No One Fits All: From Fixed Prompting to Learned Routing in Multilingual LLMs
Pith reviewed 2026-05-10 07:13 UTC · model grok-4.3
The pith
Lightweight classifiers learn to select optimal prompting strategies for each input in multilingual LLMs, beating any fixed strategy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
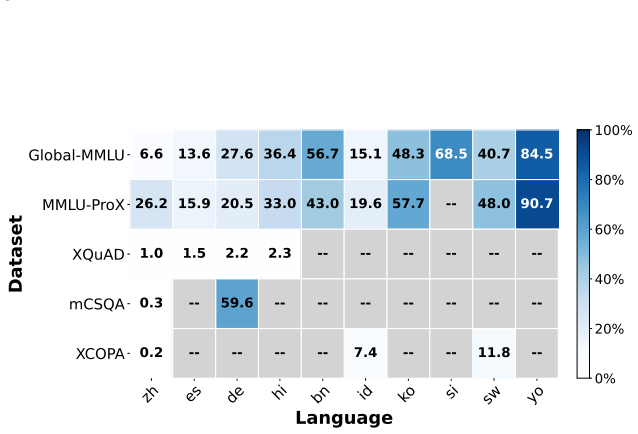
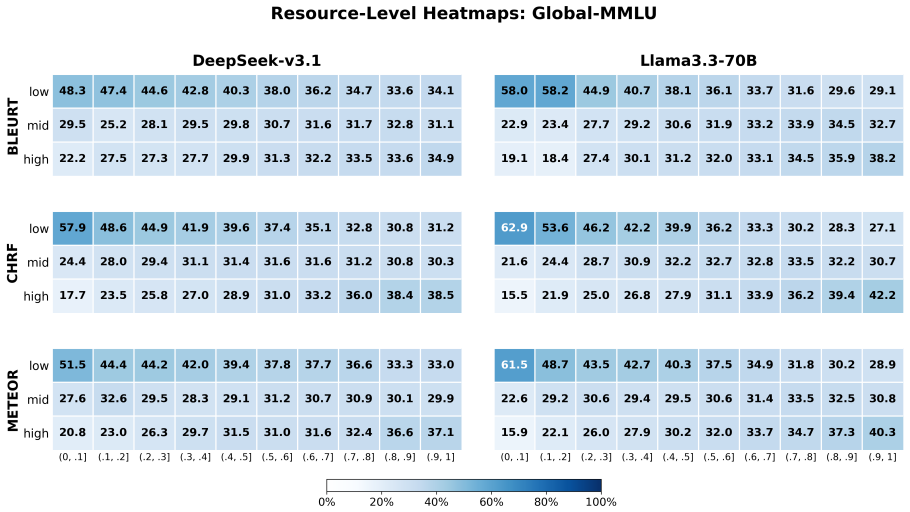
No single prompting strategy is universally optimal in multilingual LLMs. Translation-based prompting benefits low-resource languages more than high-resource ones, and language resource level matters more than translation quality alone. Lightweight classifiers trained to predict the better strategy for each instance outperform fixed strategies across benchmarks and generalize to unseen task formats.
What carries the argument
Lightweight classifiers that predict, for each input, whether native-language prompting or explicit translation-based prompting will be optimal.
If this is right
- The classifiers achieve statistically significant improvements over fixed strategies across four benchmarks.
- The routing decision generalizes to unseen task formats not observed during training.
- Language resource level, rather than translation quality alone, determines when translation helps.
- Prompt-based self-routing underperforms explicit translation.
Where Pith is reading between the lines
- Routing could be folded into model fine-tuning rather than applied only at inference time.
- The same lightweight decision model might extend to other multilingual capabilities such as generation or chain-of-thought reasoning.
- High-resource languages could avoid translation overhead entirely once the classifier is reliable.
Load-bearing premise
The classifiers trained on the tested benchmarks and languages will keep selecting the best strategy for new inputs and that the measured gains come from the routing choice itself.
What would settle it
Retraining the classifiers on a fresh set of languages or tasks and finding no improvement over the best fixed strategy, or finding that gains vanish once prompt length and format are controlled.
