Recognition: unknown
Modeling Biomechanical Constraint Violations for Language-Agnostic Lip-Sync Deepfake Detection
Pith reviewed 2026-05-10 07:16 UTC · model grok-4.3
The pith
Deepfake lip-sync videos exhibit elevated temporal lip jitter because generators ignore biomechanical movement constraints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
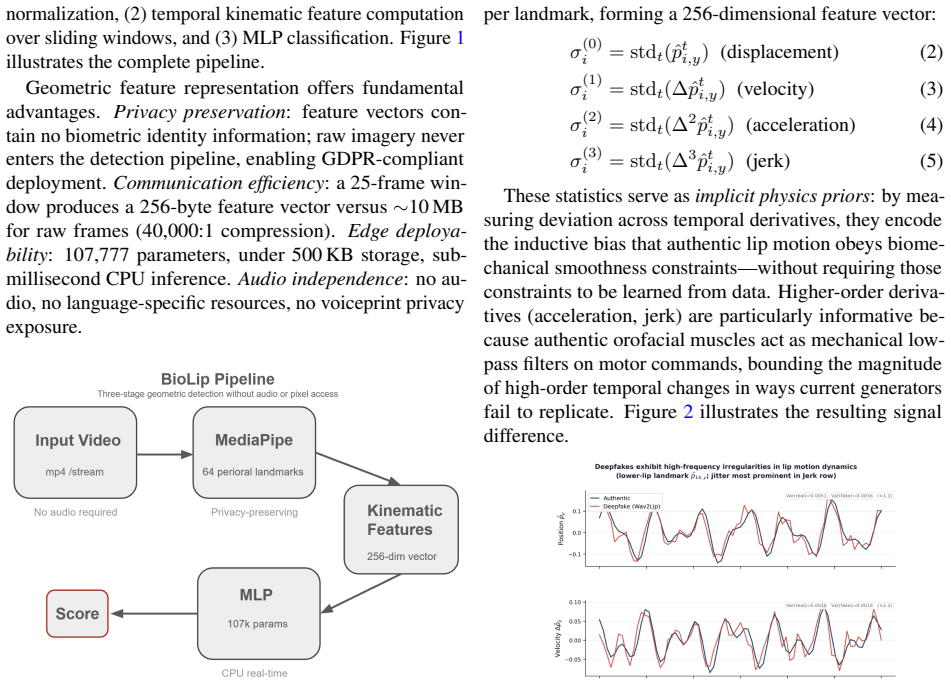
The central discovery is that generative models do not enforce the biomechanical constraints of authentic orofacial articulation, which leads to measurably elevated temporal lip variance, a phenomenon termed temporal lip jitter. This jitter signal remains empirically consistent across the speaker's language, ethnicity, and recording conditions. The paper instantiates this through BioLip, a lightweight framework operating on 64 perioral landmark coordinates extracted by MediaPipe.
What carries the argument
The BioLip framework, which measures temporal lip jitter using 64 perioral landmark coordinates to detect violations of biomechanical constraints in lip movements.
If this is right
- Language-agnostic detection becomes possible without retraining on specific languages.
- Detectors can rely on physical laws of articulation rather than pixel-level or audio-visual artifacts.
- Simple landmark-based analysis suffices for effective identification of lip-sync fakes.
- Consistency of the signal across diverse conditions broadens applicability to real-world videos.
Where Pith is reading between the lines
- Applying similar biomechanical checks to other facial regions could enhance detection of broader deepfake manipulations.
- Future generators might need to incorporate explicit physical constraints to evade this type of detection.
- Integration with existing deepfake detectors could improve overall robustness by adding a universal physical prior.
Load-bearing premise
The observed increase in temporal lip variance stems directly from generative models violating biomechanical constraints rather than resulting from inaccuracies in landmark extraction or other video processing factors.
What would settle it
Demonstrating that deepfake videos generated with explicit biomechanical constraints applied during synthesis show temporal lip variance levels matching those of authentic videos would falsify the central claim.
Figures

read the original abstract
Current lip-sync deepfake detectors rely on pixel-level artifacts or audio-visual correspondence, failing to generalize across languages because these cues encode data-dependent patterns rather than universal physical laws. We identify a more fundamental principle: generative models do not enforce the biomechanical constraints of authentic orofacial articulation, producing measurably elevated temporal lip variance -- a signal we term temporal lip jitter -- that is empirically consistent across the speaker's language, ethnicity, and recording conditions. We instantiate this principle through BioLip, a lightweight framework operating on 64 perioral landmark coordinates extracted by MediaPipe.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that lip-sync deepfakes can be detected in a language-agnostic way by exploiting the fact that generative models fail to enforce biomechanical constraints of authentic orofacial articulation. This failure produces elevated temporal variance in lip landmarks (termed 'temporal lip jitter') that is consistent across speaker language, ethnicity, and recording conditions. The approach is instantiated in the lightweight BioLip framework, which operates on 64 perioral landmark coordinates extracted by MediaPipe.
