data, hyperparameters, and loss while toggling only between stereo pairs and monocular input (or between full stereo and stereo with depth/disparity disabled). The reported deltas (+2.9% AP, +3.5% mIoU, +18% mIoU) therefore cannot be attributed specifically to geometric reasoning; they could arise from the new PhraseStereo training set or the custom stereo+VLM architecture.
- [§3 (Method)] §3 (Method): the description of how stereo features are fused with the vision-language model (e.g., disparity estimation, feature concatenation, or attention over depth) is insufficient to assess whether geometric cues are actually used or whether stereo matching errors in occluded/textureless regions are mitigated. No equations or diagrams detail this fusion step, which is load-bearing for the geometric-cue hypothesis.
minor comments (3)
- [Abstract] Abstract and §1: the phrase 'strong performance in phrase-grounded tasks' is vague; quantitative metrics and comparison to the exact baseline implementation should be stated explicitly.
- [§4 (Experiments)] §4: no error bars, standard deviations, or statistical significance tests are mentioned for the reported percentage improvements, making it hard to judge whether the gains are reliable.
- [§2 (Related Work)] Missing reference to prior stereo semantic segmentation works (even if closed-vocabulary) and to recent open-vocabulary methods that already incorporate depth or 3D cues.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important areas for strengthening the attribution of gains to stereo cues and improving methodological clarity. We address each major comment below and will incorporate revisions to enhance the manuscript.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments) and associated tables: the central claim that stereo pairs supply geometric cues improving open-vocabulary segmentation is not supported by controlled ablations. No experiments fix the VLM backbone, training data, hyperparameters, and loss while toggling only between stereo pairs and monocular input (or between full stereo and stereo with depth/disparity disabled). The reported deltas (+2.9% AP, +3.5% mIoU, +18% mIoU) therefore cannot be attributed specifically to geometric reasoning; they could arise from the new PhraseStereo training set or the custom stereo+VLM architecture.
Authors: We agree that the current set of experiments does not include a fully isolated ablation that holds the VLM backbone, training data, hyperparameters, and loss fixed while toggling only the stereo input. Our reported comparisons are against single-view baselines that use comparable VLMs, and the larger gains on stereo-specific datasets (PhraseStereo, KITTI) are consistent with the value of geometric cues. To directly address the concern, we will add a controlled ablation in the revised §4 that disables the stereo fusion module (or replaces stereo pairs with monocular input) while keeping all other factors identical. This will allow clearer attribution of performance deltas to the geometric reasoning component. revision: yes
-
Referee: [§3 (Method)] §3 (Method): the description of how stereo features are fused with the vision-language model (e.g., disparity estimation, feature concatenation, or attention over depth) is insufficient to assess whether geometric cues are actually used or whether stereo matching errors in occluded/textureless regions are mitigated. No equations or diagrams detail this fusion step, which is load-bearing for the geometric-cue hypothesis.
