Recognition: unknown
Dynamic Emotion and Personality Profiling for Multimodal Deception Detection
Pith reviewed 2026-05-10 06:23 UTC · model grok-4.3
The pith
Dynamic per-sample emotion and personality labels plus reliability-weighted multimodal fusion improve joint deception detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
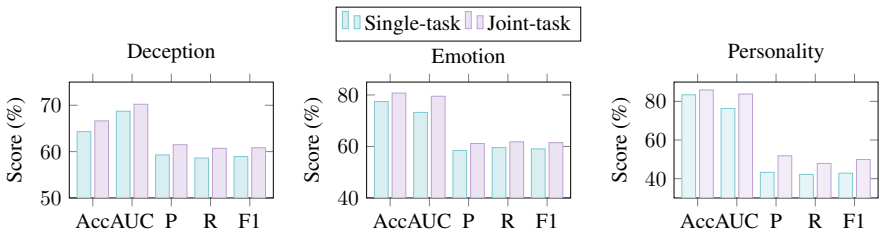
By establishing dynamic emotion and personality labels per sample through a multi-model multi-prompt scheme and quality evaluation, then applying an adaptive reliability-weighted fusion framework that maps modal features to high-dimensional Gaussian distributions, performs weighted fusion, alignment, and sorting constraints, the Rel-DDEP model jointly detects deception, emotion, and personality more accurately than existing state-of-the-art baselines, with measured F1 improvements of 2.53%, 2.66%, and 9.30% respectively on the MDPE and DDEP datasets.
What carries the argument
The Rel-DDEP framework, which quantifies uncertainty by mapping multimodal features to high-dimensional Gaussian space and then applies reliability-weighted fusion together with alignment and sorting constraint modules.
If this is right
- Dynamic per-sample labels for emotion and personality are necessary to achieve the reported gains in joint deception detection.
- Quantifying uncertainty via high-dimensional Gaussian mapping enables more effective reliability weighting across modalities.
- The alignment and sorting constraint modules contribute to consistent performance across the three detection tasks.
- The approach generalizes from the MDPE dataset to the newly constructed DDEP dataset while maintaining the measured improvements.
Where Pith is reading between the lines
- The annotation scheme could be applied to other multimodal tasks that currently lack fine-grained dynamic labels, such as sarcasm or intent detection.
- If the reliability weighting proves robust, it might reduce the need for extensive manual annotation by letting the model down-weight noisy modalities automatically.
- Extending the Gaussian-space uncertainty modeling to video or audio streams in real time could support live deception monitoring systems.
Load-bearing premise
That the multi-model multi-prompt annotations with quality checks produce truly reliable dynamic emotion and personality labels, and that the Gaussian mapping and reliability weighting produce real gains rather than overfitting to dataset artifacts.
What would settle it
Run an ablation on the same test sets where the reliability-weighted fusion and Gaussian uncertainty mapping are replaced by simple concatenation or averaging; if the F1 gains over baselines disappear or reverse while keeping all other architecture elements fixed, the claim that those components drive the improvement would be falsified.
Figures






read the original abstract
Deception detection is of great significance for ensuring information security and conducting public opinion analysis, with personality factors and emotion cues playing a critical role. However, existing methods lack sample-level dynamic annotations for emotions and personality.In this paper, we propose an innovative multi-model multi-prompt annotation scheme and a strict label quality evaluation standard, and establish a multimodal joint detection dataset DDEP for deception, emotion, and personality. Meanwhile, we propose Rel-DDEP, an adaptive reliability-weighted fusion framework. Our framework quantifies uncertainty by mapping modal features to a high-dimensional Gaussian distribution space. It then performs reliability-weighted fusion and incorporates an alignment module and a sorting constraint module to achieve joint detection of deception, emotion, and personality. Experimental results on the MDPE and DDEP datasets show that our Rel-DDEP significantly outperforms the existing state-of-the-art baseline models in three tasks. The F1 score of the deception detection increases by 2.53%, that of the emotion detection increases by 2.66%, and that of the personality detection increases by 9.30%. The experiments fully verify the necessity of annotating dynamic emotion and personality labels for each sample and the effectiveness of reliability-weighted fusion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-model multi-prompt annotation scheme with strict quality evaluation to create the new DDEP multimodal dataset for joint deception, emotion, and personality detection. It introduces the Rel-DDEP framework, which maps modal features to a high-dimensional Gaussian distribution to quantify uncertainty, applies reliability-weighted fusion, and incorporates alignment and sorting constraint modules for joint detection. Experiments on MDPE and DDEP report F1 improvements of 2.53% for deception detection, 2.66% for emotion detection, and 9.30% for personality detection over existing SOTA baselines, claiming to verify the necessity of dynamic per-sample labels and the effectiveness of the fusion approach.