Significance. If the central empirical claim is substantiated, the work would offer a principled, physics-based alternative to existing deepfake detectors that rely on data-dependent pixel artifacts or audio-visual mismatches. Such a signal could improve generalization across languages and conditions, representing a meaningful shift toward universal physical constraints rather than learned patterns.
major comments (2)
- [Abstract] Abstract: the claim that generative models produce 'measurably elevated temporal lip variance' due to biomechanical constraint violations supplies no quantitative definition of the jitter metric, no derivation, no experimental results, baselines, or error analysis, rendering the data support for the claim unevaluable.
- [Abstract] Abstract: the central assumption that observed elevation in temporal variance of the 64 perioral MediaPipe coordinates is caused by biomechanical violations (rather than landmark instability from synthesis artifacts such as blending boundaries, texture mismatches, or temporal flicker) is not addressed; no controls using an independent detector or deliberate degradation of real videos are described.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below, clarifying the content of the full paper while committing to revisions that improve the abstract and strengthen the empirical controls.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that generative models produce 'measurably elevated temporal lip variance' due to biomechanical constraint violations supplies no quantitative definition of the jitter metric, no derivation, no experimental results, baselines, or error analysis, rendering the data support for the claim unevaluable.
Authors: The abstract provides a concise overview of the central claim. The full manuscript defines the temporal lip jitter metric quantitatively in Section 3.1 as the frame-to-frame variance of the 64 perioral landmark coordinates extracted by MediaPipe, with explicit formulas for temporal aggregation. The biomechanical motivation and derivation appear in Section 2, while Section 4 reports the experimental results, including direct comparisons against multiple baselines and associated error analysis across datasets. To address the concern about evaluability from the abstract alone, we will revise the abstract to incorporate a brief quantitative definition of the jitter metric along with a reference to the key empirical consistency findings. revision: yes
-
Referee: [Abstract] Abstract: the central assumption that observed elevation in temporal variance of the 64 perioral MediaPipe coordinates is caused by biomechanical violations (rather than landmark instability from synthesis artifacts such as blending boundaries, texture mismatches, or temporal flicker) is not addressed; no controls using an independent detector or deliberate degradation of real videos are described.
Authors: The manuscript supports the biomechanical interpretation through experiments in Section 4.2 and 4.3 demonstrating that the elevated temporal variance remains consistent across languages, ethnicities, and recording conditions, which would be unlikely if driven primarily by synthesis-specific artifacts. Nevertheless, we agree that explicit controls are needed to isolate the source. In the revised manuscript we will add (i) a comparison using an independent landmark detector and (ii) controlled degradation experiments on real videos that introduce blending, texture, and flicker artifacts while preserving authentic articulation. These additions will appear in Section 4 to directly test the causal attribution. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context present an empirical identification of elevated temporal lip variance in deepfakes, labeled as temporal lip jitter, and its instantiation in the BioLip framework using MediaPipe landmarks. No equations, derivations, fitted parameters renamed as predictions, or self-citations are shown that reduce any claim to its inputs by construction. The central principle is framed as a first-principles biomechanical observation rather than a self-referential definition or statistical artifact. This is a standard non-circular empirical framing.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MediaPipe Face Mesh reliably extracts 64 perioral landmarks across languages and conditions
invented entities (1)
-
temporal lip jitter
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Soumyya Kanti Datta, Shan Jia, and Siwei Lyu. PIA: Deep- fake detection using phoneme-temporal and identity- dynamic analysis.arXiv preprint arXiv:2510.14241,
- [2]
-
[3]
MediaPipe: A Framework for Building Perception Pipelines
Camillo Lugaresi, Jiuqiang Tang, Hadon Nash, Chris McClanahan, Esha Uboweja, Michael Hays, Fan Zhang, Chuo-Ling Chang, Ming Guang Yong, Juhyun Lee, Wan-Teh Chang, Wei Hua, Manfred Georg, and Matthias Grundmann. MediaPipe: A framework for building perception pipelines.arXiv preprint arXiv:1906.08172,
work page internal anchor Pith review arXiv 1906
-
[4]
A lip sync expert is all you need for speech to lip generation in the wild,
doi: 10.1145/3394171.3413532. Andreas R ¨ossler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. FaceForensics++: Learning to detect manipulated facial images. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1–11,
- [5]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.