PAPUS: Pauli-Space-Based Multiclass Quantum Classification
Pith reviewed 2026-05-10 07:09 UTC · model grok-4.3
The pith
A pair-adaptive method in Pauli space maintains over 90% accuracy in quantum multiclass classification while lowering measurement and circuit costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
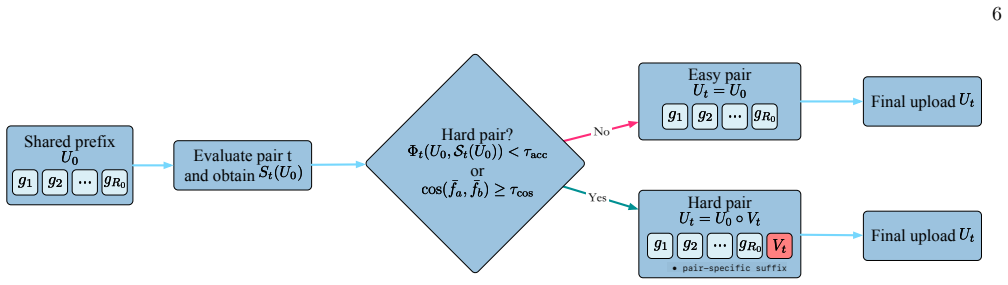
PAPUS evaluates candidate upload circuits using low-weight Pauli features and formulates upload design as a structured model selection problem based on discriminative representations. By dynamically adjusting circuit complexity according to class-pair difficulty, the framework achieves classification accuracies above 90% in both local noiseless simulation and the noisy simulator, while requiring substantially lower measurement and circuit cost. It also exhibits stronger robustness under noise compared to the two conventional baselines.
What carries the argument
The pair-adaptive selection mechanism in Pauli space that uses low-weight Pauli features to assess and choose upload circuits for balancing accuracy and cost.
If this is right
- The method scales to multiclass problems by allocating complexity only where needed for hard pairs.
- Total quantum resource usage decreases through fewer shots and gates for data upload.
- Noise robustness increases, limiting accuracy loss in noisy environments.
- Better cost-accuracy trade-off enables more tasks to run on current quantum devices.
Where Pith is reading between the lines
- Applying the adaptive selection on real quantum hardware beyond simulators could validate the noise benefits.
- Incorporating higher weight Paulis selectively might further boost accuracy for difficult pairs.
- The structured model selection could inspire similar adaptations in other quantum algorithms with variable difficulty.
- Hybrid systems might use classical preprocessing to identify which pairs need more complex features.
Load-bearing premise
Low-weight Pauli features provide sufficient discriminative power for the model selection to reliably choose circuits that maintain high accuracy at reduced cost across different class pairs.
What would settle it
Observing that on some datasets the adaptive selection either drops accuracy well below 90% or does not reduce the number of measurements and gates compared to the fixed baselines would challenge the central claim.