Significance. If the results prove robust, the work could advance multimodal deception detection by highlighting the value of dynamic emotion and personality annotations per sample and by providing an adaptive fusion mechanism that accounts for modality uncertainty. The introduction of the DDEP dataset and the annotation pipeline would constitute a useful community resource, though the absence of detailed validation limits immediate impact assessment.
major comments (3)
- [Abstract / Experimental results] Abstract and experimental results section: The reported F1 gains (2.53%, 2.66%, 9.30%) are presented without ablation studies, statistical significance tests, variance estimates across runs, or error analysis. This makes it impossible to isolate the contribution of the Gaussian mapping, reliability-weighted fusion, alignment module, and sorting constraint from the effects of the new annotation pipeline, dataset construction, or hyperparameter choices.
- [Rel-DDEP framework description] Methods description: The reliability weights and Gaussian distribution parameters are described as part of the adaptive fusion but no details are provided on their estimation procedure, whether they are learned jointly with the model or fitted post-hoc, or any regularization to prevent overfitting to the evaluation data. This directly bears on the circularity concern for the performance deltas.
- [Experiments] Experimental setup: No information is supplied on the specific SOTA baseline models, their re-implementation details, hyperparameter tuning protocols, or whether they were evaluated on the newly constructed DDEP dataset under identical conditions. Without this, the comparative claims cannot be verified.
minor comments (3)
- [Abstract] Define all acronyms (MDPE, DDEP, Rel-DDEP) at first use and ensure consistent terminology throughout.
- [Framework architecture] Provide additional details or a diagram for the alignment module and sorting constraint module to clarify their integration with the Gaussian fusion.
- [Dataset construction] Expand the description of the strict label quality evaluation standard used in the multi-model multi-prompt annotation scheme, including inter-annotator agreement metrics.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive feedback. We appreciate the identification of areas where additional rigor and detail will strengthen the manuscript. We address each major comment below and will revise the paper to incorporate the requested clarifications, analyses, and experimental details.
read point-by-point responses
-
Referee: [Abstract / Experimental results] Abstract and experimental results section: The reported F1 gains (2.53%, 2.66%, 9.30%) are presented without ablation studies, statistical significance tests, variance estimates across runs, or error analysis. This makes it impossible to isolate the contribution of the Gaussian mapping, reliability-weighted fusion, alignment module, and sorting constraint from the effects of the new annotation pipeline, dataset construction, or hyperparameter choices.
Authors: We agree that the current presentation of results would benefit from more granular analysis to isolate component contributions. In the revised manuscript we will add a dedicated ablation subsection that systematically removes the Gaussian mapping, reliability-weighted fusion, alignment module, and sorting constraint. We will report statistical significance via McNemar’s test on F1 scores, include mean and standard deviation across five independent runs with different random seeds, and provide error analysis on failure cases to illustrate where dynamic per-sample emotion/personality labels and uncertainty-aware fusion yield the largest gains. These additions will be placed in the Experiments section and referenced from the abstract. revision: yes
-
Referee: [Rel-DDEP framework description] Methods description: The reliability weights and Gaussian distribution parameters are described as part of the adaptive fusion but no details are provided on their estimation procedure, whether they are learned jointly with the model or fitted post-hoc, or any regularization to prevent overfitting to the evaluation data. This directly bears on the circularity concern for the performance deltas.
Authors: The manuscript currently gives a high-level overview of the Gaussian mapping and reliability weighting. We will expand the Methods section with the precise estimation procedure: separate prediction heads output the mean and diagonal covariance of each modality’s Gaussian; these parameters are learned jointly with the rest of the network via end-to-end back-propagation on the joint detection losses. Reliability weights are derived directly from the predicted variances at both training and inference time. We will also document the regularization terms (KL divergence on the Gaussians plus weight decay) that guard against overfitting and confirm that no post-hoc fitting on test data occurs. revision: yes
-
Referee: [Experiments] Experimental setup: No information is supplied on the specific SOTA baseline models, their re-implementation details, hyperparameter tuning protocols, or whether they were evaluated on the newly constructed DDEP dataset under identical conditions. Without this, the comparative claims cannot be verified.