Figures











read the original abstract
Translation-based prompting is widely used in multilingual LLMs, yet its effectiveness varies across languages and tasks. We evaluate prompting strategies across ten languages of different resource levels and four benchmarks. Our analysis shows that no single strategy is universally optimal. Translation strongly benefits low-resource languages even when translation quality is imperfect, high-resource languages gain little, and prompt-based self-routing underperforms explicit translation. Motivated by these findings, we formulate prompting strategy selection as a learned decision problem and introduce lightweight classifiers that predict whether native or translation-based prompting is optimal for each instance. The classifiers achieve statistically significant improvements over fixed strategies across four benchmarks and generalize to unseen task formats not observed during training. Further analysis reveals that language resource level, rather than translation quality alone, determines when translation is beneficial.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates prompting strategies for multilingual LLMs across ten languages of varying resource levels and four benchmarks. It finds that no single strategy is universally optimal, with translation-based prompting benefiting low-resource languages (even with imperfect translation) while providing little gain for high-resource languages, and prompt-based self-routing underperforming explicit translation. The authors formulate strategy selection as a learned classification problem and introduce lightweight classifiers to predict native versus translation-based prompting per instance. These classifiers are reported to deliver statistically significant improvements over fixed strategies across the benchmarks while generalizing to unseen task formats not seen during training, with further analysis attributing benefits primarily to language resource level rather than translation quality alone.
Significance. If the empirical results hold after addressing methodological details, the work is significant for demonstrating that adaptive routing via lightweight classifiers can outperform fixed prompting in multilingual settings. It provides concrete evidence on when translation helps, grounded in resource-level analysis, and highlights a practical, generalizable approach that avoids heavy compute. The reported generalization to held-out task formats and the internal consistency of the motivation with the findings are strengths that could influence prompting practices in low-resource NLP.
major comments (2)
- [Abstract] Abstract: the claim of statistically significant improvements over fixed strategies is load-bearing for the central contribution, yet the abstract (and presumably the experimental section) provides no details on classifier training procedure, exact feature set, baseline implementations, error bars, or controls for selection effects, making it impossible to verify whether gains derive from the routing decision itself.
- [Abstract] Abstract / Experiments: the generalization result to unseen task formats is central to the practical value, but without explicit description of how task formats were held out during classifier training or whether input features risk task leakage, the out-of-distribution claim cannot be fully assessed and may be weaker than stated.
minor comments (2)
- The analysis of why prompt-based self-routing underperforms explicit translation would be clearer with a dedicated quantitative breakdown or table comparing the two approaches across resource levels.
- Notation for the classifiers (e.g., input features, output labels) should be introduced consistently in the main text rather than deferred to appendices to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. The points raised correctly identify areas where additional methodological transparency will strengthen the paper. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of statistically significant improvements over fixed strategies is load-bearing for the central contribution, yet the abstract (and presumably the experimental section) provides no details on classifier training procedure, exact feature set, baseline implementations, error bars, or controls for selection effects, making it impossible to verify whether gains derive from the routing decision itself.
Authors: We agree that the abstract is too concise to include these details and that the experimental section would benefit from more explicit exposition. We will revise both the abstract and the experimental section to describe the classifier training procedure, the exact feature set used, the baseline implementations, the computation of error bars, and the controls for selection effects (including ablations that isolate the contribution of the routing decision). revision: yes
-
Referee: [Abstract] Abstract / Experiments: the generalization result to unseen task formats is central to the practical value, but without explicit description of how task formats were held out during classifier training or whether input features risk task leakage, the out-of-distribution claim cannot be fully assessed and may be weaker than stated.
Authors: We agree that the hold-out protocol and feature design require clearer documentation to substantiate the generalization claim. We will add an explicit description of the task-format hold-out procedure (training on three benchmarks and evaluating on the fourth) and an analysis of potential task leakage in the chosen input features. These additions will be placed in the experiments section and referenced from the abstract. revision: yes
Circularity Check
No significant circularity: empirical classifier evaluation is self-contained
full rationale
The paper evaluates prompting strategies empirically across languages and benchmarks, observes that no fixed strategy is optimal, then trains lightweight classifiers on that data to select per-instance strategies. The reported gains are direct statistical comparisons of classifier outputs versus fixed baselines on the same benchmarks, with generalization tested on held-out task formats. This is a standard supervised learning pipeline with no self-definitional equations, no fitted parameters renamed as predictions, and no load-bearing self-citations that reduce the central claim to prior unverified results. The derivation chain remains falsifiable and independent of its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions in supervised machine learning evaluation including representative sampling of test instances and validity of statistical significance tests.