Figures






read the original abstract
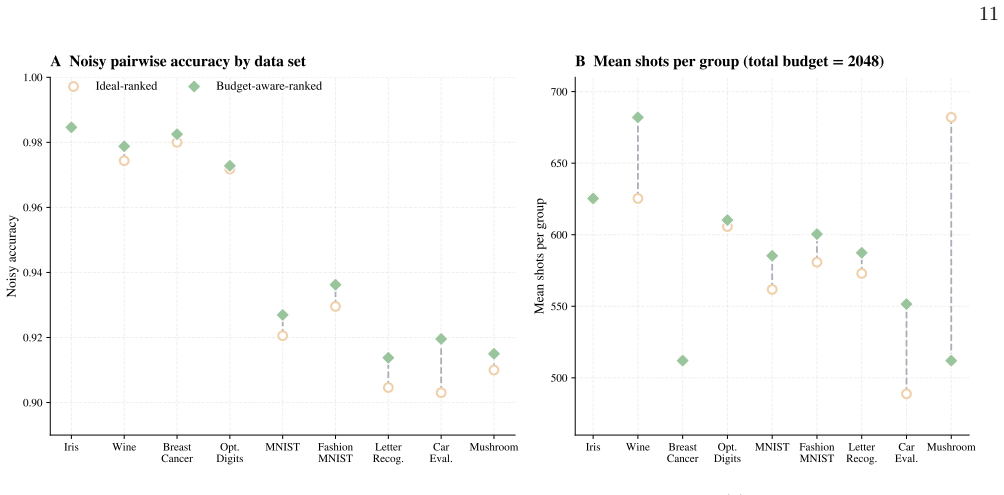
Quantum classification faces two key challenges. First, the difficulty of distinguishing between different classes varies: some class pairs are easy to separate, while others are more challenging. Second, practical execution is affected by noise, finite sampling, and measurement overhead. To address these issues, we propose PAPUS, a framework for pair-adaptive quantum classification in Pauli space. The method evaluates candidate upload circuits using low-weight Pauli features and formulates upload design as a structured model selection problem based on discriminative representations. By dynamically adjusting circuit complexity according to class-pair difficulty, the framework achieves a better balance between classification accuracy and resource efficiency. Experiments on 9 data sets with 474 tasks show that PAPUS achieves a favorable balance between predictive performance and execution cost. Specifically, PAPUS attains classification accuracies above 90% in both local noiseless simulation and the IonQ noisy simulator, while requiring substantially lower measurement and circuit cost (fewer total measurement shots and fewer quantum gates for data upload). Compared with the two conventional baselines, template_cv and kta_exact, PAPUS also shows much stronger robustness under noise: accuracy decreases by only 1.67% in the noisy setting, whereas both baselines degrade by 9.44%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents PAPUS, a Pauli-space-based framework for multiclass quantum classification. It addresses varying class-pair difficulties and noise by using low-weight Pauli features to select upload circuits via structured model selection. On 9 datasets comprising 474 tasks, it reports classification accuracies exceeding 90% in both noiseless simulation and IonQ noisy simulator, with substantially lower measurement shots and quantum gates than baselines (template_cv and kta_exact), and greater robustness to noise with only 1.67% accuracy degradation compared to 9.44% for the baselines.
Significance. If the reported robustness and cost advantages hold under proper statistical validation, this would be a meaningful contribution to practical quantum machine learning on NISQ hardware. The adaptive use of low-weight Pauli features to balance accuracy and resource use across class-pair difficulties offers a concrete approach to reducing measurement overhead and circuit depth while maintaining performance under noise. The scale of the evaluation (9 datasets, 474 tasks) is a positive aspect.
major comments (3)
- Results section (as summarized in abstract): the central robustness claim that PAPUS accuracy decreases by only 1.67% under the IonQ noisy simulator while both baselines degrade by 9.44% across 474 tasks is given as aggregate point estimates with no standard deviations, per-task or per-dataset breakdowns, or hypothesis tests on the degradation difference. This is load-bearing for the argument that the pair-adaptive Pauli-space selection reliably outperforms baselines in noise resilience; without variance measures the 7.77% gap cannot be distinguished from sampling noise.
- Method section: the formulation of upload design as a structured model selection problem based on low-weight Pauli features does not specify the exact selection criteria, the held-out evaluation protocol, or how the 474 tasks avoid data leakage between feature evaluation and final accuracy reporting. This directly affects the reliability of the claimed accuracy-cost tradeoff and the assumption that low-weight Pauli features provide sufficient discriminative power.
- Experiments section: no details are supplied on train/test splits, number of independent runs, random seeds, or error bars for the accuracy, measurement-shot, and gate-count metrics. This omission prevents assessment of whether the 'above 90%' accuracies and cost reductions are stable across the varying class-pair difficulties.
minor comments (2)
- The abstract states '9 data sets' without naming them or providing a summary table; adding a brief dataset table (with class counts and feature dimensions) in §4 would improve readability.
