Recognition: unknown
Neighbor Embedding for High-Dimensional Sparse Poisson Data
Pith reviewed 2026-05-10 06:46 UTC · model grok-4.3
The pith
p-SNE embeds high-dimensional sparse count data by using KL divergence between Poisson distributions to measure dissimilarity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
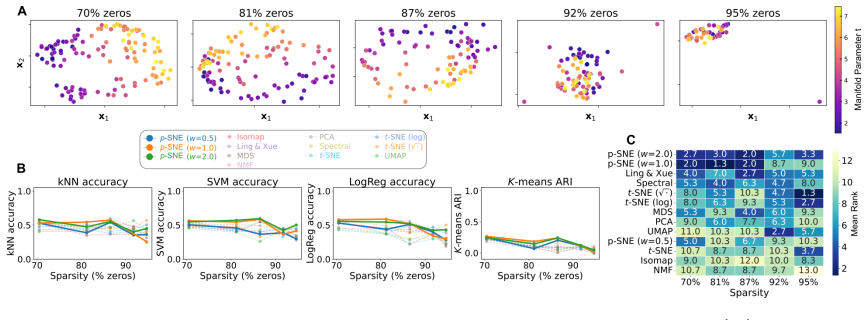
p-SNE is a nonlinear neighbor embedding method designed around the Poisson structure of count data, using KL divergence between Poisson distributions to measure pairwise dissimilarity and Hellinger distance to optimize the embedding. Tests on synthetic Poisson data and real datasets demonstrate recovery of weekday patterns in email communication, research area clusters in OpenReview papers, and temporal drift together with stimulus gradients in neural spike recordings.
What carries the argument
p-SNE, a stochastic neighbor embedding variant that substitutes Poisson KL divergence for Euclidean distances when defining neighbor probabilities and employs Hellinger distance during layout optimization.
If this is right
- Synthetic Poisson data with known cluster structure is recovered in the low-dimensional embedding.
- Email count matrices separate into weekday patterns without additional supervision.
- Research paper abstracts form clusters aligned with topical areas.
- Neural spike counts reveal both slow temporal drift and stimulus-driven gradients in the same embedding.
Where Pith is reading between the lines
- The same Poisson-based dissimilarity could be substituted into other embedding or clustering algorithms that currently use Euclidean distances.
- When count data exhibit overdispersion, replacing the Poisson KL term with a negative-binomial version might preserve the same advantages.
- Downstream supervised models trained on the p-SNE coordinates may achieve higher accuracy on count-based prediction tasks than models trained on Euclidean embeddings.
Load-bearing premise
The assumption that KL divergence between Poisson distributions is the right measure of pairwise dissimilarity for preserving meaningful structure in sparse count data.
What would settle it
Applying p-SNE to synthetic data generated from two well-separated Poisson rate vectors and finding that the resulting embedding mixes the two groups instead of keeping them distinct.
Figures







read the original abstract
Across many scientific fields, measurements often represent the number of times an event occurs. For example, a document can be represented by word occurrence counts, neural activity by spike counts per time window, or online communication by daily email counts. These measurements yield high-dimensional count data that often approximate a Poisson distribution, frequently with low rates that produce substantial sparsity and complicate downstream analysis. A useful approach is to embed the data into a low-dimensional space that preserves meaningful structure, commonly termed dimensionality reduction. Yet existing dimensionality reduction methods, including both linear (e.g., PCA) and nonlinear approaches (e.g., t-SNE), often assume continuous Euclidean geometry, thereby misaligning with the discrete, sparse nature of low-rate count data. Here, we propose p-SNE (Poisson Stochastic Neighbor Embedding), a nonlinear neighbor embedding method designed around the Poisson structure of count data, using KL divergence between Poisson distributions to measure pairwise dissimilarity and Hellinger distance to optimize the embedding. We test p-SNE on synthetic Poisson data and demonstrate its ability to recover meaningful structure in real-world count datasets, including weekday patterns in email communication, research area clusters in OpenReview papers, and temporal drift and stimulus gradients in neural spike recordings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces p-SNE, a nonlinear neighbor embedding method for high-dimensional sparse Poisson count data. High-dimensional pairwise dissimilarities are measured via KL divergence between Poisson distributions, while the low-dimensional embedding is optimized using Hellinger distance. The authors evaluate the approach on synthetic Poisson data and demonstrate recovery of structure in three real-world count datasets: weekday patterns from email counts, research-area clusters from OpenReview paper counts, and temporal/stimulus gradients from neural spike recordings.
