Recognition: unknown
Polynomial Multiproofs for Scalable Data Availability Sampling in Blockchain Light Clients
Pith reviewed 2026-05-10 08:17 UTC · model grok-4.3
The pith
Aggregating multiple KZG proofs into one polynomial multiproof reduces bandwidth, CPU, and infrastructure costs for blockchain light clients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Multiple point evaluations of a committed polynomial can be verified together using one polynomial multiproof built over a common micro-domain. Replacing per-cell KZG proofs with these aggregated objects lowers the total bytes transmitted, the computation needed to check correctness, and system-level expenses while still relying on the underlying polynomial commitment for data availability guarantees.
What carries the argument
Polynomial multiproof aggregation, which packs several cell evaluations into one proof object over a shared micro-domain to replace separate KZG proofs.
If this is right
- Fewer total proof bytes are sent across the network per sampling round.
- Verifier devices use less CPU time and memory during each check.
- Deployment infrastructure costs drop by as much as 45 percent relative to independent proofs.
- Retrieval must shift to grouped cells, creating measurable flexibility trade-offs.
- Proof generation, dissemination, and verification workflows require corresponding adjustments.
Where Pith is reading between the lines
- The same aggregation pattern could support higher sampling densities without a matching rise in client resource demands.
- Varying the micro-domain size offers a tunable knob for balancing efficiency against network conditions.
- Light clients on constrained hardware such as mobile devices could become more viable participants.
- The technique may combine with other sampling or commitment methods to produce further cumulative gains.
Load-bearing premise
Aggregating individual KZG proofs into a multiproof keeps the original security guarantees intact without introducing fresh attack surfaces.
What would settle it
A real-world deployment or security analysis that shows either higher total costs than the per-cell baseline or a break that affects only the aggregated form would falsify the claimed benefit.
Figures






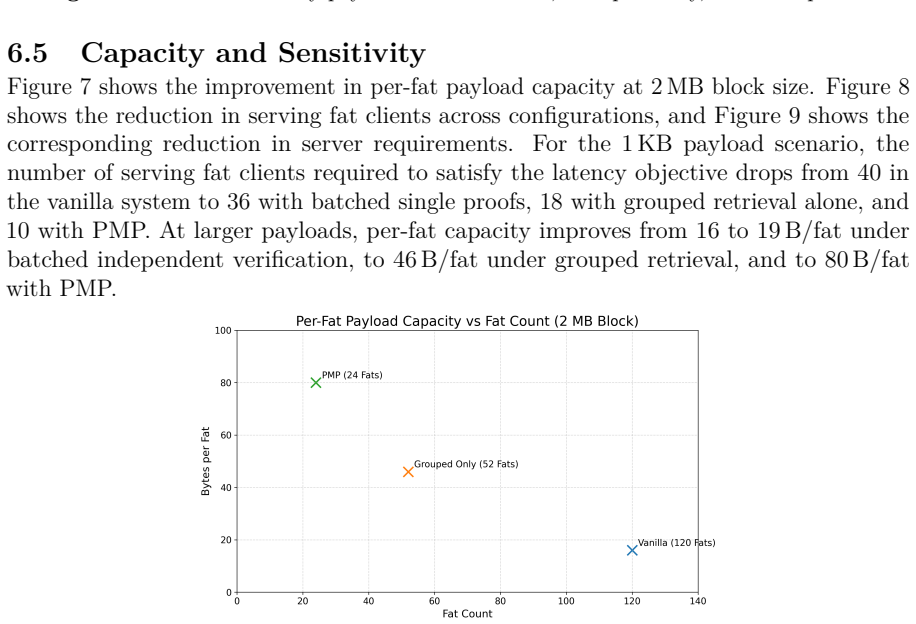
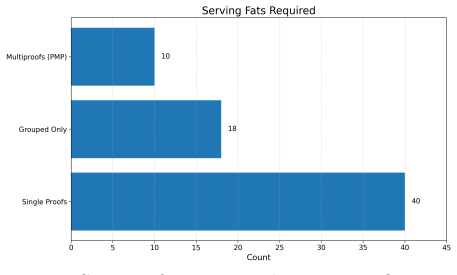

read the original abstract
Light clients are essential for scalable blockchain systems because they verify data availability without downloading full blocks. In data availability sampling based systems, sampled cells are retrieved from a peer-to-peer network and verified against cryptographic commitments. A common deployment pattern associates each sampled cell with an independent Kate-Zaverucha-Goldberg (KZG) proof, creating substantial cumulative bandwidth, storage, and verification overhead. This paper studies polynomial multiproofs (PMP) as a mechanism for reducing these costs in blockchain light clients. We present a design in which multiple sampled cell evaluations are verified using a single aggregated proof over a shared evaluation micro-domain and describe the corresponding changes to proof generation, dissemination, retrieval, and verification in a peer-to-peer light-client stack. We instantiate and evaluate the design in Avail, a modular data availability layer for blockchains, as a case study. The results show lower proof bytes, lower verifier CPU and memory usage, and deployment-level