- Notation for 'low-weight Pauli features' and 'upload circuits' is introduced without an early equation or diagram; a small illustrative example in the introduction would aid clarity for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: Results section (as summarized in abstract): the central robustness claim that PAPUS accuracy decreases by only 1.67% under the IonQ noisy simulator while both baselines degrade by 9.44% across 474 tasks is given as aggregate point estimates with no standard deviations, per-task or per-dataset breakdowns, or hypothesis tests on the degradation difference. This is load-bearing for the argument that the pair-adaptive Pauli-space selection reliably outperforms baselines in noise resilience; without variance measures the 7.77% gap cannot be distinguished from sampling noise.
Authors: We agree that the robustness claim requires statistical support to be fully convincing. In the revised manuscript we will report standard deviations for the accuracy degradations across the 474 tasks, provide per-dataset and per-task breakdowns of the noise-induced drops, and include hypothesis testing (e.g., paired statistical tests) on the difference between PAPUS and the baselines. These additions will allow readers to assess whether the observed 7.77% gap is statistically reliable rather than attributable to sampling variation. revision: yes
-
Referee: Method section: the formulation of upload design as a structured model selection problem based on low-weight Pauli features does not specify the exact selection criteria, the held-out evaluation protocol, or how the 474 tasks avoid data leakage between feature evaluation and final accuracy reporting. This directly affects the reliability of the claimed accuracy-cost tradeoff and the assumption that low-weight Pauli features provide sufficient discriminative power.
Authors: We acknowledge that the current description of the structured model selection is high-level. In the revision we will explicitly state the selection criteria (the precise metric used to rank low-weight Pauli features by discriminative power), describe the held-out validation protocol employed for model selection, and clarify the construction of the 474 tasks to confirm that feature evaluation was performed on separate validation folds with no overlap to the final test sets used for accuracy reporting. This will eliminate any ambiguity regarding data leakage and substantiate the claimed accuracy-cost trade-off. revision: yes
-
Referee: Experiments section: no details are supplied on train/test splits, number of independent runs, random seeds, or error bars for the accuracy, measurement-shot, and gate-count metrics. This omission prevents assessment of whether the 'above 90%' accuracies and cost reductions are stable across the varying class-pair difficulties.
Authors: We agree that these experimental details are necessary for reproducibility and for evaluating stability. The revised Experiments section will specify the train/test split ratios used for each dataset, the number of independent runs performed, the random seeds employed, and will include error bars (standard deviations) on all reported metrics—accuracy, measurement shots, and gate counts—across the 474 tasks. These additions will demonstrate that the >90% accuracies and cost reductions hold consistently across class-pair difficulties. revision: yes
Circularity Check
No significant circularity in PAPUS derivation
full rationale
The paper proposes PAPUS as a framework that evaluates candidate upload circuits via low-weight Pauli features and casts upload design as a structured model selection problem based on class-pair discriminative power. Experimental results on 9 datasets (474 tasks) report accuracies and noise robustness via direct comparison to baselines (template_cv, kta_exact) on both noiseless simulation and IonQ hardware. No equations, derivations, or self-citations appear in the abstract that reduce any claimed prediction or result to the input data or fitted parameters by construction. The central performance claims rest on empirical evaluation rather than a closed mathematical loop, making the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
For one samplex, the up- loaded state is produced by a sequenceU= [g 1,
Cost of one uploaded state Letnbe the number of qubits and letD= 2 n denote the Hilbert-space dimension. For one samplex, the up- loaded state is produced by a sequenceU= [g 1, . . . , gL] of Latomic blocks. The dominant work comes from repeat- edly applying quantum gates to a state vector of length D. For a single-qubit rotation block, the implementation...
-
[2]
Cost of one Pauli-feature vector Let M=|P n,≤k|= kX w=1 n w 3w (A6) be the number of retained Pauli observables. For each observableP j, the expectation value fU,j(x) =⟨ψ U(x)|Pj|ψU(x)⟩(A7) is computed by applying the corresponding denseD×D Pauli operator to the state vector and then forming an inner product. The dominant term is again the matrix- vector ...
-
[3]
Cost of one sequence evaluation Suppose one candidate sequence is evaluated onN samples. Then Eq. (A10) gives Tfeat(N, L, M, n) =N T sample(L, M, n) =O(N(Ln+M)4 n) (A11) This is the dominant term in the exact-state implemen- tation. Subsequent steps, including sparse score compu- tation, sorting, Fisher-score evaluation, cosine-similarity analysis, and lo...
