Channel Attention-Guided Cross-Modal Knowledge Distillation for Referring Image Segmentation
Pith reviewed 2026-05-10 07:21 UTC · model grok-4.3
The pith
A channel attention-guided distillation method transfers high-order vision-language correlations from teacher to student networks for referring image segmentation while preserving some independent learning in the student.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
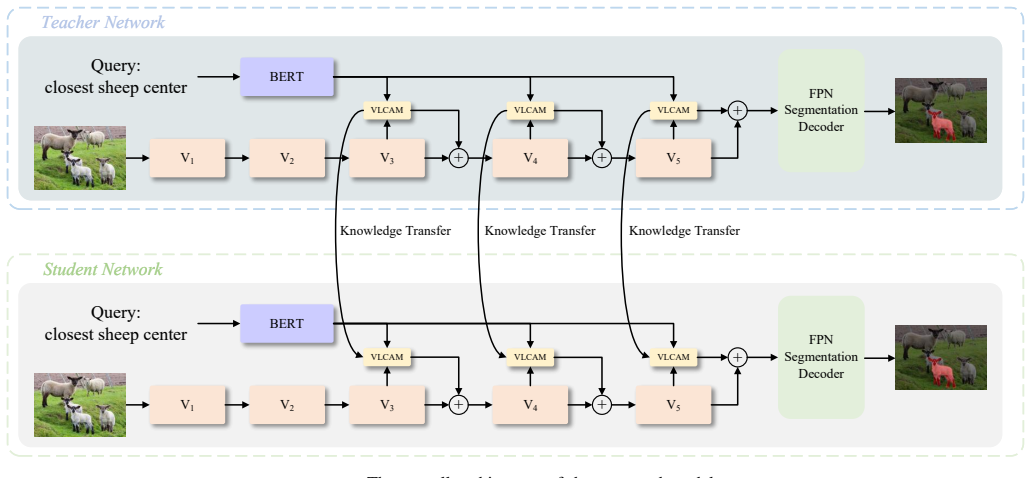
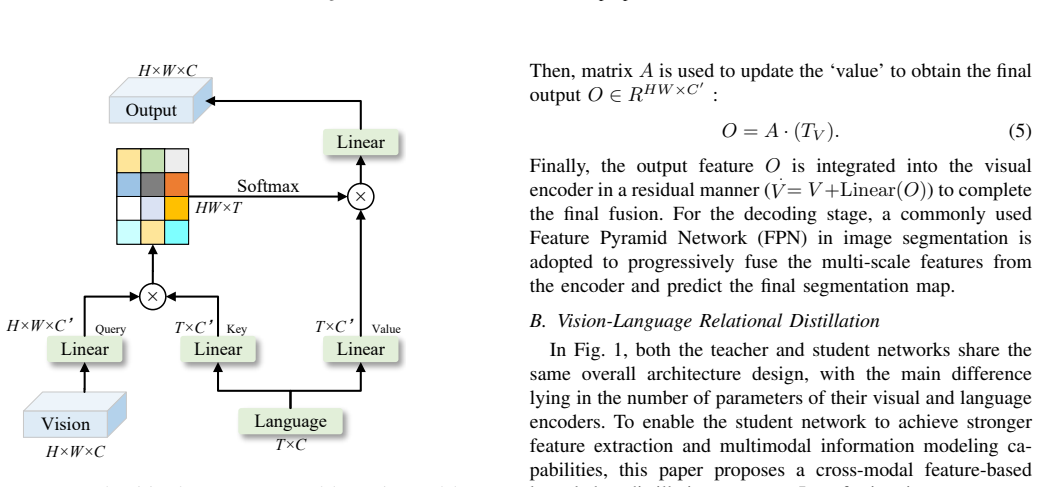
The paper establishes a channel attention-guided cross-modal knowledge distillation method that transfers the high-order fine-grained correlations between vision and language learned by the teacher network, as well as the correlations between semantic components represented by each channel, to the student network. This enables the student to learn from the teacher while retaining part of its independent learning ability, which alleviates the transfer of learning bias compared to traditional pixel-wise relational distillation. Experiments confirm the approach yields performance gains on referring image segmentation without introducing additional parameters during inference.