infrastructure cost reductions of up to 45% relative to a per-cell baseline, while also clarifying the trade-offs introduced by grouped retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes polynomial multiproofs (PMP) to aggregate multiple KZG proofs for sampled cells in data availability sampling for blockchain light clients. It describes modifications to proof generation, dissemination, retrieval, and verification using a single aggregated proof over a shared evaluation micro-domain, and evaluates the design via a case study in the Avail modular data availability layer. The evaluation reports lower proof sizes, reduced verifier CPU and memory usage, and infrastructure cost reductions of up to 45% relative to a per-cell baseline, while noting trade-offs from grouped retrieval.
Significance. If the security properties hold, the work provides a concrete efficiency improvement for light-client scalability in blockchain systems. The Avail deployment results offer measurable evidence of bandwidth, storage, and cost savings that could inform practical P2P data availability designs, and the explicit discussion of grouped-retrieval trade-offs strengthens the contribution.
major comments (1)
- [§3 (PMP Design and Aggregation)] §3 (PMP Design and Aggregation): The manuscript provides no explicit security reduction establishing that soundness of the aggregated multiproof over the shared micro-domain is equivalent to the soundness of the original individual KZG proofs. There is no argument showing that a successful forgery of the aggregated proof implies either a violation of the underlying pairing assumption or an incorrect evaluation at one of the sampled points. This is load-bearing for the central claims, because the reported 45% infrastructure savings and lower proof bytes are only meaningful if the new retrieval pattern preserves the original extractability and soundness guarantees.
minor comments (2)
- [Abstract and §5 (Evaluation)] Abstract and §5 (Evaluation): The concrete performance numbers (lower bytes, CPU, memory, and 45% cost reduction) are stated without accompanying details on baseline implementation, error bars, data exclusion criteria, or sensitivity to P2P network conditions; adding these would strengthen verifiability of the empirical results.
- [§2 (Background)] Notation: The term 'micro-domain' is introduced without a formal definition or comparison to the standard KZG evaluation domain; a short clarifying paragraph or equation would improve readability.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the paper's significance and for identifying the need for a more explicit security argument. We address the single major comment below and will revise the manuscript to incorporate a formal security reduction in §3.
read point-by-point responses
-
Referee: The manuscript provides no explicit security reduction establishing that soundness of the aggregated multiproof over the shared micro-domain is equivalent to the soundness of the original individual KZG proofs. There is no argument showing that a successful forgery of the aggregated proof implies either a violation of the underlying pairing assumption or an incorrect evaluation at one of the sampled points. This is load-bearing for the central claims, because the reported 45% infrastructure savings and lower proof bytes are only meaningful if the new retrieval pattern preserves the original extractability and soundness guarantees.