Significance. If the reported structure recovery holds under quantitative scrutiny, p-SNE would fill a methodological gap by respecting the discrete, low-rate Poisson geometry of count data rather than imposing Euclidean assumptions. This could improve embeddings for text, neuroscience, and network data where standard t-SNE or PCA often distort sparse count structure. The multi-domain empirical examples provide initial evidence of practical relevance.
minor comments (3)
- The abstract and introduction claim superior recovery of structure, but no quantitative metrics (e.g., neighborhood preservation, trustworthiness, or reconstruction error) are summarized in the provided text; adding a comparison table against t-SNE, UMAP, and Poisson PCA would strengthen the central claim.
- Section describing the optimization (likely §3 or §4) should clarify the precise form of the Hellinger-based cost function and any gradient approximations used, as the switch from KL to Hellinger is load-bearing for the method's distinction from standard SNE.
- The real-data experiments would benefit from explicit statements of the Poisson rate assumptions and any preprocessing (e.g., thresholding or normalization) applied to the count matrices, to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for their supportive summary of the manuscript and for recommending minor revision. We appreciate the recognition that p-SNE addresses a methodological gap for sparse Poisson count data and that the empirical examples across email, OpenReview, and neural spike datasets provide initial evidence of relevance. We are pleased that the approach is viewed as potentially improving upon standard t-SNE or PCA for discrete, low-rate count data.
Circularity Check
No significant circularity detected
full rationale
The paper introduces p-SNE as a novel construction that defines pairwise dissimilarities via KL divergence on Poisson distributions and optimizes embeddings with Hellinger distance. No equations or steps in the abstract or described method reduce by construction to fitted parameters, self-referential predictions, or load-bearing self-citations. Empirical tests on synthetic Poisson data and independent real-world count datasets (email, papers, neural spikes) function as external validation rather than inputs that force the claimed outcomes. The derivation chain remains self-contained against the stated assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Measurements represent counts that approximate a Poisson distribution with low rates leading to sparsity.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1910.00204 , year=
Ehsan Amid and Manfred K Warmuth. Trimap: Large-scale dimensionality reduction using triplets. arXiv preprint arXiv:1910.00204,
-
[2]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimension reduction.arXiv preprint arXiv:1802.03426,
work page internal anchor Pith review arXiv
-
[3]
Noga Mudrik, Yuxi Chen, Gal Mishne, and Adam S Charles. Multi-integration of labels across categories for component identification (milcci).arXiv preprint arXiv:2602.04270,
-
[4]
Jiancheng Xie, Lou C Kohler Voinov, Noga Mudrik, Gal Mishne, and Adam Charles. Multi- way multislice phate: Visualizing hidden dynamics of rnns through training.arXiv preprint arXiv:2406.01969,
-
[5]
Each gradient descent iteration involves updating the Student-t kernel matrixQand computing the gradient (Eq
operations (softmax normalization and symmetrization). Each gradient descent iteration involves updating the Student-t kernel matrixQand computing the gradient (Eq. S7), both of which costO(N 2P) wherePis the embedding dimensionality. OverK iterations, the total cost isO(N 2M+KN 2P). SinceM≫Pin all our experiments, the distance matrix computation dominate...
2022
-
[6]
20 , h ∗ m = 10· ⌊m/20⌋ 2 (S17) Neurons with adjacent indices thus have nearby preferred positions alongt. Firing rates and spike counts.The firing rate of neuronmon trialidepends on the distance between the stimulus position (t i, hi) and the neuron’s preferred position (t ∗ m, h∗ m): λi,m =λ bias +λ peak exp −∆t2 i,m 2 − ∆h2 i,m 20 ! (S18) 29 Figure S14...
2022
-
[7]
30 Table S3: Wall-clock runtime (seconds) ford= 3 embedding dimensions on both synthetic datasets
+ 1.5), h∼Uniform(0,5) (S19) For each class, we draw 30 stimulus positions (t i, hi), yieldingN= 120 trials (one all-zero sample was removed, giving 119). 30 Table S3: Wall-clock runtime (seconds) ford= 3 embedding dimensions on both synthetic datasets. Method Angular Embedding Sparse Sequential PCA 0.18 0.04 NMF 0.21 0.07 Spectral 0.27 0.09 Isomap 0.59 0...
2022
-
[8]
person A
25 , h ∗ m = 5.0· ⌊m/25⌋ 2 (S20) Firing rates and spike counts.The firing rate of neuronmon trialiis: λi,m =λ bias +λ peak exp − d2 i,m 3 ! (S21) whered i,m = p (ti −t ∗m)2 + (hi −h ∗m)2 is the Euclidean distance between the stimulus and the neuron’s preferred position. We setλ bias = 0.1 andλ peak = 2.5, so rates range from 0.1 to 2.6. The observed spike...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.