CBRS: Cognitive Blood Request System with Bilingual Dataset and Dual-Layer Filtering for Multi-Platform Social Streams
Pith reviewed 2026-05-10 08:07 UTC · model grok-4.3
The pith
A dual-layer system with a fine-tuned Llama model filters blood donation requests from social media at 99 percent accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
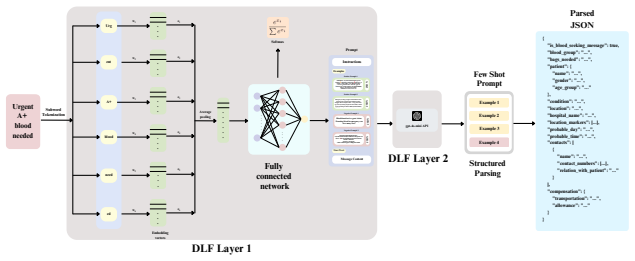
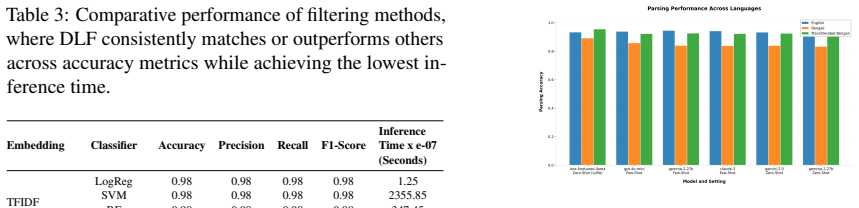
CBRS achieves an impressive 99% accuracy and precision in filtering, surpassing benchmark methods. In the parsing task, our LoRA finetuned Llama-3.2-3B model achieves 92% zero-shot accuracy, surpassing the base model by 41.54% and exceeding the few-shot performance of GPT-4o-mini, Gemini-2.0-Flash, and other LLMs, while resulting in a 35X reduction in input token usage. This work lays a robust foundation for scalable, inclusive information extraction in time-sensitive, object-focused tasks.
What carries the argument
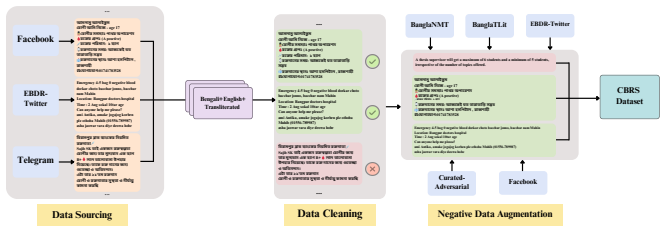
Dual-layer filtering architecture with a LoRA-finetuned Llama-3.2-3B model for bilingual blood request parsing on an 11K dataset with adversarial negatives.
If this is right
- The system enables timely alerts for blood donation needs across multiple social platforms.
- It reduces computational costs through lower token consumption compared to larger models.
- The approach supports linguistic diversity including transliterated text common in social media.
- High precision helps minimize false alerts in noisy online environments.
- The open dataset supports further development of similar extraction systems.
Where Pith is reading between the lines
- This method could extend to extracting other time-critical signals such as disaster aid requests from social media.
- Public release of the dataset and models allows community adaptation to new languages or additional platforms.
- Linking the filter output directly to blood bank systems might speed up matching donors to specific needs.
Load-bearing premise
The curated 11K dataset with adversarial negatives is representative of real multi-platform social streams and that the dual-layer system plus fine-tuned model will maintain high accuracy and low false positives when deployed live without further retraining or platform-specific adjustments.
What would settle it
Running the deployed system on live social media streams for several weeks and measuring the actual false positive rate plus missed urgent requests through manual comparison.