Authors: We acknowledge that the fusion mechanism in §3 requires additional detail to allow readers to evaluate how geometric cues are integrated and how stereo errors are handled. In the revised manuscript we will expand the method section with explicit equations for disparity estimation and the stereo-VLM feature fusion (including the specific attention or concatenation operations), add a dedicated diagram of the fusion pipeline, and include a short discussion of error mitigation strategies such as confidence-weighted fusion and multi-scale processing for occluded or textureless regions. revision: yes
Circularity Check
No circularity: empirical method validated on external datasets without self-referential derivations
full rationale
The paper introduces SENSE as an empirical architecture combining stereo pairs with vision-language models for open-vocabulary segmentation. It reports performance gains on the newly introduced PhraseStereo dataset and on standard external benchmarks (Cityscapes, KITTI) without any equations, derivations, fitted-parameter predictions, or load-bearing self-citations. All claims rest on measured improvements against baselines and competitors rather than any quantity that reduces to its own inputs by construction. The evaluation is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stereo image pairs provide geometric cues that improve spatial reasoning and segmentation accuracy in open-vocabulary tasks
Reference graph
Works this paper leans on
-
[1]
Sanjeda Akter, Ibne Farabi Shihab, and Anuj Sharma. Im- age segmentation with large language models: A survey with perspectives for intelligent transportation systems. arXiv preprint arXiv:2506.14096, 2025. 1, 2, 5, 6
-
[2]
Augmented re- ality meets computer vision: Efficient data generation for urban driving scenes
Mescheder Lars Geiger Andreas Alhaija Hassan, Mustikovela Siva and Rother Carsten. Augmented re- ality meets computer vision: Efficient data generation for urban driving scenes. IJCV, 2018. 3, 5, 6, 7, 9, 10, 11
work page 2018
-
[3]
Zero-shot semantic segmentation
Maxime Bucher, Tuan-Hung Vu, Matthieu Cord, and Patrick P´erez. Zero-shot semantic segmentation. NeurIPS, 32, 2019. 5
work page 2019
-
[4]
Phrasestereo: The first open-vocabulary stereo image segmentation dataset
Thomas Campagnolo, Ezio Malis, Philippe Martinet, and Gaetan Bahl. Phrasestereo: The first open-vocabulary stereo image segmentation dataset. arXiv preprint arXiv:2510.00818, 2025. 2, 3, 5, 10
-
[5]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In ICCV, pages 9650–9660, 2021. 2
work page 2021
-
[6]
Encoder-decoder with atrous separable convolution for semantic image segmentation
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In ECCV, pages 801–818, 2018. 1
work page 2018
-
[7]
Mocha-stereo: Motif chan- nel attention network for stereo matching
Ziyang Chen, Wei Long, He Yao, Yongjun Zhang, Bingshu Wang, Yongbin Qin, and Jia Wu. Mocha-stereo: Motif chan- nel attention network for stereo matching. In CVPR, pages 27768–27777, 2024. 4
work page 2024
-
[8]
Masked-attention mask transformer for universal image segmentation
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexan- der Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. In CVPR, pages 1290–1299, 2022. 1
work page 2022
-
[9]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In CVPR,
-
[10]
2, 3, 5, 6, 7, 9, 10, 11, 12
-
[11]
Vision transformers need registers
Timoth ´ee Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. In ICLR,
-
[12]
Bert: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding. InNAACL, pages 4171– 4186, 2019. 2
work page 2019
-
[13]
Vincent Dumoulin, Ethan Perez, Nathan Schucher, Florian Strub, Harm de Vries, Aaron Courville, and Yoshua Bengio. Feature-wise transformations. Distill, 3(7):e11, 2018. 3, 4