What carries the argument
Channel attention-guided cross-modal knowledge distillation that transfers high-order vision-language correlations and channel-wise semantic component correlations from teacher to student.
If this is right
- The student model achieves significant performance improvement on referring image segmentation tasks.
- No additional parameters are introduced to the student during inference.
- The student retains part of its independent learning ability, reducing the transfer of learning bias.
- High-order fine-grained vision-language correlations and channel-wise semantic correlations are transferred effectively.
Where Pith is reading between the lines
- This distillation could enable deployment of advanced language-guided segmentation on edge devices with tight compute budgets.
- The channel attention guidance might extend to other multimodal tasks where preserving model independence improves robustness.
- Combining this transfer with standard pixel-level losses could produce even stronger student models without extra inference cost.
Load-bearing premise
The high-order fine-grained correlations between vision and language from the teacher, together with channel-wise semantic component correlations, can be transferred to improve the student while preserving its independent learning ability.
What would settle it
Training the same student model on the public datasets both with and without the proposed distillation and checking whether segmentation metrics improve substantially while inference parameter count stays unchanged.
Figures
read the original abstract
Referring image segmentation (RIS) requires accurate segmentation of target regions in images according to language descriptions, which is a cross-modal task integrating vision and language. Existing RIS methods typically employ large-scale vision and language encoding models to improve performance, but their enormous parameter size severely restricts deployment in scenarios with limited computing resources. To solve this problem, this paper proposes a channel attention-guided cross-modal knowledge distillation method, which transfers the high-order fine-grained correlations between vision and language learned by the teacher network, as well as the correlations between semantic components represented by each channel, to the student network. Compared with the traditional pixel-wise relational distillation, this method not only enables the student to learn the knowledge of the teacher, but also retains part of its independent learning ability, alleviating the transfer of learning bias. Experimental results on two public datasets show that the proposed distillation method does not introduce additional parameters during inference and can achieve significant performance improvement for the student model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a channel attention-guided cross-modal knowledge distillation method for referring image segmentation. This method transfers high-order fine-grained vision-language correlations and channel-wise semantic component correlations from a teacher network to a student network. The distillation occurs only during training, adding no parameters at inference time. It is asserted that this allows the student to learn teacher knowledge while retaining independent learning ability, reducing bias transfer. Experiments on two public datasets reportedly show significant performance improvements for the student model.
Significance. Should the claims be substantiated, the significance lies in enabling more efficient deployment of referring image segmentation models in resource-limited settings. The channel attention guidance for transferring cross-modal knowledge represents a potentially effective way to perform knowledge distillation in multimodal tasks, going beyond standard pixel-wise approaches. This could impact practical applications where large vision-language models are currently prohibitive due to their size.
major comments (1)
- [Abstract] The central claim of achieving 'significant performance improvement' is stated without any supporting quantitative evidence, such as specific mIoU values, comparisons to baselines, or ablation studies. This issue is load-bearing as the paper's contribution hinges on demonstrating the effectiveness of the proposed distillation technique.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and the opportunity to improve our manuscript. We address the major comment below and will revise the abstract accordingly to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] The central claim of achieving 'significant performance improvement' is stated without any supporting quantitative evidence, such as specific mIoU values, comparisons to baselines, or ablation studies. This issue is load-bearing as the paper's contribution hinges on demonstrating the effectiveness of the proposed distillation technique.