Figures






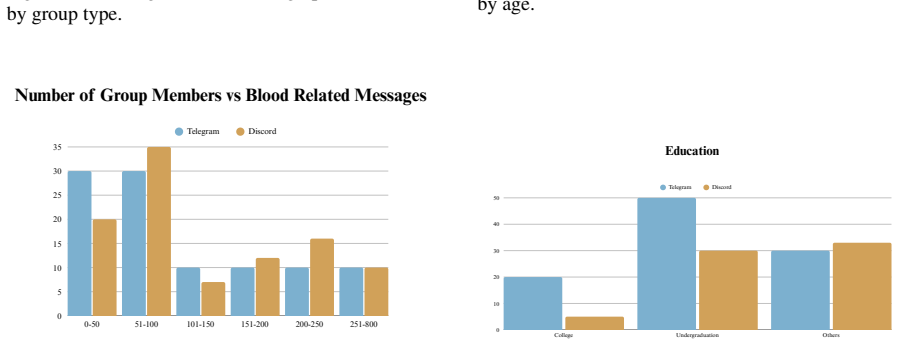
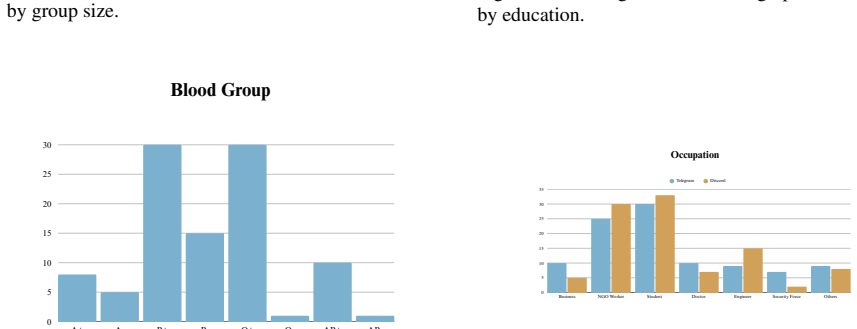
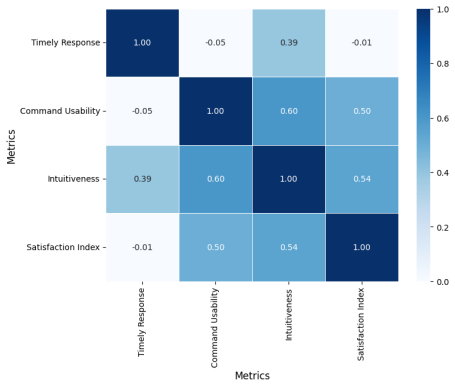
read the original abstract
Urgent blood donation seeking posts and messages on social media often go unnoticed due to the overwhelming volume of daily communications. Traditional app-based systems, reliant on manual input, struggle to reach users in low-resource settings, delaying critical responses. To address this, we introduce the Cognitive Blood Request System (CBRS), a multi-platform framework that efficiently filters and parses blood donation requests from social media streams using a cost-efficient dual-layered architecture. To do so, we curate a novel dataset of 11K parsed blood donation request messages in Bengali, English, and transliterated Bengali, capturing the linguistic diversity of real social media communications. The inclusion of adversarial negatives further enhances the robustness of our model. CBRS achieves an impressive 99% accuracy and precision in filtering, surpassing benchmark methods. In the parsing task, our LoRA finetuned Llama-3.2-3B model achieves 92% zero-shot accuracy, surpassing the base model by 41.54% and exceeding the few-shot performance of GPT-4o-mini, Gemini-2.0-Flash, and other LLMs, while resulting in a 35X reduction in input token usage. This work lays a robust foundation for scalable, inclusive information extraction in time-sensitive, object-focused tasks. Our code, dataset, and trained models are publicly available at [https://github.com/aaniksahaa/CBRS](https://github.com/aaniksahaa/CBRS).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CBRS, a dual-layer filtering system for extracting blood donation requests from multi-platform social media streams (Bengali, English, transliterated Bengali). It curates an 11K dataset with adversarial negatives, applies a cost-efficient architecture, and fine-tunes Llama-3.2-3B via LoRA for parsing. The abstract claims 99% accuracy/precision on filtering (surpassing benchmarks) and 92% zero-shot parsing accuracy (41.54% lift over base model, exceeding few-shot GPT-4o-mini/Gemini-2.0-Flash while cutting tokens 35X), with public release of code, data, and models.