Authors: We will add a comprehensive Experimental Setup subsection that (1) lists every baseline with its original citation, (2) describes our re-implementations and any multimodal adaptations, (3) details the hyperparameter search protocol (grid search over learning rate, batch size, and fusion coefficients performed on a held-out validation split), and (4) explicitly states that all baselines were retrained and evaluated on the identical DDEP train/validation/test partitions and preprocessing pipeline used for Rel-DDEP. Results on MDPE will also be reported under the same protocol for completeness. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical ML framework (multi-prompt annotation for DDEP dataset + Rel-DDEP with Gaussian mapping, reliability-weighted fusion, alignment, and sorting) and reports experimental F1 gains on MDPE and DDEP. No mathematical derivation chain, equations, or self-citations appear in the provided text that reduce any claimed result to its inputs by construction. Performance deltas are framed as experimental outcomes, not first-principles predictions or fitted quantities renamed as forecasts. The work is self-contained against external benchmarks in the sense that results are dataset-specific evaluations without load-bearing self-referential definitions.
Axiom & Free-Parameter Ledger
free parameters (2)
- reliability weights
- Gaussian distribution parameters
axioms (2)
- domain assumption Dynamic sample-level emotion and personality annotations improve joint deception detection over static labels
- domain assumption Multimodal features can be usefully represented in a shared high-dimensional Gaussian space for uncertainty quantification
invented entities (1)
-
Rel-DDEP framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URL: " 'urlintro :=
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Mohamed Abouelenien, Ver \'o nica P \'e rez-Rosas, Rada Mihalcea, and Mihai Burzo. 2016. Detecting deceptive behavior via integration of discriminative features from multiple modalities. IEEE Transactions on Information Forensics and Security, 12(5):1042--1055
2016
-
[4]
Jalal S Alowibdi, Ugo A Buy, S Yu Philip, and Leon Stenneth. 2014. Detecting deception in online social networks. In 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2014), pages 383--390. IEEE
2014
-
[5]
Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. 2020. wav2vec 2.0: A framework for self-supervised learning of speech representations. Advances in neural information processing systems, 33:12449--12460
2020
-
[6]
Cong Cai, Shan Liang, Xuefei Liu, Kang Zhu, Zhengqi Wen, Jianhua Tao, Heng Xie, Jizhou Cui, Yiming Ma, Zhenhua Cheng, et al. 2024. Mdpe: A multimodal deception dataset with personality and emotional characteristics. Advances in Neural Information Processing Systems
2024
-
[7]
Lile Cai, Xun Xu, Jun Hao Liew, and Chuan Sheng Foo. 2021. Revisiting superpixels for active learning in semantic segmentation with realistic annotation costs. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10988--10997
2021
-
[8]
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, et al. 2022. Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE Journal of Selected Topics in Signal Processing, 16(6):1505--1518
2022
-
[9]
Jacob Cohen. 1960. A coefficient of agreement for nominal scales. Educational and psychological measurement, 20(1):37--46
1960
-
[10]
Alyt Damstra, Hajo G Boomgaarden, Elena Broda, Elina Lindgren, Jesper Str \"o mb \"a ck, Yariv Tsfati, and Rens Vliegenthart. 2021. What does fake look like? a review of the literature on intentional deception in the news and on social media. Journalism Studies, 22(14):1947--1963
2021
- [11]
-
[12]
Yuzhe Ding, Kang He, Bobo Li, Li Zheng, Haijun He, Fei Li, Chong Teng, and Donghong Ji. 2025. Zero-shot conversational stance detection: Dataset and approaches. In Findings of the Association for Computational Linguistics: ACL 2025, pages 3221--3235
2025
-
[13]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[14]
Joseph P Gaspar and Maurice E Schweitzer. 2013. The emotion deception model: A review of deception in negotiation and the role of emotion in deception. Negotiation and Conflict Management Research, 6(3):160--179
2013
-
[15]
Fabrizio Gilardi, Meysam Alizadeh, and Ma \"e l Kubli. 2023. Chatgpt outperforms crowd workers for text-annotation tasks. Proceedings of the National Academy of Sciences, 120(30):e2305016120
2023
-
[16]
Viresh Gupta, Mohit Agarwal, Manik Arora, Tanmoy Chakraborty, Richa Singh, and Mayank Vatsa. 2019. Bag-of-lies: A multimodal dataset for deception detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 0--0
2019
-
[17]
Christopher N Gutierrez, Saurabh Bagchi, H Mohammed, and Jeff Avery. 2015. Modeling deception in information security as a hypergame--a primer. In Proceedings of the 16th Annual Information Security Symposium, page 41. CERIAS-Purdue University