work page 2018
-
[14]
Scal- ing open-vocabulary image segmentation with image-level labels
Golnaz Ghiasi, Xiuye Gu, Yin Cui, and Tsung-Yi Lin. Scal- ing open-vocabulary image segmentation with image-level labels. In ECCV, pages 540–557. Springer, 2022. 2, 5, 6, 7, 8, 11, 12, 13, 14
work page 2022
-
[15]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016. 2
work page 2016
-
[16]
Defom-stereo: Depth foundation model based stereo matching
Hualie Jiang, Zhiqiang Lou, Laiyan Ding, Rui Xu, Minglang Tan, Wenjie Jiang, and Rui Huang. Defom-stereo: Depth foundation model based stereo matching. In CVPR, pages 21857–21867, 2025. 4
work page 2025
-
[17]
Mdetr- modulated detection for end-to-end multi-modal understand- ing
Aishwarya Kamath, Mannat Singh, Yann LeCun, Gabriel Synnaeve, Ishan Misra, and Nicolas Carion. Mdetr- modulated detection for end-to-end multi-modal understand- ing. In ICCV, pages 1780–1790, 2021. 5, 6, 7
work page 2021
-
[18]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. In ICCV, pages 4015–4026, 2023. 2
work page 2023
-
[19]
Lafferty, Andrew McCallum, and Fernando C
John D. Lafferty, Andrew McCallum, and Fernando C. N. Pereira. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the Eighteenth International Conference on Machine Learn- ing, page 282–289, San Francisco, CA, USA, 2001. Morgan Kaufmann Publishers Inc. 2
work page 2001
-
[20]
Proxyclip: Proxy at- tention improves clip for open-vocabulary segmentation
Mengcheng Lan, Chaofeng Chen, Yiping Ke, Xinjiang Wang, Litong Feng, and Wayne Zhang. Proxyclip: Proxy at- tention improves clip for open-vocabulary segmentation. In ECCV, pages 70–88. Springer, 2024. 2
work page 2024
-
[21]
Recurrent multimodal interaction for referring image segmentation
Chenxi Liu, Zhe Lin, Xiaohui Shen, Jimei Yang, Xin Lu, and Alan Yuille. Recurrent multimodal interaction for referring image segmentation. In ICCV, pages 1271–1280, 2017. 2
work page 2017
-
[22]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. In ECCV, pages 38–55. Springer, 2024. 2
work page 2024
-
[23]
Ziming Liu, Ezio Malis, and Philippe Martinet. One-stage deep stereo network. In ICASSP, pages 3050–3054. IEEE,
-
[24]
Image segmentation using text and image prompts
Timo L ¨uddecke and Alexander Ecker. Image segmentation using text and image prompts. In CVPR, pages 7086–7096,
-
[25]
1, 2, 3, 5, 6, 7, 9, 10, 11, 12, 13
-
[26]
Maxime Oquab, Timoth ´ee Darcet, Th´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Je- gou, Julien Mairal, Patr...
work page 2024
-
[27]
Know ”no” better: A data- driven approach for enhancing negation awareness in clip,
Junsung Park, Jungbeom Lee, Jongyoon Song, Sangwon Yu, Dahuin Jung, and Sungroh Yoon. Know ”no” better: A data- driven approach for enhancing negation awareness in clip,
-
[28]
Automatic dif- ferentiation in pytorch
Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic dif- ferentiation in pytorch. In NIPS 2017 Workshop on Autodiff,
work page 2017
-
[29]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. In ICML, pages 8748–8763. PmLR, 2021. 1, 2, 3, 5 16
work page 2021
-
[30]
Mobilestereonet: Towards lightweight deep net- works for stereo matching
Faranak Shamsafar, Samuel Woerz, Rafia Rahim, and An- dreas Zell. Mobilestereonet: Towards lightweight deep net- works for stereo matching. In WACV, pages 2417–2426,
-
[31]
Lposs: Label propagation over patches and pixels for open-vocabulary semantic segmentation
Vladan Stojni ´c, Yannis Kalantidis, Ji ˇr´ı Matas, and Giorgos Tolias. Lposs: Label propagation over patches and pixels for open-vocabulary semantic segmentation. InCVPR, pages 9794–9803, 2025. 1, 6
work page 2025
-
[32]
Segmenter: Transformer for semantic segmenta- tion