Authors: We agree that an explicit security reduction is required to rigorously support the soundness claims. In the revised version we will insert a dedicated subsection in §3 that provides a formal reduction: any adversary that forges a valid aggregated multiproof over the shared micro-domain can be used to either break the underlying KZG pairing assumption or to produce an incorrect evaluation at one of the sampled points. The argument relies on the linearity of polynomial evaluation and the standard extractability property of KZG commitments; it shows that the aggregation step does not weaken the original per-cell soundness. This addition will directly address the load-bearing concern and justify the reported efficiency gains. revision: yes
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption KZG polynomial commitments admit efficient multiproofs for multiple evaluation points within a shared domain.
Reference graph
Works this paper leans on
-
[1]
Mustafa Al-Bassam, Alberto Sonnino, and Vitalik Buterin. Fraud and Data Availability Proofs: Maximising Light Client Security and Scaling Blockchains with Dishonest Majorities.arXiv preprint arXiv:1809.09044, 2018
-
[2]
Mustafa Al-Bassam. LazyLedger: A Distributed Data Availability Ledger With Client-Side Smart Contracts.arXiv preprint arXiv:1905.09274, 2019
-
[3]
Foundations of Data Availability Sampling.IACR Cryptology ePrint Archive, Paper 2023/1079, 2023
Mathias Hall-Andersen, Mark Simkin, and Benedikt Wagner. Foundations of Data Availability Sampling.IACR Cryptology ePrint Archive, Paper 2023/1079, 2023
2023
-
[4]
Michał Król, Onur Ascigil, Sergi Rene, Etienne Rivière, Matthieu Pigaglio, Kaleem Peeroo, Vladimir Stankovic, Ramin Sadre, and Felix Lange. Data Availability Sampling in Ethereum: Analysis of P2P Networking Requirements.arXiv preprint arXiv:2306.11456, 2023
-
[5]
Zaverucha, and Ian Goldberg
Aniket Kate, Gregory M. Zaverucha, and Ian Goldberg. Constant-Size Commitments to Polynomials and Their Applications. InAdvances in Cryptology – ASIACRYPT 2010, pages 177–194. Springer, 2010. 12
2010
-
[6]
Efficient Polynomial Commitment Schemes for Multiple Points and Polynomials.IACR Cryptology ePrint Archive, Report 2020/081, 2020
Dan Boneh, Justin Drake, Ben Fisch, and Ariel Gabizon. Efficient Polynomial Commitment Schemes for Multiple Points and Polynomials.IACR Cryptology ePrint Archive, Report 2020/081, 2020
2020
-
[7]
Kademlia: A Peer-to-Peer Information System Based on the XOR Metric
Petar Maymounkov and David Mazieres. Kademlia: A Peer-to-Peer Information System Based on the XOR Metric. InProceedings of IPTPS, pages 53–65. Springer, 2002
2002
-
[8]
Matthieu Pigaglio, Onur Ascigil, Michał Król, Sergi Rene, Felix Lange, Kaleem Peeroo, Ramin Sadre, Vladimir Stankovic, and Etienne Rivière. PANDAS: Peer-to-peer, Adaptive Networking for Data Availability Sampling within Ethereum Consensus Timebounds.arXiv preprint arXiv:2507.00824, 2025
-
[9]
Investigating the Decentralization of IPFS
Lennart Balduf, Daniel Trautwein, Christopher Stransky, Florian Tschorsch, and Tobias Mueller. Investigating the Decentralization of IPFS. InProceedings of the 2023 ACM on Internet Measurement Conference, pages 599–612, 2023
2023
-
[10]
Avail Light Client
Avail Project. Avail Light Client. GitHub repository. https://github.com/availproject/avail-light
-
[11]
Multiproof integration for Avail light client
Avail Project. Multiproof integration for Avail light client. GitHub pull request #778, commit 4b1718960bfc956a937de34fe3f609c7dbfee439. https://github.com/availproject/avail-light/pull/778. 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.