Recognition: unknown
E2E-WAVE: End-to-End Learned Waveform Generation for Underwater Video Multicasting
Pith reviewed 2026-05-10 06:33 UTC · model grok-4.3
The pith
E2E-WAVE embeds semantic similarity into physical-layer waveforms to deliver real-time underwater video where bit errors would otherwise destroy conventional transmissions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By jointly optimizing tokenization, waveform mapping, and OFDM transmission in a single differentiable pipeline, E2E-WAVE forces the physical-layer signal to carry semantic proximity: when decoding errors occur the receiver naturally selects the token whose waveform is closest in the learned space, converting random bit corruption into graceful semantic degradation.
What carries the argument
A trainable waveform bank that maps semantic video tokens to differentiable OFDM signals, optimized end-to-end so that Euclidean distance in waveform space aligns with semantic similarity.
If this is right
- Real-time 16 FPS video at 128x128 resolution becomes feasible over 2.3 kbps channels that defeat conventional digital modulation.
- Performance advantage over FEC-protected baselines widens as channel conditions worsen.
- A single trained model works across different underwater environments without channel-specific retraining.
- Video codecs that assume low bit-error rates or AWGN statistics become unnecessary in this regime.
Where Pith is reading between the lines
- The same semantic-waveform principle could be tested on other high-error-rate links such as satellite or deep-space channels.
- Physical-layer semantic coding might reduce the total amount of error-correction overhead required at higher protocol layers.
- Extending the approach to multi-user multicasting would require verifying whether the learned waveform bank remains stable when multiple receivers decode simultaneously.
Load-bearing premise
That training waveforms on a single underwater channel will produce signals whose semantic error behavior generalizes to other unseen underwater environments without retraining.
What would settle it
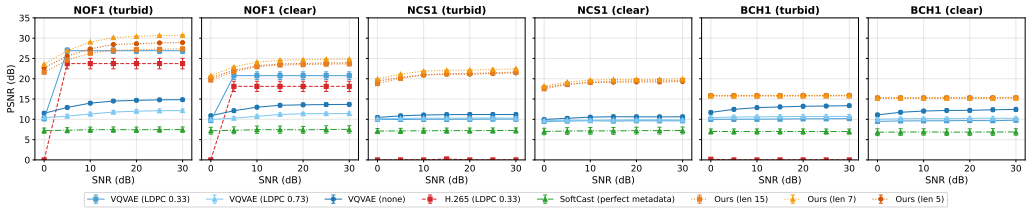
Train the model on the NOF1 channel and then measure PSNR and SSIM on the BCH1 or NCS1 channels; if the reported gains over the FEC baseline disappear or reverse, the generalization claim is false.
Figures








read the original abstract
We present E2E-WAVE, the first end-to-end learned waveform generation system for underwater video multicasting. Acoustic channels exhibit 20--46% bit error rates where forward error correction becomes counterproductive -- LDPC increases rather than decreases errors beyond its decoding threshold. E2E-WAVE addresses this by embedding semantic similarity directly into physical layer waveforms: when decoding errors are unavoidable, the system preferentially selects semantically similar tokens rather than arbitrary corruption. Combining VideoGPT tokenization (1024x compression) with a trainable waveform bank and fully differentiable OFDM transmission, E2E-WAVE achieves +5 dB (19.26%) PSNR and +0.10 (14.28%) SSIM over the strongest FEC-protected baseline in less challenging underwater channel (NOF1) while delivering real-time 16 FPS video at 128x128 resolution over 2.3 kbps channels -- impossible for conventional digital modulation. The performance gap only increases in harsher channels (BCH1, NCS1). Trained on a single channel, E2E-WAVE generalizes to unseen underwater environments without retraining, while HEVC fails at sub-5 kbps rates and SoftCast's AWGN assumptions collapse on frequency-selective channels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces E2E-WAVE, the first end-to-end learned waveform generation system for underwater video multicasting. It tokenizes video via VideoGPT (1024x compression), uses a trainable waveform bank, and employs fully differentiable OFDM to embed semantic similarity into physical-layer signals. This allows the decoder to map unavoidable channel errors (20-46% BER) to semantically similar tokens rather than arbitrary corruption. The system reports +5 dB PSNR (19.26%) and +0.10 SSIM (14.28%) gains over the strongest FEC-protected baseline in the NOF1 channel, supports real-time 16 FPS at 128x128 resolution over 2.3 kbps, generalizes to unseen channels (BCH1, NCS1) without retraining, and outperforms HEVC and SoftCast under frequency-selective underwater conditions.