-
[4]
Because the search is progressive and greedy, exactlyAcandidates are evaluated in each round
Global and pair-adaptive search complexity LetA=|A|be the number of atomic upload blocks, Rthe maximum search depth, andR 0 the number of shared-prefix rounds. Because the search is progressive and greedy, exactlyAcandidates are evaluated in each round. Therefore the number of candidate sequences ex- amined during global-prefix selection is at most Sgloba...
-
[5]
First, all retained Pauli operators are precom- puted
Memory complexity The implementation stores two kinds of large ob- jects. First, all retained Pauli operators are precom- puted. Since there areMoperators and each is a dense D×Dmatrix, the storage cost is O(M D2) =O(M4 n).(A18) Second, feature caching stores the train and test Pauli features for every evaluated sequence. IfSsequences are cached andN tot ...
- [6]
- [7]
- [8]
-
[9]
M. Schuld and N. Killoran, Quantum machine learning in feature hilbert spaces, Physical Review Letters122, 040504 (2019)
work page 2019
-
[10]
V. Havl´ ıˇ cek, A. D. C´ orcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, Super- vised learning with quantum-enhanced feature spaces, Nature567, 209 (2019)
work page 2019
-
[11]
S. M. Pillay, I. Sinayskiy, E. Jembere, and F. Petruccione, A multi-class quantum kernel-based classifier, Advanced Quantum Technologies7, 2300249 (2023)
work page 2023
-
[12]
J. Zhou, D. Li, Y. Tan, X. Yang, Y. Zheng, and X. Liu, A multi-classification classifier based on variational quan- tum computation, Quantum Information Processing22, 412 (2023)
work page 2023
-
[13]
G. Park, J. Huh, and D. K. Park, Variational quantum one-class classifier, Machine Learning: Science and Tech- nology4, 015006 (2023)
work page 2023
-
[14]
L. J. Henderson, R. Goel, and S. Shrapnel, Quantum ker- nel machine learning with continuous variables, Quantum 8, 1570 (2024)
work page 2024
-
[15]
B. Duan, X. Sun, and C.-Y. Hsieh, Parallelized vari- ational quantum classifier with shallow qram circuit, Quantum Information Processing23, 92 (2024)
work page 2024
-
[16]
J. Chen and Y. Li, Empowering complex-valued data 16 classification with the variational quantum classifier, Frontiers in Quantum Science and Technology3, 1282730 (2024)
work page 2024
-
[17]
M. Srikumar, C. D. Hill, and L. C. L. Hollenberg, A kernel-based quantum random forest for improved clas- sification, Quantum Machine Intelligence6, 10 (2024)
work page 2024
-
[18]
S. Egginger, A. Sakhnenko, and J. M. Lorenz, A hyper- parameter study for quantum kernel methods, Quantum Machine Intelligence6, 44 (2024)
work page 2024
-
[19]
J. Heredge, C. Hill, L. Hollenberg, and M. Sevior, Permu- tation invariant encodings for quantum machine learning with point cloud data, Quantum Machine Intelligence6, 25 (2024)
work page 2024
-
[20]
S. Park and O. Simeone, Quantum conformal predic- tion for reliable uncertainty quantification in quantum machine learning, IEEE Transactions on Quantum Engi- neering5, 1 (2024)
work page 2024
-
[21]
C. Ding, S. Wang, Y. Wang, and W. Gao, Quantum ma- chine learning for multiclass classification beyond kernel methods, Physical Review A111, 062410 (2025)
work page 2025
-
[22]
D. Alvarez-Estevez, Benchmarking quantum machine learning kernel training for classification tasks, IEEE Transactions on Quantum Engineering6, 1 (2025)
work page 2025
-
[23]
I. Salmenper¨ a, F. Perkkola, and J. K. Nurminen, Fea- ture permutation for quantum machine learning, Quan- tum Machine Intelligence7, 107 (2025)