Significance. If the performance holds under real distributions, the work could enable faster, scalable donor matching in low-resource settings where social media is primary, advancing humanitarian NLP applications. The public dataset and models are a clear strength for reproducibility in bilingual social-stream extraction.
major comments (3)
- [Abstract] Abstract: The 99% filtering accuracy/precision and 92% parsing accuracy are reported without any evaluation protocol, train/test splits, platform/language stratification, adversarial-negative sampling procedure, or error analysis. This is load-bearing for the central empirical claims, as the reader's report notes the absence of these details prevents assessing whether metrics reflect generalization or optimistic conditions on the curated set.
- [Abstract] Abstract: The claim that the LoRA-tuned Llama-3.2-3B exceeds few-shot GPT-4o-mini, Gemini-2.0-Flash, and other LLMs by 41.54% (with 35X token reduction) lacks specification of the few-shot prompt format, example count, exact test-set construction, or whether the fine-tuned model was evaluated in a true zero-shot held-out regime. Without this, the comparative superiority cannot be verified.
- [Abstract and Methods] Abstract and Methods: No cross-platform hold-out results, temporal splits, or live-stream deployment evaluation are described to support the claim that the dual-layer system plus fine-tuned model will maintain accuracy on real multi-platform streams without platform-specific retraining. The skeptic note correctly identifies this as the unsupported link between metrics and deployment utility.
minor comments (1)
- [Abstract] Abstract: The dual-layer architecture is described only at high level; a brief enumeration of the two layers (e.g., rule-based then model-based) would improve immediate clarity even before full methods.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, providing clarifications from the manuscript where available and indicating revisions made to improve transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: The 99% filtering accuracy/precision and 92% parsing accuracy are reported without any evaluation protocol, train/test splits, platform/language stratification, adversarial-negative sampling procedure, or error analysis. This is load-bearing for the central empirical claims, as the reader's report notes the absence of these details prevents assessing whether metrics reflect generalization or optimistic conditions on the curated set.
Authors: We agree the abstract is too concise to stand alone on these points. The full manuscript details the evaluation protocol in Section 3 (including 80/20 stratified train/test splits by language and platform, 5-fold cross-validation for filtering, adversarial-negative sampling procedure in 3.3, and error analysis in Section 5). To make this accessible without requiring the full text, we have expanded the abstract to briefly reference the stratified splits, cross-validation, and adversarial sampling. revision: yes
-
Referee: [Abstract] Abstract: The claim that the LoRA-tuned Llama-3.2-3B exceeds few-shot GPT-4o-mini, Gemini-2.0-Flash, and other LLMs by 41.54% (with 35X token reduction) lacks specification of the few-shot prompt format, example count, exact test-set construction, or whether the fine-tuned model was evaluated in a true zero-shot held-out regime. Without this, the comparative superiority cannot be verified.
Authors: The manuscript specifies 5-shot prompting with the exact template in Appendix A, the held-out 20% test set (stratified, never seen during fine-tuning), and true zero-shot inference for the LoRA-tuned model on that set. Token counts were measured directly on the same inputs. We have added a clarifying clause to the abstract and a short methods paragraph to make the comparison protocol explicit. revision: yes
-
Referee: [Abstract and Methods] Abstract and Methods: No cross-platform hold-out results, temporal splits, or live-stream deployment evaluation are described to support the claim that the dual-layer system plus fine-tuned model will maintain accuracy on real multi-platform streams without platform-specific retraining. The skeptic note correctly identifies this as the unsupported link between metrics and deployment utility.
Authors: The current splits are stratified across platforms but do not include explicit cross-platform hold-out (train on one platform, test on another) or temporal splits; no live-stream deployment was performed. We acknowledge this weakens the direct claim of robustness without retraining and have added an explicit Limitations paragraph stating the stratified nature of the existing evaluation while noting the absence of cross-platform and deployment tests. Future work will address these. revision: partial
Circularity Check
No circularity: empirical results on held-out data with no derivations or load-bearing self-citations
full rationale
The paper curates an 11K bilingual dataset, applies dual-layer filtering, and fine-tunes a LoRA-adapted Llama-3.2-3B model, then reports standard classification and parsing accuracies (99% filtering, 92% zero-shot parsing) on held-out test portions. No equations, parameter-fitting steps presented as predictions, or self-citation chains appear in the provided text. Claims rest on empirical evaluation against external baselines (GPT-4o-mini, Gemini, etc.) rather than reducing to inputs by construction. This is a typical applied ML paper whose central results are falsifiable on new data and therefore score at the low end of the scale.