Significance. If the central mechanism holds, the work would be significant for acoustic communications where conventional FEC fails and semantic-aware physical-layer design could enable reliable low-rate video. The end-to-end differentiability, real-time low-bitrate operation, and reported cross-channel generalization are notable strengths. However, the absence of direct evidence for the semantic-preference claim limits the ability to attribute gains specifically to the proposed mechanism rather than other implementation factors.
major comments (1)
- The core claim that the trainable waveform bank causes the decoder to preferentially map errors to semantically similar VideoGPT tokens (rather than arbitrary corruption) is load-bearing for the contribution, yet the evaluation provides only aggregate PSNR/SSIM and BER. No token-level error pattern analysis, embedding-space distance measurements between erroneous and correct tokens, or ablation removing the semantic loss term is reported. This leaves open whether the +5 dB gain in NOF1 (and larger gaps in BCH1/NCS1) arises from the semantic embedding or from other factors such as improved synchronization or effective BER reduction under the simulated channels.
minor comments (2)
- The abstract and results lack explicit details on data splits, number of training/test videos, error bars, or statistical significance testing for the reported PSNR/SSIM deltas.
- Notation for the waveform bank parameters and the semantic loss term should be introduced earlier and used consistently when describing the end-to-end training pipeline.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of E2E-WAVE's significance for underwater acoustic communications and for the constructive feedback on strengthening the evidence for the core mechanism. We address the major comment below and will incorporate the requested analyses in the revision.
read point-by-point responses
-
Referee: The core claim that the trainable waveform bank causes the decoder to preferentially map errors to semantically similar VideoGPT tokens (rather than arbitrary corruption) is load-bearing for the contribution, yet the evaluation provides only aggregate PSNR/SSIM and BER. No token-level error pattern analysis, embedding-space distance measurements between erroneous and correct tokens, or ablation removing the semantic loss term is reported. This leaves open whether the +5 dB gain in NOF1 (and larger gaps in BCH1/NCS1) arises from the semantic embedding or from other factors such as improved synchronization or effective BER reduction under the simulated channels.
Authors: We agree that the current evaluation relies on aggregate metrics and does not include the direct token-level or ablation analyses needed to isolate the semantic embedding contribution. In the revised manuscript we will add: (1) token-level error pattern analysis showing the distribution of decoded VideoGPT tokens under channel errors and their semantic similarity to ground truth; (2) embedding-space distance measurements (cosine similarity and Euclidean distance in the VideoGPT latent space) between correct and erroneous tokens, compared against random corruption; and (3) an ablation removing the semantic loss term to quantify its effect on PSNR/SSIM gains. These will appear in a dedicated subsection of the experiments. We will also clarify that synchronization is handled identically to the baselines and that post-decoding BER values are comparable, so the gains are unlikely to stem from those factors. The observed generalization to unseen channels (BCH1, NCS1) without retraining provides supporting evidence that the learned waveforms capture semantic robustness rather than channel-specific adaptations. revision: yes
Circularity Check
No significant circularity; empirical end-to-end training results are self-contained
full rationale
The paper describes an end-to-end differentiable system combining VideoGPT tokenization, a trainable waveform bank, and OFDM modulation, with performance evaluated via direct comparisons to external baselines (FEC-protected systems, HEVC, SoftCast) on simulated channels. No equations or steps reduce by construction to their own inputs, no fitted parameters are relabeled as predictions, and no load-bearing self-citations or uniqueness theorems from the same authors are invoked to force the architecture. Generalization claims are presented as empirical outcomes of training on one channel model, without tautological redefinition of the target metrics.