2015
-
[18]
Xiao Han, Nizar Kheir, and Davide Balzarotti. 2018. Deception techniques in computer security: A research perspective. ACM Computing Surveys (CSUR), 51(4):1--36
2018
-
[19]
Jinglue Hang, Xiangbo Lin, Tianqiang Zhu, Xuanheng Li, Rina Wu, Xiaohong Ma, and Yi Sun. 2024. Dexfuncgrasp: A robotic dexterous functional grasp dataset constructed from a cost-effective real-simulation annotation system. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 10306--10313
2024
- [20]
-
[21]
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. 2021. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM transactions on audio, speech, and language processing, 29:3451--3460
2021
-
[22]
Ronald T Kneusel and Michael C Mozer. 2017. Improving human-machine cooperative visual search with soft highlighting. ACM Transactions on Applied Perception (TAP), 15(1):1--21
2017
-
[23]
Srijan Kumar, Chongyang Bai, VS Subrahmanian, and Jure Leskovec. 2021. Deception detection in group video conversations using dynamic interaction networks. In Proceedings of the international AAAI conference on web and social media, volume 15, pages 339--350
2021
-
[24]
Vivian Lai and Chenhao Tan. 2019. On human predictions with explanations and predictions of machine learning models: A case study on deception detection. In Proceedings of the conference on fairness, accountability, and transparency, pages 29--38
2019
-
[25]
Sarah I Levitan, Guzhen An, Mandi Wang, Gideon Mendels, Julia Hirschberg, Michelle Levine, and Andrew Rosenberg. 2015. Cross-cultural production and detection of deception from speech. In Proceedings of the 2015 ACM on workshop on multimodal deception detection, pages 1--8
2015
-
[26]
Leena Mathur and Maja J Matari \'c . 2020. Introducing representations of facial affect in automated multimodal deception detection. In Proceedings of the 2020 international conference on multimodal interaction, pages 305--314
2020
-
[27]
Ver \'o nica P \'e rez-Rosas, Mohamed Abouelenien, Rada Mihalcea, Yao Xiao, CJ Linton, and Mihai Burzo. 2015. Verbal and nonverbal clues for real-life deception detection. In Proceedings of the 2015 conference on empirical methods in natural language processing, pages 2336--2346
2015
-
[28]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748--8763. PmLR
2021
-
[29]
Nathan Vance, Jeremy Speth, Siamul Khan, Adam Czajka, Kevin W Bowyer, Diane Wright, and Patrick Flynn. 2022. Deception detection and remote physiological monitoring: A dataset and baseline experimental results. IEEE Transactions on Biometrics, Behavior, and Identity Science, 4(4):522--532
2022
- [30]
-
[31]
Xinru Wang, Hannah Kim, Sajjadur Rahman, Kushan Mitra, and Zhengjie Miao. 2024. Human-llm collaborative annotation through effective verification of llm labels. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pages 1--21
2024
- [32]
-
[33]
Li Zheng, Boyu Chen, Hao Fei, Fei Li, Shengqiong Wu, Lizi Liao, Donghong Ji, and Chong Teng. 2024 a . Self-adaptive fine-grained multi-modal data augmentation for semi-supervised muti-modal coreference resolution. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 8576--8585
2024
-
[34]
Li Zheng, Hao Fei, Lei Chen, Bobo Li, Fei Li, Chong Teng, Liang Zhao, and Donghong Ji. 2025 a . Stpar: A structure-aware triaffine parser for screenplay character coreference resolution. Transactions of the Association for Computational Linguistics, 13:923--937
2025
-
[35]
Li Zheng, Hao Fei, Ting Dai, Zuquan Peng, Fei Li, Huisheng Ma, Chong Teng, and Donghong Ji. 2025 b . Multi-granular multimodal clue fusion for meme understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 26057--26065
2025
-
[36]
Li Zheng, Hao Fei, Fei Li, Bobo Li, Lizi Liao, Donghong Ji, and Chong Teng. 2024 b . Reverse multi-choice dialogue commonsense inference with graph-of-thought. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19688--19696
2024
-
[37]
Li Zheng, Donghong Ji, Fei Li, Hao Fei, Shengqiong Wu, Jingye Li, Bobo Li, and Chong Teng. 2025 c . Ecqed: emotion-cause quadruple extraction in dialogs. IEEE Transactions on Audio, Speech and Language Processing
2025
-
[38]
Li Zheng, Tengyue Song, Yuzhe Ding, Xiaorui Wu, Fei Li, Dongdong Xie, Jinbo Li, Chong Teng, and Donghong Ji. 2025 d . Improving emotion and intent understanding in multimodal conversations with progressive interaction. IEEE Transactions on Affective Computing
2025
-
[39]
Li Zheng, Sihang Wang, Hao Fei, Zuquan Peng, Fei Li, Jianming Fu, Chong Teng, and Donghong Ji. 2025 e . Enhancing hyperbole and metaphor detection with their bidirectional dynamic interaction and emotion knowledge. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL'25)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.