Robin Strudel, Ricardo Garcia, Ivan Laptev, and Cordelia Schmid. Segmenter: Transformer for semantic segmenta- tion. In ICCV, pages 7262–7272, 2021. 1
work page 2021
-
[33]
Hitnet: Hierar- chical iterative tile refinement network for real-time stereo matching
Vladimir Tankovich, Christian Hane, Yinda Zhang, Adarsh Kowdle, Sean Fanello, and Sofien Bouaziz. Hitnet: Hierar- chical iterative tile refinement network for real-time stereo matching. In CVPR, pages 14362–14372, 2021. 13
work page 2021
-
[34]
Sclip: Rethinking self-attention for dense vision-language inference
Feng Wang, Jieru Mei, and Alan Yuille. Sclip: Rethinking self-attention for dense vision-language inference. In ECCV, pages 315–332. Springer, 2024. 2, 5, 6
work page 2024
-
[35]
Declip: Decoupled learning for open- vocabulary dense perception
Junjie Wang, Bin Chen, Yulin Li, Bin Kang, Yichi Chen, and Zhuotao Tian. Declip: Decoupled learning for open- vocabulary dense perception. In CVPR, pages 14824–14834,
-
[36]
Selective-stereo: Adaptive frequency information selection for stereo matching
Xianqi Wang, Gangwei Xu, Hao Jia, and Xin Yang. Selective-stereo: Adaptive frequency information selection for stereo matching. In CVPR, pages 19701–19710, 2024. 3, 4, 5, 8, 13
work page 2024
-
[37]
Phrasecut: Language-based image segmen- tation in the wild
Chenyun Wu, Zhe Lin, Scott Cohen, Trung Bui, and Subhransu Maji. Phrasecut: Language-based image segmen- tation in the wild. In CVPR, pages 10216–10225, 2020. 2, 5, 6
work page 2020
-
[38]
Clip-dinoiser: Teaching clip a few dino tricks for open- vocabulary semantic segmentation
Monika Wysocza ´nska, Oriane Sim´eoni, Micha¨el Ramamon- jisoa, Andrei Bursuc, Tomasz Trzci ´nski, and Patrick P ´erez. Clip-dinoiser: Teaching clip a few dino tricks for open- vocabulary semantic segmentation. In ECCV, pages 320–
-
[39]
Semantic projection network for zero-and few-label semantic segmentation
Yongqin Xian, Subhabrata Choudhury, Yang He, Bernt Schiele, and Zeynep Akata. Semantic projection network for zero-and few-label semantic segmentation. In CVPR, pages 8256–8265, 2019. 2
work page 2019
-
[40]
Openworldsam: Ex- tending sam2 for universal image segmentation with lan- guage prompts
Shiting Xiao, Rishabh Kabra, Yuhang Li, Donghyun Lee, Joao Carreira, and Priyadarshini Panda. Openworldsam: Ex- tending sam2 for universal image segmentation with lan- guage prompts. In NIPS, 2025. 5, 6, 7
work page 2025
-
[41]
Cross-modal self-attention network for referring image seg- mentation
Linwei Ye, Mrigank Rochan, Zhi Liu, and Yang Wang. Cross-modal self-attention network for referring image seg- mentation. In CVPR, pages 10502–10511, 2019. 2
work page 2019
-
[42]
Prototypical matching and open set rejection for zero-shot semantic segmentation
Hui Zhang and Henghui Ding. Prototypical matching and open set rejection for zero-shot semantic segmentation. In ICCV, pages 6974–6983, 2021. 2
work page 2021
-
[43]
Vision-language models for vision tasks: A survey
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey. TPAMI, 46(8):5625–5644, 2024. 2
work page 2024
-
[44]
Extract free dense labels from clip
Chong Zhou, Chen Change Loy, and Bo Dai. Extract free dense labels from clip. In ECCV, pages 696–712. Springer,
-
[45]
Zegclip: Towards adapting clip for zero-shot se- mantic segmentation
Ziqin Zhou, Yinjie Lei, Bowen Zhang, Lingqiao Liu, and Yifan Liu. Zegclip: Towards adapting clip for zero-shot se- mantic segmentation. In CVPR, pages 11175–11185, 2023. 1, 2
work page 2023
-
[46]
Segment everything everywhere all at once
Xueyan Zou, Jianwei Yang, Hao Zhang, Feng Li, Linjie Li, Jianfeng Wang, Lijuan Wang, Jianfeng Gao, and Yong Jae Lee. Segment everything everywhere all at once. NeurIPS, 36:19769–19782, 2023. 2 17
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.