Reference graph
Works this paper leans on
-
[1]
On the cross-lingual transferability of mono- lingual representations. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguis- tics. Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An automatic metric for MT evaluation with im- proved correlation with human judgments. InPro- ceedin...
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[2]
Beyond English: The impact of prompt transla- tion strategies across languages and tasks in multilin- gual LLMs. InFindings of the Association for Com- putational Linguistics: NAACL 2025, pages 1331– 1354, Albuquerque, New Mexico. Association for Computational Linguistics. Jean De Dieu Nyandwi, Yueqi Song, Simran Khanuja, and Graham Neubig. 2025. Groundin...
-
[3]
mCSQA: Multilingual commonsense reason- ing dataset with unified creation strategy by language models and humans. InFindings of the Association for Computational Linguistics: ACL 2024, pages 14182–14214, Bangkok, Thailand. Association for Computational Linguistics. Thibault Sellam, Dipanjan Das, and Ankur Parikh. 2020. BLEURT: Learning robust metrics for ...
-
[4]
Global MMLU: Understanding and addressing cultural and linguistic biases in multilingual evalua- tion. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), pages 18761–18799, Vienna, Austria. Association for Computational Linguistics. Zhi Rui Tam, Cheng-Kuang Wu, Yu Ying Chiu, Chieh-Yen Lin, ...
-
[5]
InThe Eleventh International Conference on Learning Representations
Language matters: How do multilingual input and reasoning paths affect large reasoning models? Preprint, arXiv:2505.17407. NLLB Team, Marta R. Costa-jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Hef- fernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula,...
-
[6]
The fi- nal hyperparameter values selected for each model configuration are presented in Table 6
to perform automated hyperparameter op- timization, optimizing overall accuracy (problem- level correctness) as the primary objective. The fi- nal hyperparameter values selected for each model configuration are presented in Table 6. XGBoostWe tune the number of estimators (100– 600), maximum tree depth (3–12), learning rate (0.01–0.3, log scale), subsampl...
-
[8]
**Rule:** Ensure each step is logical, clear, and builds upon the previous one
Then, apply your strategy step-by-step to reach the solution. **Rule:** Ensure each step is logical, clear, and builds upon the previous one. **Initialization:** Let’s begin by understanding the problem and formulating a strategy. **Task Input:** Question: {question} Options: {options} Please follow the SCoT methodology: first outline your strategic appro...
-
[9]
First, analyze the problem and develop a strategic approach to solve it
-
[10]
**Rule:** Ensure each step is logical, clear, and builds upon the previous one
Then, apply your strategy step-by-step to reach the solution. **Rule:** Ensure each step is logical, clear, and builds upon the previous one. **Initialization:** Let’s begin by understanding the problem and formulating a strategy. **Task Input:** Question: {question} Options: {options} Please follow the SCoT methodology: first outline your strategic appro...
-
[11]
NATIVE: Answer directly in {language_name}
-
[12]
TRANSLATE: Translate the question to English first, then answer Please assess your proficiency and confidence: - How confident are you in understanding and reasoning in {language_name}? (Consider vocabulary, grammar, cultural context) - Is this a complex question requiring nuanced reasoning, or is it straightforward? - Would translating to English improve...
-
[13]
NATIVE: Answer directly in {language_name} based on the context
-
[14]
de","zh" dataset Name of the dataset (e.g., mmlu_prox, xquad)
TRANSLATE: Translate the context and question to English first, then answer Please assess your proficiency and confidence: - How confident are you in understanding and reasoning in {language_name}? (Consider vocabulary, grammar, cultural context) - Is this a complex question requiring nuanced reasoning, or is it straightforward? - Would translating to Eng...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.