Axiom & Free-Parameter Ledger
free parameters (1)
- trainable waveform bank parameters
axioms (1)
- domain assumption Fully differentiable OFDM transmission enables end-to-end gradient-based training
invented entities (1)
-
trainable waveform bank
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advancements in the field of autonomous underwater vehicle,
A. Sahoo, S. K. Dwivedy, and P. Robi, “Advancements in the field of autonomous underwater vehicle,”Ocean Engineering, vol. 181, pp. 145– 160, 2019
2019
-
[2]
Underwater acoustic sensor networks: research challenges,
I. F. Akyildiz, D. Pompili, and T. Melodia, “Underwater acoustic sensor networks: research challenges,”Ad hoc networks, vol. 3, no. 3, pp. 257– 279, 2005
2005
-
[3]
Underwater sensor net- works: applications, advances and challenges,
J. Heidemann, M. Stojanovic, and M. Zorzi, “Underwater sensor net- works: applications, advances and challenges,”Philosophical Transac- tions of the Royal Society A: Mathematical, Physical and Engineering Sciences, vol. 370, no. 1958, pp. 158–175, 2012
1958
-
[4]
ISO/IEC 14496-10:2022,
ISO Central Secretary, “ISO/IEC 14496-10:2022,” standard, Interna- tional Organization for Standardization, 2022
2022
-
[5]
Performance Overview of the Latest Video Coding Proposals: HEVC, JEM and VVC,
M. O. Martínez-Rach, H. Migallón, O. López-Granado, V . Galiano, and M. P. Malumbres, “Performance Overview of the Latest Video Coding Proposals: HEVC, JEM and VVC,”Journal of Imaging, vol. 7, p. 39, Feb. 2021. Number: 2 Publisher: Multidisciplinary Digital Publishing Institute
2021
-
[6]
Softcast: Clean-slate scalable wireless video,
S. Jakubczak and D. Katabi, “Softcast: Clean-slate scalable wireless video,” inProceedings of the 2010 ACM workshop on Wireless of the students, by the students, for the students, pp. 9–12, 2010
2010
-
[7]
Ecast: An enhanced video transmission design for wireless multicast systems over fading channels,
Z. Zhang, D. Liu, X. Ma, and X. Wang, “Ecast: An enhanced video transmission design for wireless multicast systems over fading channels,” IEEE Systems Journal, vol. 11, no. 4, pp. 2566–2577, 2015
2015
-
[8]
Phydnns: Bringing deep neural networks to the physical layer,
M. Abdi, K. F. Haque, F. Meneghello, J. Ashdown, and F. Restuccia, “Phydnns: Bringing deep neural networks to the physical layer,” in IEEE INFOCOM 2025-IEEE Conference on Computer Communications, pp. 1–10, IEEE, 2025
2025
-
[9]
Cosmos world foundation model platform for physical ai,
NVIDIA, N. Agarwal, A. Ali, M. Bala, Y . Balaji,et al., “Cosmos world foundation model platform for physical ai,” 2025
2025
-
[10]
Omnito- kenizer: A joint image-video tokenizer for visual generation,
J. Wang, Y . Jiang, Z. Yuan, B. Peng, Z. Wu, and Y .-G. Jiang, “Omnito- kenizer: A joint image-video tokenizer for visual generation,” 2024
2024
-
[11]
VideoGPT: Video Generation using VQ-VAE and Transformers
W. Yan, Y . Zhang, P. Abbeel, and A. Srinivas, “Videogpt: Video gener- ation using vq-vae and transformers,”arXiv preprint arXiv:2104.10157, 2021
work page internal anchor Pith review arXiv 2021
-
[12]
Deep learning enabled semantic communication systems,
H. Xie, Z. Qin, G. Y . Li, and B.-H. Juang, “Deep learning enabled semantic communication systems,”IEEE Transactions on Signal Pro- cessing, vol. 69, pp. 2663–2675, 2021
2021
-
[13]
An introduction to deep learning for the physical layer,
T. J. O’Shea and J. Hoydis, “An introduction to deep learning for the physical layer,”IEEE Transactions on Cognitive Communications and Networking, vol. 3, no. 4, pp. 563–575, 2017