Axiom & Free-Parameter Ledger
free parameters (2)
- Dual-layer decision thresholds
- LoRA hyperparameters
axioms (2)
- domain assumption The distribution of real social-media blood requests matches the curated 11K dataset including adversarial negatives
- standard math Standard supervised fine-tuning assumptions (i.i.d. samples, stable optimization) hold for the LoRA-adapted Llama model
Reference graph
Works this paper leans on
-
[1]
InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 14656–14672
Banglatlit: A benchmark dataset for back- transliteration of romanized bangla. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 14656–14672. Fangxiaoyu Feng, Yinfei Yang, Daniel Cer, Naveen Ari- vazhagan, and Wei Wang. 2022. Language-agnostic BERT sentence embedding. InProceedings of the 60th Annual Meeting of the Association...
-
[2]
Do you request blood donations on social me- dia (e.g., Telegram, Discord, etc.)? (Almost always, Often, Sometimes, Seldom, Never)
-
[3]
Did you usually receive timely responses to your blood donation requests before using BNet prior to October 23, 2024? (Almost always, Often, Sometimes, Seldom, Never)
work page 2024
-
[4]
How satisfied are you with the timely response of BNet in identifying potential donors be- tween October 23 and October 26, 2024, after integrating BNet into groups? (Very satisfied, Satisfied, Neither, Dissatisfied, Very dissatisfied)
work page 2024
-
[5]
After getting a response from BNet, have you successfully connected with a blood donor through BNet? (Almost always, Often, Sometimes, Seldom, Never)
-
[6]
How easy do you find using BNet through slash command prompts? (Extremely easy, Very easy, Moderately easy, Slightly easy, Not at all)
-
[7]
How intuitive is the user interface of BNet? (Extremely intuitive, Very intuitive, Moder- ately intuitive, Slightly intuitive, Not at all)
-
[9]
At most how many blood donation seeking messages do you feel comfortable to receive from BNet per month? (1-5, 6-10, 11-15, 16-20, 21+)
-
[10]
Do you find BNet more effective than exist- ing blood donation apps or methods you have used before? (Much better, Somewhat better, Stayed the same, Somewhat worse, Much worse, Not applicable- I have never used any app before)
-
[11]
What challenges do you face in connecting with blood donors? How can these be over- come? (Open-ended response)
-
[12]
What improvements would you suggest to make BNet better for requesters? (Open-ended response) For Donors:
-
[13]
How many times have you donated blood in the past year? (Never, 1 time, 2 times, 3 times, 4 or more)
-
[14]
Do you have trouble finding blood donation requests among a large volume of messages in social media groups? (Almost always, Often, Sometimes, Seldom, Never)
-
[15]
How convenient is BNet in notifying you about blood donation requests in social media groups? (Extremely convenient, Very convenient, Mod- erately convenient, Slightly convenient, Not at all)
-
[16]
How would you rate the overall functionality of BNet? (Excellent, Above Average, Average, Below Average, Very Poor)
-
[17]
Do you find BNet more effective than existing blood donation apps or methods you’ve used before? (Much better, Somewhat better, Stayed the same, Somewhat worse, Much worse, Not applicable)
-
[18]
What challenges do you face in connecting with blood requesters? How can these be over- come? (Open-ended response)
-
[19]
What improvements would you suggest to make BNet better for donors? (Open-ended response) E Data Analysis To address existing gap of existing BDSs, we ask the following research questions in this work: • RQ1:How can a multi-platform bot be de- signed to seamlessly integrate with OSNs to accelerate donor response and broaden the donor network? • RQ2:How ca...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.