work page 2025
-
[24]
A. Melo, N. Earnest-Noble, and F. Tacchino, Pulse- efficient quantum machine learning, Quantum7, 1130 (2023)
work page 2023
- [25]
-
[26]
J. J. Meyer, M. Mularski, E. Gil-Fuster, A. A. Mele, F. Arzani, A. Wilms, and J. Eisert, Exploiting symmetry in variational quantum machine learning, PRX Quantum 4, 010328 (2023)
work page 2023
-
[27]
E. Peters and M. Schuld, Generalization despite overfit- ting in quantum machine learning models, Quantum7, 1210 (2023)
work page 2023
-
[28]
A. P´ erez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre, Data re-uploading for a universal quantum classifier, Quantum4, 226 (2020)
work page 2020
-
[29]
A. P´ erez-Salinas, D. L´ opez-N´ u˜ nez, A. Garc´ ıa-S´ aez, P. Forn-D´ ıaz, and J. I. Latorre, One qubit as a universal approximant, Physical Review A104, 012405 (2021)
work page 2021
-
[30]
T. Ono, W. Roga, K. Wakui, M. Fujiwara, S. Miki, H. Terai, and M. Takeoka, Demonstration of a bosonic quantum classifier with data reuploading, Physical Re- view Letters131, 013601 (2023)
work page 2023
-
[31]
R. LaRose and B. Coyle, Robust data encodings for quan- tum classifiers, Physical Review A102, 032420 (2020)
work page 2020
- [32]
-
[33]
A. Hayashi, A. Sakurai, W. J. Munro, and K. Nemoto, Effective quantum feature maps in quantum extreme reservoir computation from the xy model, Physical Re- view A111, 022431 (2025)
work page 2025
- [34]
-
[35]
G. Montalbano and L. Banchi, Quantum adversarial learning for kernel methods, Quantum Machine Intelli- gence7, 15 (2025)
work page 2025
- [36]
-
[37]
G. Buonaiuto, F. Gargiulo, G. De Pietro, M. Esposito, and M. Pota, The effects of quantum hardware proper- ties on the performances of variational quantum learning algorithms, Quantum Machine Intelligence6, 9 (2024)
work page 2024
-
[38]
H. Sahu, H. P. Gupta, V. V. Puvvada, and R. Mishra, De- vqcc: Device-aware quantum circuit cutting framework with applications in quantum machine learning, Quan- tum Machine Intelligence7, 89 (2025)
work page 2025
-
[39]
S. Roncallo, A. R. Morgillo, C. Macchiavello, L. Maccone, and S. Lloyd, Quantum optical classifier with superexpo- nential speedup, Communications Physics8, 147 (2025)
work page 2025
-
[40]
E. Recio-Armengol, J. Eisert, and J. J. Meyer, Single- shot quantum machine learning, Physical Review A111, 042420 (2025)
work page 2025
-
[41]
W. J. Huggins, J. R. McClean, N. C. Rubin, Z. Jiang, N. Wiebe, K. B. Whaley, and R. Babbush, Efficient and noise resilient measurements for quantum chemistry on near-term quantum computers, npj Quantum Informa- tion7, 23 (2021)
work page 2021
-
[42]
O. Crawford, B. van Straaten, D. Wang, T. Parks, E. Campbell, and S. Brierley, Efficient quantum measure- ment of pauli operators in the presence of finite sampling error, Quantum5, 385 (2021)
work page 2021
-
[43]
L. Zhu, S. Liang, C. Yang, and X. Li, Optimizing shot assignment in variational quantum eigensolver measure- ment, Journal of Chemical Theory and Computation20, 2390 (2024)
work page 2024
-
[44]
T. Hubregtsen, J. Pichlmeier, A. Stecher, and K. Bertels, Training quantum embedding kernels on near-term quan- tum computers, Physical Review A106, 042431 (2022)
work page 2022
-
[45]
V. Heyraud, Z. Li, Z. Denis, A. Le Boit´ e, and C. Ciuti, Noisy quantum kernel machines, Physical Review A106, 052421 (2022)
work page 2022
- [46]
- [47]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.