2017
-
[14]
Underwater communications: Recent advances,
M. Furqan Ali, N. K. Jayakody, T. D Ponnimbaduge Perera, K. Srini- vasan, A. Sharma, I. Krikidis,et al., “Underwater communications: Recent advances,” ETIC conference, 2019
2019
-
[15]
Deep joint source-channel coding for underwater image transmission,
K. Anjum, Z. Qi, and D. Pompili, “Deep joint source-channel coding for underwater image transmission,” inProceedings of the 16th Interna- tional Conference on Underwater Networks & Systems, WUWNet ’22, (New York, NY , USA), Association for Computing Machinery, 2022
2022
-
[16]
Ultra low bitrate learned image compression by selective detail decoding,
H. Akutsu, A. Suzuki, Z. Zhong, and K. Aizawa, “Ultra low bitrate learned image compression by selective detail decoding,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 524–528, 2020
2020
-
[17]
Experimental evaluation of a real-time fpga platform for multichannel coherent acous- tic communication,
J. Rudander, T. Husøy, P. A. van Walree, and P. Orten, “Experimental evaluation of a real-time fpga platform for multichannel coherent acous- tic communication,”IEEE Journal of Oceanic Engineering, pp. 1–10, 2023
2023
-
[18]
The watermark benchmark for underwater acoustic modulation schemes,
P. A. van Walree, F.-X. Socheleau, R. Otnes, and T. Jenserud, “The watermark benchmark for underwater acoustic modulation schemes,” IEEE journal of oceanic engineering, vol. 42, no. 4, pp. 1007–1018, 2017
2017
-
[19]
DRUV A: Deep-sea robotic underwater video archive dataset for seafloor exploration,
N. Varghese, A. Kumar, and A. N. Rajagopalan, “DRUV A: Deep-sea robotic underwater video archive dataset for seafloor exploration,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 12248–12258, October 2022. Available at: https: //github.com/nishavarghese15/DRUV A
2022
-
[20]
UOT100: Compre- hensive underwater object tracking benchmark dataset,
L. Kezebou, K. Panetta, V . Oludare, and S. Agaian, “UOT100: Compre- hensive underwater object tracking benchmark dataset,”IEEE Journal of Oceanic Engineering, vol. 47, no. 1, pp. 59–75, 2023. Available at: https://www.kaggle.com/datasets/landrykezebou/uot100-underwater- object-tracking-dataset
2023
-
[21]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
K. Soomro, A. R. Zamir, and M. Shah, “UCF101: A dataset of 101 human action classes from videos in the wild,”arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review arXiv 2012
-
[22]
Underwater image co-enhancement with correlation feature matching and joint learning,
Q. Qi, Y . Zhang, F. Tian, Q. J. Wu, K. Li, X. Luan, and D. Song, “Underwater image co-enhancement with correlation feature matching and joint learning,”IEEE Transactions on Circuits and Systems for Video Technology, 2021
2021
-
[23]
Watermark: BCH1 dataset description,
F.-X. Socheleau, A. Pottier, and C. Laot, “Watermark: BCH1 dataset description,” technical report, Institut Mines-Telecom; TELECOM Bre- tagne, UMR CNRS 6285 Lab-STICC, 2016. HAL Id: hal-01404491. Available at: https://hal.science/hal-01404491v1/file/W ATERMARK_ BCH1.pdf
2016
-
[24]
The capacity of low-density parity- check codes under message-passing decoding,
T. J. Richardson and R. L. Urbanke, “The capacity of low-density parity- check codes under message-passing decoding,”IEEE Transactions on Information Theory, vol. 47, no. 2, pp. 599–618, 2001
2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.