Authors: We agree that the abstract would be strengthened by including concrete quantitative evidence for the claimed performance gains. In the revised version, we will update the abstract to report specific mIoU improvements achieved by the student model on the two public datasets, including direct comparisons against the baseline student model without distillation and against the teacher model. The full experimental results, including all baseline comparisons and ablation studies, are already detailed in Section 4 of the manuscript; the abstract revision will simply highlight the key quantitative outcomes to make the central claim self-contained. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper proposes a channel attention-guided cross-modal knowledge distillation method for referring image segmentation, claiming transfer of high-order vision-language correlations and channel-wise semantic correlations from teacher to student during training only, with no added inference parameters and retained student independence. This chain is self-contained: the performance improvements are reported from experiments on two public datasets rather than derived by construction from the method's own definitions, parameters, or self-citations. No equations reduce claims to fitted inputs, no uniqueness theorems or ansatzes are smuggled via self-citation, and the approach is presented as an independent technique with external empirical validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Teacher networks learn transferable high-order fine-grained vision-language correlations and channel-wise semantic representations that benefit the student
Reference graph
Works this paper leans on
-
[1]
Segmentation from natural language expressions,
R. Hu, M. Rohrbach, and T. Darrell, “Segmentation from natural language expressions,” inEuropean conference on computer vision. Springer, 2016, pp. 108–124
work page 2016
-
[2]
Key-word-aware network for refer- ring expression image segmentation,
H. Shi, H. Li, F. Meng, and Q. Wu, “Key-word-aware network for refer- ring expression image segmentation,” inProceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 38–54
work page 2018
-
[3]
Dy- namic multimodal instance segmentation guided by natural language queries,
E. Margffoy-Tuay, J. C. P ´erez, E. Botero, and P. Arbel ´aez, “Dy- namic multimodal instance segmentation guided by natural language queries,” inProceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 630–645
work page 2018
-
[4]
S. Cheng, Y . Liu, X. He, S. Ourselin, L. Tan, and G. Luo, “Weakmcn: Multi-task collaborative network for weakly supervised referring expres- sion comprehension and segmentation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 9175–9185
work page 2025
-
[5]
Referring image segmentation using text supervision,
F. Liu, Y . Liu, Y . Kong, K. Xu, L. Zhang, B. Yin, G. Hancke, and R. Lau, “Referring image segmentation using text supervision,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 22 124–22 134
work page 2023
-
[6]
Y . Wang, J. Ni, Y . Liu, C. Yuan, and Y . Tang, “Iterprime: Zero-shot referring image segmentation with iterative grad-cam refinement and primary word emphasis,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 8, 2025, pp. 8159–8168
work page 2025
-
[7]
Lisa: Reasoning segmentation via large language model,
X. Lai, Z. Tian, Y . Chen, Y . Li, Y . Yuan, S. Liu, and J. Jia, “Lisa: Reasoning segmentation via large language model,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 9579–9589
work page 2024
-
[8]
Prompt-driven referring image segmentation with instance contrasting,
C. Shang, Z. Song, H. Qiu, L. Wang, F. Meng, and H. Li, “Prompt-driven referring image segmentation with instance contrasting,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2024, pp. 4124–4134
work page 2024
-
[9]
Cross-modal self-attention network for referring image segmentation,
L. Ye, M. Rochan, Z. Liu, and Y . Wang, “Cross-modal self-attention network for referring image segmentation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 10 502–10 511
work page 2019
-
[10]
Cris: Clip-driven referring image segmentation,
Z. Wang, Y . Lu, Q. Li, X. Tao, Y . Guo, M. Gong, and T. Liu, “Cris: Clip-driven referring image segmentation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11 686–11 695
work page 2022
-
[11]
Lavt: Language-aware vision transformer for referring image segmentation,
Z. Yang, J. Wang, Y . Tang, K. Chen, H. Zhao, and P. H. Torr, “Lavt: Language-aware vision transformer for referring image segmentation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 18 155–18 165
work page 2022
-
[12]
Caris: Context-aware referring image segmentation,
S.-A. Liu, Y . Zhang, Z. Qiu, H. Xie, Y . Zhang, and T. Yao, “Caris: Context-aware referring image segmentation,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 779–788
work page 2023
-
[13]
Bridging vision and language encoders: Parameter-efficient tuning for referring image segmentation,
Z. Xu, Z. Chen, Y . Zhang, Y . Song, X. Wan, and G. Li, “Bridging vision and language encoders: Parameter-efficient tuning for referring image segmentation,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 17 503–17 512
work page 2023
-
[14]
Densely connected parameter-efficient tuning for referring image segmentation,
J. Huang, Z. Xu, T. Liu, Y . Liu, H. Han, K. Yuan, and X. Li, “Densely connected parameter-efficient tuning for referring image segmentation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 4, 2025, pp. 3653–3661
work page 2025
-
[15]
Modeling context in referring expressions,
L. Yu, P. Poirson, S. Yang, A. C. Berg, and T. L. Berg, “Modeling context in referring expressions,” inEuropean conference on computer vision. Springer, 2016, pp. 69–85
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.